Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Şunlar için geçerlidir:![]() SQL Server 2016 (13.x) ve sonraki sürümleri
SQL Server 2016 (13.x) ve sonraki sürümleri ![]() Azure SQL Yönetilen Örnek
Azure SQL Yönetilen Örnek
Bu dört bölümden oluşan öğretici serisinin üçüncü bölümünde, kümeleme gerçekleştirmek için R'de bir K-Means modeli oluşturacaksınız. Bu serinin sonraki bölümünde, bu modeli SQL Server Machine Learning Services içeren bir veritabanında veya Büyük Veri Kümelerinde dağıtacaksınız.
Bu dört bölümden oluşan öğretici serisinin üçüncü bölümünde, kümeleme gerçekleştirmek için R'de bir K-Means modeli oluşturacaksınız. Bu serinin sonraki bölümünde bu modeli SQL Server Machine Learning Services ile bir veritabanına dağıtacaksınız.
Bu dört bölümden oluşan öğretici serisinin üçüncü bölümünde, kümeleme gerçekleştirmek için R'de bir K-Means modeli oluşturacaksınız. Bu serinin sonraki bölümünde, bu modeli SQL Server R Services ile bir veritabanına dağıtacaksınız.
Bu dört bölümden oluşan öğretici serisinin üçüncü bölümünde, kümeleme gerçekleştirmek için R'de bir K-Means modeli oluşturacaksınız. Bu serinin sonraki bölümünde bu modeli Azure SQL Yönetilen Örneği Machine Learning Services ile bir veritabanına dağıtacaksınız.
Bu makalede şunları nasıl yapacağınızı öğreneceksiniz:
- K ortalamaları algoritması için küme sayısını tanımlama
- Kümeleme gerçekleştirme
- Sonuçları analiz etme
Birinci bölümde önkoşulları yüklemiş ve örnek veritabanını geri yüklemişsinizdir.
İkinci bölümde, kümeleme gerçekleştirmek için veritabanındaki verileri nasıl hazırlayabileceğinizi öğrendinsiniz.
Dördüncü bölümde, yeni verilere göre R'de kümeleme gerçekleştirebilen bir veritabanında saklı yordam oluşturmayı öğreneceksiniz.
Önkoşullar
- Bu öğretici serisinin üçüncü bölümünde, birinci bölümün önkoşullarını yerine getirdiğiniz ve ikinci bölümdeki adımları tamamladığınız varsayılır.
Küme sayısını tanımlama
Müşteri verilerinizi kümelendirmek için, verileri gruplandırmanın en basit ve en iyi bilinen yollarından biri olan K-Means kümeleme algoritmasını kullanacaksınız. K-Ortalamalar ile ilgili daha fazla bilgiyi K-Ortalamalar kümeleme algoritmasına yönelik eksiksiz bir kılavuz adlı rehberde bulabilirsiniz.
Algoritma iki girişi kabul eder: Verilerin kendisi ve oluşturulacak küme sayısını temsil eden önceden tanımlanmış bir "k" sayısı. Çıkış, giriş verilerinin kümeler arasında bölümlendiği k kümeleridir.
Algoritmanın kullanılacak küme sayısını belirlemek için, ayıklanan küme sayısına göre grupların içindeki karelerin toplamını gösteren bir çizim kullanın. Kullanılacak uygun küme sayısı, grafiğin büküm noktası veya "dirsek"indedir.
