Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Şunlar için geçerlidir:![]() Linux üzerinde SQL Server
Linux üzerinde SQL Server
Bu makale, Windows ve Linux üzerinde SQL Server'da yüksek kullanılabilirlik ve olağanüstü durum kurtarma için iş sürekliliği çözümlerine genel bir bakış sağlar.
SQL Server'ı dağıtan herkesin, iş ve son kullanıcıların ihtiyaç duyduğu tüm görev açısından kritik SQL Server örneklerinin ve veritabanlarının, kullanılabilirlik normal iş saatlerinde veya 24 saat boyunca kullanılabilir olduğundan emin olması gerekir. Amaç, işi en az kesintiyle veya hiç kesinti olmadan çalışır durumda tutmaktır. Bu kavram iş sürekliliği olarak da bilinir.
SQL Server 2017 (14.x) ve sonraki sürümleri kullanılabilirlik için özellikler ve geliştirmeler kullanıma sunulmuştur. En büyük ekleme, Linux dağıtımlarında SQL Server desteğidir. SQL Server'daki yeni özelliklerin tam listesi için aşağıdaki makalelere bakın:
| Sürüm | İşletim sistemi |
|---|---|
| SQL Server 2025 (17.x) sürümündeki yenilikler | Windows | Linux |
| SQL Server 2022 (16.x) sürümündeki yenilikler | Windows | Linux |
| SQL Server 2019 (15.x) sürümündeki yenilikler | Windows | Linux |
| SQL Server 2017 (14.x) sürümündeki yenilikler | Windows | Linux |
Bu makalede, SQL Server 2017 (14.x) ve sonraki sürümlerdeki kullanılabilirlik senaryolarının yanı sıra yeni ve gelişmiş kullanılabilirlik özelliklerine odaklanılır. Senaryolar, hem Windows Server hem de Linux'ta SQL Server dağıtımlarına yayılabilen karma olanları ve bir veritabanının okunabilir kopya sayısını artırabilenleri içerir.
Bu makale SQL Server dışındaki kullanılabilirlik seçeneklerini (sanallaştırma gibi) kapsamasa da, burada açıklanan her şey ister genel bulutta ister şirket içi hiper yönetici sunucusu tarafından barındırılan bir konuk sanal makine içindeki SQL Server yüklemeleri için geçerlidir.
Kullanılabilirlik özelliklerini kullanan SQL Server senaryoları
Always On kullanılabilirlik gruplarını, yük devretme kümesi örneklerini ve günlük gönderimlerini yalnızca kullanılabilirlik için değil, farklı amaçlarla kullanabilirsiniz. Kullanılabilirlik özelliklerini kullanmanın dört ana yolu vardır:
- Yüksek ulaşılabilirlik
- Felaket kurtarma
- Geçişler ve yükseltmeler
- Bir veya daha fazla veritabanının okunabilir kopyalarını ölçeklendirme
Aşağıdaki bölümlerde her senaryo için ilgili özellikler açıklanmaktadır. Kapsanmayan bir özellik SQL Server çoğaltmasıdır. SQL Server çoğaltması Always On şemsiyesi altında resmi olarak kullanılabilirlik özelliği olarak belirlenmiyor olsa da, genellikle belirli senaryolarda verileri yedekli hale getirmek için kullanılır. SQL Server için Linux üzerinde birleştirme çoğaltması desteklenmez. Daha fazla bilgi için bkz. Linux'ta SQL Server çoğaltması.
Önemli
SQL Server kullanılabilirlik özellikleri sağlam, iyi test edilmiş bir yedekleme ve geri yükleme stratejisine sahip olma gereksinimini değiştirmez. Yedekleme ve geri yükleme stratejisi, kullanılabilirlik çözümlerinin en temel yapı taşıdır.
Yüksek ulaşılabilirlik
Buluttaki bir veri merkezinde veya tek bir bölgede yerel bir sorun oluştuğunda SQL Server örneklerinin veya veritabanlarının kullanılabilir olduğundan emin olmak önemlidir. Bu bölümde SQL Server kullanılabilirlik özelliklerinin nasıl yardımcı olabileceği açıklanmaktadır. Açıklanan özelliklerin tümü hem Windows Server'da hem de Linux'ta kullanılabilir.
Kullanılabilirlik grupları
Kullanılabilirlik grupları (AG' ler), bir veritabanının her işlemini başka bir örneğe veya özel durumdaki bir veritabanının kopyasını içeren çoğaltmaya göndererek veritabanı düzeyinde koruma sağlar. Standart veya Kurumsal sürümlerde AG dağıtabilirsiniz. AG'ye katılan örnekler tek başına veya yük devretme kümesi örnekleri olabilir (SONRAKI bölümde açıklanan FC'ler). İşlemler gerçekleşirken bir replika gönderildiğinden, daha düşük kurtarma noktası ve kurtarma süresi hedefleri gereksinimi olan durumlarda AG gruplarının kullanılması önerilir. Çoğaltmalar arasındaki veri taşıma senkron veya asenkron olabilir; Enterprise sürümünde, birincil dahil en fazla üç çoğaltmanın senkron olmasına imkan tanınır. Ag, birincil çoğaltmada bulunan veritabanının bir tam okuma/yazma kopyasına sahipken, tüm ikincil çoğaltmalar doğrudan son kullanıcılardan veya uygulamalardan işlem alamaz.
Uyarı
Always On, SQL Server'daki kullanılabilirlik özellikleri için kullanılan bir terimdir ve hem AG'leri hem de FC'leri kapsar. Always On, AG özelliğinin adı değildir.
SQL Server 2022(16.x) öncesinde, AG'ler yalnızca veritabanı düzeyinde koruma sağlar, örnek düzeyinde koruma sağlamaz. Veritabanı günlüklerinde yakalanmayan veya veritabanında yapılandırılmayan her şey, her ikincil kopya için manuel olarak senkronize edilmelidir. El ile eşitlenmesi gereken nesnelere örnek olarak örnek düzeyinde oturum açma işlemleri, bağlı sunucular ve SQL Server Aracısı işleri verilebilir.
SQL Server 2022 (16.x) ve sonraki sürümlerinde kullanıcılar, oturum açma bilgileri, izinler ve SQL Server Aracısı işleri gibi meta veri nesnelerini örnek düzeyine ek olarak AG düzeyinde yönetebilirsiniz. Daha fazla bilgi için bkz. Kapsanan kullanılabilirlik grubu nedir?
Ag ayrıca, uygulamaların ve son kullanıcıların birincil çoğaltmayı hangi SQL Server örneğinin barındırdığını bilmeye gerek kalmadan bağlanmasına olanak tanıyan dinleyici adlı başka bir bileşene de sahiptir. Her AG'nin kendi dinleyicisi vardır. Dinleyicinin uygulamaları Windows Server ve Linux'ta biraz farklı olsa da, ikisi de aynı işlevselliği ve kullanılabilirliği sağlar. Aşağıdaki şemada, Windows Server Yük Devretme Kümesi (WSFC) kullanan Windows Server tabanlı bir AG gösterilmektedir. Linux veya Windows Server'da olsun, kullanılabilirlik için işletim sistemi katmanında temel alınan bir küme gereklidir. Örnek, altyapı kümesi olarak WSFC ile iki sunucu veya düğüm içeren basit bir yapılandırmayı gösterir.

Standart ve Enterprise sürümleri, çoğaltmalar söz konusu olduğunda farklı maksimum değerlere sahiptir. Standart sürümde "temel kullanılabilirlik grubu" olarak bilinen bir AG, AG'de yalnızca tek bir veritabanı bulunan iki replikayı (birincil ve ikincil) destekler. Enterprise edition, birden çok veritabanının tek bir AG'de yapılandırılmasına izin vermekle kalmaz, aynı zamanda en fazla dokuz toplam çoğaltmaya (bir birincil, sekiz ikincil) sahip olabilir. Enterprise edition ayrıca okunabilir ikincil çoğaltmalar, ikincil çoğaltmadan yedekleme yapma ve daha fazlası gibi diğer isteğe bağlı avantajları da sağlar.
Uyarı
SQL Server 2012'de (11.x) kullanım dışı bırakılan veritabanı yansıtma, SQL Server'ın Linux sürümünde kullanılamaz ve eklenmez. Veritabanı yansıtmayı kullanmaya devam eden müşteriler, veritabanı yansıtmasının yerini alan AG'lere geçmeyi planlamalıdır.
Kullanılabilirlik söz konusu olduğunda, AG'ler otomatik veya manuel yük devretme sağlayabilir. Eşzamanlı veri aktarımı yapılandırılmışsa ve birincil ile ikincil çoğaltmadaki veritabanı eşitlenmiş durumdaysa otomatik yük devretme gerçekleşebilir. Dinleyici kullanıldığı ve uygulama desteklenen bir .NET Framework sürümünü (Service Pack 1 veya 4.6.2 ve sonraki sürümleri içeren 3.5) kullandığı sürece, dinleyici kullanılırsa yük devretmenin son kullanıcılar üzerinde en az düzeyden hiçbir etkisi olmayacak şekilde işlenmesi gerekir. İkincil bir çoğaltmanın yeni bir birincil çoğaltma yapılması için yük devretme işlemi, otomatik veya manuel olarak yapılandırılabilir ve genellikle saniyeler içinde ölçülür.
Aşağıdaki listede, Windows Server'da Linux'a karşı AG'lerle ilgili bazı farklar vurgulanır:
Temel kümenin Linux ve Windows Server'da çalışma şekli nedeniyle, tüm AG yük devretmeleri (el ile veya otomatik) Linux üzerindeki küme üzerinden yapılır. Windows Server tabanlı AG dağıtımlarında el ile yük devretme işlemleri SQL Server aracılığıyla yapılmalıdır. Otomatik yük devretme işlemleri hem Windows Server hem de Linux'ta temel alınan küme tarafından işlenir.
Linux üzerinde SQL Server için, temel kümelemenin çalışma şekli nedeniyle en az üç çoğaltmaya sahip bir AG yapılandırmanız gerekir.
Linux'ta, her dinleyici tarafından kullanılan ortak ad, Windows Server'daki gibi kümede değil DNS'de tanımlanır.
SQL Server 2017 (14.x), AG'ler için aşağıdaki özellikleri ve geliştirmeleri kullanıma sunar:
- Küme türleri
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT- Windows Server tabanlı yapılandırmalar için gelişmiş Microsoft Dağıtımcı İşlem Düzenleyicisi (DTC) desteği
- Salt okunur veritabanları için ek ölçek genişletme senaryoları (bu makalenin ilerleyen bölümlerinde açıklanmaktadır)
Kullanılabilirlik grubu küme türleri
Windows Server'da kümelemenin yerleşik kullanılabilirlik biçimi, Yük Devretme Kümelemesi adlı bir özellik aracılığıyla etkinleştirilir. AG veya FCI ile kullanılacak bir WSFC oluşturmanıza olanak tanır. SQL Server, AG'ler ve FC'ler için tümleştirme sağlayan küme kullanan kaynak DLL'lerini gönderir.
Linux üzerinde SQL Server birden çok kümeleme teknolojisini destekler. Microsoft, SQL Server bileşenlerini desteklerken, iş ortaklarımız da ilgili kümeleme teknolojisini destekler. Örneğin, Pacemaker ile birlikte Linux üzerinde SQL Server, küme çözümü olarak HPE Serviceguard ve DH2i DxEnterprise'i destekler.
Windows tabanlı bir yük devretme kümesi çözümü ve Linux tabanlı küme çözümü farklılıktan ziyade benzerdir. Her ikisi de tek tek sunucuları alıp kullanılabilirlik sağlamak için bir yapılandırmada birleştirmek için bir yol sağlar ve kaynaklar, kısıtlamalar (farklı uygulansa bile), yük devretme vb. kavramlara sahiptir.
Örneğin, otomatik yük devretme gibi işlemler dahil olmak üzere hem AG hem de FCI yapılandırmaları için Pacemaker'ı desteklemek amacıyla Microsoft, WSFC'deki kaynak DLL'lere benzeyen fakat tam olarak aynı olmayan mssql-server-ha paketini sağlar. WSFC ile Pacemaker arasındaki farklardan biri, Pacemaker'da bir WSFC'deki dinleyicinin adını (veya FCI'nın adını) soyutlamada yardımcı olan bir ağ adı kaynağı olmamasıdır. Linux'ta ad çözümlemesi için DNS kullanın.
Küme yığınındaki fark nedeniyle SQL Server 2017 (14.x) ve sonraki sürümlerdeki AG'lerin WSFC tarafından yerel olarak işlenen bazı meta verileri işlemesi gerekir. Örneğin, bir kullanılabilirlik grubu için üç küme türü vardır, bunlar sys.availability_groupscluster_type sütunlarında ve cluster_type_desc sütununda depolanır.
- WSFC
- Dış
- Hiç kimse
Yüksek kullanılabilirlik gerektiren tüm AG'ler, SQL Server 2017 (14.x) ve sonraki sürümlerde WSFC veya Linux kümeleme aracısı anlamına gelen temel bir küme kullanmalıdır. Temel alınan WSFC kullanan Windows Server tabanlı AG'ler için varsayılan küme türü WSFC'dir ve bunu ayarlamanız gerekmez. Linux tabanlı AG'ler için AG'yi oluştururken küme türünü Dış olarak ayarlamanız gerekir. Linux'ta dış küme çözümüyle tümleştirme AG oluşturulduktan sonra yapılandırılırken, WSFC'de oluşturma zamanında yapılır.
'None' küme türü, hem Windows Server hem de Linux AG'leri ile kullanılabilir. Küme türünü Yok olarak ayarlamak, AG'nin temel alınan bir küme gerektirmediği anlamına gelir. Bu, SQL Server 2017 'nin (14.x) küme olmayan AG'leri destekleyen ilk SQL Server sürümü olduğu anlamına gelir, ancak bu yapılandırmanın yüksek kullanılabilirlik çözümü olarak desteklenmediği anlamına gelir.
Önemli
SQL Server 2017 (14.x) ve sonraki sürümlerinde, ag oluşturulduktan sonra küme türünü değiştiremezsiniz. Bu kısıtlama, AG'nin Yok'tan Dış veya WSFC'ye ya da tersi yönde geçirilemeyeceği anlamına gelir.
Veritabanının yalnızca salt okunur ek kopyalarını eklemek istiyorsanız veya AG'nin geçiş ve yükseltmeler için sağladığını istiyorsanız ancak temel alınan bir kümenin karmaşıklığıyla ve hatta çoğaltmayla ilgilenmek istemiyorsanız, küme türü Yok olan bir AG ayarlamayı düşünün. Daha fazla bilgi için Geçişler ve yükseltmeler veokuma ölçeği bölümlerine bakın.
Aşağıdaki ekran görüntüsünde, SQL Server Management Studio'daki (SSMS) farklı küme türleri için destek gösterilmektedir. 17.1 veya sonraki bir sürümü çalıştırıyor olmanız gerekir. Aşağıdaki ekran görüntüsü 17.2 sürümünden alınmıştı:

Taahhüt İçin Gerekli Senkronize İkincil Sistemler
SQL Server 2016 (13.x), Enterprise sürümünde zaman uyumlu çoğaltma sayısı için desteği ikiden üçe artırdı. Ancak, bir ikincil çoğaltma eşitlenmişse ancak diğer çoğaltma sorun yaşıyorsa, birincil çoğaltmaya hatalı davranan çoğaltmayı beklemesini veya devam etmesini sağlamasını bildirme davranışını denetlemenin bir yolu yoktur. Bu senaryoda, ikincil çoğaltma eşitlenmiş durumda olmasa bile birincil çoğaltma yine de yazma trafiği alabilir ve bu da ikincil çoğaltmada veri kaybına neden olur.
SQL Server 2017 (14.x) ve sonraki sürümlerinde, zaman uyumlu çoğaltmalar REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT olduğunda ne olacağının davranışını denetleyebilirsiniz. Bu seçenek aşağıdaki gibi çalışır:
- Üç olası değer vardır:
0,1ve2. - Değer, senkronize edilmesi gereken ikincil çoğaltmaların sayısını ifade eder ve bu, veri kaybı, Erişilebilirlik Grubu (AG) kullanılabilirliği ve yük devretmenin etkilerinde bulunan bir unsurdur.
- WSFC'ler ve None küme türü için varsayılan değer
0'dir ve bunu1veya2olarak manuel olarak ayarlayabilirsiniz. - Dış küme türü için, küme mekanizması bu değeri varsayılan olarak ayarlar ve el ile geçersiz kılabilirsiniz. Senkron üç replika için varsayılan değer
1'dir.
Linux'ta değerini kümedeki AG kaynağında yapılandırabilirsiniz REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT . Windows'ta, Transact-SQL aracılığıyla ayarlarsınız.
Veri korumasını artırmak için, 0 değerinin daha yüksek olması, gerekli ikincil kopya sayısı mevcut olmadığında, koşul çözülene kadar birincilin kullanılamaz olmasına neden olur.
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT ayrıca, doğru sayıda ikincil çoğaltmalar doğru durumda değilse otomatik yük devretme gerçekleşmeyeceğinden, yük devretme davranışını etkiler. Linux'ta değeri 0, otomatik yük devretmeye izin vermez. Bu nedenle Linux'ta zaman uyumlu çalışmayı ve otomatik yük devretmeyi birlikte kullanırken, otomatik yük devretmeyi gerçekleştirmek için değerin 0'dan daha yüksek olması gerekir.
0 Windows Server'da, SQL Server 2016 (13.x) ve önceki sürümlerdeki davranıştır.
Gelişmiş Microsoft Dağıtılmış İşlem Düzenleyicisi desteği
SQL Server 2016(13.x) öncesinde, SQL Server'da, kapakların altında DTC kullanan dağıtılmış işlemler gerektiren uygulamalar için kullanılabilirlik elde etmenin tek yolu, FCI'leri dağıtmaktı. Dağıtılmış bir işlem iki yoldan biriyle yapılabilir:
- Aynı SQL Server örneğindeki birden fazla veritabanına yayılan bir işlem.
- Birden fazla SQL Server örneğine yayılan veya SQL Server olmayan bir veri kaynağı içeren bir işlem.
SQL Server 2016 (13.x), ikinci senaryoyu ele alan AG'lerle DTC için kısmi destek kullanıma sunulmuştur. SQL Server 2017 (14.x), DTC ile her iki senaryoyu da destekleyerek hikayeyi tamamlar.
SQL Server 2017 (14.x) ve sonraki sürümlerinde, oluşturulduktan sonra AG'ye DTC desteği ekleyebilirsiniz. SQL Server 2016'da (13.x), YALNıZCA AG'yi oluştururken DTC desteğini etkinleştirebilirsiniz.
Yedekleme kümesi örnekleri
Yük devretme kümesi örnekleri (FCI'ler), örnek olarak bilinen SQL Server yüklemesinin tamamı için kullanılabilirlik sağlar. FCI'lerde, temel alınan sunucu bir sorunla karşılaşırsa, örneğin içindeki her şey veritabanları, SQL Server Aracısı işleri, bağlı sunucular ve daha fazlası dahil olmak üzere başka bir sunucuya taşınır. Ağ tanımlı olsa bile tüm FCI'ler için bir miktar paylaşılan depolama alanı gerekir. Bir düğüm, herhangi bir zamanda FCI kaynaklarını çalıştırabilir ve onlara sahip olabilir. Aşağıdaki diyagramda, kümenin ilk düğümü FCI'nin sahibidir. Ayrıca, kendisiyle ilişkilendirilmiş paylaşılan depolama kaynaklarına da sahiptir ve bu, depolamaya giden kesintisiz çizgi ile belirtilir.

Yük devretme işleminden sonra, aşağıdaki diyagramda gösterildiği gibi sahiplik değişir:

FCI'da sıfır veri kaybı vardır, ancak verilerin yalnızca bir kopyasına sahip olan ortak depolama, bir arıza kaynağıdır. Veritabanlarının yedekli kopyalarına sahip olmak için FCI'leri AG veya günlük gönderimi gibi başka bir kullanılabilirlik yöntemiyle birleştirin. Diğer yöntem FCI'dan fiziksel olarak ayrı depolama kullanmalıdır. FCI başka bir düğüme yük devrettiğinde, bir düğümde durur ve başka bir düğümde başlar. Bu işlem, bir sunucuyu açıp kapatmaya benzer.
FCI normal kurtarma işleminden geçer. İleriye alınması gereken tüm işlemleri ileriye doğru alır ve tamamlanmamış işlemleri geri alır. Bu nedenle veritabanı, bir veri noktasından hatanın meydana geldiği veya elle yük devretmenin gerçekleştiği zamana kadar tutarlı olduğu için veri kaybı olmaz. Veritabanları yalnızca kurtarma tamamlandıktan sonra kullanılabilir. Kurtarma süresi birçok faktöre bağlıdır ve genellikle bir AG'nin yük devri işleminden daha uzundur. Sonuç olarak, bir AG'nin yükünü devreddiğinizde, veritabanını kullanılabilir hale getirmek için sql Server Agent işini etkinleştirme gibi ek görevler gerekebilir.
Uyarı
Hızlandırılmış veritabanı kurtarma (ADR) kurtarma süresini azaltabilir. Daha fazla bilgi için bkz . Hızlandırılmış veritabanı kurtarma.
AG'ler gibi, FCI'ler de temel alınan kümenin hangi düğümünün onu barındırdığına dair bir soyutlama sağlar. FCI her zaman aynı adı korur. Uygulamalar ve son kullanıcılar düğümlere hiçbir zaman bağlanmaz. Bunun yerine, FCI'ya atanan benzersiz adı kullanırlar. FCI, bir AG'ye birincil veya ikincil kopyayı barındıran örneklerden biri olarak katılabilir.
Aşağıdaki listede, Windows Server ve Linux'taki FCI'lerle ilgili bazı farklar vurgulanır:
- Windows Server'da FCI, yükleme işleminin bir parçasıdır. SQL Server'ı yükledikten sonra Linux üzerinde bir FCI yapılandırabilirsiniz.
- Linux, konak başına tek bir SQL Server yüklemesini desteklediğinden tüm FCI'ler varsayılan bir örnektir. Windows Server, WSFC başına en fazla 25 FCI'yi destekler.
- Linux'ta FCI'ler tarafından kullanılan ortak ad DNS'de tanımlanır ve FCI için oluşturulan kaynakla aynı olmalıdır.
Log gönderimi
Kurtarma noktası ve kurtarma süresi hedefleri daha esnekse veya veritabanları son derece görev açısından kritik değilse, günlük gönderimi SQL Server'da kanıtlanmış bir diğer kullanılabilirlik özelliğidir. SQL Server'ın yerel yedeklemelerine bağlı olarak, günlük gönderimi işlemi otomatik olarak işlem günlüğü yedekleri oluşturur, bunları sıcak bekleme olarak bilinen bir veya daha fazla örneğe kopyalar ve işlem günlüğü yedeklemelerini otomatik olarak bu beklemeye uygular. Günlük gönderimi, işlem günlüğü yedeklemelerini yedekleme, kopyalama ve uygulama işlemini otomatikleştirmek için SQL Server Agent işlerini kullanır.
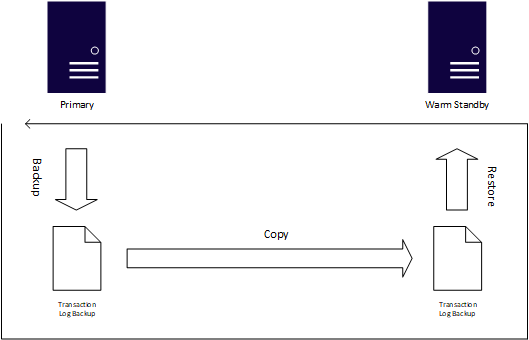
Günlük gönderimini kullanmanın en büyük avantajı, işlem günlüklerinin uygulanmasını geciktirebildiğiniz için insan hatasına neden olmasıdır. Örneğin, biri bir UPDATE'ı bir WHERE maddesi olmadan yaparsa, bekleme sistemi bu değişikliği almamış olabilir, bu yüzden birincil sistemi onarırken ona geçiş yapabilirsiniz. Günlük gönderimini yapılandırmak kolay olsa da, birincilden rol değişikliği olarak bilinen sıcak bekleme moduna geçmek her zaman el ile gerçekleştirilir. Transact-SQL aracılığıyla bir rol değişikliği başlatırsınız ve EÇ'de olduğu gibi, işlem günlüğüne yansımayan tüm nesneleri el ile eşitlemeniz gerekir. Her bir veritabanı için günlük gönderimini yapılandırmanız gerekirken, tek bir AG birden fazla veritabanı içerebilir.
AG veya FCI'den farklı olarak, günlük gönderiminde rol değişikliği için herhangi bir soyutlama yoktur ve bu durumun uygulamalar tarafından işlenebilmesi gerekir. DNS diğer adı (CNAME) gibi teknikler uygulanabilir, ancak değişiklikten sonra DNS'nin yenilenme süresi gibi bazı avantajlar ve dezavantajlar bulunmaktadır.
Felaket kurtarma
Birincil kullanılabilirlik konumunuz deprem veya sel gibi yıkıcı bir olayla karşılaştığında, işletmenin sistemlerinin başka bir yerde çevrimiçi olmasını sağlamak için hazırlıklı olması gerekir. Bu bölümde SQL Server kullanılabilirlik özelliklerinin iş sürekliliği konusunda nasıl yardımcı olabileceği anlatılabilir.
Kullanılabilirlik grupları
AG'lerin avantajlarından biri, tek bir özellik kullanarak hem yüksek kullanılabilirliği hem de olağanüstü durum kurtarmayı yapılandırmanızdır. Paylaşılan depolamanın da yüksek oranda kullanılabilir olmasını sağlama gereksinimi olmadan, yüksek kullanılabilirlik için bir veri merkezinde yerel olan çoğaltmaların ve her biri ayrı depolama alanına sahip olağanüstü durum kurtarma için diğer veri merkezlerindeki uzak çoğaltmaların bulunması çok daha kolaydır. Veritabanının fazladan kopyalarının olması, yedekliliği sağlamanın bir dezavantajıdır. Aşağıdaki diyagramda birden çok veri merkezine yayılan bir AG örneği gösterilmiştir. Birincil çoğaltmalardan biri tüm ikincil çoğaltmaları eşitlenmiş durumda tutmakla sorumludur.

"Küme türü ‘Yok’ olan bir AG dışında, bir AG'nin tüm çoğaltmalarının, ister WSFC ister harici bir küme çözümü olsun, aynı temel kümenin parçası olması gerekir." Önceki diyagramda WSFC iki farklı veri merkezinde çalışacak şekilde genişletildi ve bu da platformdan bağımsız olarak karmaşıklık katıyor (Windows Server veya Linux). Kümeleri mesafeler arasında esnetme karmaşıklık katıyor.
SQL Server 2016'da (13.x) kullanıma sunulan dağıtılmış kullanılabilirlik grubu, AG'nin farklı kümelerde yapılandırılan AG'lere yayılmasına olanak tanır. Dağıtılmış AG'ler, düğümlerin tümünün aynı kümede yer alma gereksinimini birbirinden ayrıştırarak olağanüstü durum kurtarmayı yapılandırmayı çok daha kolay hale getirir. Dağıtılmış AG'ler hakkında daha fazla bilgi için bkz . Dağıtılmış kullanılabilirlik grupları.

Yedekleme kümesi örnekleri
Olağanüstü durum kurtarma için FCI'leri kullanabilirsiniz. Normal bir AG'de olduğu gibi, temel alınan küme mekanizmasını tüm konumlara genişletmeniz gerekir ve bu da karmaşıklığı artırır. FCI'ler için paylaşılan depolamayı da göz önünde bulundurmanız gerekir. Birincil ve ikincil sitelerin aynı disklere erişmesi gerekir. FCI tarafından kullanılan depolama alanının her iki konumda da mevcut olduğundan emin olmak için, donanım katmanında depolama satıcısı tarafından sağlanan işlevsellik gibi bir dış yöntem kullanın. Alternatif olarak, Windows Server'da Storage Replica kullanın.

Log gönderimi
Günlük gönderimi (log shipping), SQL Server veritabanları için olağanüstü durum kurtarma sağlamanın en eski yöntemlerinden biridir. Günlük gönderimi genellikle ortam, yönetim becerileri veya bütçe nedeniyle diğer seçeneklerin zor olabileceği uygun maliyetli ve daha basit bir olağanüstü durum kurtarma sağlamak için AG'ler ve FC'ler ile birlikte kullanılır. Günlük gönderimi için yüksek erişilebilirlik senaryosuna benzer şekilde, birçok ortam işlem günlüğünün yüklenmesini insan hatasını hesaba katmak için geciktirir.
Geçişler ve yükseltmeler
Bir kuruluş yeni örnekler dağıttığında veya eski örnekleri yükselttiğinde, uzun kesintilere dayanamaz. Bu bölümde, SQL Server'ın kullanılabilirlik özelliklerinin planlı mimari değişiklikleri, sunucu değişikliği, platform değişikliği (örneğin, Windows Server'dan Linux'a veya tam tersi) veya yama uygulama sırasında kapalı kalma süresini en aza indirmek için nasıl kullanılabileceği açıklanmaktadır.
Uyarı
Ayrıca, geçişler ve yükseltmeler için yedeklemeler ve geri yüklemeler gibi diğer yöntemleri de kullanabilirsiniz. Bu makalede bu yöntemler ele alınmıyor.
Kullanılabilirlik grupları
Bir veya daha fazla kullanılabilirlik grubu (AG) içeren mevcut bir örneği SQL Server'ın sonraki sürümlerine yükseltebilirsiniz. Bu yükseltme bir miktar kapalı kalma süresi gerektirir ancak doğru planlamayla en aza indirilebilir.
Yapılandırmayı değiştirmeden (işletim sistemi veya SQL Server sürümü dahil) yeni sunuculara geçiş yapmak istiyorsanız, bu sunucuları mevcut temel alınan kümeye düğüm olarak ekleyin ve ardından AG'ye ekleyin. Çoğaltmalar veya yedekler doğru duruma geldiğinde, manuel olarak yeni bir sunucuya geçiş yapabilirsiniz. Ardından, eski sunucuları AG'den kaldırın ve işlemden çıkarın.
Dağıtılmış AG'ler ayrıca yeni bir yapılandırmaya geçiş yapmak veya SQL Server'ı yükseltmek için kullanılan başka bir yöntemdir. Dağıtılmış AG, farklı mimarilerde farklı temel alınan AG'leri desteklediğinden, Windows Server 2019'da çalışan SQL Server 2019'dan (15.x) Windows Server 2025'te çalışan SQL Server 2025'e (17.x) geçiş yapabilirsiniz.

Son olarak, küme tipi None olan AG'ler, veri aktarımı veya yükseltme için yararlıdır. Tipik bir AG yapılandırmasında küme türlerini karıştırıp eşleştiremezsiniz, bu nedenle tüm çoğaltmaların Hiçbiri türünde olması gerekir. Dağıtılmış AG, farklı küme türleriyle yapılandırılan AG'lere yaymak için kullanılabilir. Bu yöntem farklı işletim sistemi platformlarında da desteklenir.
Geçişler ve yükseltmeler için tüm AG (uygulama grupları) çeşitleri, işin en çok zaman alan kısmı olan veri eşitlemesinin zaman içinde dağıtılmasına olanak sağlar. Yeni yapılandırmaya geçişi başlatma zamanı geldiğinde, tam geçiş kısa süreli bir kesinti olup veri eşitleme de dahil olmak üzere tüm çalışmaların tamamlanmasının gerektiği uzun bir kapalı kalma süresine kıyasla daha kısa bir aradır.
AG'ler, düzeltme eki uygulaması devam ederken birincil çoğaltmayı ikincil çoğaltmaya el ile geçirerek, temel işletim sisteminin düzeltme eki uygulanması sırasında minimal kesinti süresi sağlayabilir. İşletim sistemi açısından bakıldığında, bunun yapılması Windows Server'da daha yaygındır, çünkü temel işletim sistemine hizmet verme işlemi yeniden başlatma gerektirebilir. Linux'a bazen düzeltme eki uygulamak, yeniden başlatmaya ihtiyaç duyabilir, ancak bu durum sık karşılaşılmaz.
Kapalı kalma süresini en aza indirmenin bir diğer yolu da AG mimarisinin ne kadar karmaşık olduğuna bağlı olarak bir kullanılabilirlik grubuna katılan SQL Server örneklerine düzeltme eki uygulamaktır. İlk olarak ikincil replika üzerine bir yama uygularsınız. Doğru sayıda çoğaltmaya düzeltme eki eklendikten sonra, yükseltmeyi yapmak için birincil çoğaltmayı başka bir düğüme el ile devredebilirsiniz. Bu noktada kalan tüm ikincil replikaları yükseltin.
Yedekleme kümesi örnekleri
FCI'ler kendi başlarına geleneksel geçiş veya yükseltme konusunda yardımcı olamaz. FCI'deki veritabanları için bir AG veya log shipping yapılandırmanız ve diğer tüm nesneleri dikkate almanız gerekir. Ancak, Windows Server'ın altındaki FCI'ler, temel alınan Windows Sunucularına düzeltme eki uygulamanız gerektiğinde popüler bir seçenek olmaya devam etmektedir. El ile bir yük devretme başlattığınızda, kısa bir kesinti, Windows Server güncelleme aldığı süre boyunca durumun kullanılamaz olmasının yerini alır.
Bir FCI'yi SQL Server'ın sonraki sürümlerine yükseltebilirsiniz. Daha fazla bilgi için Yük devretme kümesi örneğini yükseltme'ye bakın.
Log gönderimi
Log shipping, veritabanlarını taşımak ve yükseltmek için hâlâ popüler bir seçenektir. AG'lere benzer, ancak bu kez eşitleme yöntemi olarak işlem günlüğü kullanıldığında, veri yayılımı sunucu geçişinden önce iyi bir şekilde başlatılabilir. Geçiş sırasında, tüm trafik kaynakta durdurulduktan sonra son işlem günlüğünün alınması, kopyalanması ve yeni yapılandırmaya uygulanması gerekir. Bu noktada veritabanı çevrimiçi yapılabilir.
Günlük gönderme genellikle yavaş ağlara daha dayanıklıdır ve geçiş, bir AG veya dağıtılmış AG kullanılarak yapılandan biraz daha uzun olsa da genellikle saatler, günler veya haftalar değil, dakikalarla ölçülür.
AG'lere benzer şekilde günlük gönderimi, bakım penceresi sırasında başka bir sunucuya geçiş yapmak için bir yol sağlayabilir.
Diğer SQL Server dağıtım yöntemleri ve kullanılabilirliği
Linux üzerinde SQL Server için iki dağıtım yöntemi daha vardır: kapsayıcılar ve Azure'ı (veya başka bir genel bulut sağlayıcısını) kullanma. SQL Server'ın nasıl dağıtıldığından bağımsız olarak genel kullanılabilirlik gereksinimi vardır. Bu iki yöntem, SQL Server'ın yüksek oranda kullanılabilir hale getirilmesinde dikkat edilmesi gereken bazı özel noktalara sahiptir.
SQL Server kapsayıcıları ve HA/DR seçenekleri
SQL Server kapsayıcı dağıtımı , ortamlar arasında SQL Server sağlama, ölçeklendirme ve yaşam döngüsü yönetimini basitleştirmenin bir yoludur. Kapsayıcı, SQL Server'ın tam bir çalışmaya hazır görüntüsüdür.
Kapsayıcı platformunuza bağlı olarak, örneğin Kubernetes gibi bir kapsayıcı düzenleyici kullanırken, kapsayıcı kaybolursa yeniden dağıtılabilir ve kullanılan paylaşılan depolamaya eklenebilir. Bu biraz sağlamlık sağlasa da, veritabanı kurtarmayla ilişkili bazı kesinti süreleri vardır ve kullanılabilirlik grubu veya FCI kullanıldığında olduğu gibi tam anlamıyla yüksek erişilebilirliğe sahip değildir.
Kubernetes'te veya Kubernetes dışı platformlarda dağıtılan SQL Server kapsayıcıları için yüksek kullanılabilirlik yapılandırmak istiyorsanız, kümeleme çözümlerinden biri olarak DH2i DxEnterprise'i kullanabilirsiniz. Bunun üzerine ag'yi yüksek kullanılabilirlik modunda yapılandırabilirsiniz. Bu seçenek, yüksek kullanılabilirlik çözümünden beklenen kurtarma noktası hedefi (RPO) ve kurtarma süresi hedefi (RTO) sağlar.
Linux tabanlı VM dağıtımı
Linux, Linux Azure Sanal Makineleri üzerinde SQL Server ile dağıtılabilir. Şirket içi tabanlı yüklemelerde olduğu gibi, desteklenen bir yükleme, küme aracısı dışında kalan başarısız bir düğümün eskrimini gerektirir. Düğüm koruma, fencing aracıları aracılığıyla sağlanır. Bazı dağıtımlar bunları platformun bir parçası olarak gönderirken, bazıları dış donanım ve yazılım satıcılarına güvenir. Desteklenen bir çözümün genel bulutta dağıtılabilmesi için hangi düğüm eskrim biçimlerinin sağlandığını görmek için tercih ettiğiniz Linux dağıtımına bakın.
Linux'ta SQL Server yükleme kılavuzları aşağıdaki dağıtımlar için kullanılabilir:
- Hızlı Başlangıç: SQL Server'ı yükleme ve Red Hat'de veritabanı oluşturma
- Hızlı Başlangıç: SQL Server'ı yükleme ve Ubuntu'da veritabanı oluşturma
- Hızlı Başlangıç: SQL Server'ı yükleme ve SUSE Linux Enterprise Server'da veritabanı oluşturma
Okuma ölçeği
İkincil replikalar, salt okunur sorgular için kullanılabilme yeteneğine sahiptir. AG ile gerçekleştirilebilecek iki yöntem vardır.
- İkincil erişime doğrudan izin ver
- Dinleyicinin kullanılmasını gerektiren salt okunur yönlendirmeyi yapılandırma. SQL Server 2016 (13.x), round-robin algoritması kullanarak dinleyici aracılığıyla salt okunur bağlantıların yük dengelemesini sağlayarak salt okunur isteklerin tüm okunabilir kopyalara dağıtılmasına olanak tanır.
Uyarı
Okunabilir ikincil çoğaltmalar yalnızca Enterprise sürümünde kullanılabilir. Okunabilir bir çoğaltmayı barındıran her örnek için bir SQL Server lisansı gerekir.
Veritabanının okunabilir kopyalarını AG'ler aracılığıyla ölçeklendirme ilk olarak SQL Server 2016'da (13.x) dağıtılmış AG'lerle kullanıma sunulmuştur. Bu özellik, veritabanının salt okunur kopyalarını yalnızca yerel olarak değil, aynı zamanda bölgesel ve küresel olarak da en az yapılandırmayla sunar. Bu kurulum, sorguların yerel olarak yürütülmesini sağlayarak ağ trafiğini ve gecikme süresini azaltır. Bir AG'nin her birincil çoğaltması, tam okuma/yazma kopyası olmasa bile iki AG daha dağıtabilir ve her dağıtılmış AG, verilerin en fazla 27 okunabilir kopyasını destekleyebilir.

