Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Şunlar için geçerlidir:![]() SQL Server
SQL Server![]() Azure SQL Veritabanı
Azure SQL Veritabanı![]() Azure SQL Yönetilen Örneği
Azure SQL Yönetilen Örneği![]() Microsoft Fabric'te SQL veritabanı
Microsoft Fabric'te SQL veritabanı
Bu makalede , pandas'.hist() Python paketini kullanarak verilerin nasıl çizıldığı açıklanır. SQL Server veritabanı, ardışık, çakışmayan değerler içeren histogram veri aralıklarını görselleştirmek için kullanılan kaynaktır.
Prerequisites
- Windows veya Linux içinSQL Server
SQL Server Management Studio, örnek veritabanını Azure SQL Yönetilen Örneği'ne geri yüklemek için.
Azure Data Studio. Yüklemek için bkz. Azure Data Studio.
Bu makalede kullanılan örnek verileri almak için örnek DW veritabanını geri yükleyin.
Geri yüklenen veritabanını doğrulama
Tabloyu sorgulayarak geri yüklenen veritabanının Person.CountryRegion mevcut olduğunu doğrulayabilirsiniz:
USE AdventureWorksDW;
SELECT * FROM Person.CountryRegion;
Python paketlerini yükleme
Azure Data Studio'yu indirin ve yükleyin.
Aşağıdaki Python paketlerini yükleyin:
pyodbcpandassqlalchemymatplotlib
Bu paketleri yüklemek için:
- Azure Data Studio not defterinizde Paketleri Yönet'i seçin.
- Paketleri Yönet bölmesinde Yeni ekle sekmesini seçin.
- Aşağıdaki paketlerin her biri için paket adını girin, Ara'yı ve ardından Yükle'yi seçin.
Çizim histogramı
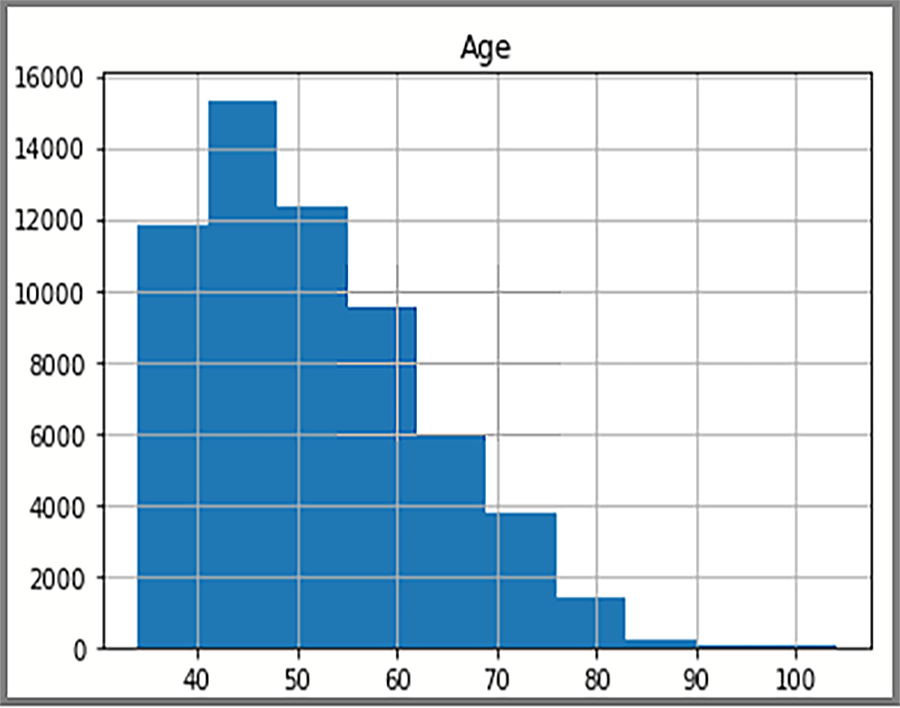
Histogramda görüntülenen dağıtılmış veriler, tarafından yapılan AdventureWorksDW2025bir SQL sorgusunu temel alır. Histogram, verileri ve veri değerlerinin sıklığını görselleştirir.
SQL Server veritabanına bağlanmak için , , serverve database bağlantı dizesi değişkenlerini usernamepassworddüzenleyin.
Yeni not defteri oluşturmak için:
Azure Data Studio'da Dosya'yı ve Yeni Not Defteri'ni seçin.
Not defterinde python3 çekirdeğini seçin ve +code öğesini seçin.
Not defterine kod yapıştırın. Tümünü Çalıştır'ı seçin.
import pyodbc import pandas as pd import matplotlib import sqlalchemy from sqlalchemy import create_engine matplotlib.use('TkAgg', force=True) from matplotlib import pyplot as plt # Some other example server values are # server = 'localhost\sqlexpress' # for a named instance # server = 'myserver,port' # to specify an alternate port server = 'servername' database = 'AdventureWorksDW2022' username = 'yourusername' password = 'databasename' url = 'mssql+pyodbc://{user}:{passwd}@{host}:{port}/{db}?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database) engine = create_engine(url) sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey" df = pd.read_sql(sql, engine) df.hist(bins=50) plt.show()
Ekranda, tablodaki müşterilerin FactInternetSales yaş dağılımı gösterilir.