Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
SQL Server 2012 ve 2014'te, SQL Server Always On kullanılabilirlik grubunda ikincil çoğaltma başlatmanın tek yolu yedekleme, kopyalama ve geri yükleme kullanmaktır. SQL Server 2016, bir ikincil çoğaltıyı başlatmak için yeni bir özellik sunar: otomatik çekirdek oluşturma. Otomatik başlatma, yapılandırılmış uç noktaları kullanarak, kullanılabilirlik grubundaki her veritabanı için yedeklemeyi VDI aracılığıyla ikincil çoğaltmaya aktarmak üzere günlük akışı aktarımını kullanır. Bu yeni özellik, bir kullanılabilirlik grubunun ilk oluşturulması sırasında veya veritabanına eklendiğinde kullanılabilir. Otomatik dağıtım, Always On kullanılabilirlik gruplarını destekleyen tüm SQL Server sürümlerindedir ve hem geleneksel kullanılabilirlik grupları hem de dağıtılmış kullanılabilirlik gruplarıyla kullanılabilir.
Security
Güvenlik izinleri, başlatılmakta olan çoğaltma türüne bağlı olarak değişir:
- Geleneksel bir kullanılabilirlik grubu için, ikincil replika kullanılabilirlik grubuna katılırken, kullanılabilirlik grubuna gerekli izinler verilmelidir. Transact-SQL'da komutunu
ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASEkullanın. - Oluşturulmakta olan çoğaltmanın veritabanlarının ikinci kullanılabilirlik grubunun birincil çoğaltması üzerinde bulunduğu bir dağıtılmış kullanılabilirlik grubu için, zaten birincil olduğundan ek izinler gerekmez. Ancak, ikinci kullanılabilirlik grubunda yalnızca bir çoğaltma varsa, ikincil kullanılabilirlik grubu adına
CREATE ANY DATABASEiznini verin; aksi takdirde otomatik tohumlama başarısız olabilir. - Dağıtılmış kullanılabilirlik grubunun ikinci kullanılabilirlik grubundaki ikincil çoğaltma için komutunu
ALTER AVAILABILITY GROUP [<2ndAGName>] GRANT CREATE ANY DATABASEkullanmanız gerekir. Bu ikincil çoğaltma, ikinci kullanılabilirlik grubunun birincil çoğaltmasından başlatılır.
Birincil replika üzerindeki performans ve işlem günlüğü etkileri
Otomatik tohumlama, veritabanının boyutuna, ağ hızına ve birincil ve ikincil çoğaltmalar arasındaki mesafeye bağlı olarak ikincil çoğaltma başlatmak için pratik olmayabilir veya olmayabilir. Örneğin, şu durumlarda:
- Veritabanı boyutu 5 TB'dir
- Ağ hızı 1 Gb/sn'dir
- İki site arasındaki mesafe 1000 mildir
Tam bant genişliği varsa 1 Gb/sn ağ 125 MB/sn sürekli aktarım hızı sağlayabilir. Bu örnekte, otomatik tohumlama 11 saatten fazla sürebilir. Uygulamada, ağ sinyalleri daha uzun mesafeler üzerinde azaldığından ve bağlantı ağdaki diğer kaynaklarla paylaşıldığından otomatik tohumlama işlemi daha yavaştır. Seeding sırasında, birincil replikadaki veritabanının işlem günlüğü büyümeyi sürdürür ve bu veritabanının otomatik tohumlama işlemi tamamlanana kadar kesilemez. İşlem günlüğü daha sonra bir işlem günlüğü yedeklemesi kullanılarak kesilebilir.
Otomatik tohumlama, en fazla beş veritabanını işleyebilen tek iş parçacıklı bir işlemdir. Tek iş parçacıklı çalışma, özellikle kullanılabilirlik grubu birden fazla veritabanı içeriyorsa performansı etkiler.
Sıkıştırma otomatik tohumlama için kullanılabilir, ancak varsayılan olarak devre dışıdır. Sıkıştırmayı etkinleştirmek, ağ bant genişliği kullanımını azaltır ve muhtemelen işlemi hızlandırır, ancak bunun karşılığında ek işlemci yükü oluşur. Otomatik tohumlama sırasında sıkıştırmayı kullanmak için izleme bayrağı 9567'yi etkinleştirin . Bkz. Kullanılabilirlik grubu için sıkıştırmayı ayarlama.
Disk düzeni
SQL Server 2016 ve öncesinde, veritabanının otomatik dağıtım tarafından oluşturulduğu klasör zaten mevcut olmalı ve birincil çoğaltmadaki yol ile aynı olmalıdır.
SQL Server 2017'de Microsoft, bir kullanılabilirlik grubuna katılan tüm çoğaltmalarda aynı veri ve günlük dosyası yolunu kullanmanızı önerir, ancak gerekirse farklı yollar kullanabilirsiniz. Örneğin, platformlar arası kullanılabilirlik grubunda bir SQL Server örneği Windows üzerinde, başka bir SQL Server örneği Linux'tadır. Farklı platformların farklı varsayılan yolları vardır. SQL Server 2017, farklı varsayılan yollara sahip SQL Server örneklerinde kullanılabilirlik grubu çoğaltmalarını destekler.
Aşağıdaki tablo, otomatik tohumlamayı destekleyen veri diski düzenlerine ilişkin örnekler sunar:
| Birincil örnek Varsayılan veri yolu |
İkincil örnek Varsayılan veri yolu |
Birincil örnek Kaynak dosya konumu |
İkincil örnek Hedef dosya konumu |
|---|---|---|---|
| c:\data\ | /var/opt/mssql/data/ | c:\data\ | /var/opt/mssql/data/ |
| c:\data\ | /var/opt/mssql/data/ | c:\data\group1\ | /var/opt/mssql/data/group1/ |
| c:\data\ | d:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | d:\data\group1\ |
Birincil ve ikincil çoğaltma veritabanı konumunun örnek varsayılan yolları olmadığı senaryolar bu değişiklik tarafından etkilenmez. İkincil çoğaltma dosya yollarının birincil çoğaltma dosya yollarıyla eşleşmesi gereksinimleri aynı kalır.
| Birincil örnek Varsayılan veri yolu |
İkincil örnek Varsayılan veri yolu |
Birincil örnek Dosya konumu |
İkincil örnek Dosya konumu |
|---|---|---|---|
| c:\data\ | c:\data\ | d:\group1\ | d:\group1\ |
| c:\data\ | c:\data\ | d:\data\ | d:\data\ |
| c:\data\ | c:\data\ | d:\data\group1\ | d:\data\group1\ |
Birincil ve ikincil çoğaltmalarda varsayılan ve varsayılan olmayan yolları karıştırırsanız, SQL Server 2017 önceki sürümlerden farklı davranır. Aşağıdaki tabloda SQL Server 2017 davranışı gösterilmektedir.
| Birincil örnek Varsayılan veri yolu |
İkincil örnek Varsayılan veri yolu |
Birincil örnek Dosya konumu |
SQL Server 2016 İkincil örnek Dosya konumu |
SQL Server 2017 İkincil örnek Dosya konumu |
|---|---|---|---|---|
| c:\data\ | d:\data\ | c:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | c:\data\group1\ | d:\data\group1\ |
SQL Server 2016 ve öncesinde davranışa dönmek için izleme bayrağı 9571'i etkinleştirin. İzleme bayraklarını etkinleştirme hakkında bilgi için bkz. DBCC TRACEON (Transact-SQL).
Otomatik tohumlama ile kullanılabilirlik grubu oluşturma
Transact-SQL veya SQL Server Management Studio (SSMS, sürüm 17 veya üzeri) ile otomatik tohumlama kullanarak bir kullanılabilirlik grubu oluşturursunuz. SSMS'de Kullanılabilirlik Grubu Sihirbazı'nı kullanmak için şu yönergeleri izleyin: 9. Adım'a gittiğinizde otomatik tohumlamanın ilk ve varsayılan seçenek olduğuna dikkat edin.
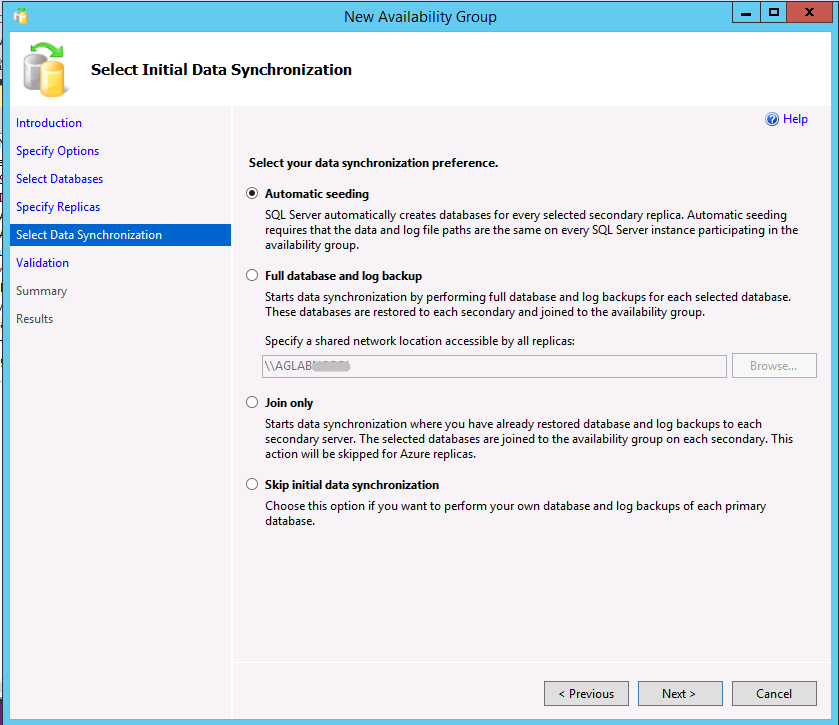
Aşağıdaki örnek, Transact-SQL kullanarak otomatik tohumlama ile bir kullanılabilirlik grubu oluşturur. Ayrıca Kullanılabilirlik Grubu Oluşturma (Transact-SQL) konusuna da bakın.
SEEDING_MODE seçeneği AUTOMATIC olarak ayarlanarak ikincil kopyada çekirdek oluşturma etkinleştirilir. Varsayılan davranış MANUAL’dır; bu, SQL Server 2016 öncesindeki davranıştır ve veritabanının bir yedeğinin birincil çoğaltmada alınmasını, yedek dosyasının ikincil çoğaltmaya kopyalanmasını ve yedeğin WITH NORECOVERY geri yüklenmesini gerektirir.
CREATE AVAILABILITY GROUP [<AGName>]
FOR DATABASE db1
REPLICA ON N'Primary_Replica'
WITH (
ENDPOINT_URL = N'TCP://Primary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT
),
N'Secondary_Replica' WITH (
ENDPOINT_URL = N'TCP://Secondary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
SEEDING_MODE = AUTOMATIC);
GO
Birincil çoğaltmada SEEDING_MODE ayarlanmasının, CREATE AVAILABILITY GROUP deyimi sırasında, hiçbir etkisi yoktur; çünkü birincil çoğaltma zaten veritabanının ana okuma/yazma kopyasını içerir.
SEEDING_MODE yalnızca başka bir çoğaltma birincil olarak ayarlandığında ve bir veritabanı eklendiğinde geçerli olur. Tohumlama modu daha sonra değiştirilebilir; bkz. bir replikanın tohumlama modunu değiştirme.