SQL Server 2017 (14.x) ve sonraki sürümlerinde, küme tipi "None" olarak yapılandırılmış Eşgüdüm Grupları (AG'ler) ile neredeyse gerçek zamanlı, salt okunur bir çözüm oluşturabilirsiniz. Amacınız kullanılabilirlik yerine okunabilir ikincil çoğaltmalar için AG'leri kullanmaksa, bu yaklaşım Linux'ta WSFC veya dış küme çözümü kullanmanın karmaşıklığını ortadan kaldırır. Daha basit bir dağıtım yöntemi ile AG'nin kolay okunabilir avantajlarını sunar.
Tek önemli uyarı, küme türü Hiçbiri olan temel küme olmaması nedeniyle salt okunur yönlendirme yapılandırmasının biraz farklı olmasıdır. SQL Server açısından bakıldığında, küme olmasa bile istekleri yönlendirmek için yine de bir dinleyici gereklidir. Geleneksel bir dinleyici yapılandırmak yerine, birincil çoğaltmanın IP adresini veya adını kullanın. Ardından birincil çoğaltma salt okunur istekleri yönlendirir.
Günlük gönderimi için sıcak bekleme, veritabanını WITH STANDBYgeri yükleyerek okunabilir kullanım için teknik olarak yapılandırılabilir. Ancak, işlem günlükleri geri yükleme için veritabanının özel olarak kullanılmasını gerektirdiğinden, bu durumda kullanıcıların veritabanına erişemediği anlamına gelir. Bu, özellikle gerçek zamanlıya yakın veriler gerekiyorsa günlük gönderme işlemini ideal bir çözüm olmaktan çıkarır.
İşlem çoğaltmasında tüm verilerin aktif olduğu durumun aksine, okuma ölçekli bir senaryodaki her ikincil çoğaltma birincil kopyanın birebir kopyasıdır. Replika, benzersiz dizinlerin uygulanabileceği bir durumda değil. Raporlama için herhangi bir dizin gerekiyorsa veya verilerin değiştirilmesi gerekiyorsa, bu dizinleri birincil çoğaltmadaki veritabanlarında oluşturmanız gerekir. Bu esnekliğe ihtiyacınız varsa, okunabilir veriler için çoğaltma daha iyi bir çözümdür.
Platformlar arası ve Linux dağıtım birlikte çalışabilirliği
Hem Windows Server hem de Linux'ta SQL Server desteğiyle bu bölümde, diğer amaçlara ek olarak kullanılabilirlik için birlikte nasıl çalışabilecekleri anlatılmaktadır. Ayrıca birden fazla Linux dağıtımı içeren çözümlerin hikayesini de kapsar.
Uyarı
WSFC tabanlı yük devretme kümesi örneğinin (FCI) veya kullanılabilirlik grubunun (AG) doğrudan Linux tabanlı bir FCI veya AG ile çalıştığı hiçbir senaryo yoktur. Windows Server Yük Devretme Kümesi (WSFC), Pacemaker düğümü tarafından genişletilemiyor ve tam tersi de geçerli.
Dağıtılmış kullanılabilirlik grupları
Dağıtılmış AG'ler, AG'lerin altındaki iki temel küme ister iki farklı WSFC ister iki farklı Linux dağıtımı veya biri WSFC diğeri Linux üzerinde olsun, bu yapılandırmaları kapsayacak şekilde tasarlanmıştır. Dağıtılmış AG, platformlar arası çözüme sahip olmanın birincil yöntemidir. Dağıtılmış AG, şirketinizin yapmak istediği şey buysa Windows Server tabanlı SQL Server altyapısından Linux tabanlı bir altyapıya dönüştürme gibi geçişler için de birincil çözümdür. Daha önce belirtildiği gibi, AG'ler ve özellikle dağıtılmış AG'ler, bir uygulamanın kullanım için kullanılamama süresini en aza indirirdi. Aşağıdaki diyagramda WSFC ve Pacemaker'a yayılan dağıtılmış AG örneği gösterilmiştir:

Bir AG'yi Yok küme türüyle yapılandırıyorsanız, Bu, Windows Server ve Linux'a ve birden çok Linux dağıtımına yayılabilir. Bu yapılandırma gerçek yüksek kullanılabilirlik olmadığından görev açısından kritik dağıtımlar için kullanmayın. Bunun yerine, okuma-ölçeklendirme veya geçiş ve yükseltme senaryoları için kullanın.
Log gönderimi
SQL Server’da log gönderimi yedekleme ve geri yüklemeyi temel alır, bu nedenle Windows Server’daki SQL Server ile Linux üzerindeki SQL Server’a kıyasla veritabanlarında, dosya yapılarında ve diğer öğelerde hiçbir fark yoktur. Windows Server tabanlı SQL Server yüklemesi ile Linux yüklemesi arasında ve Linux dağıtımları arasında günlük gönderimi yapılandırabilirsiniz. Diğer her şey aynı kalır.
AG'de olduğu gibi, kaynak sunucu daha yüksek bir SQL Server ana sürümüne sahipse, daha düşük bir ana sürümdeki hedefe log gönderimi çalışmaz.
Özet
Hem Windows Server hem de Linux'ta aynı özellikleri kullanarak SQL Server 2017 (14.x) ve sonraki sürümlerin örneklerini ve veritabanlarını yüksek oranda kullanılabilir hale getirebilirsiniz. Yerel yüksek kullanılabilirlik ve olağanüstü durum kurtarmanın standart kullanılabilirlik senaryolarının yanı sıra, SQL Server'daki kullanılabilirlik özelliklerini kullanarak yükseltmeler ve geçişlerle ilişkili kapalı kalma süresini en aza indirebilirsiniz. AG'ler, okunabilir kopyaların ölçeğini genişletmek için aynı mimarinin parçası olarak veritabanının ek kopyalarını da sağlayabilir. İster yeni bir çözüm dağıtıyor olun ister yükseltmeyi göz önünde bulundurun, SQL Server ihtiyacınız olan kullanılabilirliğe ve güvenilirliğe sahiptir.