Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Dağıtılmış kullanılabilirlik grubu (AG), iki ayrı kullanılabilirlik grubuna yayılan özel bir kullanılabilirlik grubu türüdür. Dağıtılmış kullanılabilirlik grupları SQL Server 2016'dan itibaren kullanılabilir.
Bu makalede, dağıtılmış kullanılabilirlik grubu özelliği açıklanmaktadır. Dağıtılmış kullanılabilirlik grubu yapılandırmak için bkz. Dağıtılmış kullanılabilirlik gruplarını yapılandırma.
Genel Bakış
Dağıtılmış kullanılabilirlik grubu, iki ayrı kullanılabilirlik grubuna yayılan özel bir kullanılabilirlik grubu türüdür. Dağıtılmış kullanılabilirlik grubuna katılan kullanılabilirlik gruplarının aynı konumda olması gerekmez. Bunlar fiziksel, sanal, şirket içi, genel bulutta veya kullanılabilirlik grubu dağıtımını destekleyen herhangi bir yerde olabilir. Buna, etki alanları arasında ve hatta bir platformdan diğerine geçiş içerecek şekilde, Linux üzerinde barındırılan bir kullanılabilirlik grubu ile Windows'da barındırılan bir kullanılabilirlik grubu arasında geçiş de dahildir. İki kullanılabilirlik grubu iletişim kurabildiği sürece, onlarla dağıtılmış bir kullanılabilirlik grubu yapılandırabilirsiniz.
Geleneksel bir kullanılabilirlik grubu, Windows Server Yük Devretme Kümesinde (WSFC) veya Linux üzerinde Pacemaker'da yapılandırılmış kaynaklara sahiptir. Dağıtılmış kullanılabilirlik grubu, temel alınan kümede (WSFC veya Pacemaker) hiçbir şey yapılandırmaz. Bununla ilgili her şey SQL Server'da tutulur. Dağıtılmış kullanılabilirlik grubu bilgilerini görüntülemeyi öğrenmek için bkz. Dağıtılmış kullanılabilirlik grubu bilgilerini görüntüleme.
Dağıtılmış kullanılabilirlik grubu, temel alınan kullanılabilirlik gruplarının bir dinleyiciye sahip olmasını gerektirir. Geleneksel kullanılabilirlik grubuyla yaptığınız gibi tek başına bir örneğin temel sunucu adını (veya SQL Server yük devretme kümesi örneği [FCI], ağ adı kaynağıyla ilişkili değer) sağlamak yerine, dağıtılmış kullanılabilirlik grubu için yapılandırılan dinleyiciyi oluştururken ENDPOINT_URL parametresiyle belirtirsiniz. Dağıtılmış kullanılabilirlik grubunun temel alınan her kullanılabilirlik grubunun bir dinleyicisi olmasına rağmen, dağıtılmış kullanılabilirlik grubunun kendi dinleyicisi yoktur.
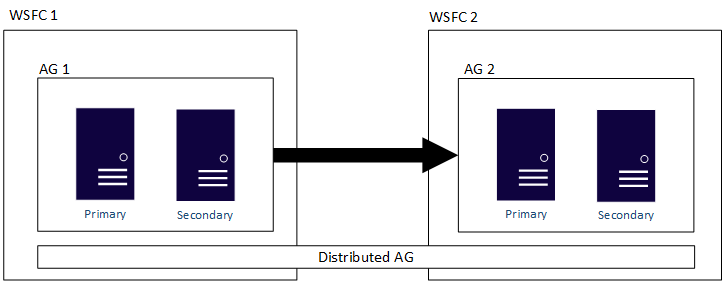
Aşağıdaki şekilde, her biri kendi WSFC'sinde yapılandırılmış iki kullanılabilirlik grubuna (AG 1 ve AG 2) yayılan bir dağıtılmış kullanılabilirlik grubunun üst düzey görünümü gösterilmektedir. Dağıtılmış kullanılabilirlik grubunun toplam dört çoğaltması vardır, her kullanılabilirlik grubunda ikişer tane bulunur. Her kullanılabilirlik grubu en fazla çoğaltma sayısını destekleyebilir, bu nedenle dağıtılmış bir kullanılabilirlik grubunun toplam çoğaltma sayısı 18'e kadar olabilir.
Dağıtılmış kullanılabilirlik gruplarında veri taşımayı zaman uyumlu veya zaman uyumsuz olarak yapılandırabilirsiniz. Ancak, dağıtılmış kullanılabilirlik gruplarında veri taşıma işlemi geleneksel kullanılabilirlik grubuyla karşılaştırıldığında biraz farklıdır. Her kullanılabilirlik grubunun birincil çoğaltması olsa da, dağıtılmış kullanılabilirlik grubuna katılan ve eklemeleri, güncelleştirmeleri ve silmeleri kabul edebilen veritabanlarının yalnızca bir kopyası vardır. Aşağıdaki şekilde gösterildiği gibi AG 1 birincil kullanılabilirlik grubudur. Birincil çoğaltma, işlemleri hem AG 1'in ikincil çoğaltmalarına hem de AG 2'nin birincil çoğaltmasına gönderir. AG 2'nin birincil çoğaltması, iletici olarak da bilinir. Dağıtılmış bir kullanılabilirlik grubunda, iletici ikincil kullanılabilirlik grubundaki birincil örnektir. İletici, birincil kullanılabilirlik grubundaki birincil çoğaltmadan işlemleri alır ve bunları kendi kullanılabilirlik grubu içerisindeki ikincil çoğaltmalara iletir. Daha sonra iletici, AG 2'nin ikincil çoğaltmalarını güncel tutar.
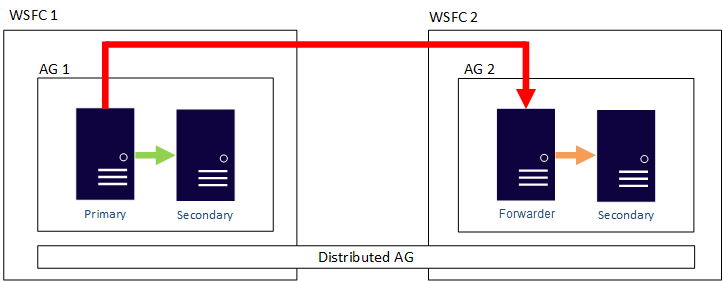
AG 2'nin birincil çoğaltmasının ekleri, güncellemeleri ve silmeleri kabul etmesini sağlamanın tek yolu, dağıtılmış yüksek kullanılabilirlik grubunu AG 1'den el ile geçiş yapmaktır. Önceki şekilde, AG 1 veri kümesinin yazılabilir kopyasını içerdiğinden, yük devretme talebi AG 2'yi ekleme, güncelleme ve silme işlemlerini yapabilen kullanılabilirlik grubu yapar. Bir dağıtılmış kullanılabilirlik grubunun yükünü diğerine devretme hakkında bilgi için bkz. İkincil kullanılabilirlik grubuna yük devretme.
Uyarı
- SQL Server 2016'daki dağıtılmış kullanılabilirlik grupları, seçeneğini
FORCE_FAILOVER_ALLOW_DATA_LOSSkullanarak yalnızca bir kullanılabilirlik grubundan diğerine yük devretmeyi destekler. - Dağıtılmış kullanılabilirlik gruplarıyla işlem çoğaltması kullanılırken yönlendirici kopya yayımcı olarak yapılandırılamaz.
SQL Server 2025 değişiklikleri
SQL Server 2025 (17.x) aşağıdaki değişiklikleri tanıtır:
Dağıtılmış AG senkronizasyonunda iyileştirme
SQL Server 2025 (17.x), ara sunucu replikası asenkron taahhüt modundayken ağ doygunluğunu azaltarak eşitleme performansını geliştirmek amacıyla dağıtılmış kullanılabilirlik grupları için iç eşitleme mekanizmasında bir değişiklik sunar. Bu değişiklik varsayılan olarak etkindir ve herhangi bir yapılandırma gerektirmez.
Uyarı
Dağıtılmış kullanılabilirlik grubunuzu, temel alınan iki kullanılabilirlik grubunun kullanılabilirlik modları arasında bir uyuşmazlık ile yapılandırmanız önerilmez ve eşitleme gecikmesine neden olabilir. En iyi performansı ve eşitlemeyi sağlamak için her iki kullanılabilirlik grubu da aynı kullanılabilirlik moduyla (zaman uyumlu veya zaman uyumsuz) yapılandırılmalıdır.
Kapsanan kullanılabilirlik grubu desteği
SQL Server 2025 (17.x), dağıtılmış bir kapsanan kullanılabilirlik grubu için destek sağlar. Dağıtılmış kullanılabilirlik grubunda iletici olarak bir contained AG kullanmayı planlıyorsanız, contained AG'yi CREATE AVAILABILITY GROUP komutunun WITH | CONTAINED seçeneği için AUTOSEEDING_SYSTEM_DATABASES yan tümcesini kullanarak oluşturmanız gerekir.
Sürüm ve sürüm gereksinimleri
SQL Server 2017 veya sonraki sürümlerindeki dağıtılmış kullanılabilirlik grupları, SQL Server'ın ana sürümlerini aynı dağıtılmış kullanılabilirlik grubunda karıştırabilir. Okuma/yazma birincilini içeren AG, dağıtılmış AG'ye katılan diğer AG'lerden aynı sürüm veya daha düşük olabilir. Diğer AG'ler aynı sürüm veya üzeri olabilir. Bu senaryo yükseltme ve geçiş senaryolarına yöneliktir. Örneğin, okuma/yazma birincil çoğaltmasını içeren AG SQL Server 2016 ise ancak SQL Server 2017 veya sonraki bir sürümüne yükseltmek/geçirmek istiyorsanız, dağıtılmış AG'ye katılan diğer AG SQL Server 2017 ile yapılandırılabilir.
Dağıtılmış kullanılabilirlik grupları özelliği SQL Server 2012 veya 2014'te mevcut olmadığından, bu sürümlerle oluşturulan kullanılabilirlik grupları dağıtılmış kullanılabilirlik gruplarına katılamaz.
Uyarı
SQL Server sürümüne bağlı olarak, Azure hizmetlerine ( Yönetilen Örnek bağlantısı gibi) bağlanırken, Standart sürüm veya Standart ve Enterprise sürümlerinin bir karışımı ile dağıtılmış bir kullanılabilirlik grubu yapılandırmak mümkündür. Daha fazla bilgi edinmek için KB5016729 gözden geçirin.
İki ayrı kullanılabilirlik grubu bulunduğundan, dağıtılmış kullanılabilirlik grubuna katılan bir eşlemeye hizmet paketi veya toplu güncelleştirme yükleme işlemi, geleneksel kullanılabilirlik grubundakinden daha farklıdır.
Dağıtılmış kullanılabilirlik grubundaki ikinci kullanılabilirlik grubunun çoğaltmalarını güncelleştirerek başlayın.
Dağıtılmış kullanılabilirlik grubunda birincil kullanılabilirlik grubunun çoğaltmalarına düzeltme ekini uygulayın.
Standart bir kullanılabilirlik grubunda olduğu gibi, birincil kullanılabilirlik grubunun yükünü kendi çoğaltmalarından birine (ikinci kullanılabilirlik grubunun birinciline değil) devredip düzeltme eki uygular. Birincil dışında başka bir kopya yoksa, ikinci kullanılabilirlik grubuna el ile yük devretme gerekmektedir.
Windows Server sürümleri ve dağıtılmış kullanılabilirlik grupları
Dağıtılmış kullanılabilirlik grubu, her biri kendi temel WSFC'sine sahip birden çok kullanılabilirlik grubuna yayılır ve dağıtılmış kullanılabilirlik grubu yalnızca SQL Server yapısıdır. Bu, tek tek kullanılabilirlik gruplarını barındıran WSFC'lerin Windows Server'ın farklı ana sürümlerine sahip olabileceği anlamına gelir. SQL Server'ın ana sürümleri, önceki bölümde açıklandığı gibi aynı olmalıdır. Aşağıdaki şekilde, ilk şekilde olduğu gibi AG 1 ve AG 2'nin dağıtılmış bir kullanılabilirlik grubuna katıldığı gösterilmektedir, ancak WSC'lerin her biri Windows Server'ın farklı bir sürümüdür.
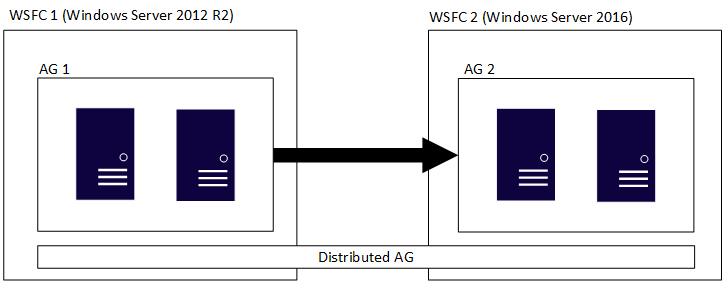
Tek tek WSC'ler ve ilgili kullanılabilirlik grupları geleneksel kurallara uyar. Yani, bir etki alanına katılabilir veya bir etki alanına (Windows Server 2016 veya üzeri) katılamayabilirler. İki farklı kullanılabilirlik grubu tek bir dağıtılmış kullanılabilirlik grubunda birleştirildiğinde dört senaryo vardır:
- Her iki WSFC de aynı etki alanına katılır.
- Her WSFC farklı bir etki alanına katılır.
- Bir WSFC bir etki alanına katılır ve bir WSFC bir etki alanına katılmaz.
- Hiçbir WSFC etki alanına katılmamıştır.
her iki WSC de aynı etki alanına (güvenilen etki alanları değil) katıldığında, dağıtılmış kullanılabilirlik grubunu oluştururken özel bir şey yapmanız gerekmez. Aynı etki alanına katılmamış kullanılabilirlik grupları ve WSFC'ler için, dağıtılmış kullanılabilirlik grubunun çalışmasını sağlamak için, etki alanı bağımsız bir kullanılabilirlik grubu için bir kullanılabilirlik grubu oluşturabileceğiniz şekilde sertifikaları kullanın. Dağıtılmış kullanılabilirlik grubu için sertifikaların nasıl yapılandırıldığını görmek için Etki alanı bağımsız kullanılabilirlik grubu oluşturma altında 3-13 arası adımları izleyin.
Dağıtılmış kullanılabilirlik grubunda, her bir kullanılabilirlik grubundaki birincil çoğaltmalar birbirlerinin sertifikalarına sahip olmalıdır. Sertifika kullanmayan uç noktalarınız zaten varsa, sertifika kullanımını yansıtmak için kullanarak ALTER ENDPOINT bu uç noktaları yeniden yapılandırın.
Kullanım senaryoları
Dağıtılmış kullanılabilirlik grubu için üç ana kullanım senaryosu aşağıdadır:
- Olağanüstü durum kurtarma ve daha kolay çoklu site yapılandırmaları
- Yeni donanım veya yapılandırmalara geçiş; bu, yeni donanım kullanmayı veya temel işletim sistemlerini değiştirmeyi içerebilir
- Birden çok kullanılabilirlik grubunu kapsayan tek bir kullanılabilirlik grubunda okunabilir çoğaltma sayısını sekizden fazla artırma
Olağanüstü durum kurtarma ve çok siteli senaryolar
Geleneksel kullanılabilirlik grubu, tüm sunucuların aynı WSFC'nin parçası olmasını gerektirir ve bu da birden çok veri merkezini yayma işlemini zorlaştırabilir. Aşağıdaki şekilde, veri akışı dahil olmak üzere geleneksel bir çok siteli kullanılabilirlik grubu mimarisinin nasıl göründüğü gösterilmektedir. Tüm ikincil çoğaltmalara işlem gönderen bir birincil çoğaltma vardır. Bu yapılandırma, bazı yönlerden dağıtılmış bir kullanılabilirlik grubuna göre daha az kapsamlıdır. Örneğin, WSFC'de nitelikli çoğunluk için gerekirse Active Directory gibi öğeler ve tanık kurmanız gerekir. WSFC'nin diğer yönlerini, örneğin düğüm oylarını değiştirmeyi de dikkate almanız gerekebilir.

