OneLake'i Azure Synapse Analytics ile tümleştirme
Azure Synapse, kurumsal veri depolama ve Büyük Veri analizlerini bir araya getiren sınırsız bir analiz hizmetidir. Bu öğreticide, Azure Synapse Analytics kullanarak OneLake'e nasıl bağlandığınız gösterilmektedir.
Apache Spark kullanarak Synapse'ten veri yazma
Azure Synapse Analytics'ten OneLake'e örnek veriler yazmak için Apache Spark'ı kullanmak için bu adımları izleyin.
Synapse çalışma alanınızı açın ve tercih ettiğiniz parametrelerle bir Apache Spark havuzu oluşturun.
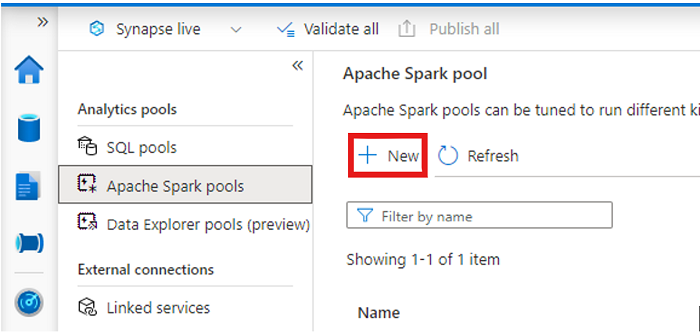
Yeni bir Apache Spark not defteri oluşturun.
Not defterini açın, dili PySpark (Python) olarak ayarlayın ve yeni oluşturduğunuz Spark havuzuna bağlayın.
Ayrı bir sekmede Microsoft Fabric lakehouse'unuza gidin ve en üst düzey Tablolar klasörünü bulun.
Tablolar klasörüne sağ tıklayın ve Özellikler'i seçin.
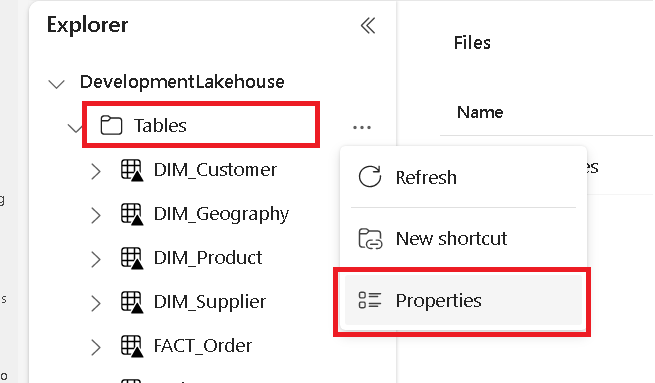
Özellikler bölmesinden ABFS yolunu kopyalayın.
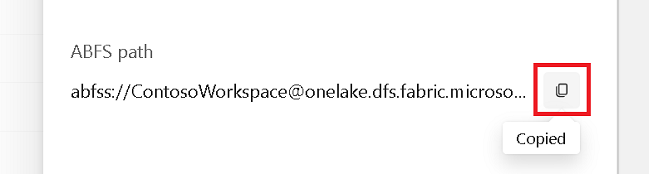
Azure Synapse not defterine geri dönüp ilk yeni kod hücresinde lakehouse yolunu sağlayın. Bu göl evi, verilerinizin daha sonra yazıldığı yerdir. Hücreyi çalıştırın.
# Replace the path below with the ABFS path to your lakehouse Tables folder. oneLakePath = 'abfss://WorkspaceName@onelake.dfs.fabric.microsoft.com/LakehouseName.lakehouse/Tables'Yeni bir kod hücresinde, Azure açık veri kümesindeki verileri bir veri çerçevesine yükleyin. Bu veri kümesi, göl kutunuza yüklediğiniz veri kümesidir. Hücreyi çalıştırın.
yellowTaxiDf = spark.read.parquet('wasbs://nyctlc@azureopendatastorage.blob.core.windows.net/yellow/puYear=2018/puMonth=2/*.parquet') display(yellowTaxiDf.limit(10))Yeni bir kod hücresinde verilerinizi filtreleyin, dönüştürün veya hazırlayın. Bu senaryoda daha hızlı yükleme yapmak, diğer veri kümeleriyle birleştirmek veya belirli sonuçlara göre filtreleme yapmak için veri kümenizi kırpabilirsiniz. Hücreyi çalıştırın.
filteredTaxiDf = yellowTaxiDf.where(yellowTaxiDf.tripDistance>2).where(yellowTaxiDf.passengerCount==1) display(filteredTaxiDf.limit(10))Yeni bir kod hücresinde, OneLake yolunuzu kullanarak filtrelenmiş veri çerçevenizi Fabric lakehouse'unuzda yeni bir Delta-Parquet tablosuna yazın. Hücreyi çalıştırın.
filteredTaxiDf.write.format("delta").mode("overwrite").save(oneLakePath + '/Taxi/')Son olarak, yeni bir kod hücresinde, OneLake'den yeni yüklenen dosyanızı okuyarak verilerinizin başarıyla yazıldığını test edin. Hücreyi çalıştırın.
lakehouseRead = spark.read.format('delta').load(oneLakePath + '/Taxi/') display(lakehouseRead.limit(10))
Tebrikler. Artık Azure Synapse Analytics'te Apache Spark kullanarak OneLake'te veri okuyabilir ve yazabilirsiniz.
SQL kullanarak Synapse'ten veri okuma
Azure Synapse Analytics'ten OneLake'ten veri okumak için SQL sunucusuz kullanmak için bu adımları izleyin.
Bir Fabric lakehouse açın ve Synapse'ten sorgulamak istediğiniz tabloyu belirleyin.
Tabloya sağ tıklayın ve Özellikler'i seçin.
Tablonun ABFS yolunu kopyalayın.
Yeni bir SQL betiği oluşturun.
SQL sorgu düzenleyicisinde aşağıdaki sorguyu girin ve yerine
ABFS_PATH_HEREdaha önce kopyaladığınız yolu girin.SELECT TOP 10 * FROM OPENROWSET( BULK 'ABFS_PATH_HERE', FORMAT = 'delta') as rows;Tablonuzun ilk 10 satırını görüntülemek için sorguyu çalıştırın.
Tebrikler. Artık Azure Synapse Analytics'te SQL sunucusuz kullanarak OneLake'ten veri okuyabilirsiniz.
İlgili içerik
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin