Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Şunlar için geçerlidir: ✅Microsoft Fabric✅Azure Veri Gezgini
Eklenti, bag_unpack her özellik paketi üst düzey yuvasını sütun olarak değerlendirerek türünde dynamictek bir sütunu açar. Eklenti işleciyle birlikte çağrılır evaluate .
Sözdizimi
T|evaluatebag_unpack( Sütunu [,OutputColumnPrefix ] [,columnsConflict ] [,ignoredProperties ] ) [:OutputSchema]
Söz dizimi kuralları hakkında daha fazla bilgi edinin.
Parametreler
| Ad | Tür | Zorunlu | Açıklama |
|---|---|---|---|
| T | string |
✔️ | Sütununun paketten çıkarılacağı tablosal giriş. |
| Sütun | dynamic |
✔️ | Paketten çıkarılmayan T sütunu. |
| OutputColumnPrefix | string |
Eklenti tarafından üretilen tüm sütunlara eklenecek ortak bir ön ek. | |
| columnsConflict | string |
Sütun çakışma çözümlemesinin yönü. Geçerli değerler: error - Sorgu hata üretir (varsayılan)replace_source - Kaynak sütun değiştirildikeep_source - Kaynak sütun tutulur |
|
| ignoredProperties | dynamic |
Göz ardı edilecek isteğe bağlı bir çanta özellikleri kümesi. } | |
| OutputSchema | Eklenti çıkışı için bag_unpack sütun adlarını ve türlerini belirtin. Söz dizimi bilgileri için bkz . Çıktı şeması söz dizimi ve etkilerini anlamak için bkz. Performansla ilgili dikkat edilmesi gerekenler. |
Çıktı şeması söz dizimi
(
ColumnName:ColumnType [, ...])
Çıkışa kaynak tablonun tüm sütunlarını eklemek için ilk parametre olarak aşağıdaki gibi joker karakter * kullanın:
(
*
,
ColumnName:ColumnType [, ...])
Performansla ilgili dikkat edilmesi gerekenler
Eklentiyi OutputSchema olmadan kullanmak, büyük veri kümelerinde ciddi performans etkileri olabilir ve bundan kaçınılmalıdır.
OutputSchema'nın sağlanması sorgu altyapısının sorgu yürütmeyi iyileştirmesine olanak tanır. Giriş verilerini ayrıştırmaya ve çözümlemeye gerek kalmadan çıkış şemasını belirleyebilir. Bu, giriş verileri büyük veya karmaşık olduğunda faydalıdır. Eklentiyi tanımlı bir OutputSchema ile ve olmadan kullanmanın performans üzerindeki etkileri olan örnekler bölümüne bakın.
Döndürülenler
Eklenti, bag_unpack tablosal girişi (T) kadar kaydı olan bir tablo döndürür. Tablonun şeması, aşağıdaki değişikliklerle tablosal girişinin şemasıyla aynıdır:
- Belirtilen giriş sütunu (Sütun) kaldırılır.
- Her sütunun adı, isteğe bağlı olarak OutputColumnPrefix ön ekine sahip olan her yuvanın adına karşılık gelir.
- Her sütunun türü, aynı yuvanın tüm değerleri aynı türe sahipse yuvanın türü veya
dynamicdeğer türü farklıysa olur. - Şema, T'nin en üst düzey özellik paketi değerlerinde ayrı yuvalar olduğu kadar çok sütunla genişletilir.
Not
- OutputSchema belirtmezseniz, eklenti çıkış şeması giriş veri değerlerine göre değişir. Eklentinin farklı veri girişlerine sahip birden çok yürütülmesi farklı çıkış şemaları oluşturabilir.
-
OutputSchema belirtilirse, joker karakter
*kullanılmadığı sürece eklenti yalnızca Çıktı şeması söz diziminde tanımlanan sütunları döndürür. - Giriş verilerinin tüm sütunlarını ve OutputSchema'da tanımlanan sütunları döndürmek için OutputSchema'da bir joker karakter
*kullanın.
Tablosal şema kuralları giriş verilerine uygulanır. Özellikle:
- Çıkış sütun adı, paketten çıkarılacak sütun (Sütun) olmadığı sürece tablosal giriş T'deki mevcut bir sütunla aynı olamaz. Aksi takdirde, çıkış aynı ada sahip iki sütun içerir.
- OutputColumnPrefix öneki eklendiğinde tüm yuva adları geçerli varlık adları olmalıdır ve tanımlayıcı adlandırma kurallarına uymalıdır.
Eklenti null değerleri yoksayar.
Örnekler
Bu bölümdeki örneklerde, kullanmaya başlamanıza yardımcı olması için söz diziminin nasıl kullanılacağı gösterilmektedir.
