Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
| Mayana Pereira | Scott Christiansen |
|---|---|
| CELA Veri Bilimi | Müşteri Güvenliği ve Güveni |
| Microsoft | Microsoft |
Soyut — Güvenlik hata raporlarının (SBR) tanımlanması, yazılım geliştirme yaşam döngüsünün önemli bir adımıdır. Denetimli makine öğrenmesi tabanlı yaklaşımlarda, hata raporlarının tamamının eğitim için kullanılabilir olduğunu ve etiketlerinin kirlilik içermediğini varsaymak normaldir. Bildiğimiz kadarıyla, bu, yalnızca başlık mevcut olduğunda ve etiket kirliliği bulunduğunda bile SBR için doğru etiket tahmininin mümkün olduğunu gösteren ilk çalışmadır.
Dizin Koşulları — Machine Learning, Yanlış Etiketleme, Kirlilik, Güvenlik Hata Raporu, Hata Depoları
Ben. GİRİŞ
Bildirilen hatalar arasında güvenlikle ilgili sorunların belirlenmesi, yazılım geliştirme ekipleri arasında acil bir gereksinimdir. Bu tür sorunlar, uyumluluk gereksinimlerini karşılamak ve yazılım ile müşteri verilerinin bütünlüğünü sağlamak için daha hızlı düzeltmeler çağrısı yapar.
Makine öğrenmesi ve yapay zeka araçları, yazılım geliştirmeyi daha hızlı, çevik ve doğru yapmayı vaat ediyor. Birçok araştırmacı, [2], [7], [8], [18] güvenlik hatalarını belirleme sorununa makine öğrenmesi uyguladı. Daha önce yayımlanan çalışmalar, hata raporunun tamamının bir makine öğrenmesi modelini eğitip puanlama için kullanılabilir olduğunu varsaymıştı. Bu durum söz konusu olmayabilir. Hata raporunun tamamının kullanılabilir duruma getirilemediği durumlar vardır. Örneğin, hata raporu parolalar, kişisel olarak tanımlayıcı bilgiler (PII) veya diğer hassas veri türlerini (şu anda Microsoft'ta karşı karşıya olduğumuz bir durum) içerebilir. Bu nedenle, yalnızca hata raporunun başlığının kullanılabilir olması gibi daha az bilgi kullanılarak güvenlik hatası belirlemenin ne kadar iyi gerçekleştirilebileceğinin belirlenmesi önemlidir.
Buna ek olarak, hata depoları genellikle yanlış etiketlenmiş girdiler içerir [7]: güvenlikle ilgili olarak sınıflandırılan güvenlikle ilgili olmayan hata raporları ve tam tersi. Geliştirme ekibinin güvenlik konusunda uzman olmamasından belirli sorunların belirsizliğine kadar çeşitli yanlış etiketlemeler oluşmasının çeşitli nedenleri vardır; örneğin, güvenlikle ilgili olmayan hataların dolaylı bir şekilde kötüye kullanılmasının bir güvenlik etkisine neden olması mümkündür. Bu ciddi bir sorundur çünkü SBR'lerin yanlış etiketlenmesi, güvenlik uzmanlarının hata veritabanını pahalı ve zaman alan bir çabayla el ile gözden geçirmesine neden olur. Kirliliğin farklı sınıflandırıcıları nasıl etkilediğini ve farklı türlerdeki kirliliklerle kirlenmiş veri kümelerinin varlığında farklı makine öğrenmesi tekniklerinin ne kadar güçlü (veya kırılgan) olduğunu anlamak, yazılım mühendisliği uygulamasına otomatik sınıflandırma getirmek için ele alınması gereken bir sorundur.
Ön çalışma, hata depolarının içsel olarak gürültülü olduğunu ve kirliliğin performans makine öğrenmesi sınıflandırıcıları üzerinde olumsuz bir etkisi olabileceğini savunuyor [7]. Bununla birlikte, farklı kirlilik düzeylerinin ve türlerinin güvenlik hata raporlarını (SBS) belirleme sorunu için farklı denetimli makine öğrenmesi algoritmalarının performansını nasıl etkilediğine ilişkin sistematik ve nicel bir çalışma yoktur.
Bu çalışmada, hata raporlarının sınıflandırmasının yalnızca başlık eğitim ve puanlama için kullanılabilir olduğunda bile gerçekleştirilebileceğini gösteriyoruz. Bildiğimiz kadarıyla, bu konuda yapılmış ilk çalışmadır. Ayrıca, hata raporu sınıflandırmasında kirlilik etkisinin ilk sistematik çalışmasını sağlıyoruz. Sınıftan bağımsız gürültüye karşı üç makine öğrenmesi tekniğinin (lojistik regresyon, saf Bayes ve AdaBoost) sağlamlığı hakkında karşılaştırmalı bir çalışma yapıyoruz.
Birkaç basit sınıflandırıcı [5], [6] için kirliliğin genel etkisini yakalayan bazı analitik modeller olsa da, bu sonuçlar kirliliğin duyarlılık üzerindeki etkisi üzerinde sıkı sınırlar sağlamaz ve yalnızca belirli bir makine öğrenmesi tekniği için geçerlidir. Makine öğrenmesi modellerindeki gürültü etkisinin doğru bir analizi genellikle hesaplama denemeleri çalıştırılarak gerçekleştirilir. Bu tür analizler, yazılım ölçüm verilerinden [4], uydu görüntü sınıflandırmasına [13] ve tıbbi verilere [12] kadar çeşitli senaryolar için yapılmıştır. Ancak bu sonuçlar, veri kümelerinin doğasına yüksek bağımlılığı ve temel sınıflandırma sorunu nedeniyle belirli bir sorunumuza çevrilemez. Bildiklerimize göre, özellikle güvenlik hata raporu sınıflandırması üzerindeki etkisi konusunda gürültülü veri kümeleriyle ilgili yayımlanmış bir sonuç yoktur.