İkincil çoğaltmaya dönüşen bir örnekte, örnek katıldıktan sonra SQL Server Günlüğüne aşağıdaki ileti eklenir:
'AGName' kullanılabilirlik grubu için yerel kullanılabilirlik çoğaltmasına veritabanı oluşturma izni verilmemiştir, ancak
SEEDING_MODEolarakAUTOMATICdeğerine sahiptir. Birincil kullanılabilirlik çoğaltması tarafından tohumlanan veritabanlarının oluşturulmasına izin vermek içinALTER AVAILABILITY GROUP ... GRANT CREATE ANY DATABASEkullanın.
Kullanılabilirlik grubuna ikincil replika üzerinde veritabanı oluşturma izni verme
Birleştirdikten sonra, SQL Server'ın ikincil çoğaltma örneğinde veritabanları oluşturması için kullanılabilirlik grubuna izin tanıyın. Otomatik tohumlamanın çalışması için kullanılabilirlik grubunun veritabanı oluşturma iznine sahip olması gerekir.
Tip
Kullanılabilirlik grubu ikincil çoğaltma üzerinde bir veritabanı oluşturduğunda, "sa"yı (daha açık belirtmek gerekirse, SID değeri 0x01 olan hesabı) veritabanı sahibi olarak ayarlar.
İkincil çoğaltma otomatik olarak bir veritabanı oluşturduğunda veritabanı sahibini değiştirmek için kullanın ALTER AUTHORIZATION. Bkz ALTER AUTHORIZATION . (Transact-SQL).
Aşağıdaki örnek AGName adlı bir kullanılabilirlik grubuna bu izni verir.
ALTER AVAILABILITY GROUP [<AGName>]
GRANT CREATE ANY DATABASE
GO
Gerekirse ikincil kopyada veritabanı sahibini ayarlayın.
Otomatik çekirdeklemeyi doğrulayın
Başarılı olursa, veritabanı/veritabanları ikincil çoğaltmada aşağıdaki durumlardan biriyle otomatik olarak oluşturulur:
- SYNCHRONIZED, ikincil çoğaltma eşzamanlı olarak yapılandırılmışsa ve veri eşitlenmişse.
- EŞİTLENİYOR: İkincil çoğaltma asenkron veri hareketiyle yapılandırılmışsa veya senkron olarak yapılandırılmış ancak henüz birincil çoğaltmayla eşitlenmemişse.
Aşağıda açıklanan Dinamik Yönetim Görünümlerine ek olarak, otomatik tohumlamanın başlangıcı ve tamamlanması SQL Server Günlüğü'nde görülebilir:

Otomatik dağıtım ile yedekleme ve geri yükleme özelliklerini birleştirme
Geleneksel yedekleme, kopyalama ve geri yükleme özelliklerini otomatik dağıtımla birleştirmek mümkündür. Bu durumda, önce veritabanını kullanılabilir tüm işlem günlükleri de dahil olmak üzere ikincil bir çoğaltmaya geri yükleyin. Ardından, ikincil çoğaltmanın veritabanını sanki bir kuyruk günlüğü yedeği geri yüklenmiş gibi güncel duruma getirmek için, kullanılabilirlik grubunu oluştururken otomatik başlatmayı etkinleştirin (bkz. Kuyruk Günlüğü Yedeklemeleri (SQL Server)).
Otomatik tohumlama ile kullanılabilirlik grubuna veritabanı ekleme
Transact-SQL veya SQL Server Management Studio (SSMS, sürüm 17 veya üzeri) kullanarak otomatik çekirdek oluşturma kullanarak bir kullanılabilirlik grubuna veritabanı ekleyebilirsiniz.
İkincil çoğaltma, kullanılabilirlik grubuna eklendiğinde otomatik tohumlama kullandıysa ek bir işlem yapılmasına gerek yoktur. İkincil çoğaltma yedekleme, kopyalama ve geri yükleme kullandıysa, önce başlatma modunu değiştirin (bkz. sonraki bölüm) ve ardından veritabanını eklerken GRANT deyimini kullanın; bkz. Kullanılabilirlik Grubu - Veritabanı Ekleme.
Bir replikanın başlatma modunu değiştirme
Kullanılabilirlik grubu oluşturulduktan sonra bir replikanın tohumlama modu değiştirilebilir; böylece otomatik tohumlama etkinleştirilebilir veya devre dışı bırakılabilir. Oluşturma işleminden sonra otomatik tohumlamanın etkinleştirilmesi, veritabanının yedekleme, kopyalama ve geri yükleme ile oluşturulduysa otomatik tohumlama kullanılarak kullanılabilirlik grubuna eklenmesini sağlar. Örneğin:
ALTER AVAILABILITY GROUP [AGName]
MODIFY REPLICA ON 'Replica_Name'
WITH (SEEDING_MODE = AUTOMATIC)
Otomatik tohumlama özelliğini devre dışı bırakmak için MANUAL değerini kullanın.
Bir kullanılabilirlik grubu oluşturulduktan sonra otomatik tohumlamayı önleme
İkincil çoğaltma için otomatik tohumlama özelliğini tamamen devre dışı bırakmak istemiyorsanız ancak ikincil çoğaltmanın veritabanlarını otomatik olarak oluşturabilmesini geçici olarak engellemek istiyorsanız, kullanılabilirlik grubu OLUŞTURMA iznini reddedin. Bu, kullanılabilirlik grubuna yeni bir veritabanı eklendiğinde, ancak kullanılabilirlik grubunun veritabanını ikincil replika üzerinde oluşturmasına izin verilmemesi gerektiği durumdur.
ALTER AVAILABILITY GROUP [AGName]
DENY CREATE ANY DATABASE
GO
Otomatik tohumlama izleme
Otomatik tohumlama işlemini izlemenin ve sorunlarını gidermenin dört yolu vardır:
- SQL Server Günlüğü daha önce açıklandığı gibi
- Dinamik yönetim görünümleri
- Yedekleme geçmişi tabloları
- Genişletilmiş olaylar
Dinamik Yönetim Görünümleri
Seeding’i izlemek için iki dinamik yönetim görünümü (DMV) vardır: sys.dm_hadr_automatic_seeding ve sys.dm_hadr_physical_seeding_stats.
sys.dm_hadr_automatic_seedingotomatik tohumlamanın genel durumunu içerir ve her yürütülme zamanı için (başarılı olsun veya olmasın) geçmişi korur.current_statesütununun değeri ya TAMAMLANDI ya da BAŞARISIZ OLDU. Değer BAŞARISIZ ise, sorunu tanılamaya yardımcı olması için içindekifailure_state_descdeğerini kullanın. Neyin yanlış gittiğini görmek için bunu SQL Server Günlüğündekiyle birleştirmeniz gerekebilir. Bu DMV, birincil replikada ve tüm ikincil replikalarda veriyle doldurulur.sys.dm_hadr_physical_seeding_statsotomatik tohumlama işleminin yürütülürken durumunu gösterir.sys.dm_hadr_automatic_seedingile olduğu gibi, bu işlem hem birincil hem de ikincil çoğaltmalar için değerler döndürür, ancak bu geçmiş saklanmaz. Değerler yalnızca geçerli çalıştırma için geçerlidir ve saklanmaz. İlgili sütunlar arasındastart_time_utc,end_time_utc,estimate_time_complete_utc,total_disk_io_wait_time_msvetotal_network_wait_time_msyer alır; tohumlama işlemi başarısız olursa failure_message da buna dahildir.
Yedekleme geçmişi tabloları
Otomatik tohumlama ayrıca yedeklemeler ve geri yüklemeler için geçmişi depolayan tablolara msdb girdiler yerleştirir. Otomatik tohumlamayı alan ikincil replika üzerinde, backupmediafamily tablosundaki physical_device_name sütununun değeri bir GUID'dir ve backupset içindeki ilgili girdide, server_name ve machine_name için birincil replikanın adı yer alır.
Genişletilmiş olaylar
Otomatik tohumlama, başlatma sırasında durum değişikliğini, hataları ve performans istatistiklerini izlemek için yeni genişletilmiş olaylar ekler. Örneğin, aşağıdaki betik otomatik tohumlamayla ilgili olayları yakalayan genişletilmiş olaylar oturumu oluşturur.
CREATE EVENT SESSION [AlwaysOn_autoseed] ON SERVER
ADD EVENT sqlserver.hadr_automatic_seeding_state_transition,
ADD EVENT sqlserver.hadr_automatic_seeding_timeout,
ADD EVENT sqlserver.hadr_db_manager_seeding_request_msg,
ADD EVENT sqlserver.hadr_physical_seeding_backup_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_failure,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_target_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_progress,
ADD EVENT sqlserver.hadr_physical_seeding_restore_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_submit_callback
ADD TARGET package0.event_file(
SET filename=N'autoseed.xel',
max_file_size=(5),
max_rollover_files=(4)
)
WITH (
MAX_MEMORY=4096 KB,
EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY=30 SECONDS,
MAX_EVENT_SIZE=0 KB,
MEMORY_PARTITION_MODE=NONE,
TRACK_CAUSALITY=OFF,
STARTUP_STATE=ON
)
GO
ALTER EVENT SESSION AlwaysOn_autoseed ON SERVER STATE=START
GO
Aşağıdaki tabloda otomatik tohumlamayla ilgili genişletilmiş olaylar listeleniyor.
| Name | Description |
|---|---|
| hadr_db_manager_seeding_request_msg | Tohumlama istek iletisi. |
| hadr_physical_seeding_backup_state_change | Fiziksel tohumlama yedek taraf durum değişikliği. |
| hadr_physical_seeding_restore_state_change | Fiziksel tohumlama geri yükleme yan durum değişikliği. |
| hadr_physical_seeding_forwarder_state_change | Fiziksel tohumlama iletici tarafı durum değişikliği. |
| hadr_physical_seeding_forwarder_target_state_change | Fiziksel tohumlama ileticisi hedef tarafı durum değişikliği. |
| hadr_physical_seeding_submit_callback | Fiziksel tohumlama gönderim geri çağırım olayı. |
| hadr_physical_seeding_failure | Fiziksel tohumlama hatası olayı. |
| hadr_physical_seeding_progress | Fiziksel tohumlama ilerleme durumu olayı. |
| HADR_fiziksel_çekirdek_oluşturma_zamanlanmış_uzun_görev_başarısızlığı | Fiziksel tohumlama zamanlaması uzun görev hatası olayı. |
| hadr_automatic_seeding_start | Otomatik bir tohumlama işlemi gönderildiğinde gerçekleşir. |
| hadr_automatic_seeding_state_transition | Otomatik bir tohumlama işlemi durum değiştirdiğinde gerçekleşir. |
| hadr_automatic_seeding_success | Otomatik bir tohumlama işlemi başarılı olduğunda gerçekleşir. |
| hadr_automatic_seeding_failure | Otomatik bir tohumlama işlemi başarısız olduğunda gerçekleşir. |
| hadr_automatic_seeding_timeout | Otomatik bir tohumlama işlemi zaman aşımına uğradığında oluşur. |
Ayrıca bakınız
ALTER AVAILABILITY GROUP (Transact-SQL)
CREATE AVAILABILITY GROUP (Transact-SQL)
AlwaysOn Kullanılabilirlik Grupları Sorun Giderme ve İzleme Kılavuzu