Bir torbayı genişletme:
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20}),
dynamic({"Name": "Dave", "Age":40}),
dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d)
Çıktı
| Yaş | Ad |
|---|---|
| 20 | John |
| 40 | Demirci |
| 30 | Yasemin |
Bir torbayı OutputColumnPrefix genişletin ve önek içeren sütun adları oluşturmak için seçeneğini kullanın:
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20}),
dynamic({"Name": "Dave", "Age":40}),
dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d, 'Property_')
Çıktı
| Property_Age | Property_Name |
|---|---|
| 20 | John |
| 40 | Demirci |
| 30 | Yasemin |
Bir torbayı columnsConflict genişletin ve dinamik sütun ile mevcut sütun arasındaki sütun çakışmasını çözmek için seçeneğini kullanın:
datatable(Name:string, d:dynamic)
[
'Old_name', dynamic({"Name": "John", "Age":20}),
'Old_name', dynamic({"Name": "Dave", "Age":40}),
'Old_name', dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d, columnsConflict='replace_source') // Use new name
Çıktı
| Yaş | Ad |
|---|---|
| 20 | John |
| 40 | Demirci |
| 30 | Yasemin |
datatable(Name:string, d:dynamic)
[
'Old_name', dynamic({"Name": "John", "Age":20}),
'Old_name', dynamic({"Name": "Dave", "Age":40}),
'Old_name', dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d, columnsConflict='keep_source') // Keep old name
Çıktı
| Yaş | Ad |
|---|---|
| 20 | Old_name |
| 40 | Old_name |
| 30 | Old_name |
Bir torbayı ignoredProperties genişletin ve özellik paketindeki özelliklerden 2'sini yoksaymak için seçeneğini kullanın:
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20, "Address": "Address-1" }),
dynamic({"Name": "Dave", "Age":40, "Address": "Address-2"}),
dynamic({"Name": "Jasmine", "Age":30, "Address": "Address-3"}),
]
// Ignore 'Age' and 'Address' properties
| evaluate bag_unpack(d, ignoredProperties=dynamic(['Address', 'Age']))
Çıktı
| Ad |
|---|
| John |
| Demirci |
| Yasemin |
Bir torbayı genişletin ve OutputSchema seçeneğini kullanın:
datatable(d:dynamic)
[
dynamic({"Name": "John", "Age":20}),
dynamic({"Name": "Dave", "Age":40}),
dynamic({"Name": "Jasmine", "Age":30}),
]
| evaluate bag_unpack(d) : (Name:string, Age:long)
Çıktı
| Ad | Yaş |
|---|---|
| John | 20 |
| Demirci | 40 |
| Yasemin | 30 |
OutputSchema içeren bir torbayı genişletin ve joker * karakter seçeneğini kullanın:
Bu sorgu özgün yuva Açıklamasını ve OutputSchema'da tanımlanan sütunları döndürür.
datatable(d:dynamic, Description: string)
[
dynamic({"Name": "John", "Age":20, "height":180}), "Student",
dynamic({"Name": "Dave", "Age":40, "height":160}), "Teacher",
dynamic({"Name": "Jasmine", "Age":30, "height":172}), "Student",
]
| evaluate bag_unpack(d) : (*, Name:string, Age:long)
Çıktı
| Açıklama | Ad | Yaş |
|---|---|---|
| Öğrenci | John | 20 |
| Öğretmen | Demirci | 40 |
| Öğrenci | Yasemin | 30 |
Performans üzerindeki etkileri olan örnekler
Performans etkilerini karşılaştırmak için bir torbayı tanımlı OutputSchema ile ve olmadan genişletin:
Bu örnek , yardım kümesinde genel kullanıma açık bir tablo kullanır. ContosoSales veritabanında SalesDynamic adlı bir tablo vardır. Tablo satış verilerini içerir ve Customer_Properties adlı dinamik bir sütun içerir.
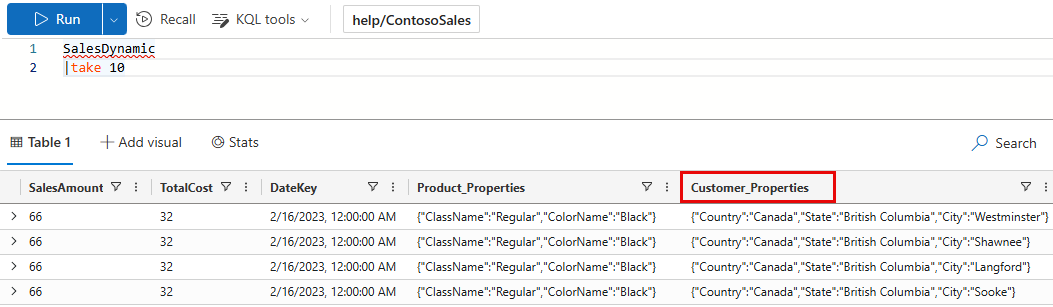
Çıkış şeması olmayan örnek: İlk sorgu OutputSchema tanımlamaz. Sorgu 5,84 saniye CPU alır ve 36,39 MB veri tarar.
SalesDynamic | evaluate bag_unpack(Customer_Properties) | summarize Sales=sum(SalesAmount) by Country, StateÇıkış şeması örneği: İkinci sorgu bir OutputSchema sağlar. Sorgu 0,45 saniye CPU alır ve 19,31 MB veri tarar. Sorgunun giriş tablosunu analiz etmek zorunda değildir ve işlem süresinden tasarruf edin.
SalesDynamic | evaluate bag_unpack(Customer_Properties) : (*, Country:string, State:string, City:string) | summarize Sales=sum(SalesAmount) by Country, State
Çıktı
Çıktı her iki sorgu için de aynıdır. Çıktının ilk 10 satırı aşağıda gösterilmiştir.
| Kanada | Britanya Kolumbiyası | 56,101,083 |
|---|---|---|
| Birleşik Krallık | İngiltere | 77,288,747 |
| Avustralya | Victoria | 31,242,423 |
| Avustralya | Queensland | 27,617,822 |
| Avustralya | Güney Avustralya | 8,530,537 |
| Avustralya | Yeni Güney Galler | 54,765,786 |
| Avustralya | Tazmanya | 3,704,648 |
| Kanada | Alberta | 375,061 |
| Kanada | Ontario | 38,282 |
| Amerika Birleşik Devletleri | Washington | 80,544,870 |
| ... | ... | ... |
İlgili içerik
- parse_json işlevi
- mv-expand işleci