ARAŞTıRMA KATKıLARıMıZ:
Sınıflandırıcıları yalnızca raporların başlığına göre güvenlik hata raporlarının (SBR) tanımlanması için eğitiyoruz. Bildiklerimiz dahilinde, bu, bunu yapan ilk çalışmadır. Önceki çalışmalarda hata raporunun tamamı kullanılmış veya hata raporu ek tamamlayıcı özelliklerle geliştirilmiştir. Yalnızca kutucuğu temel alan hataları sınıflandırmak, gizlilikle ilgili endişelerden dolayı hata raporlarının tamamı kullanılabilir hale getirilemediğinde özellikle önemlidir. Örneğin, parolalar ve diğer hassas veriler içeren hata raporlarının kötü bir adı vardır.
Ayrıca SBRI'lerin otomatik olarak sınıflandırılması için kullanılan farklı makine öğrenmesi modellerinin ve tekniklerinin etiket kirliliğine dayanıklılık ile ilgili ilk sistematik çalışmayı sağlıyoruz. Sınıfa bağımlı ve sınıftan bağımsız kirliliğe karşı üç farklı makine öğrenmesi tekniğinin (lojistik regresyon, saf Bayes ve AdaBoost) sağlamlığı hakkında karşılaştırmalı bir çalışma yapıyoruz.
Kağıdın kalan kısmı şu şekilde sunulmuştur: II. bölümde literatürde önceki eserlerin bazılarını sunuyoruz. Bölüm III'te veri kümesini ve verilerin önceden nasıl işlendiğini açıklayacağız. Metodoloji bölüm IV'te açıklanmıştır ve denemelerimizin sonuçları V bölümünde analiz edilir. Son olarak, sonuçlarımız ve gelecekteki çalışmalarımız VI'da sunulmaktadır.
II. ÖNCEKİ ÇALIŞMALAR
HATA DEPOLARıNA MAKINE ÖĞRENMESI UYGULAMALARı.
Birkaç uygulamayı adlandırmak için güvenlik hata algılama [2], [7], [8], [18], hata yineleme belirleme [3], hata önceliklendirme [1], [11] gibi zahmetli görevleri otomatikleştirme amacıyla hata depolarına metin madenciliği, doğal dil işleme ve makine öğrenmesi uygulama konusunda kapsamlı bir literatür mevcuttur. İdeal olarak makine öğrenmesi (ML) ile doğal dil işlemenin evliliği, hata veritabanlarını seçmek, bu görevleri gerçekleştirmek için gereken süreyi kısaltmak ve sonuçların güvenilirliğini artırmak için gereken el ile çalışmayı azaltma potansiyeline sahiptir.
[7] içinde yazarlar, hatanın açıklamasına göre SBR sınıflandırmasını otomatikleştirmek için doğal bir dil modeli önerir. Yazarlar eğitim veri kümesindeki tüm hata açıklamalarından bir kelime dağarcığı ayıklar ve el ile üç sözcük listesi haline getirmektedir: ilgili sözcükler, durdurma sözcükleri (sınıflandırma için ilgisiz görünen ortak sözcükler) ve eş anlamlılar. Güvenlik mühendisleri tarafından değerlendirilen veriler üzerinde eğitilen güvenlik hata sınıflandırıcısının performansını ve genel olarak hata muhabirleri tarafından etiketlenen veriler üzerinde eğitilen bir sınıflandırıcıyı karşılaştırır. Modeli, güvenlik mühendisleri tarafından gözden geçirilen veriler üzerinde eğitildiğinde açıkça daha etkili olsa da, önerilen model el ile türetilmiş bir kelime dağarcığını temel alır ve bu da onu insan kürasyonuna bağımlı hale getirir. Ayrıca, farklı kirlilik düzeylerinin modellerini nasıl etkilediği, farklı sınıflandırıcıların kirliliklere nasıl yanıt verdiği ve iki sınıftaki kirlilik performansı farklı şekilde etkileyip etkilemediğinin analizi yoktur.
Zou et. al [18] hata raporunun metinsel olmayan alanlarını (meta özellikler, örneğin zaman, önem derecesi ve öncelik) ve hata raporunun metin içeriğini (metinsel özellikler, özet alanlarındaki metin) içeren bir hata raporunda yer alan birden çok bilgi türünü kullanın. Bu özelliklere dayanarak, doğal dil işleme ve makine öğrenmesi teknikleri aracılığıyla SBRI'leri otomatik olarak tanımlamak için bir model oluşturur. [8] içinde yazarlar benzer bir analiz gerçekleştirir, ancak buna ek olarak denetimli ve denetimsiz makine öğrenmesi tekniklerinin performansını karşılaştırır ve modellerini eğitmek için ne kadar veri gerektiğini incelerler.
[2] makalesinde yazarlar, hataları açıklamalarına göre SBR veya NSBR (Güvenlikle İlgili Olmayan Hata Raporu) olarak sınıflandırmak için farklı makine öğrenmesi tekniklerini de keşfeder. TFIDF'ye dayalı veri işleme ve model eğitimi için bir işlem hattı önerir. Önerilen işlem hattını, sözcük torbalarını ve saf Bayes'i temel alan bir modelle karşılaştırır. Wijayasekara ve diğerleri. [16] ayrıca Gizli Etki Hatalarını (HBS) tanımlamak için sık kullanılan sözcüklere dayanarak her hata raporunun özellik vektörü oluşturmak için metin madenciliği tekniklerini kullandı. Yang ve diğerleri [17] Terim Sıklığı (TF) ve saf Bayes'in yardımıyla yüksek etkiye sahip hata raporlarını (örneğin SBR) tanımladı. [9] içinde yazarlar bir hatanın önem derecesini tahmin etmek için bir model önerir.
ETIKET KIRLILIĞI
Etiket kirliliği olan veri kümeleriyle ilgilenme sorunu kapsamlı bir şekilde incelenmiştir. Frenay ve Verleysen, farklı gürültülü etiket türlerini ayırt etmek için [6] içinde bir etiket kirliliği taksonomisi önerir. Yazarlar üç farklı kirlilik türü önerir: gerçek sınıftan ve örnek özelliklerinin değerlerinden bağımsız olarak oluşan etiket kirliliği; yalnızca gerçek etikete bağlı etiket kirliliği; yanıltma olasılığının özellik değerlerine de bağlı olduğu etiket kirliliği. Çalışmamızda ilk iki gürültü türünü inceliyoruz. Teorik açıdan bakıldığında etiket kirliliği, bazı belirli durumlar dışında genellikle modelin performansını [10] düşürür [14]. Genel olarak, sağlam yöntemler etiket kirliliğini ele almak için aşırı uyumdan kaçınmayı kullanır [15]. Sınıflandırmadaki gürültü etkilerinin incelenmesi daha önce uydu görüntü sınıflandırması [13], yazılım kalite sınıflandırması [4] ve tıbbi etki alanı sınıflandırması [12] gibi birçok alanda yapılmıştır. Bildigimiz kadarıyla, gürültülü etiketlerin SBR sınıflandırması sorunundaki etkilerinin kesin ölçümünü inceleyen yayımlanmış herhangi bir çalışma bulunmamaktadır. Bu senaryoda, gürültü düzeyleri, gürültü türleri ve performans düşüşü arasında kesin ilişki kurulmamıştır. Ayrıca, farklı sınıflandırıcıların kirlilik varlığında nasıl davrandığını anlamak faydalı olabilir. Daha genel olarak, gürültülü veri kümelerinin yazılım hata raporları bağlamında farklı makine öğrenmesi algoritmalarının performansı üzerindeki etkisini sistematik olarak gösteren herhangi bir çalışmadan haberimiz yoktur.
III. VERİ SETİ TANIMI
Veri kümemiz 1.073.149 hata başlığından oluşur ve bu başlıklardan 552.073'ü SBRI'lere, 521.076'sı NSBR'ye karşılık gelir. Veriler 2015, 2016, 2017 ve 2018 yıllarında Microsoft genelindeki çeşitli ekiplerden toplanmaktadır. Tüm etiketler imza tabanlı hata kontrol sistemleri veya insanlar tarafından etiketlenmiş olarak elde edildi. Veri kümemizdeki hata başlıkları, soruna genel bir bakışla birlikte yaklaşık 10 sözcük içeren çok kısa metinlerdir.
A. Veri Ön İşleme Her hata başlığını boş alanlara göre ayrıştırarak belirteç listesi elde ederiz. Her belirteç listesini aşağıdaki gibi işleriz:
Dosya yolu olan tüm belirteçleri kaldırma
Şu simgelerin bulunduğu belirteçleri bölün: { , (, ), -, }, {, [, ], }
Durdurma sözcüklerini , yalnızca sayısal karakterler tarafından oluşturulan belirteçleri ve tüm corpus içinde 5'ten az kez görünen belirteçleri kaldırın.
IV. METODOLOJİ
Makine öğrenmesi modellerimizi eğitme süreci iki ana adımdan oluşur: verileri özellik vektörlerine kodlama ve denetimli makine öğrenmesi sınıflandırıcılarını eğitme.
A. Özellik Vektörleri ve Makine Öğrenmesi Teknikleri
İlk bölüm, [2] içinde kullanıldığı gibi frequencyinverse belge sıklığı algoritması (TF-IDF) terimini kullanarak verileri özellik vektörlerine kodlamayı içerir. TF-IDF, terim sıklığını (TF) ve ters belge sıklığını (IDF) tartan bir bilgi alma tekniğidir. Her sözcüğün veya terimin ilgili TF ve IDF puanı vardır. TF-IDF algoritması, belgede kaç kez göründüğüne bağlı olarak söz konusu sözcüğün önemini atar ve daha da önemlisi, anahtar sözcüğün veri kümesindeki başlık koleksiyonu boyunca ne kadar uygun olduğunu denetler. Üç sınıflandırma tekniği eğittik ve karşılaştırdık: saf Bayes (NB), artırılmış karar ağaçları (AdaBoost) ve lojistik regresyon (LR). Bu teknikleri seçtik çünkü literatürdeki raporun tamamına göre güvenlik hatası raporlarını tanımlamayla ilgili görev için performans açısından iyi bir performans gösterildi. Bu sonuçlar, bu üç sınıflandırıcının destek vektör makinelerinden ve rastgele ormanlardan daha iyi performans gösterdiği bir ön analizde onaylandı. Denemelerimizde kodlama ve model eğitimi için scikit-learn kitaplığını kullanıyoruz.
B. Gürültü Türleri
Bu çalışmada incelenen gürültü, eğitim verilerindeki sınıf etiketindeki gürültüyü ifade eder. Bu tür gürültülerin varlığında, sonuç olarak, öğrenme süreci ve elde edilen model yanlış etiketlenmiş örnekler nedeniyle bozulur. Sınıf bilgilerine uygulanan farklı kirlilik düzeylerinin etkisini analiz ediyoruz. Daha önce literatürde çeşitli terminolojiler kullanılarak etiket kirliliği türleri ele alınmıştır. Çalışmamızda sınıflandırıcılarımızdaki iki farklı etiket kirliliğinin etkilerini analiz ediyoruz: örnekleri rastgele seçerek ve etiketlerini çevirerek ortaya çıkan sınıftan bağımsız etiket kirliliği; ve sınıfa bağımlı kirlilik; burada sınıflar gürültülü olma olasılığı farklıdır.
a) Sınıfından bağımsız kirlilik: Sınıftan bağımsız kirlilik, örneklerin gerçek sınıfından bağımsız olarak oluşan gürültüyü ifade eder. Bu kirlilik türünde, pbr yanlış etiketleme olasılığı, veri kümesindeki tüm örnekler için aynıdır. Sınıftan bağımsız gürültü ekleriz, veri kümemizdeki her etiketi pbrolasılığıyla rastgele değiştirerek.
b) Sınıfa bağımlı kirlilik: Sınıfa bağımlı kirlilik, örneklerin gerçek sınıfına bağlı olan gürültüyü ifade eder. Bu tür gürültüde, SBR sınıfında yanlış etiketleme olasılığı psbr ve NSBR sınıfında yanlış etiketleme olasılığı pnsbr'dir. Doğru etiketin SBR olduğu veri kümesindeki her girdiyi psbrolasılığıyla değiştirerek veri kümesine sınıfa bağımlı gürültü ekleriz. Benzer şekilde, pnsbrolasılığı olan NSBR örneklerinin sınıf etiketini çeviririz.
c) Tek sınıflı gürültü: Tek sınıflı gürültü, sınıfa bağlı gürültünün özel bir durumudur, burada pnsbr = 0 ve psbr> 0'dır. Sınıftan bağımsız gürültü için psbr = pnsbr = pbrolduğunu unutmayın.
C. Gürültü Oluşturma
Denemelerimiz SBR sınıflandırıcılarının eğitimindeki farklı kirlilik türlerinin ve düzeylerinin etkisini araştırır. Denemelerimizde veri kümesinin 25% test verileri, 10% doğrulama ve 65% eğitim verileri olarak ayarladık.
Farklı pbr, psbr ve pnsbr düzeyleri için eğitim ve doğrulama veri kümelerine gürültü ekliyoruz. Test veri kümesinde herhangi bir değişiklik yapmayız. Kullanılan farklı kirlilik düzeyleri P = {0,05 × i|0 < i < 10} şeklindedir.
Sınıftan bağımsız gürültü denemelerinde pbr ∈ P için aşağıdakileri yaparız:
Eğitim ve doğrulama veri kümeleri için gürültü oluşturma;
Eğitim veri kümesini (gürültü ile) kullanarak lojistik regresyon, saf Bayes ve AdaBoost modellerini eğitin; * Doğrulama veri kümesini (gürültü ile) kullanarak modelleri ayarlayın;
Test veri kümesini (gürültüsüz) kullanarak modelleri test edin.
Sınıfa bağlı kirlilik denemelerinde psbr ∈ P ve pnsbr ∈ P için psbr ve pnsbrtüm bileşimleri için aşağıdakileri yaparız:
Eğitim ve doğrulama veri kümeleri için gürültü oluşturma;
Eğitim veri kümesini (gürültü ile) kullanarak lojistik regresyon, naif Bayes ve AdaBoost modellerini eğitin.
Doğrulama veri kümesini (gürültüyle) kullanarak modelleri ayarlayın;
Test veri kümesini (gürültüsüz) kullanarak modelleri test edin.
V. DENEYSEL SONUÇLAR
Bu bölümde, bölüm IV'te açıklanan metodolojiye göre yapılan deneylerin sonuçlarını analiz edin.
a)eğitim veri kümesinde gürültü olmadan model performansı: Bu makalenin katkılarından biri, karar alma için yalnızca hata başlığını veri olarak kullanarak güvenlik hatalarını tanımlamak için bir makine öğrenmesi modeli teklifidir. Bu, geliştirme ekipleri hassas verilerin varlığı nedeniyle hata raporlarını tam olarak paylaşmak istemese bile makine öğrenmesi modellerinin eğitilmelerini sağlar. Yalnızca hata başlıkları kullanılarak eğitildiğinde üç makine öğrenmesi modeli performansını karşılaştırıyoruz.
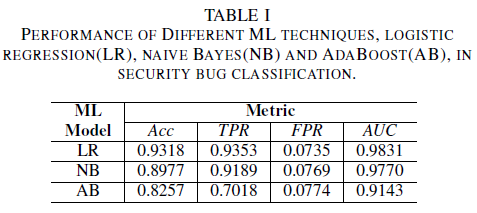
Lojistik regresyon modeli en iyi performans gösteren sınıflandırıcıdır. En yüksek AUC değeri olan 0,9826'ya sahip ve 0,0735 FPR değeri için 0,9353 hatırlama oranına sahip sınıflandırıcıdır. Naive Bayes Sınıflandırıcısı, FPR değeri 0.0769 iken, AUC değeri 0.9779 ve geri çağrım değeri 0.9189 ile lojistik regresyon Sınıflandırıcısından biraz daha düşük performans sunar. AdaBoost sınıflandırıcısı, daha önce bahsedilen iki sınıflandırıcıya kıyasla daha düşük bir performansa sahiptir. AUC değeri 0,9143, hatırlama oranı 0,7018 ve 0,0774 FPR için elde ediliyor. ROC eğrisinin (AUC) altındaki alan, TPR ile FPR ilişkisini tek bir değerde özetlediğinden, çeşitli modellerin performansını karşılaştırmak için iyi bir ölçümdür. Sonraki analizde karşılaştırmalı analizimizi AUC değerleriyle kısıtlayacağız.
A. Sınıf Gürültüsü: tek sınıf
Tüm hataların varsayılan olarak NSBR sınıfına atandığı ve hatanın yalnızca hata deposunu inceleyen bir güvenlik uzmanı varsa SBR sınıfına atanacağı bir senaryo hayal edilebilir. Bu senaryo, pnsbr = 0 ve 0 < psbr< 0.5 olduğunu varsaydığımız tek sınıflı deneysel ayarda temsil edilir.
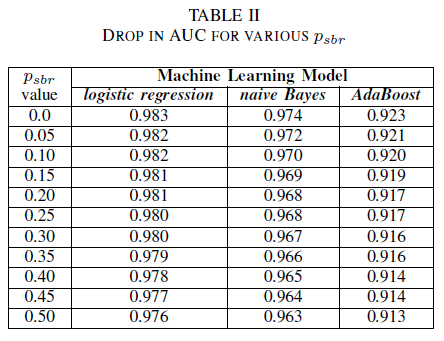
Tablo II'den, üç sınıflandırıcı için de AUC'de çok küçük bir etki gözlemliyoruz. psbr = 0 üzerinde eğitilmiş bir modeldeki AUC-ROC, psbr = 0,25 olan modeldeki AUC-ROC ile karşılaştırıldığında farklılıklar şöyle: lojistik regresyon için 0,003, naif Bayes için 0,006 ve AdaBoost için 0,006. psbr = 0,50 durumunda, her model için ölçülen AUC değeri, psbr = 0 modeline göre lojistik regresyon için 0,007, naif Bayes için 0,011, ve AdaBoost için 0,010 fark etmektedir. tek sınıf gürültü varlığında eğitilen lojistik regresyon sınıflandırıcısı, saf Bayes ve AdaBoost sınıflandırıcılarımıza kıyasla AUC ölçütünde en küçük varyasyonu, yani daha sağlam bir performans sunar.
B. Sınıf Gürültüsü: sınıftan bağımsız
Eğitim kümesinin sınıftan bağımsız bir gürültü ile bozulduğu durumda üç sınıflandırıcımızın performansını karşılaştırıyoruz. Eğitim verilerinde farklı pbr düzeyleriyle eğitilen her model için AUC'yi ölçüyoruz.
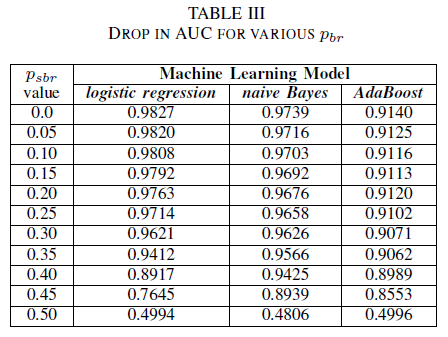
Tablo III'te, deneydeki her gürültü artışı için AUC-ROC'da bir düşüş gözlemliyoruz. Modelin gürültüsüz verilerle eğitilmesiyle elde edilen AUC-ROC, pbr = 0,25 ile sınıftan bağımsız gürültüyle eğitilmiş bir modelin AUC-ROC'i ile karşılaştırıldığında; lojistik regresyon için 0,011, naif Bayes için 0,008 ve AdaBoost için 0,0038 olarak farklılık gösterir. Kirlilik düzeyleri 40%'den düşük olduğunda etiket kirliliğinin naif Bayes ve AdaBoost sınıflandırıcılarının AUC'sini önemli ölçüde etkilemediğini gözlemliyoruz. Öte yandan, lojistik regresyon sınıflandırıcısının, 30%üzerindeki etiket kirliliği düzeylerinde AUC ölçüsünde etkilendiği gözlemlenir.
AUC Çeşitlemesi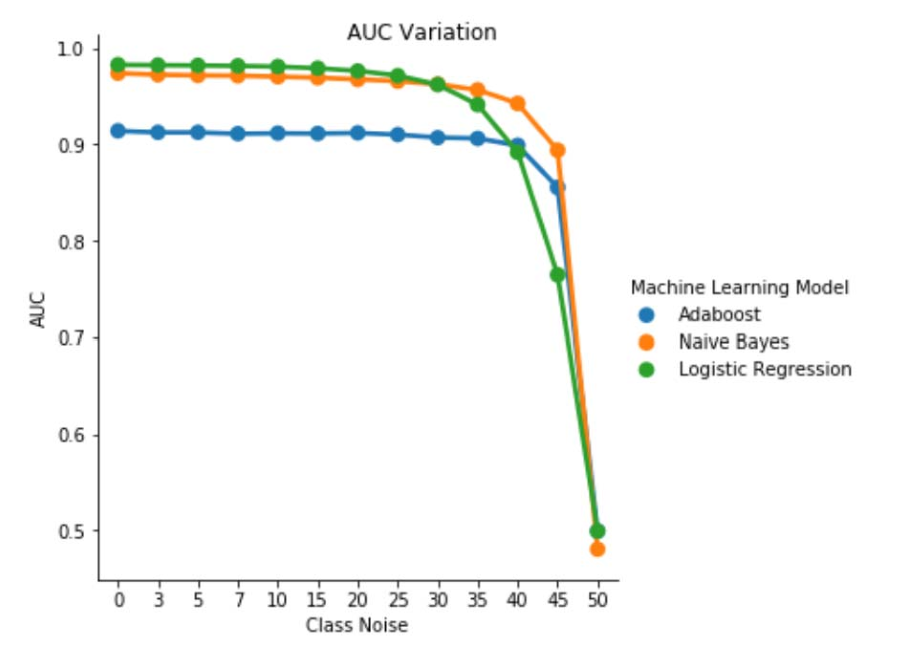 AUC Variation
AUC Variation
Şekil 1. Sınıftan bağımsız gürültüdeki AUC-ROC varyasyonu. Gürültü düzeyi pbr =0,5 için sınıflandırıcı rastgele bir sınıflandırıcı gibi davranır, örneğin AUC≈0,5. Ancak düşük kirlilik düzeyleri (pbr ≤0.30) için lojistik regresyon öğrenicisinin diğer iki modele kıyasla daha iyi bir performans sunduğunu gözlemleyebiliriz. Ancak, 0,35≤ pbr ≤0,45 aralığında, saf Bayes algoritması daha iyi AUCROC metrikleri sağlar.
C. Sınıf Kirliliği: sınıfa özgü
Denemelerin son kümesinde, farklı sınıfların farklı kirlilik düzeyleri içerdiği bir senaryoyu ele alıyoruz; örneğin psbr ≠ pnsbr. Eğitim verilerinde psbr ve pnsbr bağımsız olarak 0,05'e kadar sistematik olarak artırıyoruz ve üç sınıflandırıcının davranışındaki değişikliği gözlemliyoruz.
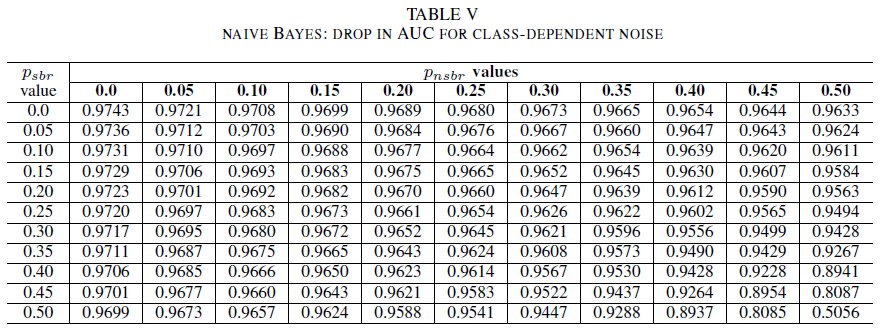
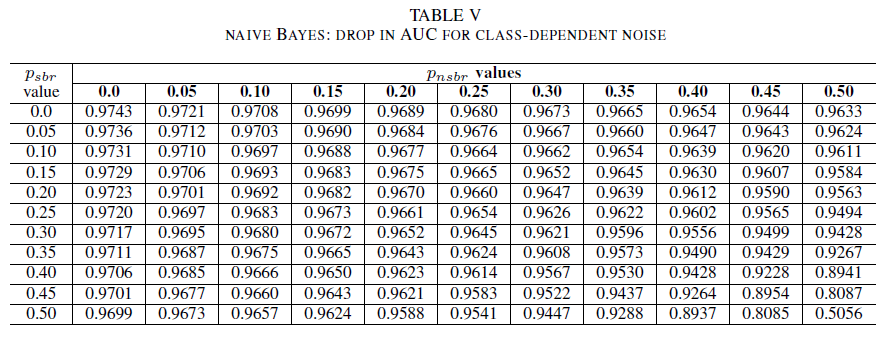
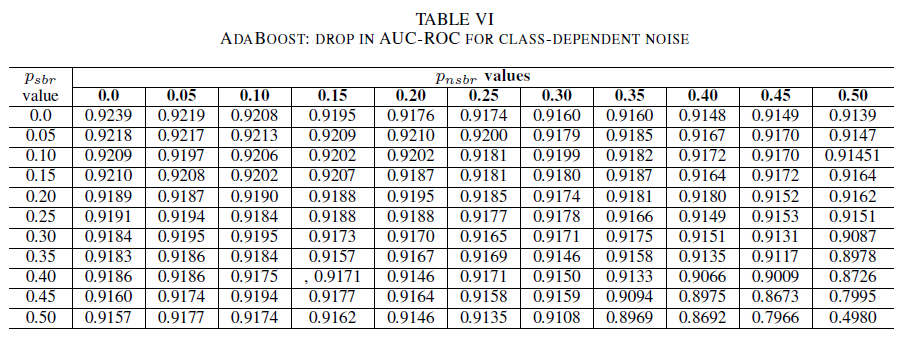
Tablo IV, V ve VI, sırasıyla Tablo IV'teki lojistik regresyon, Tablo V'deki naif Bayes ve Tablo VI'daki AdaBoost için her sınıfta artan gürültü seviyelerinde AUC'nin nasıl değiştiğini göstermektedir. Tüm sınıflandırıcılar için, her iki sınıf da 30%üzerinde gürültü seviyesi içerdiğinde AUC ölçümünde bir etki olduğunu fark ettik. naive Bayes daha dayanıklı davranır. Pozitif sınıftaki etiketlerin 50%'ı tersine çevrilse bile, negatif sınıf 30% veya daha az gürültülü etiket içeriyorsa, AUC üzerindeki etki çok küçüktür. Bu durumda AUC'deki düşüş 0,03'tür. AdaBoost, üç sınıflandırıcının da en sağlam davranışını sundu. AUC'de önemli bir değişiklik yalnızca her iki sınıfta da 45%'den büyük gürültü düzeyleri için gerçekleşir. Bu durumda, 0,02'den büyük bir AUC çürümesini gözlemlemeye başlarız.
D. Orijinal Veri Kümesinde Artık Gürültünün Varlığı Üzerine
Veri kümemiz imza tabanlı otomatik sistemler ve insan uzmanlar tarafından etiketlendi. Ayrıca, tüm hata raporları insan uzmanlar tarafından daha fazla gözden geçirilmiş ve kapatılmıştır. Veri kümemizdeki kirlilik miktarının en düşük düzeyde olmasını ve istatistiksel olarak önemli olmamasını beklesek de, artık kirlilik varlığı sonuçlarımızı geçersiz kılmaz. Aslında, örnek olması açısından, özgün veri kümesinin her giriş için 0 < p < 1/2 bağımsız ve aynı dağılıma sahip (i.i.d) olan sınıftan bağımsız bir gürültü ile bozulduğunu varsayalım.
Özgün gürültüye ek olarak pbr i.d olasılığına sahip sınıftan bağımsız bir kirlilik eklersek, girdi başına ortaya çıkan kirlilik p∗ = p(1 − pbr )+(1 − p)pbr olacaktır. 0 < p,pbr< 1/2 için etiket başına gerçek gürültü p∗, pbr veri kümesine yapay olarak eklediğimiz gürültüden kesinlikle daha büyüktür. Bu nedenle sınıflandırıcılarımızın performansı, ilk etapta tamamen gürültüsüz bir veri kümesi (p = 0) ile eğitilmeleri durumunda daha da iyi olacaktır. Özetle, gerçek veri kümesinde kalan gürültünün varlığı, sınıflandırıcılarımızın gürültüye karşı dayanıklılığının burada sunulan sonuçlardan daha iyi olduğu anlamına gelir. Ayrıca, veri kümemizdeki artık gürültü istatistiksel olarak anlamlı olsaydı, sınıflandırıcılarımızın AUC değeri, tam olarak 0,5'ten daha düşük bir gürültü düzeyi için 0,5 olurdu (rastgele bir tahmin). Sonuçlarımızda bu tür davranışlar gözlemlenmez.
VI. SONUÇLAR VE GELECEK ÇALIŞMALAR
Bu makaledeki katkımız iki kat daha fazla.
İlk olarak, yalnızca hata raporunun başlığına dayalı olarak güvenlik hata raporu sınıflandırmasının uygulanabilirliğini gösterdik. Bu özellikle gizlilik kısıtlamaları nedeniyle hata raporunun tamamının kullanılamadığı senaryolarda geçerlidir. Örneğin, bizim örneğimizde hata raporları parolalar ve şifreleme anahtarları gibi özel bilgiler içeriyordu ve sınıflandırıcıları eğitmeye uygun değildi. Elde edilen sonuç, yalnızca rapor başlıkları kullanılabilir olduğunda bile SBR tanımlamanın yüksek doğrulukta gerçekleştirilebileceğini gösteriyor. TF-IDF ve lojistik regresyonun birleşimini kullanan sınıflandırma modelimiz 0,9831 AUC'de performans gösterir.
İkincisi, yanlış etiketlenmiş eğitim ve doğrulama verilerinin etkisini analiz ettik. Farklı gürültü türlerine ve gürültü düzeylerine karşı sağlamlıkları açısından üç iyi bilinen makine öğrenmesi sınıflandırma tekniğini (saf Bayes, lojistik regresyon ve AdaBoost) karşılaştırdık. Üç sınıflandırıcı da tek sınıflı gürültüye dayanıklıdır. Eğitim verilerindeki kirlilik, sonuçta elde edilen sınıflandırıcıda önemli bir etkiye sahip değildir. AUC'deki azalma çok küçüktür (0,01) 50%gürültü seviyesi için. Her iki sınıfta da mevcut olan ve sınıftan bağımsız olan kirlilik için, naif Bayes ve AdaBoost modelleri AUC'de yalnızca 40%'den yüksek kirlilik düzeylerine sahip bir veri kümesiyle eğitildiğinde önemli varyasyonlar sunar.
Son olarak, sınıfa bağlı kirlilik AUC'yi yalnızca her iki sınıfta da 35% daha fazla kirlilik olduğunda önemli ölçüde etkiler. AdaBoost en sağlamlığı gösterdi. AUC üzerindeki etki, pozitif sınıfın etiketlerinin 50% gürültülü olması durumunda bile, negatif sınıfın 45% veya daha az gürültülü etiket içermesi koşuluyla çok küçüktür. Bu durumda AUC'deki düşüş 0,03'ten küçüktür. Bu, gürültülü veri kümelerinin güvenlik hata raporu belirlemeye etkisi üzerine yapılan ilk sistematik çalışmadır.
GELECEK ÇALIŞMALAR
Bu makalede, güvenlik hatalarının tanımlanması için makine öğrenmesi sınıflandırıcılarının performansındaki kirliliğin etkilerini sistematik olarak incelemeye başladık. Bu çalışmanın birkaç ilginç devamı vardır: gürültülü veri kümelerinin güvenlik hatalarının önem düzeyini belirlemedeki etkisini inceleme; sınıf dengesizliğini, eğitilen modellerin gürültüye karşı dayanıklılığı üzerindeki etkisini anlamak; veri kümesinde saldırgan bir şekilde ortaya çıkartılan kirliliğin etkisini anlama.
KAYNAKLAR
[1] John Anvik, Lyndon Hiew ve Gail C Murphy. Bu hatayı kim düzeltmelidir? Yazılım mühendisliği üzerine 28. uluslararası konferans bildirilerinde, sayfalar 361–370. ACM, 2006.
[2] Diksha Behl, Sahil Handa ve Anuja Arora. Naïve bayes ve tf-idf kullanarak güvenlik hatalarını tanımlamak ve analiz etmek için bir hata madenciliği aracı. Optimizasyon, Güvenilirlik ve Bilgi Teknolojisi (ICROIT), 2014 Uluslararası Konferansı’nda, sayfa 294-299. IEEE, 2014.
[3] Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann ve Sunghun Kim. Yinelenen hata raporları gerçekten zararlı olarak mı kabul ediliyor? Yazılım Bakımı, 2008. ICSM 2008. IEEE Uluslararası Konferansı'de, sayfalar 337–345. IEEE, 2008.
[4] Andres Folleco, Taghi M Khoshgoftaar, Jason Van Hulse ve Lofton Bullard. Düşük kaliteli verilere dayanıklı öğrencilerin tanımlanması. Bilgileri Yeniden Kullanma ve Tümleştirme bölümünde, 2008. IRI 2008. IEEE Uluslararası Konferansı'nda, sayfalar 190–195. IEEE, 2008.
[5] Benoˆıt Frenay.' Makine öğrenmesinde belirsizlik ve etiket kirliliği. Doktora tezi, Louvain Katolik Üniversitesi, Louvain-la-Neuve, Belçika, 2013.
[6] Benoˆıt Frenay ve Michel Verleysen. Etiket gürültüsü varlığında sınıflandırma: bir anket. sinir ağları ve öğrenme sistemleri üzerinde IEEE işlemleri, 25(5):845–869, 2014.
[7] Michael Gegick, Pete Rotella ve Tao Xie. Metin madenciliği aracılığıyla güvenlik hata raporlarını tanımlama: Endüstriyel örnek olay incelemesi. Madencilik yazılım depolarında (MSR), 2010 7. IEEE çalışma konferansı, sayfalar 11–20. IEEE, 2010.
[8] Katerina Goseva-Popstojanova ve Jacob Tyo. Denetimli ve denetimsiz sınıflandırma kullanılarak metin madenciliği yoluyla güvenlikle ilgili hata raporlarının belirlenmesi. 2018 IEEE Uluslararası Yazılım Kalitesi, Güvenilirlik ve Güvenlik Konferansı (QRS), sayfa 344–355, 2018.
[9] Ahmed Lamkanfi, Serge Demeyer, Emanuel Giger ve Bart Goethals. Bildirilen bir hatanın önem derecesini tahmin etme. Yazılım Deposu Madenciliği (MSR), 2010 7. IEEE Çalışma Konferansı, sayfa 1–10. IEEE, 2010.
[10] Naresh Manwani ve PS Sastry. Risk minimizasyonu altında gürültü toleransı. IEEE Sibernetik İşlemleri, 43(3):1146–1151, 2013.
[11] G Murphy ve D Cubranic. Metin kategorisini kullanarak otomatik hata önceliklendirmesi. On Altıncı Uluslararası Yazılım Mühendisliği Bilgi Mühendisliği Konferansı Bildirileri &. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen ve Oleksandr Pechenizkiy. Tıbbi alanlarda sınıf gürültüsü ve denetimli öğrenme: Özellik ayıklamanın etkisi. null, sayfa 708–713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre ve Gerard Dedieu.' Uydu görüntü zaman serisiyle kara örtüsü eşlemesi için eğitim sınıfı etiket gürültüsünün sınıflandırma performansları üzerindeki etkisi. Uzaktan Algılama, 9(2):173, 2017.
[14] PS Sastry, GD Nagendra ve Naresh Manwani. Yarım alanların gürültüye dayanıklı bir şekilde öğrenilmelerini sağlamak için süreklilik temelli öğrenme automata'larından oluşan bir ekip. IEEE Systems, Man ve Cybernetics Dergisi, Bölüm B (Sibernetik), 40(1):19–28, 2010.
[15] Choh-Man Teng. Gürültü işleme tekniklerinin karşılaştırması. FLAIRS Konferansı, sayfalar 269–273, 2001.
[16] Dumidu Wijayasekara, Milos Manic ve Miles McQueen. Metin madenciliği hata veritabanları aracılığıyla güvenlik açığı tanımlama ve sınıflandırma. Industrial Electronics Society, IECON 2014-40. IEEE Yıllık Konferansı, sayfalar 3612–3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia ve Jianling Sun. Dengesiz öğrenme stratejilerinden yararlanan yüksek etkili hata raporlarının otomatik olarak tanımlanması. Bilgisayar Yazılım ve Uygulamaları Konferansı'nda (COMPSAC), 2016 IEEE 40. Yıllık, cilt 1, sayfa 227–232. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Zhen Li ve Hai Jin. Çok türlü özellik analizi aracılığıyla güvenlik hata raporlarını otomatik olarak tanımlama. Avustralya ve Yeni Zelanda Bilgi Güvenliği ve Gizlilik Konferansı, sayfa 619–633. Springer, 2018.