Dağıtılmış kullanılabilirlik grupları, birden çok veri merkezine yayılan kullanılabilirlik grupları için daha esnek bir dağıtım senaryosu sunar. Geçmişte olağanüstü durum kurtarma gibi senaryolar için günlük gönderimi gibi özelliklerin kullanıldığı senaryolarda, dağıtılmış kullanılabilirlik gruplarını bile kullanabilirsiniz. Ancak, log shipping'in aksine, dağıtılmış kullanılabilirlik grupları işlemlerin gecikmeli uygulamasını desteklemez. Bu, verilerin yanlış güncelleştirildiği veya silindiği insan hatası durumunda kullanılabilirlik gruplarının veya dağıtılmış kullanılabilirlik gruplarının yardımcı olabileceği anlamına gelir.
Dağıtılmış kullanılabilirlik grupları gevşek bir şekilde birleştirilmiştir ve bu durumda tek bir WSFC gerektirmedikleri ve SQL Server tarafından tutulacakları anlamına gelir. WSFC'ler ayrı ayrı tutulacağından ve iki kullanılabilirlik grubu arasında eşitleme temelde zaman uyumsuz olduğundan, başka bir sitede olağanüstü durum kurtarmayı yapılandırmak daha kolaydır. Her kullanılabilirlik grubundaki ana çoğaltmalar kendi ikincil çoğaltmalarını senkronize eder.
- Dağıtılmış kullanılabilirlik grubu için yalnızca manuel yük devretme desteklenir. Veri merkezlerini değiştirdiğiniz bir afet kurtarma durumunda, otomatik geçişi yapılandırmamalısınız (nadir istisnalar dışında).
- Büyük olasılıkla CrossSubnetThreshold gibi çok siteli veya alt ağ WSFC'leri için bazı geleneksel öğeleri veya parametreleri ayarlamanız gerekmez, ancak yine de veri aktarımı için farklı bir katmanda ağ gecikmesi hakkında bilgi sahibi olmanız gerekir. Fark, her WSFC'nin kendi kullanılabilirliğini korumasıdır; küme, dört düğümden oluşan büyük bir varlık değildir. Önceki şekilde gösterildiği gibi iki ayrı iki düğümlü WSFC'niz vardır.
- Felaket kurtarma amacı taşıdığından dolayı zaman uyumsuz veri taşıma yaklaşımını öneririz.
- Birincil çoğaltma ile ikinci kullanılabilirlik grubunun en az bir ikincil çoğaltması arasında zaman uyumlu veri taşımayı yapılandırırsanız ve dağıtılmış kullanılabilirlik grubunda zaman uyumlu taşımayı yapılandırırsanız, dağıtılmış kullanılabilirlik grubu tüm zaman uyumlu kopyalar verilerin bulunduğunu onaylayana kadar bekler. Birden çok dağıtılmış kullanılabilirlik grubu birbirine bağlanarak bir zincir oluşturduysa (AG1 -> AG2 -> AG3) ve eşzamanlı olarak ayarlandıysa, dağıtılmış bir kullanılabilirlik grubu, en son kullanılabilirlik grubunun son çoğaltması güncelleştirilene kadar bekler.
Göçmek
Dağıtılmış kullanılabilirlik grupları tamamen farklı iki kullanılabilirlik grubu yapılandırmasını desteklediği için, yalnızca daha kolay olağanüstü durum kurtarma ve çok siteli senaryoları değil, aynı zamanda geçiş senaryolarını da etkinleştirir. İster yeni donanıma ister sanal makinelere (genel bulutta şirket içi veya IaaS) geçiş yapın, dağıtılmış kullanılabilirlik grubu yapılandırmak, geçmişte yedekleme, kopyalama ve geri yükleme veya günlük gönderimi kullanmış olabileceğiniz bir geçişin gerçekleşmesine olanak tanır.
Geçiş özelliği, aynı SQL Server sürümünü tutarken temel işletim sistemini değiştirdiğiniz veya yükselttiğiniz senaryolarda özellikle yararlıdır. Windows Server 2016 aynı donanımda Windows Server 2012 R2'den sıralı yükseltmeye izin vermese de, kullanıcıların çoğu yeni donanım veya sanal makineler dağıtmayı tercih eder.
Yeni yapılandırmaya geçişi tamamlamak için, işlemin sonunda tüm veri trafiğini özgün kullanılabilirlik grubuna durdurun ve dağıtılmış kullanılabilirlik grubunu zaman uyumlu veri taşıma olarak değiştirin. Bu eylem, ikinci kullanılabilirlik grubunun birincil çoğaltmasının tamamen eşitlenmesini sağlar, bu nedenle veri kaybı olmaz. Eşitleme doğrulandıktan sonra, dağıtılmış kullanılabilirlik grubunu ikincil kullanılabilirlik grubuna aktarın. Daha fazla bilgi için bkz. İkincil kullanılabilirlik grubuna yük devretme.
İkinci kullanılabilirlik grubunun artık yeni birincil kullanılabilirlik grubu olduğu geçiş sonrası, aşağıdaki adımlardan birini yapmanız gerekebilir:
- İkincil kullanılabilirlik grubundaki dinleyiciyi yeniden adlandırın (ve büyük olasılıkla özgün birincil kullanılabilirlik grubunda eskisini silin veya yeniden adlandırın) ya da uygulamaların ve kullanıcıların yeni yapılandırmaya erişebilmesi için özgün birincil kullanılabilirlik grubundan dinleyiciyle yeniden oluşturun.
- Yeniden adlandırma veya yeniden oluşturma mümkün değilse, uygulamaları ve kullanıcıları ikinci kullanılabilirlik grubundaki dinleyiciye yöneltin.
Daha yüksek SQL Server sürümlerine geçiş
Geçiş senaryosu sırasında, veritabanlarınızı kaynaktan daha yüksek bir sürüme sahip bir SQL Server hedefine geçirmek için dağıtılmış bir AG yapılandırmak mümkün olsa da, birkaç sınırlama vardır.
Dağıtılmış AG'yi kaynaktan daha yüksek bir sürüme sahip bir SQL Server geçiş hedefi ile yapılandırdığınızda, otomatik sağlama desteklenmez, bu nedenle dağıtım modunun olarak MANUALayarlanması gerekir. AUTO-SEEDING'i devre dışı bırakmazsanız, geçiş başarısız olur ve şu hatayı görürsünüz: 946 " 'DistributionAG' veritabanı sürümü xxx açılamıyor." Hata günlüğünde veritabanını en son sürüme yükseltin". Tohumlama modunu MANUAL olarak ayarlamanız ve birincil AG'den kaynak veritabanının tam ve işlem günlüğü yedeklemesini el ile gerçekleştirmeniz gerekir. Ardından işlem günlüğüyle birlikte ikincil AG'ye el ile geri yükleyin. Daha fazla bilgi edinmek için, dağıtılmış AG'nizi yapılandırmak için el ile dağıtım adımlarını ve veritabanınızı birincil AG'den ikincil AG'ye yedeklemek ve geri yüklemek için betikleri gözden geçirin.
İkincil AG'nin (AG2) geçiş hedefi olduğunu ve birincil AG'den (AG1) daha yüksek bir sürüm olduğunu varsayarsak, aşağıdaki sınırlamaları göz önünde bulundurun:
- Birincil AG daha düşük bir sürümde olduğu sürece ikincil AG'deki çoğaltma veritabanlarından hiçbirine okuma erişiminiz olmaz.
- Bu süre boyunca güncelleştirmeler Birincil AG'den (AG1) İkincil AG'ye (AG2) akmaya devam eder, ancak İkincil AG'nin durumu Kısmen İyi Durumda olarak gösterilir ve İkincil AG'nin (AG2) ikincil kopyalarındaki veritabanları Eşitleme/Kurtarmada (AG senkronize durumda olsa bile) olarak gösterilir.
- Dağıtılmış AG daha yüksek sürüme (AG2) devredildikten sonra AG2 sağlıklı hale gelmelidir.
- Bu süre boyunca AG1'e yeniden çalışma, daha düşük bir sürümde olduğu için mümkün olmayacaktır.
- AG1 daha düşük bir sürümde olduğundan AG2'ye yük devretme sonrasında AG2 güncelleştirmeleri AG1'e çoğaltılamaz.
- Buradan, özgün (birincil) AG'yi devreden çıkarmak mı yoksa AG1'i yükseltmek ve dağıtılmış AG'yi sürdürmek mi istediğinizi seçin.
- AG1'i devreden çıkarmayı seçerseniz, özgün birincil AG'yi dağıtılmış AG'den kaldırın ve işlem tamamlanır.
- Dağıtılmış AG'nin bakımını yapmayı seçerseniz AG1 için SQL Server sürümünü AG2 ile eşleşecek şekilde yükseltin. AG1 yükseltildikten sonra, AG1 sağlıklı duruma gelir, dağıtılmış AG sağlıklı olur, replikalar eşitlemeye yetişir ve geri dönme mümkün hale gelir.
Okunabilir çoğaltmaların ölçeğini genişletme
Tek bir dağıtılmış kullanılabilirlik grubunun gerektiğinde en fazla 16 ikincil çoğaltması olabilir. Bu nedenle, farklı kullanılabilirlik gruplarının iki birincil kopyası da dahil olmak üzere okuma için en fazla 18 kopya bulundurma kapasitesine sahip olabilir. Bu yaklaşım, birden fazla sitenin çeşitli uygulamalara raporlama için neredeyse gerçek zamanlı erişime sahip olabileceği anlamına gelir.
Dağıtılmış kullanılabilirlik grupları, salt okunur yapılandırmaları tek bir kullanılabilirlik grubuyla genişletebileceğinizden daha fazla genişletmenize olanak tanır. Dağıtılmış kullanılabilirlik grubu, okunabilir replikaların ölçeğini iki şekilde genişletebilir.
- İkinci kullanılabilirlik grubunun birincil çoğaltmasını bir dağıtılmış kullanılabilirlik grubu içinde kullanarak veritabanı KURTARMA'da olmasa bile başka bir dağıtılmış kullanılabilirlik grubu oluşturabilirsiniz.