# Determine number of clusters by using a plot of the within groups sum of squares,
# by number of clusters extracted.
wss <- (nrow(customer_data) - 1) * sum(apply(customer_data, 2, var))
for (i in 2:20)
wss[i] <- sum(kmeans(customer_data, centers = i)$withinss)
plot(1:20, wss, type = "b", xlab = "Number of Clusters", ylab = "Within groups sum of squares")
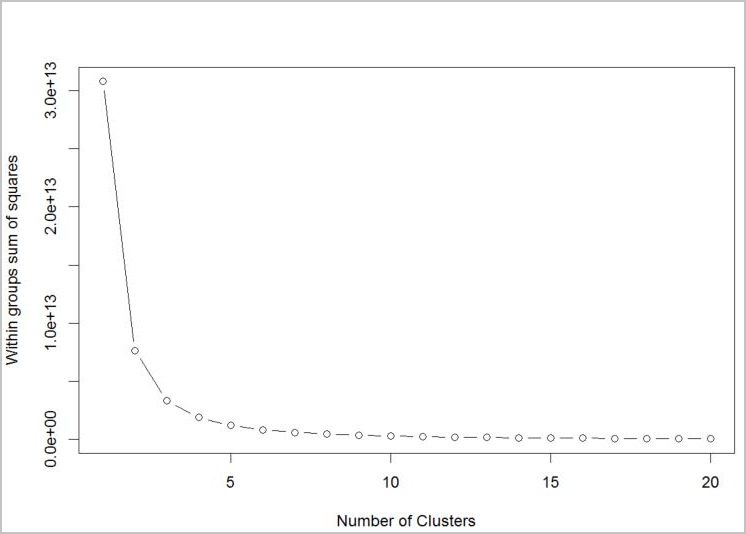
Grafiğe bağlı olarak , k = 4 denemek için iyi bir değer olacaktır. Bu k değeri, müşterileri dört küme halinde gruplandıracaktır.
Kümeleme gerçekleştirme
Aşağıdaki R betiğinde kümeleme gerçekleştirmek için kmeans işlevini kullanacaksınız.
# Output table to hold the customer group mappings.
# Generate clusters using Kmeans and output key / cluster to a table
# called return_cluster
## create clustering model
clust <- kmeans(customer_data[,2:5],4)
## create clustering output for table
customer_cluster <- data.frame(cluster=clust$cluster,customer=customer_data$customer,orderRatio=customer_data$orderRatio,
itemsRatio=customer_data$itemsRatio,monetaryRatio=customer_data$monetaryRatio,frequency=customer_data$frequency)
## write cluster output to DB table
sqlSave(ch, customer_cluster, tablename = "return_cluster")
# Read the customer returns cluster table from the database
customer_cluster_check <- sqlFetch(ch, "return_cluster")
head(customer_cluster_check)
Sonuçları analiz etme
Kümeleme işlemini K-Means kullanarak gerçekleştirdiğinize göre, sonraki adım sonucu analiz etmek ve eyleme dönüştürülebilir herhangi bir bilgi bulup bulamayacağınızı görmektir.
#Look at the clustering details to analyze results
clust[-1]
$centers
orderRatio itemsRatio monetaryRatio frequency
1 0.621835791 0.1701519 0.35510836 1.009025
2 0.074074074 0.0000000 0.05886575 2.363248
3 0.004807692 0.0000000 0.04618708 5.050481
4 0.000000000 0.0000000 0.00000000 0.000000
$totss
[1] 40191.83
$withinss
[1] 19867.791 215.714 660.784 0.000
$tot.withinss
[1] 20744.29
$betweenss
[1] 19447.54
$size
[1] 4543 702 416 31675
$iter
[1] 3
$ifault
[1] 0
Dört küme ortalaması , ikinci bölümde tanımlanan değişkenler kullanılarak verilir:
- orderRatio = iade siparişi oranı (kısmen veya tamamen iade edilen toplam sipariş sayısı ile toplam sipariş sayısı)
- itemsRatio = iade öğesi oranı (döndürülen toplam öğe sayısı ile satın alınan ürün sayısı)
- monetaryRatio = getiri tutarı oranı (döndürülen toplam parasal öğe miktarı ile satın alınan tutar)
- frequency = dönüş sıklığı
K-Means ile veri madenciliği, genellikle sonuçların daha fazla analizini ve her kümeyi daha iyi anlamak için ek adımlar gerektirir; ancak bazı iyi ipuçları sağlayabilir. Bu sonuçları yorumlamanın birkaç yolu şunlardır:
- Küme 1 (en büyük küme) etkin olmayan bir müşteri grubu gibi görünüyor (tüm değerler sıfırdır).
- Küme 3, dönüş davranışı açısından öne çıkan bir grup gibi görünüyor.
Kaynakları temizle
Bu öğreticiye devam etmeyecekseniz tpcxbb_1gb veritabanını silin.
Sonraki Adımlar
Bu öğretici serisinin üçüncü bölümünde şunların nasıl yapılacağını öğrendiniz:
- K ortalamaları algoritması için küme sayısını tanımlama
- Kümeleme gerçekleştirme
- Sonuçları analiz etme
Oluşturduğunuz makine öğrenmesi modelini dağıtmak için bu öğretici serisinin dördüncü bölümünü izleyin: