Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Power BI'daki örnekleme algoritması, yüksek yoğunluklu verileri örnekleyen görselleri geliştirir. Örneğin, her mağazanın her yıl 10.000'den fazla satış makbuzu olan satış sonuçlarından bir çizgi grafik oluşturabilirsiniz. Bu tür satış bilgilerinin bir çizgi grafiği, her mağaza için verilerden veri örnekleri alır ve temel alınan verileri temsil eden çok serili bir çizgi grafik oluşturur. Satışların zaman içinde nasıl değiştiğini göstermek için bu verilerin anlamlı bir gösterimini seçin. Bu uygulama, yüksek yoğunluklu verileri görselleştirmede yaygındır. Yüksek yoğunluklu veri örneklemenin ayrıntıları bu makalede açıklanmıştır.
Uyarı
Bu makalede açıklanan Yüksek yoğunluklu örnekleme algoritması hem Power BI Desktop'ta hem de Power BI hizmetinde kullanılabilir.
Yüksek yoğunluklu çizgi örnekleme nasıl çalışır?
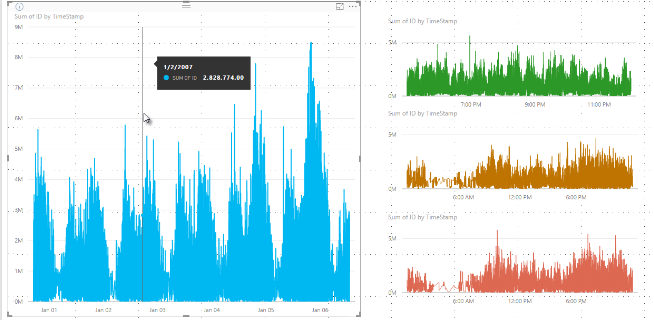
Daha önce Power BI, temel alınan verilerin tam aralığındaki örnek veri noktalarından oluşan bir koleksiyonu belirleyici bir şekilde seçiyordu. Örneğin, bir takvim yılına yayılan bir görselde yüksek yoğunluklu veriler varsa, görsel 350 örnek veri noktası görüntüler. Algoritma, tüm veri aralığının görselde temsil edilmesini sağlamak için her veri noktasını seçer. Bunun nasıl gerçekleştiğini anlamanıza yardımcı olmak için bir yıllık bir dönem boyunca hisse senedi fiyatı çizip 365 veri noktası seçerek çizgi grafik görseli oluşturmayı düşünün. Bu, her gün için bir veri noktasıdır.
Bu durumda, her gün bir hisse senedi fiyatı için birçok değer vardır. Elbette, günlük yüksek ve düşük bir değer vardır, ancak bu değerler borsanın açık olduğu gün boyunca herhangi bir zamanda ortaya çıkabilir. Yüksek yoğunluklu çizgi örneklemesi için, temel alınan veri örneği her gün 10:30 ve 12:00'de alınırsa, 10:30 ve 12:00'deki fiyat gibi temel verilerin temsili bir anlık görüntüsünü elde edersiniz. Ancak anlık görüntü, o gün o temsili veri noktası için hisse senedi fiyatının gerçek yüksek ve düşük kısmını yakalamayabilir. Bu durumda ve diğer durumlarda, örnekleme, temel alınan verileri temsil eder, ancak her zaman önemli noktaları yakalayamaz, ki bu durumda önemli olan günlük hisse senedi fiyatlarının en yüksek ve en düşük değerleridir.
Tanımı gereği yüksek yoğunluklu veriler, etkileşime duyarlı ve makul bir şekilde hızlı bir şekilde görselleştirmeler oluşturmak için örneklenir. Görselde çok fazla veri noktası olması görseli yavaşlatabilir ve eğilimlerin görünürlüğünü düşürebilir. Verilerin nasıl örneklenmiş olduğu, en iyi görselleştirme deneyimini sağlamak için örnekleme algoritmasının oluşturulmasını sağlar. Power BI Desktop'ta algoritma, her zaman dilimindeki önemli noktaların yanıt verme, temsil ve net bir şekilde korunmasının en iyi bileşimini sağlar.
Çizgi örnekleme algoritması nasıl çalışır?
Yüksek yoğunluklu çizgi örnekleme algoritması, sürekli x eksenine sahip çizgi grafik ve alan grafiği görselleri için kullanılabilir.
Yüksek yoğunluklu bir görsel için Power BI , verilerinizi akıllı bir şekilde yüksek çözünürlüklü öbekler halinde dilimler ve ardından her öbekleri temsil eden önemli noktaları seçer. Bu yüksek çözünürlüklü verileri dilimleme işlemi, elde edilen grafiğin tüm verilerin işlenmiş haliyle görsel olarak fark edilemez olmasını, ancak daha hızlı ve etkileşimli olmasını sağlamak için ayarlanmıştır.
Yüksek yoğunluklu çizgi görselleri için minimum ve maksimum değerler
Tüm görselleştirmeler için aşağıdaki sınırlamalar geçerlidir:
- 3.500 , temel alınan veri noktası veya seri sayısından bağımsız olarak çoğu görselde görüntülenen maksimum veri noktası sayısıdır. Özel durumlar için aşağıdaki listeye bakın. Örneğin, her birinde 350 veri noktası bulunan 10 seriniz varsa görsel, genel veri noktası üst sınırına ulaşır. Bir seriniz varsa, algoritma temel alınan veriler için en iyi örneklemeyi kabul ederse 3.500'e kadar veri noktası olabilir.
- Herhangi bir görsel için en fazla 60 seri vardır. 60'tan fazla seriniz varsa verileri ayırıp her birinde 60 veya daha az seri bulunan birden çok görsel oluşturun. Verilerin yalnızca belirli kesimlerini göstermek için bir dilimleyici kullanmak, ancak bunu sadece belirli seriler için yapmak iyi bir uygulamadır. Örneğin, göstergedeki tüm alt kategorileri görüntülüyorsanız, aynı rapor sayfasındaki genel kategoriye göre filtrelemek için bir dilimleyici kullanabilirsiniz.
En fazla veri sınırı sayısı, 3.500 veri noktası sınırının özel durumları olan aşağıdaki görsel türleri için daha yüksektir:
- R görselleri için maksimum 150.000 veri noktası.
- Azure Map görselleri için 30.000 veri noktası.
- Bazı dağılım grafiği yapılandırmaları için 10.000 veri noktası (dağılım grafikleri varsayılan olarak 3.500 olur).
- Yüksek yoğunluklu örnekleme kullanan diğer tüm görseller için 3.500. Diğer bazı görseller daha fazla veri görselleştirebilir, ancak örnekleme kullanmaz.
Bu parametreler, Power BI Desktop'taki görsellerin hızlı işlenmesini, kullanıcı etkileşimine yanıt vermemeye devam etmesini ve görseli işleyen bilgisayarda gereksiz hesaplama yüküne neden olmamasını sağlar.
Yüksek yoğunluklu çizgi görselleri için temsili veri noktalarını değerlendirme
Temel alınan veri noktalarının sayısı görselin gösterebileceği en yüksek veri noktalarını aştığında, gruplama adlı bir işlem başlar. Bölme, temel alınan verileri kutular adı verilen gruplara ayırır ve sonra bu kutuları yinelemeli olarak iyileştirir.
Algoritma, görsel için en büyük ayrıntı düzeyini oluşturmak için mümkün olduğunca çok bölme oluşturur. Her bölmede algoritma, aykırı değerler gibi önemli ve önemli değerlerin yakalanıp görselde görüntülendiğinden emin olmak için en düşük ve en yüksek veri değerini bulur. Verilerin Power BI tarafından gruplanması ve daha sonra değerlendirilmesinin sonuçlarına bağlı olarak, görsel için x ekseni için minimum çözünürlük, görsel için en yüksek ayrıntı düzeyini sağlamak üzere belirlenir.
Daha önce belirtildiği gibi, her seri için minimum ayrıntı düzeyi 350 nokta, çoğu görsel için maksimum 3.500'dür. Özel durumlar önceki bölümde listelenmiştir.
Her bölme iki veri noktasıyla temsil edilir ve bu da bölmenin görseldeki temsili veri noktaları olur. Veri noktaları, bu aralığın en yüksek ve en düşük değerleridir. Bölme işlemi, yüksek ve düşük değerleri seçerek önemli yüksek veya önemli düşük değerlerin görselde yakalanmasını ve işlenmesini sağlar.
Bu işlem, ara sıra aykırı değerin yakalanmasını ve görselde düzgün bir şekilde görüntülenmesini sağlamak için çok fazla analiz gerektiriyorsa, haklısınız. Algoritma ve gruplama işleminin tam nedeni budur.
Araç ipuçları ve yüksek yoğunluklu çizgi örnekleme
Bölme işlemi belirli bir bölmede en düşük ve en yüksek değeri yakalar ve görüntüler. Bu işlem, veri noktalarının üzerine geldiğinizde araç ipuçlarının verileri nasıl gösterdiğini etkileyebilir. Bu işlemin araç ipuçlarını nasıl ve neden etkilediğini açıklamak için hisse senedi fiyatlarıyla ilgili örneğimizi yeniden gözden geçirelim.
Hisse senedi fiyatını temel alan bir görsel oluşturuyorsunuz ve her ikisi de Yüksek yoğunluklu örnekleme kullanan iki farklı hisse senedini karşılaştırıyorsunuz. Her seri için temel alınan verilerin birçok veri noktası vardır. Örneğin, günün her saniyesinde hisse senedi fiyatını yakalarsınız. Yüksek yoğunluklu çizgi örnekleme algoritması, her seri için birbirinden bağımsız olarak bölme gerçekleştirir.
Şimdi, ilk hisse senedi fiyatı 12:02'de yükselip 10 saniye sonra hızla geri geliyor. Bu önemli bir veri noktasıdır. Bu hisse senedi için gruplama gerçekleştiğinde, 12:02'deki yüksek değer söz konusu bölme için temsili bir veri noktasıdır.
Ancak ikinci hisse senedi için 12:02, bu zaman aralığını içeren aralıkta en yüksek veya en düşük değer değil. Belki de 12:02'yi içeren aralıktaki yüksek ve düşük noktalar üç dakika sonra gerçekleşir. Bu durumda, çizgi grafik oluşturulduğunda ve 12:02'nin üzerine geldiğinizde, ilk hisse senedi için araç ipucunda bir değer görürsünüz. 12:02'de ilk hisse senedinin değerinin yükselmesi nedeniyle bu değer vardır ve algoritma bu değeri bölmenin yüksek veri noktası olarak seçer. Ancak 12:02'de ikinci hisse senedi için ipucunda herhangi bir değer görmüyorsunuz. İkinci hisse senedi, 12:02'yi içeren zaman dilimi için yüksek veya düşük bir değere sahip değildi. Bu nedenle, ikinci hisse senedi için saat 12:02'de gösterilecek veri yoktur ve bu nedenle hiçbir araç ipucu verisi görüntülenmez.
Bu durum araç ipuçlarında sık sık gerçekleşir. Belirli bir bölmenin yüksek ve düşük değerleri büyük olasılıkla eşit ölçeklendirilmiş x ekseni değer noktalarıyla mükemmel eşleşmediğinden araç ipucu değeri görüntülemez.
Yüksek yoğunluklu çizgi örneklemeyi açma
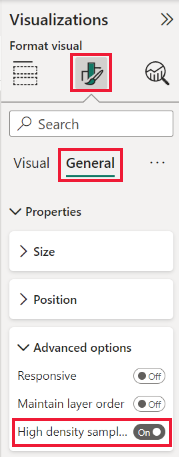
Varsayılan olarak algoritma Açık'tır. Bu ayarı değiştirmek için Biçimlendirme bölmesine gidin, Genel kartında ve alt kısımda Yüksek yoğunluklu örnekleme kaydırıcısını görürsünüz. Kaydırıcıyı seçerek Açık veya Kapalı konuma getirin.
Dikkat edilmesi gerekenler ve sınırlamalar
Yüksek yoğunluklu çizgi örnekleme algoritması Power BI'da önemli bir geliştirmedir, ancak yüksek yoğunluklu değerler ve verilerle çalışırken bilmeniz gereken birkaç nokta vardır.
- Artan ayrıntı düzeyi ve gruplandırma işlemi nedeniyle Araç ipuçları yalnızca temsili veriler imlecinizle hizalanırsa bir değer gösterebilir. Daha fazla bilgi için bu makaledeki Araç ipuçları ve yüksek yoğunluklu çizgi örnekleme bölümüne bakın.
- Genel bir veri kaynağının boyutu çok büyük olduğunda algoritma, veri içeri aktarma üst sınırına uyum sağlamak için serileri (gösterge öğeleri) ortadan kaldırır.
- Bu durumda algoritma, gösterge serisini alfabetik olarak sıralar. Veri içeri aktarma üst sınırına ulaşılana kadar gösterge öğeleri listesini alfabetik sırada başlatır ve daha fazla seriyi içeri aktarmaz.
- Temel alınan bir veri kümesinde en fazla seri sayısı olan 60'tan fazla seri olduğunda, algoritma seriyi alfabetik olarak sıralar ve 60. alfabetik sıralı serinin ötesindeki serileri ortadan kaldırır.
- Verilerdeki değerler sayısal veya tarih/saat türleri değilse Power BI algoritmayı kullanmaz ve önceki, yüksek yoğunluklu olmayan örnekleme algoritmasına geri döner.
- Veri içermeyen öğeleri göster ayarı algoritma tarafından desteklenmez.
- Algoritma, SQL Server Analysis Services sürüm 2016 veya önceki sürümlerinde barındırılan bir modele canlı bağlantı kullanılırken desteklenmez. Power BI veya Azure Analysis Services'te barındırılan modellerde desteklenir.