- Ayrıca, başka bir dağıtılmış kullanılabilirlik grubu oluşturmak için ilk kullanılabilirlik grubunun birincil çoğaltmasını da kullanabilirsiniz.
Başka bir deyişle, birincil kopya farklı dağıtılmış kullanılabilirlik gruplarına katılabilir. Aşağıdaki şekilde, AG 1 ve AG 2'nin her ikisi de Distributed AG 1'e, AG 2 ve AG 3 ise Distributed AG 2'ye katılırken gösterilmektedir. AG 2'nin birincil kopyası (veya ileticisi), hem Dağıtılmış AG 1 için ikincil bir kopyadır hem de Dağıtılmış AG 2 için birincil bir kopyadır.
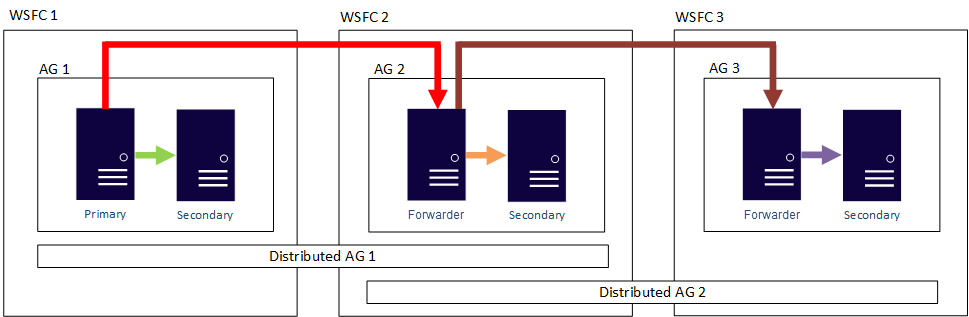
Aşağıdaki şekilde AG 1, iki farklı dağıtılmış kullanılabilirlik grubu için birincil çoğaltma olarak gösterilmektedir: Dağıtılmış AG 1 (AG 1 ve AG2'nin oluşturduğu) ve Dağıtılmış AG 2 (AG 1 ve AG 3'ün oluşturduğu).
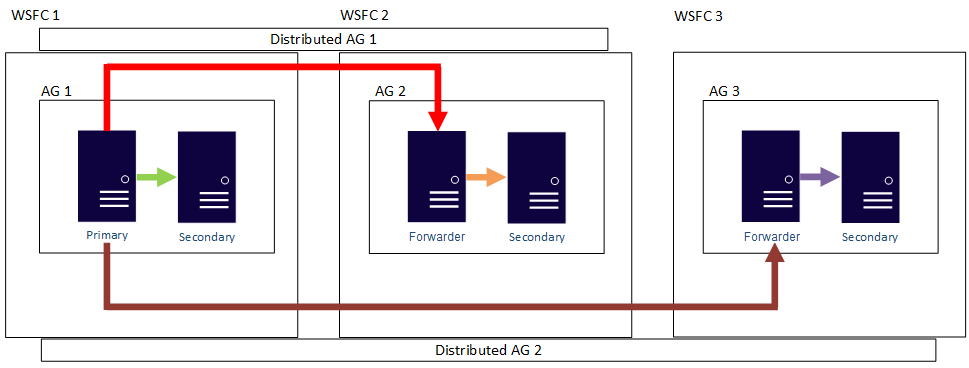
Önceki her iki örnekte de üç kullanılabilirlik grubunda toplam 27 çoğaltma olabilir ve bunların tümü salt okunur sorgular için kullanılabilir.
Yalnızca okunabilir yönlendirme, Dağıtılmış Kullanılabilirlik Grupları ile tam olarak çalışmaz. Daha açık belirtmek gerekirse,
- Read-Only Yönlendirme yapılandırılabilir ve dağıtılmış kullanılabilirlik grubunun birincil kullanılabilirlik grubu için çalışır.
- Read-Only Yönlendirme yapılandırılabilir, ancak dağıtılmış kullanılabilirlik grubunun ikincil kullanılabilirlik grubu için çalışmaz. Tüm sorgular, ikincil kullanılabilirlik grubuna bağlanmak için dinleyiciyi kullanırsa, ikincil kullanılabilirlik grubunun birincil örneğine gider. Aksi takdirde, her kopyayı, ikincil bir kopya olarak tüm bağlantılara izin verecek ve bunlara doğrudan erişim sağlayacak şekilde yapılandırmanız gerekir. Ancak, ikincil kullanılabilirlik grubu yük devretmenin ardından birincil hale gelirse salt okunur yönlendirme çalışır. Bu davranış, SQL Server 2016 güncelleştirmesinde veya SQL Server'ın gelecekteki bir sürümünde değiştirilebilir.
İkincil kullanılabilirlik gruplarını başlatma
Dağıtılmış kullanılabilirlik grupları, ikinci kullanılabilirlik grubundaki birincil çoğaltmayı başlatmak için kullanılan ana yöntem olmak üzere otomatik tohumlama ile tasarlanmıştır. Aşağıdakileri yaparsanız, ikinci kullanılabilirlik grubunun birincil çoğaltması üzerinde tam veritabanı geri yüklemesi yapılabilir:
- NORECOVERY ile veritabanı yedeklemesini geri yükleyin.
- Gerekirse NORECOVERY ile doğru işlem günlüğü yedeklemelerini geri yükleyin.
- Veritabanı adı belirtmeden ve SEEDING_MODE OTOMATIK olarak ayarlanmış ikinci kullanılabilirlik grubunu oluşturun.
- Otomatik dağıtım kullanarak dağıtılmış kullanılabilirlik grubunu oluşturun.
İkinci kullanılabilirlik grubunun birincil çoğaltmasını dağıtılmış kullanılabilirlik grubuna eklediğinizde, çoğaltma, ilk kullanılabilirlik grubunun birincil veritabanlarıyla karşılaştırılarak kontrol edilir ve otomatik tohumlama, veritabanını kaynağa kadar günceller. Birkaç uyarı vardır:
İkinci kullanılabilirlik grubunun birincil çoğaltmasında
sys.dm_hadr_automatic_seedingüzerinde gösterilen çıktı, "Seeding Check Message Timeout" nedeniylecurrent_stateolarak FAILED ifadesini gösterecektir.İkinci kullanılabilirlik grubunun birincil çoğaltması üzerindeki geçerli SQL Server hata günlüğü otomatik tohumlamanın çalıştığını ve LSN'lerin eşitlendiğini gösterir.
İlk kullanılabilirlik grubunun birincil çoğaltmasında
sys.dm_hadr_automatic_seedinggösterilen çıkışta, current_state'in "COMPLETED" olduğunu gösterir.Otomatik dağıtım, dağıtılmış kullanılabilirlik gruplarında da farklı davranışlara sahiptir. Otomatik tohumlamanın ikinci çoğaltmada başlaması için, çoğaltmada komut
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASEkomutunu vermeniz gerekir. Bu koşul, temel alınan kullanılabilirlik grubuna katılan tüm ikincil çoğaltmalar için hala geçerli olsa da, ikinci kullanılabilirlik grubunun birincil çoğaltması dağıtılmış kullanılabilirlik grubuna eklendikten sonra otomatik dağıtıma başlama izni vermek için zaten doğru izinlere sahiptir.
Uyarı
- İkincil kullanılabilirlik grubu aynı veritabanı yansıtma uç noktasını kullanmalıdır. Aksi takdirde, yerel yük devretmeden sonra çoğaltma durdurulur.
- Altta yatan kullanılabilirlik grupları aynı kullanılabilirlik modunda olmalıdır, yani her iki kullanılabilirlik grubu da ya senkron taahhüt modunda ya da asenkron taahhüt modunda olmalıdır. Hangisini kullanacağınızdan emin değilseniz, yük devretmeye hazır olana kadar her ikisini de zaman uyumsuz işleme moduna ayarlayın.
Sağlığı izleme
Dağıtılmış kullanılabilirlik grubu yalnızca SQL Server yapısıdır ve temel WSFC'de görülmez. Aşağıdaki kod örneğinde her biri kendi kullanılabilirlik gruplarına sahip iki farklı WSC (CLUSTER_A ve CLUSTER_B) gösterilmektedir. Burada yalnızca CLUSTER_A içindeki AG1 ve CLUSTER_B içindeki AG2 ele alınmaktadır.
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
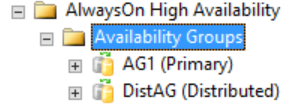
Dağıtılmış kullanılabilirlik grubu hakkındaki tüm ayrıntılı bilgiler SQL Server'da, özellikle de kullanılabilirlik grubu dinamik yönetim görünümlerindedir. Şu anda, dağıtılmış bir kullanılabilirlik grubu için SQL Server Management Studio'da gösterilen tek bilgi, kullanılabilirlik grubu için birincil replikadadır. Aşağıdaki şekilde gösterildiği gibi, Kullanılabilirlik Grupları klasörünün altında SQL Server Management Studio dağıtılmış bir kullanılabilirlik grubu olduğunu gösterir. Şekilde AG1, dağıtılmış kullanılabilirlik grubu için değil, söz konusu örnekte yerel olan bireysel bir kullanılabilirlik grubu için birincil çoğaltma olarak gösterilmektedir.
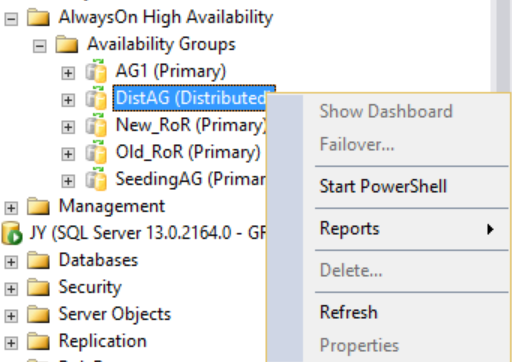
Ancak, dağıtılmış kullanılabilirlik grubuna sağ tıklarsanız, kullanılabilir seçenek yoktur (aşağıdaki şekle bakın) ve genişletilmiş Kullanılabilirlik Veritabanları, Kullanılabilirlik Grubu Dinleyicileri ve Kullanılabilirlik Çoğaltmaları klasörlerinin tümü boş olur. SQL Server Management Studio 16 bu sonucu görüntüler, ancak SQL Server Management Studio'nun gelecekteki bir sürümünde değişebilir.
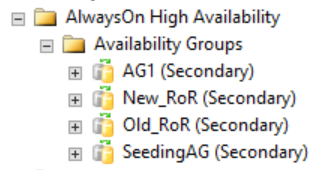
Aşağıdaki şekilde gösterildiği gibi, ikincil çoğaltmalar SQL Server Management Studio'da dağıtılmış kullanılabilirlik grubuyla ilgili hiçbir şey göstermez. Bu kullanılabilirlik grubu adları, önceki CLUSTER_A WSFC görüntüsünde gösterilen rollerle eşlenmiştir.
Tüm kullanılabilirlik çoğaltma adlarını listelemek için DMV
Dinamik yönetim görünümlerini kullandığınızda aynı kavramlar geçerlidir. Aşağıdaki sorguyu kullanarak tüm kullanılabilirlik gruplarını (normal ve dağıtılmış) ve bunlara katılan düğümleri görebilirsiniz. Bu sonuç, yalnızca dağıtılmış kullanılabilirlik grubuna katılan WSFC'lerden birindeki birincil replikayı sorguladığınızda görüntülenir. Dinamik yönetim görünümünde sys.availability_groups , kullanılabilirlik grubu dağıtılmış bir kullanılabilirlik grubu olduğunda 1 olan adlı is_distributedyeni bir sütun vardır. Bu sütunu görmek için:
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
Aşağıdaki şekilde, dağıtılmış kullanılabilirlik grubuna katılan ikinci WSFC çıktısının bir örneği gösterilmiştir. SPAG1 iki kopyadan oluşur: DENNIS ve JY. Ancak SPDistAG adlı dağıtılmış kullanılabilirlik grubu, geleneksel bir kullanılabilirlik grubunda olduğu gibi örneklerin adları yerine iki katılımcı kullanılabilirlik grubunun (SPAG1 ve SPAG2) adlarına sahiptir.
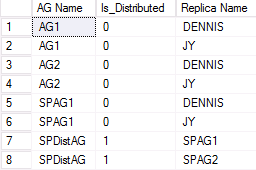
DMV, dağıtılmış AG sağlık bilgilerini listeleyecek.
SQL Server Management Studio'da, Pano'da ve diğer alanlarda gösterilen tüm durumlar yalnızca bu kullanılabilirlik grubu içinde yerel eşitleme içindir. Dağıtılmış bir kullanılabilirlik grubunun durumunu görüntülemek için dinamik yönetim görünümlerini sorgular. Aşağıdaki örnek sorgu, önceki sorguyu genişletir ve daraltır:
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV'nin performansı incelemesi için
Önceki sorguyu daha da genişletmek için sys.dm_hadr_database_replicas_states ekleyerek dinamik yönetim görünümleri aracılığıyla temel performansı da görebilirsiniz. Dinamik yönetim görünümü şu anda yalnızca ikinci kullanılabilirlik grubu hakkındaki bilgileri depolar. Birincil kullanılabilirlik grubunda çalıştırılacak aşağıdaki örnek sorgu, aşağıda gösterilen örnek çıkışı üretir:
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

Dağıtılmış AG'nin performans sayaçlarını görüntülemek için Dinamik Yönetim Görünümleri (DMV)
Aşağıdaki sorgu, belirli bir dağıtılmış kullanılabilirlik grubuyla ilişkili performans sayaçlarını görüntüler.
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'
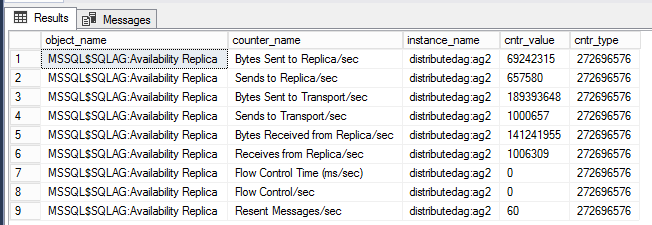
Uyarı
Filtre, LIKE dağıtılmış kullanılabilirlik grubunun adına sahip olmalıdır. Bu örnekte, dağıtılmış kullanılabilirlik grubunun adı 'distributedag' şeklindedir. Değiştiriciyi LIKE dağıtılmış kullanılabilirlik grubunuzun adını yansıtacak şekilde değiştirin.
DMV, hem AG'nin hem de Dağıtılmış AG'nin sağlık durumunu görüntüleyecek.
Aşağıdaki sorgu, hem kullanılabilirlik grubunun hem de dağıtılmış kullanılabilirlik grubunun durumu hakkında çok sayıda bilgi görüntüler. ( Tracy Boggiano'dan izinle çoğaltıldı.)
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

Dağıtılmış Erişim Grubu'nun meta verilerini görüntülemek için Dinamik Yönetim Görünümleri (DMV'ler)
Aşağıdaki sorgular, dağıtılmış kullanılabilirlik grubu da dahil olmak üzere kullanılabilirlik grupları tarafından kullanılan uç nokta URL'leri hakkında bilgi görüntüler. ( David Barbarin'in izniyle yeniden oluşturulmuş.)
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

DMV'nin tohumlamanın mevcut durumunu göstermesi
Aşağıdaki sorgu, tohumlamanın geçerli durumuyla ilgili bilgileri görüntüler. Bu, çoğaltmalar arasındaki eşitleme hatalarını gidermek için kullanışlıdır. ( David Barbarin'in izniyle yeniden oluşturulmuş.)
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO
