Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Şunlar için geçerlidir:![]() SQL Server
SQL Server![]() Azure SQL Veritabanı
Azure SQL Veritabanı![]() Azure SQL Yönetilen Örneği
Azure SQL Yönetilen Örneği![]() Microsoft Fabric'te SQL veritabanı
Microsoft Fabric'te SQL veritabanı
SQL Server Veritabanı Altyapısı, yerel tablolar, bölümlenmiş tablolar ve birden çok sunucuya dağıtılmış tablolar gibi çeşitli veri depolama mimarilerindeki sorguları işler. Aşağıdaki bölümlerde SQL Server'ın sorguları işleme ve yürütme planı önbelleğe alma yoluyla sorgu yeniden kullanmayı iyileştirme işlemleri ele alınıyor.
Yürütme modları
SQL Server Veritabanı Altyapısı, iki ayrı işleme modu kullanarak Transact-SQL deyimlerini işleyebilir:
- Satır modu yürütme
- Toplu modda yürütme
Satır modu yürütme
Satır modu yürütme , verilerin satır biçiminde depolandığı geleneksel RDBMS tablolarıyla kullanılan bir sorgu işleme yöntemidir. Sorgu yürütülür ve satır deposu tablolarındaki verilere eriştiğinde, yürütme ağacı işleçleri ve alt işleçler tablo şemasında belirtilen tüm sütunlar genelinde gerekli satırları okur. Okunan her satırdan SQL Server, bir SELECT deyimi, JOIN koşulu veya filtre koşulunun gerektirdiği şekilde sonuç kümesi için gerekli sütunları alır.
Uyarı
Satır modu yürütme, OLTP senaryoları için çok verimlidir, ancak örneğin Veri Ambarı senaryolarında büyük miktarda veriyi tararken daha az verimli olabilir.
Toplu modda yürütme
Batch modu yürütmesi, birçok satırı bir arada işlemek için kullanılan bir sorgu işleme yöntemidir (bu yüzden de buna toplu işleme denir). Toplu iş içindeki her sütun, ayrı bir bellek alanında vektör olarak depolanır, bu nedenle toplu iş modu işleme vektör tabanlıdır. Toplu iş modu işleme, modern donanımda bulunan çok çekirdekli CPU'lar ve daha yüksek bellek aktarım hızı için iyileştirilmiş algoritmalar da kullanır.
İlk kez tanıtıldığında, toplu iş modu yürütmesi sütun deposu depolama formatıyla yakından entegre edilmiş ve bu forma göre optimize edilmiştir. Ancak, SQL Server 2019 (15.x) ve Azure SQL Veritabanı'nda başlayarak toplu iş modu yürütmesi artık columnstore dizinleri gerektirmez. Daha fazla bilgi için bkz. Rowstore'da Batch modu.
Toplu iş modu, mümkün olduğunda sıkıştırılmış veriler üzerinde çalışır ve satır modu yürütme tarafından kullanılan exchange işlecini ortadan kaldırır. Sonuç daha iyi paralellik ve daha hızlı performanstır.
Bir sorgu toplu iş modunda yürütülür ve columnstore dizinlerindeki verilere eriştiğinde, yürütme ağacı işleçleri ve alt işleçler sütun kesimlerinde birden çok satırı birlikte okur. SQL Server, SELECT ifadesi, JOIN koşulu veya filtre koşuluna göre başvurulan, yalnızca sonuç için gereken sütunları okur. Columnstore dizinleri hakkında daha fazla bilgi için bkz. Columnstore Dizin Mimarisi.
Uyarı
Toplu iş modu yürütmesi, büyük miktarda verinin okunduğu ve toplandığı çok verimli Veri Ambarı senaryolarıdır.
SQL deyimi işleme
Tek bir Transact-SQL deyimini işlemek, SQL Server'ın Transact-SQL deyimlerini yürütmesinin en temel yoludur. Yalnızca yerel temel tablolara (görünüm veya uzak tablo olmadan) başvuran tek SELECT bir deyimi işlemek için kullanılan adımlar temel işlemi gösterir.
Mantıksal işleç önceliği
Bir deyimde birden fazla mantıksal işleç kullanıldığında, NOT önce , sonra ANDve son olarak ORdeğerlendirilir. Aritmetik ve bit düzeyinde işleçler mantıksal işleçler öncesinde işlenir. Daha fazla bilgi için bkz. İşleç Önceliği.
Aşağıdaki örnekte, renk koşulu 21 numaralı ürün modeliyle ilgilidir, çünkü ANDOR üzerinde önceliğe sahiptir, bu nedenle 20 numaralı ürün modeliyle ilgili değildir.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
Parantez ekleyerek OR'nın öncelikli değerlendirilmesini sağlamak için sorgunun anlamını değiştirebilirsiniz. Aşağıdaki sorgu yalnızca 20 ve 21 modellerinin altındaki kırmızı olan ürünleri bulur.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
Parantezlerin kullanılması, gerekli olmasa bile sorguların okunabilirliğini artırabilir ve işleç önceliği nedeniyle küçük bir hata yapma olasılığını azaltabilir. Parantezlerin kullanılmasında önemli bir performans cezası yoktur. Aşağıdaki örnek, özgün örnekten daha okunabilir, ancak sentaktik olarak aynıdırlar.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
SELECT deyimlerini iyileştirme
Deyim SELECT yordamsal değildir; veritabanı sunucusunun istenen verileri almak için kullanması gereken adımları tam olarak belirtmez. Bu, veritabanı sunucusunun istenen verileri ayıklamanın en verimli yolunu belirlemek için deyimini analiz etmesi gerektiği anlamına gelir. Bu, SELECT ifadesinin optimize edilmesi olarak adlandırılır. Bunu sağlayan bileşen, Sorgu İyileştiricisi olarak adlandırılır. Sorgu İyileştiricisi girişi sorgudan, veritabanı şemasından (tablo ve dizin tanımları) ve veritabanı istatistiklerinden oluşur. Sorgu İyileştiricisi'nin çıkışı, bazen sorgu planı veya yürütme planı olarak adlandırılan bir sorgu yürütme planıdır. Yürütme planının içeriği bu makalenin devamında daha ayrıntılı olarak açıklanmıştır.
Tek SELECT bir deyimin iyileştirilmesi sırasında Sorgu İyileştiricisi'nin girişleri ve çıkışları aşağıdaki diyagramda gösterilmiştir:
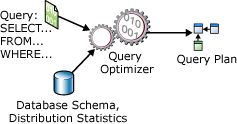
Deyimi SELECT yalnızca aşağıdakileri tanımlar:
- Sonuç kümesinin biçimi. Bu çoğunlukla seçme listesinde belirtilir. Ancak diğer yan tümceler örneğin
ORDER BYveGROUP BY, sonuç kümesinin son biçimini de etkiler. - Kaynak verileri içeren tablolar. Bu,
FROMmaddesinde belirtilir. - Tabloların ifadenin amaçları için mantıksal olarak nasıl ilişkili olduğu. Bu durum,
WHEREyan tümcesinde veya aşağıdakiONardından gelen birFROMyan tümcesinde görülebilen birleştirme özelliklerinde tanımlanır. - Kaynak tablolardaki satırların
SELECTifadesini karşılaması için gereken koşullar. BunlarWHEREveHAVINGyan tümcelerinde belirtilir.
Sorgu yürütme planı aşağıdakilerin tanımıdır:
Kaynak tablolara erişilen sıra.
Genellikle, veritabanı sunucusunun sonuç kümesini oluşturmak için temel tablolara erişebildiği birçok dizi vardır. Örneğin,SELECTdeyimi üç tabloya başvuruyorsa, veritabanı sunucusu önceTableAöğesine erişebilir,TableAiçindeki verileri kullanarakTableBiçindeki eşleşen satırları ayıklayabilir ve ardındanTableBiçindeki verileri kullanarakTableCiçindeki verileri ayıklayabilir. Veritabanı sunucusunun tablolara erişebildiği diğer sıralar şunlardır:
TableC,TableB,TableAveya
TableB,TableA,TableCveya
TableB,TableC,TableAveya
TableC,TableA,TableBHer tablodan veri ayıklamak için kullanılan yöntemler.
Genel olarak, her tablodaki verilere erişmek için farklı yöntemler vardır. Belirli anahtar değerlerine sahip yalnızca birkaç satır gerekiyorsa, veritabanı sunucusu bir dizin kullanabilir. Tablodaki tüm satırlar gerekliyse, veritabanı sunucusu dizinleri yoksayabilir ve tablo taraması gerçekleştirebilir. Tablodaki tüm satırlar gerekliyse ancak anahtar sütunlarıORDER BYiçinde olan bir dizin varsa, tablo taraması yerine dizin taraması yapmak, sonuç kümesinin ayrı bir türünü kaydedebilir. Tablo çok küçükse, tablo taramaları tabloya neredeyse tüm erişim için en verimli yöntem olabilir.Hesaplamaları hesaplamak için kullanılan yöntemler ve her tablodan verileri filtreleme, toplama ve sıralama.
Tablolardan verilere erişildiğinde, skaler değerleri hesaplama ve sorgu metninde tanımlandığı gibi verileri toplama ve sıralama gibi farklı yöntemler vardır. Örneğin,GROUP BYveyaORDER BYyan tümcesi kullanılırken ve örneğinWHEREveyaHAVINGyan tümcesi kullanılırken verileri filtreleme.
Olası birçok plandan bir yürütme planı seçme işlemi iyileştirme olarak adlandırılır. Sorgu İyileştiricisi, Veritabanı Altyapısı'nın en önemli bileşenlerinden biridir. Sorgu İyileştiricisi tarafından sorguyu analiz etmek ve bir plan seçmek için biraz yük kullanılır; ancak Sorgu İyileştiricisi etkili bir yürütme planı seçtiğinde bu yük genellikle birkaç kat tasarruf edilir. Örneğin, iki inşaat şirketine bir ev için aynı şemalar verilebilir. Bir şirket, evi nasıl inşa edeceklerini planlamak için başlangıçta birkaç gün geçirirse ve diğer şirket planlama yapmadan bina yapmaya başlarsa, projesini planlamak için zaman alan şirket muhtemelen önce tamamlanır.
SQL Server Sorgu İyileştiricisi maliyet tabanlı bir iyileştiricidir. Her olası yürütme planının, kullanılan bilgi işlem kaynaklarının miktarı açısından ilişkili bir maliyeti vardır. Sorgu İyileştirici olası planları analiz etmeli ve tahmini maliyeti en düşük olanı seçmelidir. Bazı karmaşık SELECT deyimlerde binlerce olası yürütme planı vardır. Bu gibi durumlarda Sorgu İyileştiricisi tüm olası birleşimleri analiz etmez. Bunun yerine, maliyeti mümkün olan en düşük maliyete oldukça yakın bir yürütme planı bulmak için karmaşık algoritmalar kullanır.
SQL Server Sorgu İyileştiricisi yalnızca en düşük kaynak maliyetine sahip yürütme planını seçmez; kaynaklarda makul bir maliyetle kullanıcıya sonuçları döndüren ve sonuçları en hızlı şekilde döndüren planı seçer. Örneğin, bir sorguyu paralel olarak işlemek genellikle seri olarak işlemeye kıyasla daha fazla kaynak kullanır, ancak sorguyu daha hızlı tamamlar. SQL Server Sorgu İyileştiricisi, sunucudaki yük olumsuz etkilenmezse sonuçları döndürmek için paralel bir yürütme planı kullanır.
SQL Server Sorgu İyileştiricisi, bir tablo veya dizinden bilgi ayıklamak için farklı yöntemlerin kaynak maliyetlerini tahmin ettiğinde dağıtım istatistiklerine dayanır. Dağıtım istatistikleri sütunlar ve dizinler için tutulur ve temel alınan verilerin yoğunluk 1'ine ilişkin bilgileri tutar. Bu, belirli bir dizin veya sütundaki değerlerin seçiciliğini göstermek için kullanılır. Örneğin, arabaları temsil eden bir tabloda, birçok araba aynı üreticiye sahiptir, ancak her arabanın benzersiz bir araç kimlik numarası (VIN) vardır. VIN üzerindeki bir dizin, üreticideki bir dizinden daha seçicidir, çünkü VIN üreticiden daha düşük yoğunluğa sahiptir. Dizin istatistikleri geçerli değilse, Sorgu İyileştiricisi tablonun geçerli durumu için en iyi seçimi yapamayabilir. Yoğunluklar hakkında daha fazla bilgi için bkz. İstatistikler.
1 Yoğunluk, verilerde bulunan benzersiz değerlerin dağılımını veya belirli bir sütun için ortalama yinelenen değer sayısını tanımlar. Yoğunluk azaldıkça değerin seçiciliği artar.
SQL Server Sorgu İyileştiricisi, veritabanı sunucusunun programcı veya veritabanı yöneticisinden giriş gerektirmeden veritabanındaki değişen koşullara dinamik olarak ayarlamasını sağladığından önemlidir. Bu, programcıların sorgunun nihai sonucunu açıklamaya odaklanmasını sağlar. SQL Server Sorgu İyileştiricisi'nin, sorgu her çalıştırıldığında veritabanının durumu için verimli bir yürütme planı oluşturacağına güvenilebilir.
Uyarı
SQL Server Management Studio'nun yürütme planlarını görüntülemek için üç seçeneği vardır:
- Sorgu İyileştiricisi tarafından üretilen, derlenmiş plan olan Tahmini Yürütme Planı.
- Derlenen plan ve yürütme bağlamı ile aynı olan Gerçek Yürütme Planı. Bu, yürütme tamamlandıktan sonra kullanılabilir çalışma zamanı bilgilerini içerir; örneğin yürütme uyarıları veya Veritabanı Altyapısı'nın daha yeni sürümlerinde yürütme sırasında kullanılan geçen ve CPU süresi.
- Derlenen plan ve yürütme bağlamı ile aynı olan Canlı Sorgu İstatistikleri. Bu, yürütme ilerlemesi sırasında çalışma zamanı bilgilerini içerir ve her saniye güncelleştirilir. Çalışma zamanı bilgileri, örneğin işlemcilerden geçen gerçek satır sayısını içerir.
SELECT deyimini işleme
SQL Server'ın tek bir SELECT deyimini işlemek için kullandığı temel adımlar şunlardır:
- Ayrıştırıcı deyimi tarar
SELECTve anahtar sözcükler, ifadeler, işleçler ve tanımlayıcılar gibi mantıksal birimlere böler. - Bazen sıralı ağaç olarak da adlandırılan bir sorgu ağacı, kaynak verileri sonuç kümesinin gerektirdiği biçime dönüştürmek için gereken mantıksal adımları açıklayan şekilde oluşturulur.
- Sorgu İyileştiricisi, kaynak tablolara farklı yollarla erişilebildiğini analiz eder. Daha sonra daha az kaynak kullanırken sonuçları en hızlı döndüren adım dizisini seçer. Sorgu ağacı, tam olarak bu adım serisini kaydedecek şekilde güncelleştirilir. Sorgu ağacının son, iyileştirilmiş sürümü yürütme planı olarak adlandırılır.
- İlişkisel motor yürütme planını uygulamaya başlar. Temel tablolardan veri gerektiren adımlar işlenirken ilişkisel altyapı, depolama altyapısının ilişkisel altyapıdan istenen satır kümelerinden veri geçirmesini ister.
- İlişkisel altyapı, depolama altyapısından döndürülen verileri sonuç kümesi için tanımlanan biçime işler ve sonuç kümesini istemciye döndürür.
Sürekli katlama ve ifade değerlendirmesi
SQL Server, sorgu performansını geliştirmek için bazı sabit ifadeleri erken değerlendirir. Sorgu iyileştiricisi tarafından kullanılan bu iyileştirme tekniği, ifadeleri çalışma zamanında değil derleme zamanında basitleştirmeyi amaçlar. Sonuçta elde edilen yürütme planının daha verimli olması için sorgu derlemesi sırasında sabit ifadelerin değerlendirilmesi gerekir. Bu, sabit katlama olarak adlandırılır. Sabit, 3, 'ABC', '2005-12-31', 1.0e3 veya 0x12345678 gibi Transact-SQL literali olan bir değişmez değerdir. Örneğin, şu sorguyu alın:
SELECT * FROM Orders WHERE OrderDate < DATEADD(day, 30 * 12, '2020-01-01');
Burada 30 * 12 sabit bir ifadedir. SQL Server derleme sırasında bunu değerlendirebilir ve sorguyu dahili olarak şu şekilde yeniden yazabilir:
SELECT * FROM Orders WHERE OrderDate < DATEADD(day, 360, '2020-01-01');
Katlanabilir ifadeler
SQL Server, aşağıdaki ifade türleriyle sürekli katlama kullanır:
- Aritmetik ifadeler, yalnızca sabitleri içeren
1 + 1ve5 / 3 * 2gibi. - Yalnızca sabitleri içeren mantıksal ifadeler,
1 = 1ve1 > 2 AND 3 > 4gibi. - SQL Server tarafından katlanabilir olarak kabul edilen yerleşik işlevler,
CASTveCONVERTgibi. Genellikle iç işlev, SET seçenekleri, dil ayarları, veritabanı seçenekleri ve şifreleme anahtarları gibi diğer bağlamsal bilgilerin değil yalnızca girişlerinin bir işleviyse katlanabilir. Belirsiz işlevler katlanabilir değildir. Bazı özel durumlar dışında deterministik yerleşik işlevler katlanabilir. - CLR kullanıcı tanımlı türlerin ve belirlenimci skaler değerli CLR kullanıcı tanımlı işlevlerinin (SQL Server 2012 (11.x) ile başlayarak) belirlenimci yöntemleri. Daha fazla bilgi için CLR User-Defined İşlevleri ve Yöntemleri için Sabit Katlama sayfasına bakın.
Uyarı
Büyük nesne türleri için özel durum oluşturulur. Katlama işleminin çıkış türü büyük bir nesne türüyse (text,ntext, image, nvarchar(max), varchar(max), varbinary(max) veya XML), SQL Server ifadeyi katlamaz.
Katlanamayan ifadeler
Diğer tüm ifade türleri katlanabilir değildir. Özellikle, aşağıdaki ifade türleri katlanabilir değildir:
- Sonucu bir sütunun değerine bağlı olan ifade gibi tutarsız ifadeler.
- Sonuçları gibi yerel bir değişkene veya parametreye @xbağlı olan ifadeler.
- Belirsiz işlevler.
- Kullanıcı tanımlı Transact-SQL işlevleri1.
- Sonuçları dil ayarlarına bağlı olan ifadeler.
- Sonuçları SET seçeneklerine bağlı olan ifadeler.
- Sonuçları sunucu yapılandırma seçeneklerine bağlı olan ifadeler.
1 SQL Server 2012 (11.x) öncesinde, belirleyici skaler değerli CLR kullanıcı tanımlı işlevler ve CLR kullanıcı tanımlı türlerin yöntemleri katlanabilir değildi.
Katlanabilir ve katlanabilir olmayan sabit ifade örnekleri
Aşağıdaki sorguyu göz önünde bulundurun:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
Bu sorgu için veritabanı seçeneği olarak PARAMETERIZATION ayarlı FORCED değilse, sorgu derlenmeden önce ifade 117.00 + 1000.00 değerlendirilir ve sonucuyla 1117.00 değiştirilir. Bu sabit katlamanın avantajları şunlardır:
- İfadenin çalışma zamanında tekrar tekrar değerlendirilmesi gerekmez.
- değerlendirildikten sonra ifadenin değeri, Sorgu İyileştiricisi tarafından sorgunun
TotalDue > 117.00 + 1000.00bölümünün sonuç kümesinin boyutunu tahmin etmek için kullanılır.
Öte yandan, eğer dbo.f tek değerli bir kullanıcı tanımlı işlevse, SQL Server, belirleyici olsalar bile kullanıcı tanımlı işlevler içeren ifadeleri katlamadığından, ifade dbo.f(100) katlanmaz. Parametreleştirme hakkında daha fazla bilgi için bu makalenin devamında yer alan Zorlamalı Parametreleştirme bölümüne bakın.
İfade değerlendirmesi
Buna ek olarak, sabit katlanmamış ancak bağımsız değişkenleri derleme zamanında bilinen, bağımsız değişkenlerin parametre mi yoksa sabit mi olduğu bilinen bazı ifadeler, iyileştirme sırasında iyileştiricinin bir parçası olan sonuç kümesi boyutu (kardinalite) tahmin aracı tarafından değerlendirilir.
Özellikle, aşağıdaki yerleşik işlevler ve özel işleçler, tüm girişleri biliniyorsa derleme zamanında değerlendirilir: UPPER, , LOWERRTRIM, DATEPART( YY only ), , GETDATE, CASTve CONVERT. Aşağıdaki işleçler, tüm girişleri biliniyorsa derleme zamanında da değerlendirilir:
- Aritmetik işleçler: +, -, *, /, tekli -
- Mantıksal İşleçler:
AND,OR,NOT - Karşılaştırma işleçleri: <, >, <=, >=, <>,
LIKE,IS NULLIS NOT NULL
Kardinalite tahmini sırasında Sorgu İyileştiricisi tarafından başka hiçbir işlev veya işleç değerlendirilmez.
Derleme zamanı ifade değerlendirmesi örnekleri
Bu saklı yordamı dikkate alın:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Yordamdaki deyiminin SELECT iyileştirilmesi sırasında Sorgu İyileştiricisi, koşul OrderDate > @d+1için sonuç kümesinin beklenen kardinalitesini değerlendirmeye çalışır. İfade @d+1, sabit katlanmış değildir, çünkü @d bir parametredir. Ancak, iyileştirme zamanında parametresinin değeri bilinir. Bu, Sorgu İyileştirici'nin sonuç kümesinin boyutunu doğru bir şekilde tahmin etmesine olanak tanır ve bu da iyi bir sorgu planı seçmesine yardımcı olur.
Şimdi önceki örneğe benzer bir durum düşünün, ancak burada @d2, sorgudaki @d+1 yerine yerel bir değişken olarak kullanılır ve ifade sorguda değil, SET deyiminde değerlendirilir.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
SELECT deyimi MyProc2 SQL Server'da optimize edildiğinde, @d2 değerinin ne olduğu bilinmez. Bu nedenle Sorgu İyileştiricisi, seçiciliği OrderDate > @d2için varsayılan bir tahmin kullanır (bu örnekte yüzde 30).
Diğer ifadeleri işleme
Bir SELECT deyimini işlemek için açıklanan temel adımlar, , INSERTve UPDATEgibi DELETEdiğer Transact-SQL deyimleri için geçerlidir.
UPDATE ve DELETE deyimlerinin her ikisinin de değiştirilecek veya silinecek satır kümesini hedeflemesi gerekir. Bu satırları tanımlama işlemi, bir SELECT deyiminin sonuç kümesine katkıda bulunan kaynak satırları tanımlamak için kullanılan işlemle aynıdır.
UPDATE ve INSERT deyimleri, güncelleştirilecek veya eklenecek veri değerlerini sağlayan katıştırılmış SELECT deyimler içerebilir.
Veri Tanım Dili (DDL) deyimleri, örneğin CREATE PROCEDURE veya ALTER TABLE gibi, nihayetinde sistem kataloğu tablolarında ve bazen de (örneğin ALTER TABLE ADD COLUMN gibi) veri tablolarında bir dizi ilişkisel işlemle çözümlenir.
Çalışma Masaları
İlişkisel Altyapı'nın bir Transact-SQL deyiminde belirtilen mantıksal işlemi gerçekleştirmek için bir çalışma tablosu oluşturması gerekebilir. Worktable'lar ara sonuçları tutmak için kullanılan iç tablolardır. Çalışma masaları belirli GROUP BY, ORDER BYveya UNION sorgular için oluşturulur. Örneğin, bir ORDER BY madde, herhangi bir dizin kapsamında olmayan sütunlara başvuruyorsa, İlişkisel Motor, sonuç kümesini istenen sıraya göre sıralamak için bir çalışma tablosu oluşturmak zorunda kalabilir. Çalışma tabloları, bazen sorgu planının bir bölümünün yürütülmesinin sonucunu geçici olarak tutan makaralar olarak da kullanılır. Bu çalışma masaları yerleşiktir tempdb ve artık gerekli olmadıklarında otomatik olarak kaldırılır.
Çözünürlüğü görüntüle
SQL Server sorgu işlemcisi dizinlenmiş ve dizine alınmamış görünümleri farklı şekilde ele almaktadır:
- Dizine alınan bir görünümün satırları veritabanında tabloyla aynı biçimde depolanır. Sorgu İyileştiricisi bir sorgu planında dizinlenmiş bir görünüm kullanmaya karar verirse, dizine alınan görünüm temel tabloyla aynı şekilde değerlendirilir.
- Görünümün satırları değil, yalnızca dizinlenmemiş görünümün tanımı depolanır. Sorgu İyileştiricisi, görünüm tanımındaki mantığı, dizinlenmemiş görünüme başvuran Transact-SQL deyimi için oluşturduğu yürütme planına ekler.
SQL Server Sorgu İyileştiricisi tarafından dizinlenmiş görünümün ne zaman kullanılacağına karar vermek için kullanılan mantık, bir tabloda dizini ne zaman kullanacağınıza karar vermek için kullanılan mantığa benzer. Dizinli görünümdeki veriler Transact-SQL deyiminin tamamını veya bir bölümünü kapsıyorsa ve Sorgu İyileştiricisi görünümdeki bir dizinin düşük maliyetli erişim yolu olduğunu belirlerse, sorgudaki ada göre başvurulup başvurulmadığına bakılmaksızın Sorgu İyileştirici dizini seçer.
Transact-SQL deyimi dizinlenmemiş bir görünüme başvurduğunda, ayrıştırıcı ve Sorgu İyileştiricisi hem Transact-SQL deyiminin hem de görünümün kaynağını analiz eder ve sonra bunları tek bir yürütme planında çözümler. Transact-SQL ifadesi için tek bir plan yoktur ve görünüm için ayrı bir plan da bulunmamaktadır.
Örneğin, aşağıdaki görünümü göz önünde bulundurun:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
Bu görünüme bağlı olarak, bu Transact-SQL deyimlerinin her ikisi de temel tablolarda aynı işlemleri gerçekleştirir ve aynı sonuçları üretir:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
SQL Server Management Studio Showplan özelliği, ilişkisel altyapının bu SELECT deyimlerin her ikisi için de aynı yürütme planını oluşturduğunu gösterir.
Görünümlerle ipuçları kullan
Sorgudaki görünümlere yerleştirilen ipuçları, görünüm temel tablolarına erişmek üzere genişletildiğinde bulunan diğer ipuçlarıyla çakışabilir. Bu durum oluştuğunda sorgu bir hata döndürür. Örneğin, tanımında tablo ipucu içeren aşağıdaki görünümü göz önünde bulundurun:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Şimdi şu sorguyu girdiğinizi varsayalım:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
Sorgu başarısız oluyor, çünkü sorgudaki görünüme SERIALIZABLE uygulanan ipucu Person.AddrState, genişletildiğinde hem görünüme hem de görünüme dahil olan tablolara Person.Address ve Person.StateProvince yayılıyor. Ancak, görünümün genişletilmesi NOLOCK üzerinde Person.Address ipucunu da ortaya çıkarır.
SERIALIZABLE ve NOLOCK ipuçları çakıştığı için, sonuçta elde edilen sorgu yanlıştır.
PAGLOCK, NOLOCK, , ROWLOCK, TABLOCKveya TABLOCKX tablo ipuçları gibi, HOLDLOCKNOLOCKREADCOMMITTED, veya REPEATABLEREADSERIALIZABLE tablo ipuçları da birbiriyle çakışıyor.
İpuçları iç içe görünümlerin düzeyleri aracılığıyla yayılabilir. Örneğin, bir sorgunun HOLDLOCK ipucunu bir görünüme v1 uyguladığını varsayalım. Genişletildiğinde v1 , görünümün v2 tanımının bir parçası olduğunu fark ederiz.
v2'nin tanımı, temel tablolarından biriyle ilgili bir NOLOCK ipucu içerir. Ancak bu tablo, ipucunu HOLDLOCK görünümündeki v1sorgudan da devralır.
NOLOCK ve HOLDLOCK ipuçları çakıştığı için sorgu başarısız olur.
FORCE ORDER İpucu, görünüm içeren bir sorguda kullanıldığında, görünümdeki tabloların birleştirme sırası, görünümün sıralı yapıdaki konumuna göre belirlenir. Örneğin, aşağıdaki sorgu üç tablodan ve bir görünümden seçim yapar:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
Ve View1 aşağıda gösterildiği gibi tanımlanır:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
Sorgu planındaki birleştirme sırası Table1, Table2, TableA, TableB, Table3 şeklindedir.
Görünümlerde dizinleri çözme
Tüm dizinlerde olduğu gibi SQL Server da sorgu planında dizine alınan bir görünümü kullanmayı yalnızca Sorgu İyileştiricisi bunun yararlı olduğunu belirlerse seçer.
Dizinli görünümler, SQL Server'ın herhangi bir sürümünde oluşturulabilir. SQL Server'ın bazı eski sürümlerinin bazı sürümlerinde, Sorgu İyileştiricisi otomatik olarak dizinlenmiş görünümü dikkate alır. SQL Server'ın bazı eski sürümlerinin bazı sürümlerinde, dizinli görünüm NOEXPAND kullanmak için tablo ipucu kullanılmalıdır. Sorgu iyileştiricisi tarafından dizine alınan bir görünümün otomatik kullanımı yalnızca SQL Server'ın belirli sürümlerinde desteklenir. Azure SQL Veritabanı ve Azure SQL Yönetilen Örneği, NOEXPAND ipucunu belirtmeden dizinlenmiş görünümlerin otomatik kullanımını da destekler.
SQL Server Sorgu İyileştiricisi, aşağıdaki koşullar karşılandığında dizinli bir görünüm kullanır:
- Bu oturum seçenekleri olarak
ONayarlanır:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- Oturum
NUMERIC_ROUNDABORTseçeneği KAPALI olarak ayarlanır. - Sorgu İyileştiricisi, görünüm dizini sütunları ve sorgudaki öğeler arasında aşağıdaki gibi bir eşleşme bulur:
- WHERE yan tümcesindeki arama koşulları
- Birleştirme işlemleri
- Toplama işlevleri
-
GROUP BYCümleler - Tablo referansları
- Dizini kullanmanın tahmini maliyeti, Sorgu İyileştiricisi tarafından dikkate alınacak erişim mekanizmalarının en düşük maliyetine sahiptir.
- Dizinli görünümdeki bir tablo başvurusuna karşılık gelen sorguda başvuruda bulunan her tabloda (doğrudan veya temel tablolarına erişmek için bir görünümü genişleterek) sorguda aynı ipuçları kümesi uygulanmalıdır.
Uyarı
READCOMMITTED ve READCOMMITTEDLOCK ipuçları, geçerli işlem yalıtım düzeyi ne olursa olsun bu bağlamda her zaman farklı ipuçları olarak kabul edilir.
Seçenekler ve tablo ipuçları gereksinimleri SET dışında, bunlar Sorgu İyileştiricisi'nin tablo dizininin sorguyu kapsayıp kapsamadığını belirlemek için kullandığı kurallarla aynıdır. Dizine alınan görünümün kullanılabilmesi için sorguda başka hiçbir şeyin belirtilmesine gerek yoktur.
Sorgu İyileştirici'nin dizinlenmiş görünümü kullanması için sorgunun yan tümcesinde FROM dizinlenmiş bir görünüme açıkça başvurması gerekmez. Sorgu, dizinlenmiş görünümde de bulunan temel tablolardaki sütunlara başvurular içeriyorsa ve Sorgu İyileştiricisi dizinlenmiş görünümün kullanılmasıyla en düşük maliyet erişim mekanizmasının sağlandığını tahmin ederse, Sorgu İyileştiricisi dizinlenmiş görünümü seçer; örneğin, sorguda doğrudan başvurulmazsa temel tablo dizinlerini seçme yöntemine benzer. Görünüm, sorguda belirtilen sütunlardan birini veya daha fazlasını kapsayan en düşük maliyet seçeneğini sunduğu sürece, sorgu tarafından referans verilmemiş sütunlar içerse bile Sorgu Optimizasyonu tarafından seçilebilir.
Sorgu İyileştirici, FROM yan tümcesinde referans alınan dizin görünümünü standart görünüm olarak kabul eder. Sorgu İyileştiricisi, iyileştirme işleminin başlangıcında görünümün tanımını sorguya genişletir. Ardından dizinli görünüm eşleştirmesi gerçekleştirilir. Dizine alınmış görünüm, Sorgu İyileştiricisi tarafından seçilen son yürütme planında kullanılabilir veya bunun yerine, plan görünümün başvurmuş olduğu temel tablolara erişerek gerekli verileri görünümden elde edebilir. Sorgu İyileştiricisi en düşük maliyetli alternatifi seçer.
Dizinlenmiş görünümlerle ipuçlarından yararlanma
Sorgu ipucunu kullanarak EXPAND VIEWS görünüm dizinlerinin sorgu için kullanılmasını engelleyebilir veya sorgunun NOEXPAND yan tümcesinde FROM belirtilen dizinli görünüm için dizin kullanımını zorlamak için tablo ipucunu kullanabilirsiniz. Ancak, Sorgu İyileştiricisi'nin her sorgu için kullanılacak en iyi erişim yöntemlerini dinamik olarak belirlemesine izin vermelisiniz. ve EXPAND kullanımınızı, testin NOEXPAND performansı önemli ölçüde artırdığını gösterdiği belirli durumlara sınırlayın.
seçeneği,
EXPAND VIEWSSorgu İyileştiricisi'nin sorgunun tamamı için hiçbir görünüm dizini kullanmadığını belirtir.Bir
NOEXPANDgörünüm için belirtildiğinde, Sorgu İyileştiricisi görünümde tanımlanan tüm dizinleri kullanmayı göz önünde bulundurmaktadır.NOEXPANDisteğe bağlıINDEX()yan tümcesiyle belirtilirse, Sorgu İyileştiricisi belirtilen dizinleri kullanmaya zorlar.NOEXPANDyalnızca dizine alınan bir görünüm için belirtilebilir ve dizine alınmamış bir görünüm için belirtilemez. Sorgu iyileştiricisi tarafından dizine alınan bir görünümün otomatik kullanımı yalnızca SQL Server'ın belirli sürümlerinde desteklenir. Azure SQL Veritabanı ve Azure SQL Yönetilen Örneği,NOEXPANDipucunu belirtmeden dizinlenmiş görünümlerin otomatik kullanımını da destekler.
Görünüm içeren bir sorguda ne NOEXPAND ne de EXPAND VIEWS belirtilmezse, görünüm temel alınan tablolara erişecek şekilde genişletilir. Görünümü oluşturan sorgu herhangi bir tablo ipucu içeriyorsa, bu ipuçları temel alınan tablolara yayılır. (Bu işlem, Çözümü Görüntüle bölümünde daha ayrıntılı olarak açıklanmıştır.) Görünümün temel tablolarında bulunan ipuçları kümesi birbiriyle aynı olduğu sürece, sorgu dizinli bir görünümle eşleştirilmeye uygundur. Çoğu zaman bu ipuçları birbiriyle eşleşecektir çünkü bunlar doğrudan görünümden devralınır. Ancak, sorgu görünümler yerine tablolara başvuruyorsa ve doğrudan bu tablolara uygulanan ipuçları aynı değilse, bu tür bir sorgu dizinli görünümle eşleştirme için uygun değildir.
INDEX, PAGLOCK, , ROWLOCK, TABLOCKX, veya UPDLOCKXLOCK ipuçları görünüm genişletme sonrasında sorguda başvuruda bulunılan tablolara uygulanırsa, sorgu dizinli görünüm eşleştirme için uygun değildir.
Bir sorguda biçiminde INDEX (index_val[ ,...n] ) olan bir tablo belirteci bir görünüme atıfta bulunuyorsa ve belirteci NOEXPAND olarak da belirtmezseniz, dizin belirteci yoksayılır. Belirli bir dizinin kullanımını belirtmek için kullanın NOEXPAND.
Genellikle, Sorgu İyileştiricisi dizine alınan bir görünümü sorguyla eşleştirdiğinde, sorgudaki tablolarda veya görünümlerde belirtilen tüm ipuçları doğrudan dizinlenmiş görünüme uygulanır. Sorgu İyileştiricisi dizinli görünüm kullanmamayı seçerse, tüm ipuçları doğrudan görünümde başvurulan tablolara yayılır. Daha fazla bilgi için bkz. Çözünürlük Görünümü. Bu yayılma join hints için geçerli değildir. Bunlar yalnızca sorgudaki özgün konumlarında uygulanır. Sorguları dizine alınan görünümlerle eşleştirirken Birleştirme ipuçları Sorgu İyileştiricisi tarafından dikkate alınmaz. Sorgu planı, birleştirme ipucu içeren bir sorgunun parçasıyla eşleşen dizinli bir görünüm kullanıyorsa, birleştirme ipucu planda kullanılmaz.
Dizine alınan görünümlerin tanımlarında ipuçlarına izin verilmez. Uyumluluk modunda 80 ve üzeri sürümlerde SQL Server, dizinlenmiş görünüm tanımlarının bakımını yaparken veya dizine alınan görünümleri kullanan sorgular yürütürken dizine alınan görünüm tanımlarının içindeki ipuçlarını yoksayar. Indexli görünüm tanımlarında ipuçlarının kullanılması, 80 uyumluluk modunda söz dizimi hatası oluşturmaz ancak göz ardı edilir.
Daha fazla bilgi için bkz. Tablo İpuçları (Transact-SQL).
Dağıtılmış bölümlenmiş görünümleri çözümleme
SQL Server sorgu işlemcisi, dağıtılmış bölümlenmiş görünümlerin performansını iyileştirir. Dağıtılmış bölümlenmiş görünüm performansının en önemli yönü, üye sunucular arasında aktarılan veri miktarını en aza indirmektir.
SQL Server, uzak üye tablolarındaki verilere erişmek için dağıtılmış sorguları verimli bir şekilde kullanan akıllı, dinamik planlar oluşturur:
- Sorgu İşlemcisi her üye tablosundan denetim kısıtlaması tanımlarını almak için önce OLE DB'yi kullanır. Bu, sorgu işlemcisinin üye tabloları arasında anahtar değerlerinin dağılımını eşlemesine olanak tanır.
- Sorgu İşlemcisi, Transact-SQL deyimi
WHEREyan tümcesinde belirtilen anahtar aralıklarını, satırların üye tablolarında nasıl dağıtıldığını gösteren haritayla karşılaştırır. Sorgu işlemcisi daha sonra dağıtılmış sorguları kullanarak yalnızca Transact-SQL deyimini tamamlamak için gereken uzak satırları alan bir sorgu yürütme planı oluşturur. Yürütme planı ayrıca, veriler veya meta veriler için uzak üye tablolarına erişimin, bilgiler gerekli olana kadar erteleneceği şekilde de oluşturulur.
Örneğin, bir tablonun Server1 (1 ile 3299999 arasında), Server2 (CustomersCustomerID3300000 ile 6599999 arasında) ve Server3 (CustomerID6600000 ile 9999999 arasında) arasında bölümlendiği bir CustomerID sistem düşünün.
Sunucu1'de yürütülen bu sorgu için oluşturulan yürütme planını göz önünde bulundurun:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
Bu sorgunun yürütme planı, anahtar değerleri 3200000 ile CustomerID 3299999 arasındaki satırları yerel üye tablosundan ayıklar ve Server2'den 3300000 ile 3400000 arasındaki anahtar değerlerine sahip satırları almak için dağıtılmış bir sorgu verir.
SQL Server Sorgu İşlemcisi, plan oluşturulması gerektiğinde anahtar değerlerinin bilinmediği Transact-SQL deyimleri için sorgu yürütme planlarına dinamik mantık da oluşturabilir. Örneğin, şu saklı yordamı göz önünde bulundurun:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server, yordam her çalıştırıldığında @CustomerIDParameter parametresi tarafından sağlanacak anahtar değeri tahmin edemez. Anahtar değeri tahmin edilemediğinden, sorgu işlemcisi hangi üye tablosuna erişilmesi gerektiğini de tahmin edemez. Bu durumu işlemek için SQL Server, giriş parametresi değerine bağlı olarak hangi üye tablosuna erişildiğini denetlemek için dinamik filtreler olarak adlandırılan koşullu mantığa sahip bir yürütme planı oluşturur. Saklı yordamın GetCustomer Server1'de yürütüldiği varsayıldığında, yürütme planı mantığı aşağıdaki gibi gösterilebilir:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
SQL Server bazen parametrelendirilmemiş sorgular için bile bu tür dinamik yürütme planları oluşturur. Sorgu İyileştiricisi, yürütme planının yeniden kullanılabilmesi için sorguyu parametreleştirebilir. Sorgu İyileştiricisi bölümlenmiş görünüme başvuran bir sorguyu parametreleştirirse, Sorgu İyileştiricisi artık gerekli satırların belirtilen temel tablodan geleceğini varsaymayabilir. Ardından yürütme planında dinamik filtreler kullanması gerekir.
Saklı yordam ve tetikleyici çalıştırma
SQL Server yalnızca saklı yordamlar ve tetikleyiciler için kaynağı depolar. Saklı yordam veya tetikleyici ilk kez yürütüldüğünde, kaynak bir yürütme planına derlenir. Yürütme planı bellekten eskimeden önce saklı yordam veya tetikleyici yeniden yürütülürse ilişkisel altyapı mevcut planı algılar ve yeniden kullanır. Plan bellekte eskidiyse yeni bir plan oluşturulur. Bu işlem, SQL Server'ın tüm Transact-SQL deyimleri için izlediği işleme benzer. Saklı yordamların ve tetikleyicilerin SQL Server'da dinamik Transact-SQL toplu işlemleriyle karşılaştırıldığında sahip olduğu temel performans avantajı, Transact-SQL deyimlerinin her zaman aynı olmasıdır. Bu nedenle, ilişkisel altyapı bunları mevcut yürütme planlarıyla kolayca eşleştirir. Saklı yordam ve tetikleyici planları kolayca yeniden kullanılabilir.
Saklı yordamlar ve tetikleyiciler için yürütme planı, saklı yordamı çağıran veya tetikleyiciyi tetikleyen toplu işlemin yürütme planından ayrı olarak yürütülür. Bu, saklı yordamın daha fazla yeniden kullanılmasını ve yürütme planlarını tetiklemesini sağlar.
Yürütme planı önbelleğe alma ve yeniden kullanma
SQL Server,hem yürütme planlarını hem de veri arabelleklerini depolamak için kullanılan bir bellek havuzuna sahiptir. Yürütme planlarına veya veri arabelleklerine ayrılan havuzun yüzdesi, sistemin durumuna bağlı olarak dinamik olarak dalgalanma gösterir. Yürütme planlarını depolamak için kullanılan bellek havuzunun parçası plan önbelleği olarak adlandırılır.
Plan önbelleğinin tüm derlenmiş planlar için iki deposu vardır:
- Kalıcı nesnelerle (saklı yordamlar, işlevler ve tetikleyiciler) ilgili planlar için kullanılan Nesne Planları önbellek deposu (OBJCP).
- Otomatik parametreli, dinamik veya hazırlanmış sorgular ile ilgili planlar için kullanılan SQL Planları önbellek deposu (SQLCP).
Aşağıdaki sorgu, bu iki önbellek deposu için bellek kullanımı hakkında bilgi sağlar:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Uyarı
Plan önbelleğinde planları depolamak için kullanılmayan iki ek depo vardır:
- Görünümler, kısıtlamalar ve varsayılanlar için plan derlemesi sırasında kullanılan veri yapıları için İlişkili Ağaçlar önbellek deposu (PHDR) kullanılır. Bu yapılar, Bağlı Ağaçlar veya Cebirci Ağaçları olarak bilinir.
- Önceden tanımlanmış sistem yordamları, veya
sp_executeSqlgibi, Transact-SQL deyimleri yerine DLL kullanılarak tanımlandığında kullanılanxp_cmdshellönbellek deposu (XPROC). Önbelleğe alınan yapı yalnızca yordamın uygulandığı işlev adını ve DLL adını içerir.
SQL Server yürütme planları aşağıdaki ana bileşenlere sahiptir:
Derlenmiş Plan (veya Sorgu Planı)
Derleme işlemi tarafından oluşturulan sorgu planı, çoğunlukla herhangi bir sayıda kullanıcı tarafından kullanılan geri dönüşlü, salt okunur bir veri yapısıdır. Aşağıdakilerle ilgili bilgileri depolar:Mantıksal işleçler tarafından açıklanan işlemi uygulayan fiziksel işleçler.
Verilere erişilen, filtrelenen ve toplanan verilerin sırasını belirleyen bu işleçlerin sırası.
İşleçlerden geçen tahmini satır sayısı.
Uyarı
Veritabanı Altyapısı'nın daha yeni sürümlerinde, Kardinalite Tahmini için kullanılan istatistik nesneleri hakkındaki bilgiler de depolanır.
Hangi destek nesnelerinin oluşturulması gerekir, örneğin çalışma tabloları veya iş dosyaları içinde? Sorgu planında hiçbir kullanıcı bağlamı veya çalışma zamanı bilgisi depolanmaz. Bellekte sorgu planının bir veya ikiden fazla kopyası yoktur: tüm seri yürütmeler için bir kopya ve tüm paralel yürütmeler için başka bir kopya. Paralel kopya, paralellik derecelerinden bağımsız olarak tüm paralel yürütmeleri kapsar.
Yürütme Bağlamı
Sorguyu yürütmekte olan her kullanıcının, parametre değerleri gibi yürütmelerine özgü verileri tutan bir veri yapısı vardır. Bu veri yapısı yürütme bağlamı olarak adlandırılır. Yürütme bağlamı veri yapıları yeniden kullanılır, ancak içeriği yeniden kullanılmaz. Başka bir kullanıcı aynı sorguyu yürütürse, veri yapıları yeni kullanıcının bağlamıyla yeniden başlatılır.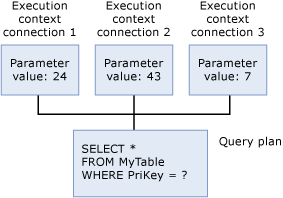
SQL Server'da herhangi bir Transact-SQL deyimi yürütürken, Veritabanı Altyapısı aynı Transact-SQL deyimi için mevcut bir yürütme planının mevcut olduğunu doğrulamak için önce plan önbelleğini arar. Transact-SQL deyimi, daha önce yürütülen bir Transact-SQL deyimini önbelleğe alınmış bir planla(karakter başına karakter) eşlerse, var olan bir deyim olarak niteler. SQL Server bulduğu mevcut tüm planları yeniden kullanır ve Transact-SQL deyimini yeniden derleme ek yükünü azaltır. Yürütme planı yoksa, SQL Server sorgu için yeni bir yürütme planı oluşturur.
Uyarı
Satır deposunda çalışan toplu işlem deyimleri veya boyutu 8 KB'den büyük dize değişmez değerleri içeren deyimler gibi bazı Transact-SQL deyimleri için yürütme planları plan önbelleğinde kalıcı değildir. Bu planlar yalnızca sorgu yürütülürken mevcut olur.
SQL Server, belirli bir Transact-SQL deyimi için mevcut yürütme planlarını bulmak için verimli bir algoritmaya sahiptir. Çoğu sistemde, bu tarama tarafından kullanılan asgari kaynaklar, her Transact-SQL deyimini derlemek yerine mevcut planları yeniden kullanarak tasarruf edilen kaynaklardan daha azdır.
Yeni Transact-SQL deyimlerini plan önbelleğindeki mevcut, kullanılmayan yürütme planlarıyla eşleştirme algoritmaları, tüm nesne başvurularının tam olarak nitelenmiş olmasını gerektirir. Örneğin, aşağıdaki Person deyimleri yürüten kullanıcı için varsayılan şema olduğunu SELECT varsayalım. Bu örnekte Person tablonun yürütülmesi için tam olarak nitelenmiş olması gerekmez; bu, ikinci ifadenin mevcut bir planla eşleşmediği, ancak üçüncü ifadenin eşleştiği anlamına gelir:
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
Veritabanı Altyapısı sürekli katlama gerçekleştirdiğinden ve bu seçenekler bu tür ifadelerin sonuçlarını etkilediğinden, belirli bir yürütme için aşağıdaki SET seçeneklerinden herhangi birinin değiştirilmesi planları yeniden kullanma özelliğini etkiler:
ANSI_NULL_DFLT_OFF (ANSI'de NULL varsayılan değer kapalı)
GÜÇPLANI
ARITHABORT
DATEFIRST
ANSI_PADDING
SAYISAL_YUVARLAMADURDUR
ANSI_NULL_DFLT_ON
DİL
CONCAT_NULL_YIELDS_NULL (Boş değerler birleştirildiğinde boş değer döner)
Tarih Formatı
ANSI_WARNINGS (ANSI Uyarıları)
TIRNAKLI_BELİRLEYİCİ
ANSI_NULLS (ANSI NULL Değerleri Ayarları)
NO_BROWSETABLE
ANSI varsayılanları
Aynı sorgu için birden çok planı önbelleğe alma
Sorgular ve yürütme planları, Veritabanı Altyapısı'nda parmak izi gibi benzersiz bir şekilde tanımlanabilir:
- Sorgu planı karması, belirli bir sorgu için yürütme planında hesaplanan ikili karma değerdir ve benzer yürütme planlarını benzersiz olarak tanımlamak için kullanılır.
- Sorgu karması, sorgunun Transact-SQL metninde hesaplanan ikili karma değerdir ve sorguları benzersiz olarak tanımlamak için kullanılır.
Derlenmiş bir plan, plan önbellekte kalırken yalnızca sabit kalan geçici bir tanımlayıcı olan Plan Tanıtıcısı kullanılarak plan önbelleğinden alınabilir. Plan tanıtıcısı, toplu işin tamamının derlenmiş planından türetilen bir karma değerdir. Toplu iş içindeki bir veya daha fazla deyim yeniden derlense bile, derlenmiş bir planın plan tanıtıcısı aynı kalır.
Uyarı
Bir plan tek bir deyim yerine bir veri kümesi için derlenmişse, veri kümesi içindeki tek tek deyimler için plan tanıtıcısı ve deyim göstergeleri kullanılarak alınabilir.
sys.dm_exec_requests DMV, her kayıt için statement_start_offset ve statement_end_offset sütunlarını içerir, bunlar şu anda yürütülen toplu iş veya kalıcı nesnenin şu anda yürütülmekte olan deyimine başvurur. Daha fazla bilgi için bkz . sys.dm_exec_requests (Transact-SQL).
sys.dm_exec_query_stats DMV, her kayıt için bir toplu iş veya kalıcı nesne içindeki bir açıklamanın konumuna başvuran bu sütunları da içerir. Daha fazla bilgi için bkz. sys.dm_exec_query_stats (Transact-SQL).
Bir toplu işlemin gerçek Transact-SQL metni, plan önbelleğinden SQL Manager önbelleği (SQLMGR) olarak adlandırılan ayrı bir bellek alanında depolanır. Derlenmiş bir planın Transact-SQL metni, SQL Yöneticisi önbelleğinden, geçici bir tanımlayıcı olan SQL Tanıtıcısı kullanılarak alınabilir; bu tanıtıcı, yalnızca ona referans veren en az bir plan plan önbelleğinde kaldığı sürece sabit kalır. SQL tanıtıcısı, toplu iş metninin tamamından türetilen bir karma değerdir ve her toplu işlem için benzersiz olacağı garanti edilir.
Uyarı
Derlenmiş bir plan gibi, Transact-SQL metni açıklamalar da dahil olmak üzere her toplu iş için saklanır. SQL tanıtıcısı, toplu iş metninin tamamının MD5 karması içerir ve her toplu işlem için benzersiz olacağı garanti edilir.
Aşağıdaki sorgu sql manager önbelleği için bellek kullanımı hakkında bilgi sağlar:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
SQL tanıtıcısı ile plan tanıtıcıları arasında 1:N ilişkisi vardır. Derlenen planların önbellek anahtarı farklı olduğunda böyle bir koşul oluşur. Bunun nedeni, aynı toplu iş için yapılan iki yürütme arasındaki SET seçeneklerindeki değişiklik olabilir.
Aşağıdaki saklı yordamı göz önünde bulundurun:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Aşağıdaki sorguyu kullanarak plan önbelleğinde neler bulunabileceğini doğrulayın:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Sonuç kümesi aşağıdadır.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Şimdi saklı yordamı farklı bir parametreyle yürütebilirsiniz, ancak yürütme bağlamında başka bir değişiklik yapılmaz:
EXEC usp_SalesByCustomer 8
GO
Plan önbelleğinde neler bulunabileceğini yeniden doğrulayın. Sonuç kümesi aşağıdadır.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
öğesinin usecounts 2'ye yükseltildiğine dikkat edin. Bu, yürütme bağlamı veri yapılarının yeniden kullanılması nedeniyle aynı önbelleğe alınmış planın as-isyeniden kullanılması anlamına gelir. Şimdi SET ANSI_DEFAULTS seçeneğini değiştirin ve aynı parametreyi kullanarak saklı yordamı yürütün.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Plan önbelleğinde neler bulunabileceğini yeniden doğrulayın. Sonuç kümesi aşağıdadır.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
DMV çıktısında artık iki kayıt olduğuna dikkat edin.
-
usecountssütunu,1ile bir kez yürütülen planın ilk kayıttakiSET ANSI_DEFAULTS OFFdeğerini gösterir. - İkinci kayıttaki
usecountsdeğerini gösteren2sütunu, iki kez yürütüldüğü içinSET ANSI_DEFAULTS ONile yürütülen planı temsil eder. - Farklı
memory_object_address, plan önbelleğindeki farklı bir yürütme planı girdisine başvurur. Ancak, her iki girdi için desql_handledeğeri aynıdır çünkü aynı partiye atıfta bulunuyorlar.- OFF olarak ayarlanmış işlem
ANSI_DEFAULTSyeni birplan_handleöğesine sahiptir ve aynı SET seçeneklerine sahip çağrılar için yeniden kullanılabilir. Değişen SET seçenekleri nedeniyle uygulama bağlamı yeniden başlatıldığı için yeni plan çağrıcısı gereklidir. Ancak bu bir yeniden derlemeyi tetiklemez: her iki girdi de aynı plan ve sorguya başvurur ve aynıquery_plan_hashvequery_hashdeğerler tarafından kanıtlanmıştır.
- OFF olarak ayarlanmış işlem
Bu, aynı toplu işleme karşılık gelen iki plan girdisinin önbellekte olması anlamına gelir ve aynı sorgular tekrar tekrar yürütüldüğünde plan önbelleğinde etkili olan SET seçeneklerinin aynı olmasını sağlamanın önemini vurgular, plan tekrar kullanımını optimize eder ve plan önbelleği boyutunu gerekli minimumda tutar.
Tavsiye
Yaygın bir tuzak, farklı istemcilerin SET seçenekleri için farklı varsayılan değerlere sahip olmasıdır. Örneğin, SQL Server Management Studio aracılığıyla yapılan bir bağlantı QUOTED_IDENTIFIER'yı otomatik olarak AÇIK olarak ayarlar, SQLCMD ise QUOTED_IDENTIFIER'yi KAPALI olarak ayarlar. Bu iki istemciden aynı sorguların yürütülmesi birden çok planla sonuçlanır (yukarıdaki örnekte açıklandığı gibi).
Plan önbelleğinden yürütme planlarını kaldırma
Yürütme planları, depolamak için yeterli bellek olduğu sürece plan önbelleğinde kalır. Bellek baskısı olduğunda SQL Server Veritabanı Altyapısı, plan önbelleğinden hangi yürütme planlarının kaldırılacağını belirlemek için maliyet tabanlı bir yaklaşım kullanır. Maliyet tabanlı bir karar vermek için, SQL Server Veritabanı Altyapısı aşağıdaki faktörlere göre her yürütme planı için geçerli bir maliyet değişkenini artırır ve azaltır.
Kullanıcı işlemi önbelleğe bir yürütme planı eklediğinde, kullanıcı işlemi geçerli maliyeti özgün sorgu derleme maliyetine eşit olarak ayarlar; geçici yürütme planları için kullanıcı işlemi geçerli maliyeti sıfır olarak ayarlar. Bundan sonra, bir kullanıcı işlemi bir yürütme planına her başvurduğunda, geçerli maliyeti özgün derleme maliyetine geri sıfırlar; rastgele yürütme planları için, kullanıcı işlemi geçerli maliyeti artırır. Tüm planlar için geçerli maliyet için en yüksek değer özgün derleme maliyetidir.
Bellek baskısı olduğunda SQL Server Veritabanı Altyapısı, yürütme planlarını plan önbelleğinden kaldırarak yanıt verir. Hangi planların kaldırılacağını belirlemek için, SQL Server Veritabanı Altyapısı her yürütme planının durumunu tekrar tekrar inceler ve geçerli maliyetleri sıfır olduğunda planları kaldırır. Bellek baskısı mevcut olduğunda, geçerli maliyeti sıfır olan bir yürütme planı otomatik olarak kaldırılmaz; yalnızca SQL Server Veritabanı Altyapısı planı incelediğinde ve geçerli maliyet sıfır olduğunda kaldırılır. SQL Server Veritabanı Motoru, bir yürütme planını incelerken, bir sorgu şu anda planı kullanmıyorsa geçerli maliyeti azaltarak maliyeti sıfıra doğru düşürür.
SQL Server Veritabanı Altyapısı, bellek gereksinimlerini karşılamak için gereken miktarda kaldırılana kadar yürütme planlarını sürekli olarak inceler. Bellek baskısı mevcut olsa da yürütme planının maliyeti birden çok kez artırılıp azaltılmış olabilir. Bellek baskısı artık olmadığında, SQL Server Veritabanı Altyapısı kullanılmayan yürütme planlarının geçerli maliyetini azaltmayı durdurur ve maliyeti sıfır olsa bile tüm yürütme planları plan önbelleğinde kalır.
SQL Server Veritabanı Altyapısı, bellek baskısına yanıt olarak, plan önbelleğinden bellek boşaltmak amacıyla kullanıcı iş parçacıkları ve kaynak izleme mekanizmasını kullanır. Kaynak izleyicisi ve kullanıcı işçi parçacıkları, kullanılmayan her yürütme planının mevcut maliyetini azaltmak için eşzamanlı yürütülen planları inceleyebilir. Kaynak izleyicisi, genel bellek baskısı mevcut olduğunda plan önbelleğinden yürütme planlarını kaldırır. Sistem belleği, işlem belleği, kaynak havuzu belleği ve tüm önbellekler için maksimum boyut dahil belleği serbest bırakarak ilkeleri uygular.
Tüm önbelleklerin maksimum boyutu, arabellek havuzu boyutunun bir işlevidir ve sunucu belleğinin maksimumunu aşamaz. Azami sunucu belleğini yapılandırma hakkında daha fazla bilgi için max server memory içindeki sp_configure ayarına bakın.
Tek önbellek bellek baskısı olduğunda, kullanıcı çalışan iş parçacıkları yürütme planlarını plan önbelleğinden kaldırır. Maksimum tekil önbellek boyutu ve maksimum tekil önbellek girdisi için politikaları zorunlu kılarlar.
Aşağıdaki örneklerde, hangi yürütme planlarının plan önbelleğinden kaldırıldığı gösterilmektedir:
- Yürütme planına sık sık başvurulur, böylece maliyeti hiçbir zaman sıfıra gitmez. Plan plan önbelleğinde kalır ve bellek baskısı olmadığı ve geçerli maliyet sıfır olmadığı sürece kaldırılmaz.
- Bellek baskısı oluşmadan önce geçici yürütme planı eklenir ve yeniden başvurulmaz. Geçici planlar geçerli maliyeti sıfır olan bir şekilde başlatıldığından, SQL Server Veritabanı Altyapısı yürütme planını incelediğinde sıfır geçerli maliyeti görür ve planı plan önbelleğinden kaldırır. Geçici yürütme planı, bellek baskısı olmadığında plan önbelleğinde sıfır geçerli maliyetle kalır.
Tek bir planı veya tüm planları önbellekten el ile kaldırmak için DBCC FREEPROCCACHE kullanın.
DBCC FREESYSTEMCACHE , plan önbelleği de dahil olmak üzere tüm önbellekleri temizlemek için de kullanılabilir. SQL Server 2016 (13.x) ile başlayarak, kapsamındaki veritabanı için prosedür (plan) önbelleğini temizlemek üzere ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE komutunu kullanın.
sp_configure ve yeniden yapılandırma yoluyla bazı yapılandırma ayarlarında yapılan bir değişiklik, planların plan önbelleğinden kaldırılmasına da neden olur. Bu yapılandırma ayarlarının listesini DBCC FREEPROCCACHE makalesinin Açıklamalar bölümünde bulabilirsiniz. Bunun gibi bir yapılandırma değişikliği, hata günlüğüne aşağıdaki bilgi iletisini kaydeder:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Yürütme planlarını yeniden derleme
Veritabanındaki bazı değişiklikler, veritabanının yeni durumuna bağlı olarak yürütme planının verimsiz veya geçersiz olmasına neden olabilir. SQL Server, yürütme planını geçersiz kılıp planı geçerli değil olarak işaretleyen değişiklikleri algılar. Ardından sorguyu yürüten sonraki bağlantı için yeni bir plan yeniden derlenmelidir. Planı geçersiz kılma koşulları şunlardır:
- Sorgu (
ALTER TABLEveALTER VIEW) tarafından başvuruda bulunulan bir tabloda veya görünümde yapılan değişiklikler. - Tek bir yordamda yapılan değişiklikler, bu yordam için tüm planları önbellekten (
ALTER PROCEDURE) düşürür. - Yürütme planı tarafından kullanılan dizinlerde yapılan değişiklikler.
- Yürütme planı tarafından kullanılan ve bir deyimden açıkça oluşturulan, örneğin
UPDATE STATISTICS, veya otomatik olarak oluşturulan istatistiklerle ilgili güncellemeler. - Yürütme planında kullanılan bir dizini kaldırmak.
-
sp_recompileiçin açık bir çağrı. - Anahtarlardaki çok sayıda değişiklik (diğer kullanıcıların sorgunun başvurduğu bir tabloyu değiştiren
INSERTveyaDELETEdeyimleri tarafından oluşturulan). - Tetikleyicileri olan tablolarda, eklenen veya silinen tablolardaki satır sayısı önemli ölçüde artarsa.
- seçeneğini kullanarak saklı yordam yürütme
WITH RECOMPILE.
Çoğu yeniden derleme, deyim doğruluğu veya daha hızlı sorgu yürütme planları elde etmek için gereklidir.
2005'den önceki SQL Server sürümlerinde, bir toplu iş içindeki bir deyim yeniden derlemeye neden olduğunda, saklı yordam, tetikleyici, geçici toplu iş veya hazırlanmış deyim aracılığıyla gönderilen toplu işlemin tamamı yeniden derlenmiştir. SQL Server 2005 (9.x) sürümünden itibaren, yalnızca yeniden derlemeyi tetikleyen toplu işlemin içindeki ifade yeniden derlenir. Ayrıca, genişletilmiş özellik kümesi nedeniyle SQL Server 2005 (9.x) ve sonraki sürümlerinde ek türlerde yeniden derlemeler vardır.
Deyim düzeyinde yeniden derleme, çoğu durumda az sayıda ifadenin CPU süresi ve kilitler açısından yeniden derlemelere ve bunların ilişkili cezalarına neden olması nedeniyle performansı artırır. Bu nedenle yeniden derlenmesi gerekmeyen toplu işlemdeki diğer ifadeler için bu cezalardan kaçınılır.
Genişletilmiş olay (XEvent) ifade düzeyinde yeniden derlemeleri raporlar. Bu XEvent, herhangi bir yığın türü için ifade düzeyinde yeniden derleme gerektiğinde meydana gelir. Buna saklı yordamlar, tetikleyiciler, geçici toplu işlemler ve sorgular dahildir. Batch'ler , dinamik SQL, Hazırlama yöntemleri veya Execute yöntemleri gibi sp_executesqlçeşitli arabirimler aracılığıyla gönderilebilir.
recompile_cause XEvent sütunusql_statement_recompile, yeniden derlemenin nedenini gösteren bir tamsayı kodu içerir. Aşağıdaki tabloda olası nedenler yer alır:
Şema değiştirildi
İstatistikler değiştirildi
Ertelenmiş derleme
SET seçeneği değiştirildi
Geçici tablo değiştirildi
Uzak satır kümesi değiştirildi
FOR BROWSE izin değiştirildi
Sorgu bildirim ortamı değiştirildi
Bölümlenmiş görünüm değiştirildi
İmleç seçenekleri değiştirildi
OPTION (RECOMPILE) İstenen
Parametreli plan temizlendi
Veritabanı sürümünü etkileyen plan değiştirildi
Sorgu Deposu planı zorlama ilkesi değiştirildi
Query Store planı uygulanamadı
Sorgu Deposu planı eksik
Uyarı
XEvent'lerin kullanılamadığı SQL Server sürümlerinde SQL Server Profiler SP:Recompile izleme olayı, deyim düzeyinde yeniden derlemeleri raporlamanın aynı amacı için kullanılabilir.
İzleme olayı SQL:StmtRecompile ayrıca deyim düzeyinde yeniden derlemeleri raporlar ve bu izleme olayı, yeniden derlemeleri izlemek ve hatalarını ayıklamak için de kullanılabilir.
SP:Recompile yalnızca saklı yordamlar ve tetikleyiciler için oluştururken, SQL:StmtRecompile saklı yordamlar, tetikleyiciler, anlık (ad hoc) toplu işler, sp_executesql kullanılarak yürütülen toplu işlemler, hazırlanmış sorgular ve dinamik SQL için oluşturulur.
ve öğesinin SP:RecompileSQL:StmtRecompile sütunu, yeniden derlemenin nedenini gösteren bir tamsayı kodu içerir. Kodlar SQL:StmtRecompile Olay Sınıfı'nda açıklanmıştır.
Uyarı
AUTO_UPDATE_STATISTICS Veritabanı seçeneği olarak ONayarlandığında, istatistikleri güncelleştirilmiş veya kardinaliteleri son yürütmeden bu yana önemli ölçüde değişmiş olan tabloları veya dizine alınmış görünümleri hedef alan sorgular yeniden derlenir.
Bu davranış standart kullanıcı tanımlı tablolar, geçici tablolar ve DML tetikleyicileri tarafından oluşturulan eklenen ve silinen tablolar için geçerlidir. Sorgu performansı aşırı yeniden derlemelerden etkileniyorsa, bu ayarı olarak OFFdeğiştirmeyi göz önünde bulundurun.
AUTO_UPDATE_STATISTICS Veritabanı seçeneği olarak OFFayarlandığında, DML INSTEAD OF tetikleyicileri tarafından oluşturulan eklenen ve silinen tablolar dışında istatistiklere veya kardinalite değişikliklerine göre yeniden derleme gerçekleşmez. Bu tablolar tempdb içinde oluşturulduğundan, bunlara erişen sorguların yeniden derlenmesi AUTO_UPDATE_STATISTICS içindeki tempdb ayarına bağlıdır.
2005'in öncesinde SQL Server'da sorgular, bu ayar OFFolduğunda bile eklenen ve silinen DML tetikleyicisindeki kardinalite değişikliklerine göre yeniden derlemeye devam eder.
Parametrelerin ve yürütme planlarının yeniden kullanımı
ADO, OLE DB ve ODBC uygulamalarında parametre işaretçileri de dahil olmak üzere parametrelerin kullanılması, yürütme planlarının yeniden kullanımını artırabilir.
Uyarı
Son kullanıcılar tarafından girilen değerleri tutmak için parametreleri veya parametre işaretçilerini kullanmak, bu değerleri bir veri erişim API'si yöntemi, EXECUTE deyimi veya sp_executesql saklı yordam kullanılarak yürütülen bir dizeye birleştirmekten daha güvenlidir.
Aşağıdaki iki SELECT ifade arasındaki tek fark, WHERE alt cümlede karşılaştırılan değerlerdir.
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Bu sorgular için yürütme planları arasındaki tek fark, sütunla karşılaştırma ProductSubcategoryID için depolanan değerdir. Hedef, SQL Server'ın deyimlerinin temelde aynı planı oluşturduğunu ve planları yeniden kullandığını her zaman tanıması olsa da, SQL Server bazen karmaşık Transact-SQL deyimlerinde bunu algılamaz.
Parametreleri kullanarak sabitleri Transact-SQL deyiminden ayırmak, ilişkisel altyapının yinelenen planları tanımasını sağlar. Parametreleri aşağıdaki yollarla kullanabilirsiniz:
Transact-SQL içinde kullanın
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmBu yöntem, SQL deyimlerini dinamik olarak oluşturan Transact-SQL betikler, saklı yordamlar veya tetikleyiciler için önerilir.
ADO, OLE DB ve ODBC parametre işaretçilerini kullanır. Parametre işaretçileri, SQL deyimindeki bir sabitin yerini alan ve bir program değişkenine bağlı olan soru işaretleridir (?). Örneğin, bir ODBC uygulamasında aşağıdakileri yapabilirsiniz:
Sql deyimindeki ilk parametre işaretçisine bir tamsayı değişkeni bağlamak için kullanın
SQLBindParameter.Tamsayı değerini değişkenine yerleştirin.
Parametre işaretçisini (?) belirterek ifadeyi çalıştırın.
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
SQL Server'da bulunan SQL Server Yerel İstemci OLE DB Sağlayıcısı ve SQL Server Yerel İstemci ODBC sürücüsü, uygulamalarda parametre işaretçileri kullanıldığında SQL Server'a deyim göndermek için
sp_executesqlkullanır.Parametreleri tasarıma göre kullanan saklı yordamlar tasarlamak için.
Uygulamalarınızın tasarımında açıkça parametre oluşturmazsanız, basit parametreleştirmenin varsayılan davranışını kullanarak belirli sorguları otomatik olarak parametreleştirmek için SQL Server Sorgu İyileştiricisi'ne de güvenebilirsiniz. Alternatif olarak, PARAMETERIZATION seçeneğini ALTER DATABASE deyiminde FORCED olarak ayarlayarak Sorgu İyileştiricisi'ni, veritabanındaki tüm sorguları parametreleştirmeyi göz önünde bulundurması için zorlayabilirsiniz.
Zorlamalı parametreleştirme etkinleştirildiğinde, basit parametreleştirme yine de oluşabilir. Örneğin, aşağıdaki sorgu zorlamalı parametreleştirme kurallarına göre parametrelenemez:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
Ancak, basit parametreleştirme kurallarına göre parametrelendirilebilir. Zorlamalı parametreleştirme denendiğinde ancak başarısız olduğunda, basit parametreleştirme yine de denenmeye devam edilir.
Basit parametreleştirme
SQL Server'da, Transact-SQL deyimlerinde parametrelerin veya parametre işaretçilerinin kullanılması, ilişkisel altyapının yeni Transact-SQL deyimlerini mevcut, daha önce derlenmiş yürütme planlarıyla eşleştirme becerisini artırır.
Uyarı
Son kullanıcılar tarafından yazılan değerleri tutmak için parametreleri veya parametre işaretçilerini kullanmak, değerleri bir veri erişim API'si yöntemi, EXECUTE deyimi veya sp_executesql saklı yordam kullanılarak yürütülen bir dizede birleştirmekten daha güvenlidir.
bir Transact-SQL deyimi parametresiz yürütülürse, SQL Server deyimini mevcut bir yürütme planıyla eşleştirme olasılığını artırmak için dahili olarak parametreleştirir. Bu işleme basit parametreleştirme adı verilir. 2005'in önceki SQL Server sürümlerinde işleme otomatik parametreleştirme adı verildi.
Şu deyimi göz önünde bulundurun:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
Deyimin sonundaki 1 değeri parametre olarak belirtilebilir. İlişkisel motor, bu toplu iş için, 1 değerinin yerine bir parametre belirtilmiş gibi yürütme planını oluşturur. Bu basit parametreleme nedeniyle SQL Server, aşağıdaki iki deyimin temelde aynı yürütme planını oluşturduğunu algılar ve ikinci deyim için ilk planı yeniden kullanır:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Karmaşık Transact-SQL deyimlerini işlerken, ilişkisel altyapı hangi ifadelerin parametrelendirilebileceğini belirlemekte zorlanabilir. İlişkisel motorun karmaşık Transact-SQL ifadelerini mevcut, kullanılmayan yürütme planlarıyla eşleştirme yeteneğini artırmak için, parametreleri açıkça belirtin; bunu yapmak için ya sp_executesql ya da parametre işaretçilerini kullanın.
Uyarı
+, -, *, / veya % aritmetik işleçleri, int, smallint, tinyint veya bigint sabit değerlerini float, real, decimal veya numeric veri türlerine örtük veya açık şekilde dönüştürmek için kullanıldığında, SQL Server ifade sonuçlarının türünü ve duyarlılığını hesaplamak için belirli kurallar uygular. Ancak bu kurallar, sorgunun parametreli olup olmamasına bağlı olarak farklılık gösterir. Bu nedenle, sorgulardaki benzer ifadeler bazı durumlarda farklı sonuçlar üretebilir.
Basit parametreleştirmenin varsayılan davranışı altında, SQL Server görece küçük bir sorgu sınıfını parametreleştirir. Ancak, belirli sınırlamalara tabi olarak veritabanındaki tüm sorguların parametrelendirilmiş olacağını, PARAMETERIZATION komutunun ALTER DATABASE seçeneğini FORCED olarak ayarlayarak belirtebilirsiniz. Bunun yapılması, sorgu derlemelerinin sıklığını azaltarak yüksek hacimli eşzamanlı sorgularla karşılaşan veritabanlarının performansını artırabilir.
Alternatif olarak, tek bir sorgu ve söz dizimsel olarak eşdeğer olan ancak yalnızca parametre değerlerinde farklılık gösteren diğer tüm sorguların parametreleştirilmesini belirtebilirsiniz.
Tavsiye
Entity Framework (EF) gibi bir Object-Relational Eşleme (ORM) çözümü kullanılırken, el ile LINQ sorgu ağaçları gibi uygulama sorguları veya belirli ham SQL sorguları parametrelendirilmeyebilir; bu da plan yeniden kullanımını ve Sorgu Deposu'ndaki sorguları izleme özelliğini etkiler. Daha fazla bilgi için bkz. EF Sorgu önbelleğe alma ve parametreleştirme ve EF Raw SQL Sorguları .
Zorlamalı parametreleştirme
Veritabanındaki tüm SELECT, , INSERTUPDATEve DELETE deyimlerinin belirli sınırlamalara tabi olacağını belirterek SQL Server'ın varsayılan basit parametreleştirme davranışını geçersiz kılabilirsiniz. Zorlamalı parametreleştirme, PARAMETERIZATION deyiminde FORCED seçeneğinin ALTER DATABASE olarak ayarlanmasıyla etkinleştirilir. Zorlamalı parametreleme, sorgu derlemelerinin ve yeniden derlemelerin sıklığını azaltarak belirli veritabanlarının performansını artırabilir. Zorlamalı parametreleştirmeden yararlanabilecek veritabanları genellikle satış noktası uygulamaları gibi kaynaklardan gelen yüksek hacimli eşzamanlı sorgularla karşılaşan veritabanlarıdır.
PARAMETERIZATION seçeneği FORCED olarak ayarlandığında, herhangi bir SELECT biçiminde gönderilen, INSERT, UPDATE veya DELETE deyiminde görünen tüm sabit değerler sorgu derlemesi sırasında bir parametreye dönüştürülür. Özel durumlar, aşağıdaki sorgu yapılarında görünen sabit değerlerdir.
-
INSERT...EXECUTEİfadeler. - Saklı yordamların, tetikleyicilerin veya kullanıcı tanımlı işlevlerin gövdelerindeki ifadeler. SQL Server bu yordamlar için sorgu planlarını zaten yeniden kullanır.
- İstemci tarafı uygulamasında halihazırda parametreleştirilmiş olan hazırlığı yapılmış ifadeler.
- XQuery yöntemi çağrıları içeren deyimler, burada yöntemin bağımsız değişkenlerinin genellikle parametreleştirileceği bir bağlamda (yan tümce gibi)
WHEREgörünür. Yöntem, bağımsız değişkenlerinin parametreleştirilmeyeceği bir bağlamda görünüyorsa, ifadenin geri kalanı parametreleştirilir. - Transact-SQL imleç içindeki ifadeler. (
SELECTAPI kursorler içindeki ifadeler parametreleştirilir.) - Kullanım dışı bırakılan sorgu yapıları.
- Herhangi bir deyim, bağlamında
ANSI_PADDINGçalıştırıldığında veyaANSI_NULLSOFFolarak ayarlandığında. - Parametreleştirmeye uygun 2.097'den fazla değişmez değer içeren ifadeler.
- gibi
WHERE T.col2 >= @bbdeğişkenlere başvuran deyimler. - Sorgu ipucunu
RECOMPILEiçeren deyimler. -
COMPUTEhükmü içeren ifadeler. -
WHERE CURRENT OFhükmü içeren ifadeler.
Ayrıca aşağıdaki sorgu yan tümceleri parametrelendirilmemektedir. Bu gibi durumlarda yalnızca yan tümceler parametrelendirilmemektedir. Aynı sorgudaki diğer yan tümceler zorunlu parametreleştirme için uygun olabilir.
- Herhangi bir < deyimin >select_list
SELECT. Bu,SELECTalt sorgu listelerini veSELECTdeyimlerin içindekiINSERTlisteleri içerir. - Bir
SELECTdeyiminin içinde görünen alt sorguIFdeyimleri. - Sorgunun
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTOveyaFOR XMLyan tümceleri. - Bağımsız değişkenler (doğrudan veya alt ifadeler olarak),
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXMLveya herhangi birFULLTEXTişleci için. -
LIKEyan tümcesinin pattern ve escape_character bağımsız değişkenleri. - Bir
CONVERTbölümü için stil argümanı. -
IDENTITYşarta içinde tamsayı sabitleri. - ODBC uzantısı söz dizimi kullanılarak belirtilen sabitler.
-
+,-,*,/ve%işleçlerinin bağımsız değişkenleri olan sabit katlanabilir ifadeler. Zorlamalı parametreleştirme için uygunluk göz önünde bulundurulduğunda, SQL Server aşağıdaki koşullardan biri doğru olduğunda bir ifadenin sabit katlanabilir olduğunu düşünür:- İfadede sütun, değişken veya alt sorgu görüntülenmez.
- İfade bir
CASEyan tümcesi içerir.
- sorgu ipucu ifadelerine yönelik argümanlar. Bunlar, sorgu ipucunun
FASTbağımsız değişkenini, sorgu ipucununMAXDOPbağımsız değişkenini ve sorgu ipucunun sayı bağımsız değişkeniniMAXRECURSIONiçerir.
Parametreleştirme tek tek Transact-SQL deyimleri düzeyinde gerçekleşir. Yani, bir toplu iş içindeki tek tek cümleler parametreleştirilir. Derledikten sonra, parametreli bir sorgu ilk gönderildiği toplu iş bağlamında yürütülür. Sorgu için bir yürütme planı önbelleğe alınmışsa, dinamik yönetim görünümünün sql sütununa başvurarak sorgunun sys.syscacheobjects parametrelendirilip parametrelendirilmediğini belirleyebilirsiniz. Bir sorgu parametreleştirilmişse, parametrelerin adları ve veri türleri bu sütunda gönderilen toplu işlemin metninden önce (@1 tinyint) gibi gelir.
Uyarı
Parametre adları rastgeledir. Kullanıcılar veya uygulamalar belirli bir adlandırma sırasına güvenmemelidir. Ayrıca, aşağıdakiler SQL Server sürümleri ile toplu güncelleştirme (CU) yükseltmeleri arasında değişebilir: Parametre adları, parametreleştirilmiş değişmez değerlerin seçimi ve parametreleştirilmiş metindeki aralıklar.
Parametre veri türleri
SQL Server sabit değerleri parametreleştirdiğinde, parametreler aşağıdaki veri türlerine dönüştürülür.
- Boyutu aksi takdirde int veri türüne sığacak olan tamsayı sabitleri int olarak parametreleştirilir. Herhangi bir karşılaştırma operatörünü (
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEEN, veINdahil) içeren ilişki ifadelerinin parçaları olan daha büyük tamsayı sabitleri numeric(38,0) olarak parametreleştirilir. Karşılaştırma işleçleri içeren koşulun parçası olmayan daha büyük sabit değerler, boyutlarını destekleyecek kadar büyük bir duyarlılığa sahip ve ölçeği 0 olan sayısal değerlere dönüştürülür. - Karşılaştırma işleçleri içeren koşullarda yer alan sabit noktalı sayısal sabit değerler, duyarlılığı 38 olan ve ölçekte boyutunu destekleyecek kadar büyük olan sayısal değerlerle parametreleştirilir. Karşılaştırma işleçlerini içeren önermelerden bağımsız olan sabit noktalı sayısal değişmezler, boyutunu desteklemek için yeterli hassaslığa ve ölçeğe sahip sayısal bir veri tipine parametreleştirilir.
- Kayan nokta sayısal değişmezleri float(53) veri tipi ile parametreleştirilir.
- Unicode olmayan dize değişmez değerleri, değişmez değer 8.000 karaktere sığıyorsa varchar(8000) ve 8.000 karakterden büyükse varchar(max) olarak parametreleştirir.
- Unicode dize sabit değerleri, eğer sabit değer 4.000 Unicode karaktere sığıyorsa nvarchar(4000) ve eğer sabit değer 4.000 karakterden büyükse nvarchar(max) olarak ayarlanır.
- İkili değişmez ifadeler 8.000 bayta sığıyorsa, varbinary(8000) olarak parametrelenir. 8.000 bayttan büyükse, varbinary(max) değerine dönüştürülür.
- Para türü değişmez değerleri paraya parametreli hale getirmektir.
Zorlamalı parametreleştirme kullanma yönergeleri
FORCED seçeneğini ayarlarken PARAMETERIZATION aşağıdakileri göz önünde bulundurun:
- Zorlamalı parametreleştirme, sorguyu derlerken sorgudaki değişmez değer sabitlerini parametrelere dönüştürür. Bu nedenle, Sorgu İyileştiricisi sorgular için en iyi olmayan planları seçebilir. Özellikle Sorgu İyileştiricisi'nin sorguyu dizine alınmış bir görünümle veya hesaplanan sütundaki bir dizinle eşleştirme olasılığı daha düşüktür. Bölümlenmiş tablolarda ve dağıtılmış bölümlenmiş görünümlerde bulunan sorgular için en iyi olmayan planları da seçebilir. Kapsamlı olarak dizinlenmiş görünümler ve hesaplanan sütunlardaki dizinler üzerine kurulu ortamlarda zorunlu parametrelemenin kullanılması önerilmez. Genel olarak, bu seçeneğin
PARAMETERIZATION FORCEDyalnızca deneyimli veritabanı uzmanları tarafından, bunu yapmanın performansı olumsuz etkilemediğini belirledikten sonra kullanılması gerekir. - Birden fazla veritabanına başvuran dağıtılmış sorgular,
PARAMETERIZATIONseçeneği, sorgunun çalıştığı veritabanının bağlamındaFORCEDolarak ayarlandığı sürece zorlamalı parametreleştirme için uygundur. - seçeneğinin
PARAMETERIZATIONFORCEDayarlanması, şu anda derleme, yeniden derleme veya çalıştırma işlemleri yapanlar dışında veritabanının plan önbelleğinden tüm sorgu planlarını temizler. Ayar değişikliği sırasında derlenen veya çalışan sorgu planları, sorgunun bir sonraki yürütülmesinde parametrelendirilir. - Seçeneğin
PARAMETERIZATIONayarlanması, veritabanı düzeyinde özel kullanım kilidi gerektirmeyen çevrimiçi bir işlemdir. - Veritabanını yeniden eklerken veya geri yüklerken seçeneğin geçerli ayarı
PARAMETERIZATIONkorunur.
Tek bir sorguda basit parametreleştirmenin deneneceğini ve söz dizimsel olarak eşdeğer olan ancak yalnızca parametre değerlerinde farklılık gösteren diğer tüm diğer parametreleri belirterek zorlamalı parametreleştirme davranışını geçersiz kılabilirsiniz. Buna karşılık, veritabanında zorlamalı parametreleştirme devre dışı bırakılsa bile, yalnızca söz dizimsel olarak eşdeğer sorgularda zorlamalı parametreleştirmenin deneneceğini belirtebilirsiniz. Plan kılavuzları bu amaçla kullanılır.
Uyarı
PARAMETERIZATION seçeneği FORCED olarak ayarlandığında, hata iletilerinin raporlanması PARAMETERIZATION seçeneği SIMPLE olarak ayarlandığında farklı olabilir: zorlamalı parametreleme altında birden çok hata iletisi bildirilebilir, basit parametreleme altında ise daha az ileti bildirilir ve hataların oluştuğu satır numaraları yanlış bildirilebilir.
SQL deyimlerini hazırlama
SQL Server ilişkisel motoru, Transact-SQL deyimlerini yürütülmeden önce hazırlamak için tam destek sunar. Bir uygulamanın birkaç kez Transact-SQL deyimi yürütmesi gerekiyorsa, aşağıdakileri yapmak için veritabanı API'sini kullanabilir:
- Beyanı bir kez hazırlayın. Bu işlem, Transact-SQL deyimini bir yürütme planına derler.
- İfadeyi her yürütmesi gerektiğinde önceden derlenmiş yürütme planını yürütür. Bu, Transact-SQL ifadesinin, ilk çalıştırmadan sonra her bir yürütmede yeniden derlenmesini önler. Deyimlerin hazırlanması ve yürütülmesi API işlevleri ve yöntemleri tarafından denetlenir. Transact-SQL dilinin bir parçası değildir. Transact-SQL deyimlerini yürütmeye yönelik hazırlama/yürütme modeli SQL Server Yerel İstemci OLE DB Sağlayıcısı ve SQL Server Yerel İstemci ODBC sürücüsü tarafından desteklenir. Hazırlama isteğinde, ya sağlayıcı ya da sürücü ifadeyi hazırlama talebiyle SQL Server'a gönderir. SQL Server bir yürütme planı derler ve bu plan için sağlayıcıya veya sürücüye bir tanıtıcı döndürür. Yürütme isteğinde, sağlayıcı veya sürücü sunucuya tanıtıcıyla ilişkili planı yürütmek için bir istek gönderir.
Hazırlanan deyimler SQL Server'da geçici nesneler oluşturmak için kullanılamaz. Hazırlanan deyimler, geçici tablolar gibi geçici nesneler oluşturan sistem saklı yordamlarına referans veremez. Bu prosedürler doğrudan uygulanmalıdır.
Hazırlama/yürütme modelinin fazla kullanımı performansı düşürebilir. Eğer bir ifade yalnızca bir kez yürütülürse, doğrudan sunucuya yapılan yürütme yalnızca bir ağ gidiş-dönüşü gerektirir. Yalnızca bir kez yürütülen bir Transact-SQL ifadesinin hazırlanması ve yürütülmesi fazladan bir ağ gidiş dönüşü gerektirir; ifadeyi hazırlamak için bir gidiş ve onu yürütmek için bir dönüş.
Parametre işaretçileri kullanıldığında bir açıklama hazırlamak daha etkilidir. Örneğin, bir uygulamanın zaman zaman örnek veritabanından ürün bilgilerini almasının AdventureWorks istendiğini varsayalım. Uygulamanın bunu yapmanın iki yolu vardır.
Uygulama, ilk yöntemi kullanarak istenen her ürün için ayrı bir sorgu yürütebilir:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
İkinci yöntemle, uygulama aşağıdakileri yapar:
Parametre işaretçisi (?) içeren bir deyim hazırlar:
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Bir program değişkenini parametre işaretçisine bağlar.
Ürün bilgilerine her ihtiyaç duyulduğunda, ilişkili değişkeni anahtar değeriyle doldurur ve deyimini yürütür.
İkinci yol, deyimi üçten fazla kez yürütülürken daha verimlidir.
SQL Server'da, SQL Server'ın yürütme planlarını yeniden kullanma şekli nedeniyle hazırlama/yürütme modelinin doğrudan yürütmeye kıyasla önemli bir performans avantajı yoktur. SQL Server, geçerli Transact-SQL deyimlerini aynı Transact-SQL deyiminin önceki yürütmeleri için oluşturulan yürütme planlarıyla eşleştirmek için verimli algoritmalara sahiptir. Bir uygulama parametre işaretçileri içeren bir Transact-SQL deyimini birden çok kez yürütürse, SQL Server ikinci ve sonraki yürütmeler için ilk yürütmenin yürütme planını yeniden kullanır (plan önbelleğinden çıkarılmadığı sürece). Hazırlama/yürütme modelinin hala şu avantajları vardır:
- Bir yürütme planını bir tanıtıcı ile bulmak, bir Transact-SQL deyimini mevcut yürütme planlarıyla eşleştirmek için kullanılan algoritmalara göre daha verimlidir.
- Uygulama, yürütme planının ne zaman oluşturulduğunu ve ne zaman yeniden kullanıldığını denetleyebilir.
- Hazırlama/yürütme modeli, SQL Server'ın önceki sürümleri de dahil olmak üzere diğer veritabanlarına taşınabilir.
Parametre duyarlılığı
"Parametre algılama" olarak da bilinen parametre duyarlılığı, SQL Server'ın derleme veya yeniden derleme sırasında geçerli parametre değerlerini "kokladığı" ve daha verimli olabilecek sorgu yürütme planları oluşturmak için kullanılabilmesi için bunu Sorgu İyileştiricisi'ne geçirdiği bir işlemi ifade eder.
Parametre değerleri, aşağıdaki toplu iş türleri için derleme veya yeniden derleme işlemleri sırasında incelenir:
- Saklanan prosedürler
- Aracılığıyla gönderilen sorgular
sp_executesql - Hazırlanan sorgular
Parametre algılama sorunlarını giderme hakkında daha fazla bilgi için bkz:
- Parametreye duyarlı sorunları araştırma ve çözme
- Parametreler ve Yürütme Planı Yeniden Kullanımı
- Parametreye Duyarlı Plan optimizasyonu
- Azure SQL Veritabanı'nda parametreye duyarlı sorgu yürütme planı sorunlarıyla ilgili sorguları giderme
- Azure SQL Yönetilen Örneği'nde parametreye duyarlı sorgu yürütme planı sorunlarıyla ilgili sorguları giderme
SQL Server'daki bir sorgu ipucunu OPTION (RECOMPILE) kullandığında, sorgu iyileştiricisi parametreyi ve yerel değişkenleri sabit olarak katlanıp değişmez değerlere indirgenebilen derleme zamanı sabitlerine dönüştürür. Bu, derleme sırasında iyileştiricinin parametrelerin ve yerel değişkenlerin geçerli çalışma zamanı değerlerini, bu deyimden hemen önce var oldukları için bildiği ve kullanabileceği anlamına gelir. OPTION (RECOMPILE), iyileştiricinin belirli değerlere göre uyarlanmış daha uygun bir sorgu planı oluşturmasına ve çalışma zamanında en iyi temel dizinlerden yararlanmasına olanak tanır. Parametreler için, bu işlem toplu işleme veya saklı yordama başlangıçta geçirilen değerleri değil, yeniden derleme sırasındaki değerlerini ifade eder. Bu değerler, RECOMPILE içeren deyime ulaşmadan önce yordam içerisinde değiştirilmiş olabilir. Bu davranış, yüksek oranda değişken veya çarpık giriş verilerine sahip sorgular için performansı geliştirebilir.
Yerel değişkenler
Bir sorgu yerel değişkenler kullandığında, SQL Server derleme zamanında değerlerini algılayamaz, bu nedenle kullanılabilir istatistikleri veya buluşsal yöntemleri kullanarak kardinaliteyi tahmin eder. İstatistikler varsa, koşulla eşleşen satır sayısını tahmin etmek için genellikle istatistiksel histogramdaki Tüm Yoğunluk değerini ( ortalama yoğunluk olarak da bilinir) kullanır. Ancak, sütun için istatistikler mevcut değilse, SQL Server, eşitlik predikatlarında 10% ve eşitsizlikler ile aralıklar için 30% seçiciliği varsayarak, daha az doğru yürütme planlarına yol açabilecek buluşsal tahminlere geri döner. Aşağıda yerel değişken kullanan bir sorgu örneği verilmiştır.
DECLARE @ProductId INT = 100;
SELECT * FROM Products WHERE ProductId = @ProductId;
Bu durumda, SQL Server sorguyu iyileştirmek için 100 değerini kullanmaz. Genel bir tahmin kullanır.
Paralel sorgu işleme
SQL Server, birden fazla mikro işlemciye (CPU) sahip bilgisayarlar için sorgu yürütme ve dizin işlemlerini iyileştirmeye yönelik paralel sorgular sağlar. SQL Server birkaç işletim sistemi çalışan iş parçacığı kullanarak paralel bir sorgu veya dizin işlemi gerçekleştirebildiğinden, işlem hızlı ve verimli bir şekilde tamamlanabilir.
Sorgu iyileştirme sırasında SQL Server, paralel yürütmeden yararlanabilecek sorguları veya dizin işlemlerini arar. Bu sorgular için SQL Server, sorguyu paralel yürütmeye hazırlamak için sorgu yürütme planına exchange işleçleri ekler. Exchange işleci, işlem yönetimi, veri yeniden dağıtım ve akış denetimi sağlayan sorgu yürütme planındaki bir işleçtir. Exchange işleci, alt tür olarak Distribute Streams, Repartition Streams ve Gather Streams mantıksal işleçlerini içerir, bunlardan biri veya daha fazlası paralel sorgu için sorgu planının Showplan çıkışında görünebilir.
Önemli
Bazı yapılar, SQL Server'ın tüm yürütme planında, parçalarında veya yürütme planında paralellik kullanma yeteneğini engeller.
Paralelliği engelleyen yapılar şunlardır:
Skaler Kullanıcı Tanımlı İşlevler
Skaler kullanıcı tanımlı işlevler hakkında daha fazla bilgi için bkz. Kullanıcı Tanımlı İşlevler Oluşturma. SQL Server 2019 'dan (15.x) başlayarak, SQL Server Veritabanı Altyapısı bu işlevleri satır içi yapma ve sorgu işleme sırasında paralellik kullanımının kilidini açma özelliğine sahiptir. Skaler UDF inlining hakkında daha fazla bilgi için bkz. SQL veritabanlarında akıllı sorgu işleme.Uzak Sorgu
Uzak Sorgu hakkında daha fazla bilgi için Showplan Mantıksal ve Fiziksel İşleçler Referansı bölümüne bakın.Dinamik imleçler
İmleçler hakkında daha fazla bilgi için bkz. İMLECI BILDIRME.Özyinelemeli sorgular
Özyineleme hakkında daha fazla bilgi için bkz. T-SQL'deÖzyinelemeli Ortak Tablo İfadeleri ve Özyineleme Tanımlama ve Kullanma Yönergeleri.Çok ifadeli tablo değerli işlevler (MSTVFs)
MSTVF'ler hakkında daha fazla bilgi için bkz. Kullanıcı Tanımlı İşlevler Oluşturma (Veritabanı Altyapısı).TOP anahtar sözcüğü
Daha fazla bilgi için bkz. TOP (Transact-SQL).
Sorgu yürütme planı QueryPlan öğesinde NonParallelPlanReason özniteliğini içerebilir ve paralelliğin neden kullanılmadığı açıklanır. Bu özniteliğin değerleri şunlardır:
| NonParallelPlanReason Değeri | Açıklama |
|---|---|
| MaxDOPSetToOne | En yüksek paralellik derecesi 1 olarak ayarlanır. |
| TahminiDOPBir | Tahmini paralellik derecesi 1'dir. |
| Uzaktan Sorguyla Paralellik Yok | Paralellik uzak sorgular için desteklenmez. |
| ParalelDinamikİmleçYok | Dinamik imleçler için paralel planlar desteklenmez. |
| Paralel Hızlı İleri Sarma İmleci Yok | Hızlı imleçler için paralel planlar desteklenmez. |
| İşaretleyiciyle Paralel Olmayan İmleç Alma | Yer işaretiyle getirilen imleçler için paralel planlar desteklenmez. |
| İşletme Sürümü Olmayan Sürümde Paralel Dizin Oluşturma Yok | Paralel dizin oluşturma, Enterprise dışı sürümler için desteklenmez. |
| Masaüstü veya Express Sürümde Paralel Planlar Yok | Masaüstü ve Express sürümü için paralel planlar desteklenmez. |
| Paralelize Edilemez İçsel Fonksiyon | Sorgu paralelleştirilemez bir iç işleve başvuruyor. |
| CLR Kullanıcı Tanımlı Fonksiyonu Veri Erişimi Gerektirir | Paralellik, veri erişimi gerektiren bir CLR UDF için desteklenmez. |
| TSQLKullanıcıTanımlıFonksiyonlarParalelÇalıştırılamaz | Sorgu, paralelleştirilebilir olmayan bir T-SQL Kullanıcı Tanımlı İşleve başvuruyor. |
| TabloDeğişkeniİşlemleriParalelİçİşlemleriDesteklemez | Tablo değişkeni işlemleri paralel iç içe geçmiş işlemleri desteklemez. |
| DMLSorgusuÇıktıyıMüşteriyeGönderir | DML sorgusu istemciye çıktı döndürür ve paralelleştirilebilir değildir. |
| Karışık Sıralı ve Paralel Çevrimiçi Dizin Oluşturma Desteklenmiyor | Tek bir çevrimiçi dizin oluşturma için desteklenmeyen seri ve paralel plan karışımı. |
| Geçerli Bir Paralel Plan Oluşturulamıyor | Paralel planın doğrulanması başarısız oldu, seriye geri dönülüyor. |
| Bellek Optimizasyonlu Tablolar için Paralellik Yok | Başvurulan In-Memory OLTP tabloları için paralellik desteklenmiyor. |
| Bellek İle Optimizasyon Yapılmış Tablo İçin Paralel DML Yok | In-Memory OLTP tablosunda DML için paralellik desteklenmez. |
| Yerel Olarak Derlenmiş Modül İçin Paralel Yok | Referans verilen yerel derlenmiş modüller için paralellik desteklenmez. |
| Aralıklar Yeniden Başlatılabilir Oluşturulamaz | Devam edebilen bir oluşturma işlemi için aralık üretimi başarısız oldu. |
Exchange işleçleri eklendikten sonra, sonuç paralel sorgu yürütme planıdır. Paralel sorgu yürütme planı birden fazla çalışan iş parçacığı kullanabilir. Paralel olmayan (seri) bir sorgu tarafından kullanılan seri yürütme planı, yürütmesi için yalnızca bir çalışan iş parçacığı kullanır. Paralel sorgu tarafından kullanılan çalışan iş parçacıklarının gerçek sayısı sorgu planı yürütme başlatma sırasında belirlenir ve planın karmaşıklığı ve paralellik derecesi tarafından belirlenir.
Paralellik derecesi (DOP), kullanılan en fazla CPU sayısını belirler; bu, kullanılmakta olan çalışan iş parçacığı sayısı anlamına gelmez. DOP sınırı, görev başına ayarlanır. Bu, talep başına veya sorgu başına bir sınır değildir. Bu, paralel sorgu yürütme sırasında tek bir isteğin zamanlayıcıya atanmış birden çok görev oluşturabileceği anlamına gelir. MaxDOP tarafından belirtilenden daha fazla işlemci, farklı görevler eşzamanlı olarak yürütülürken sorgu yürütmenin belirli bir noktasında eşzamanlı olarak kullanılabilir. Daha fazla bilgi için bkz. İş Parçacığı ve Görev Mimarisi Kılavuzu.
Sql Server Sorgu İyileştiricisi, aşağıdaki koşullardan biri doğruysa sorgu için paralel yürütme planı kullanmaz:
- Seri yürütme planı önemsizdir veya paralellik ayarı için maliyet eşiğini aşmaz.
- Seri yürütme planı, iyileştirici tarafından keşfedilen paralel yürütme planlarından daha düşük toplam tahmini alt ağaç maliyetine sahiptir.
- Sorgu, paralel olarak çalıştırılamayan skaler veya ilişkisel işleçler içeriyor. Bazı işleçler, sorgu planının bir bölümünün seri modda çalışmasına veya planın tamamının seri modda çalışmasına neden olabilir.
Uyarı
Paralel bir planın toplam tahmini alt ağaç maliyeti, paralellik ayarı için maliyet eşiğinden daha düşük olabilir. Bu, seri planın toplam tahmini alt ağaç maliyetinin bunu aştığını ve toplam tahmini alt ağaç maliyetinin daha düşük olduğu sorgu planının seçildiğini gösterir.
Paralellik derecesi (DOP)
SQL Server, paralel sorgu yürütme veya dizin veri tanımı dili (DDL) işleminin her örneği için en iyi paralellik derecesini otomatik olarak algılar. Bunu aşağıdaki ölçütlere göre yapar:
SQL Server'ın simetrik çok işlemcili bilgisayar (SMP) gibi birden fazla mikro işlemciye veya CPU'ya sahip bir bilgisayarda çalışıp çalışmadığı. Yalnızca birden fazla CPU'ya sahip bilgisayarlar paralel sorgular kullanabilir.
Yeterli iş parçacığının mevcut olup olmadığı Her sorgu veya dizin işleminin yürütülmesi için belirli sayıda çalışan iş parçacığı gerekir. Paralel plan yürütmek için seri plana göre daha fazla çalışan iş parçacığı gerekir ve gerekli çalışan iş parçacıklarının sayısı paralellik derecesiyle artar. Paralel planın belirli bir paralellik derecesi için çalışan iş parçacığı gereksinimi karşılanamıyorsa, SQL Server Veritabanı Altyapısı paralellik derecesini otomatik olarak azaltır veya belirtilen iş yükü bağlamında paralel planı tamamen bırakır. Ardından (bir çalışan iş parçacığı kullanan) seri planı yürütür.
Yürütülen sorgu veya dizin işleminin türü. Dizin oluşturan veya yeniden oluşturan ya da kümelenmiş dizini bırakan dizin işlemleri ve cpu döngülerini yoğun olarak kullanan sorgular paralel plan için en iyi adaylardır. Örneğin, büyük tabloların birleşimleri, büyük toplamalar ve büyük sonuç kümelerinin sıralanması iyi adaylardır. İşlem işleme uygulamalarında sıklıkla bulunan basit sorgular, bir sorguyu paralel olarak yürütmek için gereken ek koordinasyonu potansiyel performans artışından daha ağır basıyor. Paralellikten yararlanan sorgular ile fayda sağlamayan sorguları ayırt etmek için, SQL Server Veritabanı Altyapısı sorguyu veya dizin işlemini yürütmenin tahmini maliyetini paralellik değerinin maliyet eşiğiyle karşılaştırır. Düzgün test, çalışan iş yükü için farklı bir değerin daha uygun olduğunu tespit ederse, kullanıcılar sp_configure kullanarak varsayılan 5 değerini değiştirebilir.
İşlenmek için yeterli sayıda satır olup olmadığı. Sorgu İyileştirici, satır sayısının çok düşük olduğunu belirlerse, satırları dağıtmak için değişim operatörleri kullanmaz. Bu nedenle, işleçler seri olarak yürütülür. İşleçlerin seri planda yürütülmesi, başlatma, dağıtım ve koordinasyon maliyetlerinin paralel işleç yürütmesi tarafından elde edilen kazanımları aşması senaryolarını önler.
Geçerli dağıtım istatistiklerinin kullanılabilir olup olmadığı. En yüksek paralellik derecesi mümkün değilse, paralel plan terk edilmeden önce düşük dereceler dikkate alınır. Örneğin, bir görünümde kümelenmiş dizin oluşturduğunuzda, kümelenmiş dizin henüz mevcut olmadığından dağıtım istatistikleri değerlendirilemiyor. Bu durumda, SQL Server Veritabanı Altyapısı dizin işlemi için en yüksek paralellik derecesini sağlayamaz. Ancak sıralama ve tarama gibi bazı işleçler paralel yürütmeden yararlanmaya devam edebilir.
Uyarı
Paralel dizin işlemleri yalnızca SQL Server Enterprise, Developer ve Evaluation sürümlerinde kullanılabilir.
Yürütme zamanında SQL Server Veritabanı Altyapısı, daha önce açıklanan geçerli sistem iş yükünün ve yapılandırma bilgilerinin paralel yürütmeye izin verip vermediğini belirler. Paralel yürütme garanti edilirse, SQL Server Veritabanı Altyapısı en iyi çalışan iş parçacığı sayısını belirler ve paralel planın yürütülmesini bu çalışan iş parçacıklarına yayar. Paralel yürütme için bir sorgu veya dizin işlemi birden çok çalışan iş parçacığında yürütülmeye başladığında, işlem tamamlanana kadar aynı sayıda çalışan iş parçacığı kullanılır. SQL Server Veritabanı Motoru, bir yürütme planı plan önbelleğinden her alındığında çalışan iş parçacıkları için en uygun sayıyı yeniden değerlendirir. Örneğin, bir sorgunun bir çalıştırılması seri bir plan kullanabilir; aynı sorgunun daha sonra çalıştırılması üç iş parçacığı kullanan paralel bir planla sonuçlanabilir ve üçüncü bir çalıştırma dört iş parçacığı kullanan paralel bir planla sonuçlanabilir.
Paralel sorgu yürütme planındaki güncelleştirme ve silme işleçleri seri olarak yürütülür, ancak WHERE bir UPDATE veya DELETE deyiminin yan tümcesi paralel olarak yürütülebilir. Gerçek veri değişiklikleri daha sonra veritabanına seri olarak uygulanır.
SQL Server 2012'ye (11.x) kadar, ekleme işleci de seri olarak yürütülür. Ancak, INSERT deyiminin SELECT bölümü paralel olarak yürütülebilir. Gerçek veri değişiklikleri daha sonra veritabanına seri olarak uygulanır.
SQL Server 2014 (12.x) ve veritabanı uyumluluk düzeyi 110'dan başlayarak deyimi SELECT ... INTO paralel olarak yürütülebilir. Diğer ekleme işleçleri, SQL Server 2012 (11.x) için açıklandığı şekilde çalışır.
SQL Server 2016 (13.x) ve veritabanı uyumluluk düzeyi 130'dan başlayarak, INSERT ... SELECT ifade yığınlara veya kümelenmiş columnstore dizinlerine (CCI) eklenirken ve TABLOCK ipucunu kullanarak aynı anda yürütülebilir. Yerel geçici tablolara (# önekiyle tanımlanır) ve genel geçici tablolara (## ön ekleriyle tanımlanır) ekler, TABLOCK ipucu kullanılarak paralellik için de etkinleştirilir. Daha fazla bilgi için bkz . INSERT (Transact-SQL).
Statik ve anahtar kümesine dayalı imleçler, paralel yürütme planları tarafından doldurulabilir. Ancak, dinamik imleçlerin davranışı yalnızca seri yürütme tarafından sağlanabilir. Sorgu İyileştiricisi, dinamik imlecin parçası olan bir sorgu için her zaman bir seri yürütme planı oluşturur.
Paralellik derecelerini geçersiz kılma
Paralellik derecesi, paralel plan yürütmede kullanılacak işlemci sayısını ayarlar. Bu yapılandırma çeşitli düzeylerde ayarlanabilir:
Sunucu yapılandırma seçeneği olarak maksimum paralellik derecesi (MAXDOP) kullanılarak, sunucu düzeyinde.
Şunlar için geçerlidir: SQL ServerUyarı
SQL Server 2019 (15.x), yükleme işlemi sırasında MAXDOP sunucu yapılandırma seçeneğini ayarlamak için otomatik öneriler sunar. Kurulum kullanıcı arabirimi, önerilen ayarları kabul etmenizi veya kendi değerinizi girmenizi sağlar. Daha fazla bilgi için bkz. Veritabanı Altyapısı Yapılandırması - MaxDOP sayfası.
MAX_DOPResource Governor iş yükü grubu yapılandırma seçeneği kullanılarak iş yükü düzeyi.
Şunlar için geçerlidir: SQL ServerVeritabanı seviyesi, MAXDOPveritabanı kapsamlı yapılandırması kullanılarak.
Şunlar için geçerlidir: SQL Server ve Azure SQL VeritabanıSorgu veya dizin deyimi düzeyi, MAXDOPsorgu ipucunu veya MAXDOP dizin seçeneğini kullanarak. Örneğin, çevrimiçi dizin işlemine ayrılmış işlemci sayısını artırarak veya azaltarak denetlemek için MAXDOP seçeneğini kullanabilirsiniz. Bu şekilde, bir dizin işlemi tarafından kullanılan kaynakları eşzamanlı kullanıcıların kaynaklarıyla dengeleyebilirsiniz.
Şunlar için geçerlidir: SQL Server ve Azure SQL Veritabanı
En yüksek paralellik derecesi seçeneğinin 0 (varsayılan) olarak ayarlanması, SQL Server'ın bir paralel plan yürütmesinde en fazla 64 işlemciye kadar kullanılabilir tüm işlemcileri kullanmasını sağlar. MAXDOP seçeneği 0 olarak ayarlandığında SQL Server 64 mantıksal işlemciden oluşan bir çalışma zamanı hedefi ayarlasa da, gerekirse farklı bir değer el ile ayarlanabilir. Sorgular ve dizinler için MAXDOP değerini 0 olarak ayarlamak, SQL Server'ın paralel plan yürütmesinde verilen sorgular veya dizinler için en fazla 64 işlemciye kadar kullanılabilir tüm işlemcileri kullanmasına olanak tanır. MAXDOP, tüm paralel sorgular için zorlanan bir değer değil, paralellik için uygun tüm sorgular için belirsiz bir hedeftir. Bu, çalışma zamanında yeterli çalışan iş parçacığı yoksa, bir sorgunun MAXDOP sunucu yapılandırma seçeneğinden daha düşük bir paralellik derecesiyle yürütülebileceği anlamına gelir.
Tavsiye
Daha fazla bilgi için, MAXDOP önerileri kısmına bakınız; sunucu, veritabanı, sorgu veya tavsiye düzeyinde MAXDOP yapılandırma yönergeleri içindir.
Paralel sorgu örneği
Aşağıdaki sorgu, 1 Nisan 2000'den başlayarak belirli bir üç aylık dönem içinde verilen ve müşteri tarafından taahhüt edilen tarihten sonra siparişin en az bir satır öğesinin alındığı sipariş sayısını sayar. Bu sorgu, her sıralama önceliğine göre gruplandırılmış ve artan öncelik sırasına göre sıralanmış bu tür siparişlerin sayısını listeler.
Bu örnekte teorik tablo ve sütun adları kullanılır.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
İlk olarak `lineitem` ve `orders` tablolarında aşağıdaki dizinlerin tanımlandığını varsayalım:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Aşağıda daha önce gösterilen sorgu için oluşturulmuş olası paralel planlardan biri gösterilmiştir:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
Aşağıdaki çizimde paralellik derecesi 4 olan ve iki tabloyu birleştiren bir sorgu planı gösterilmektedir.
Paralel plan üç paralellik işleci içerir. Hem dizinin Index Seek işleci o_datkey_ptr hem de dizinin Dizin Tarama işleci l_order_dates_idx paralel olarak gerçekleştirilir. Bu, birden fazla özel akış oluşturur. Bu, sırasıyla Dizin Tarama ve Dizin Arama işleçlerinin üzerindeki en yakın Paralellik işleçlerinden belirlenebilir. Her ikisi de değişim türünü yeniden bölümlediriyor. Yani, yalnızca akışlar arasında veriyi yeniden düzenler ve çıkışlarında girişlerinde bulunan aynı sayıda akış üretirler. Bu akış sayısı paralellik derecesine eşittir.
Üzerindeki paralellik işleci l_order_dates_idx Dizin Taraması işlecinin, giriş akışlarını L_ORDERKEY değerini anahtar olarak kullanarak yeniden bölümlemektedir. Bu şekilde, L_ORDERKEY aynı değerleri aynı çıkış akışında son bulur. Aynı zamanda, çıkış akışları Birleştirme İşlecinin L_ORDERKEY sütunundaki giriş gereksinimini karşılamak için sırayı korur.
Index Seek işlecinin üzerindeki paralellik işleci, değerini O_ORDERKEYkullanarak giriş akışlarını yeniden bölümlemektedir. Girdi, O_ORDERKEY sütun değerlerinde sıralanmadığı için ve bu sütun Merge Join operatöründe birleştirme sütunu olduğu için, Paralellik ve Birleştirme işleçleri arasındaki Sıralama operatörü, Merge Join operatörü için girşin birleştirme sütunlarında sıralanmış olmasını sağlar. Sort işleci, Birleştirme işleci gibi paralel olarak gerçekleştirilir.
En üstteki paralellik işleci, çeşitli akışlardan tek bir akışta sonuç toplar. Paralellik işlecinin altındaki Stream Aggregate işleci tarafından gerçekleştirilen kısmi toplamalar, paralellik işlecinin üzerindeki Stream Aggregate işlecinde her bir farklı SUM değeri için tek bir O_ORDERPRIORITY değerinde toplanır. Bu plan, paralellik derecesi 4'e eşit olan iki değişim kesimine sahip olduğundan sekiz çalışan iş parçacığı kullanır.
Bu örnekte kullanılan işleçler hakkında daha fazla bilgi için bkz. Showplan Mantıksal ve Fiziksel İşleçler Başvurusu.
Paralel dizin işlemleri
Bir dizini oluşturan veya yeniden oluşturan ya da kümelenmiş bir dizini bırakan dizin işlemleri için oluşturulan sorgu planları, birden fazla mikro işlemcisi olan bilgisayarlarda paralel ve çok iş parçacıklı çalışan işlemlere izin verir.
Uyarı
Paralel dizin işlemleri yalnızca SQL Server 2008 (10.0.x) ile başlayarak Enterprise Sürümü'da kullanılabilir.
SQL Server, diğer sorgularda olduğu gibi dizin işlemleri için paralellik derecesini (çalıştırılacak ayrı çalışan iş parçacıklarının toplam sayısı) belirlemek için aynı algoritmaları kullanır. Dizin işlemi için en yüksek paralellik derecesi, maksimum paralellik sunucusu yapılandırma seçeneğine tabidir. CREATE INDEX, ALTER INDEX, DROP INDEX ve ALTER TABLE deyimlerinde MAXDOP dizin seçeneğini ayarlayarak tek tek dizin işlemleri için en yüksek paralellik derecesini geçersiz kılabilirsiniz.
SQL Server Veritabanı Altyapısı bir dizin yürütme planı oluştururken, paralel işlemlerin sayısı aşağıdakilerden en düşük değere ayarlanır:
- Bilgisayardaki mikro işlemcilerin veya CPU'ların sayısı.
- En yüksek paralellik derecesi sunucu yapılandırma seçeneğinde belirtilen sayı.
- SQL Server çalışan iş parçacıkları için henüz belirlenen iş eşiğini aşmamış CPU sayısı.
Örneğin, sekiz CPU'su olan ancak en yüksek paralellik derecesinin 6 olarak ayarlandığı bir bilgisayarda, bir dizin işlemi için altıdan fazla paralel çalışan iş parçacığı oluşturulmaz. Bir dizin yürütme planı oluşturulduğunda bilgisayardaki CPU'lardan beşi SQL Server çalışma eşiğini aşarsa, yürütme planı yalnızca üç paralel çalışan iş parçacığı belirtir.
Paralel dizin işleminin ana aşamaları şunlardır:
- Bir eşgüdüm çalışan iş parçacığı, dizin anahtarlarının dağılımını tahmin etmek için tabloyu hızla ve rastgele tarar. Koordine eden iş parçacığı, paralel işlemlerin derecesine eşit sayıda anahtar aralığı oluşturacak ve bu anahtar aralıklarının her biri benzer sayıda satırı kapsayacak şekilde anahtar sınırlarını belirler. Örneğin, tabloda dört milyon satır varsa ve paralellik derecesi 4 ise, eşgüdümlü çalışan iş parçacığı her kümede 1 milyon satır içeren dört satır kümesini sınırlandıran anahtar değerleri belirler. Tüm CPU'ları kullanmak için yeterli anahtar aralığı oluşturulamazsa paralellik derecesi buna göre azalır.
- Koordine eden çalışan iş parçacığı, paralel işlemlerin derecesine eşit bir dizi çalışan iş parçacığı gönderir ve bu çalışan iş parçacıklarının işlerini tamamlanmasını bekler. Her çalışan iş parçacığı, yalnızca çalışan iş parçacığına atanan aralık içinde anahtar değerleri olan satırları alan bir filtre kullanarak temel tabloyu tarar. Her çalışan iş parçacığı, anahtar aralığındaki satırlar için bir dizin yapısı oluşturur. Bölümlenmiş dizin söz konusu olduğunda, her çalışan iş parçacığı belirli sayıda bölüm oluşturur. Bölümler çalışan iş parçacıkları arasında paylaşılmaz.
- Tüm paralel çalışan iş parçacıkları tamamlandıktan sonra, koordine eden çalışan iş parçacığı dizin alt birimlerini tek bir dizine bağlar. Bu aşama yalnızca çevrimdışı dizin işlemleri için geçerlidir.
Tek tek CREATE TABLE veya ALTER TABLE deyimler, dizin oluşturulmasını gerektiren birden çok kısıtlamaya sahip olabilir. Her dizin oluşturma işlemi birden çok CPU'su olan bir bilgisayarda paralel bir işlem olsa da, bu birden çok dizin oluşturma işlemi seri olarak gerçekleştirilir.
Dağıtılmış sorgu mimarisi
Microsoft SQL Server, Transact-SQL deyimlerinde heterojen OLE DB veri kaynaklarına başvurmak için iki yöntemi destekler:
Bağlı sunucu adları
Sistem saklı yordamlarısp_addlinkedservervesp_addlinkedsrvloginole db veri kaynağına sunucu adı vermek için kullanılır. Bu bağlı sunuculardaki nesnelere dört bölümlü adlar kullanılarak Transact-SQL deyimlerinde başvurulabilir. Örneğin, bağlı sunucu adıDeptSQLSrvrbaşka bir SQL Server örneğinde tanımlanmışsa, aşağıdaki deyim bu sunucudaki bir tabloya başvurur:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;Bağlı sunucu adı, OLE DB veri kaynağından bir satır kümesini açmak için bir
OPENQUERYifadede de belirtilebilir. Daha sonra bu satır kümesine Transact-SQL deyimlerindeki bir tablo gibi başvurulabilir.Geçici bağlayıcı adları
Bir veri kaynağına seyrek başvurular için,OPENROWSETveyaOPENDATASOURCEişlevleri, bağlı sunucuya bağlanmak için gereken bilgilerle belirtilir. Daha sonra satır kümesine, Transact-SQL deyimlerinde bir tabloya başvurulacağı şekilde başvurulabilir:SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server, ilişkisel altyapı ile depolama altyapısı arasında iletişim kurmak için OLE DB kullanır. İlişkisel altyapı, her Transact-SQL deyimini temel tablolardan depolama altyapısı tarafından açılan basit OLE DB satır kümelerinde bir dizi işlem halinde ayırır. Bu, ilişkisel altyapının herhangi bir OLE DB veri kaynağında basit OLE DB satır kümelerini de açabileceği anlamına gelir.
İlişkisel altyapı, bağlı sunucularda satır kümelerini açmak, satırları getirmek ve işlemleri yönetmek için OLE DB uygulama programlama arabirimini (API) kullanır.
Bağlı sunucu olarak erişilen her OLE DB veri kaynağı için, SQL Server çalıştıran sunucuda bir OLE DB sağlayıcısı bulunmalıdır. Belirli bir OLE DB veri kaynağında kullanılabilecek Transact-SQL işlemleri kümesi, OLE DB sağlayıcısının özelliklerine bağlıdır.
SQL Server'ın her örneği için, sabit sunucu rolünün sysadmin üyeleri SQL Server DisallowAdhocAccess özelliğini kullanarak bir OLE DB sağlayıcısı için geçici bağlayıcı adlarının kullanımını etkinleştirebilir veya devre dışı bırakabilir. Geçici erişim etkinleştirildiğinde, bu örnekte oturum açan tüm kullanıcılar, ağ üzerindeki ole db sağlayıcısı kullanılarak erişilebilen herhangi bir veri kaynağına başvuruda bulunarak geçici bağlayıcı adlarını içeren Transact-SQL deyimleri yürütebilir. Veri kaynaklarına erişimi denetlemek için, rolün sysadmin üyeleri söz konusu OLE DB sağlayıcısı için geçici erişimi devre dışı bırakabilir ve böylece kullanıcıları yalnızca yöneticiler tarafından tanımlanan bağlı sunucu adları tarafından başvuruda bulunan veri kaynaklarıyla sınırlandırabilir. Varsayılan olarak, SQL Server OLE DB sağlayıcısı için geçici erişim etkinleştirilir ve diğer tüm OLE DB sağlayıcıları için devre dışı bırakılır.
Dağıtılmış sorgular, kullanıcıların SQL Server hizmetinin çalıştığı Microsoft Windows hesabının güvenlik bağlamını kullanarak başka bir veri kaynağına (örneğin, dosyalar, Active Directory gibi ilişkisel olmayan veri kaynakları vb.) erişmesine izin verebilir. SQL Server, Windows oturum açma işlemleri için uygun şekilde oturum açma kimliğine bürüner; ancak SQL Server oturum açma işlemleri için bu mümkün değildir. Bu, dağıtılmış sorgu kullanıcısının izinleri olmayan başka bir veri kaynağına erişmesine izin verebilir, ancak SQL Server hizmetinin çalıştığı hesabın izinleri vardır. İlgili bağlı sunucuya erişme yetkisi olan belirli oturum açma bilgilerini tanımlamak için kullanın sp_addlinkedsrvlogin . Bu denetim geçici adlar için kullanılamaz, bu nedenle bir OLE DB sağlayıcısını geçici erişim için etkinleştirirken dikkatli olun.
Mümkün olduğunda, SQL Server birleştirmeler, kısıtlamalar, projeksiyonlar, sıralamalar ve gruplandırma işlemleri gibi ilişkisel işlemleri OLE DB veri kaynağına gönderir. SQL Server varsayılan olarak temel tabloyu SQL Server'da tarayarak ilişkisel işlemleri gerçekleştirmez. SQL Server, desteklediği SQL dil bilgisi düzeyini belirlemek için OLE DB sağlayıcısını sorgular ve bu bilgilere dayanarak sağlayıcıya mümkün olduğunca çok ilişkisel işlem gönderir.
SQL Server, bir OLE DB sağlayıcısının, anahtar değerlerin OLE DB veri kaynağı içinde nasıl dağıtıldığını gösteren istatistikler döndürmesi için bir mekanizma belirtir. Bu, SQL Server Sorgu İyileştiricisi'nin veri kaynağındaki veri desenini her Transact-SQL deyiminin gereksinimlerine göre daha iyi analiz edebilmesini sağlar ve Sorgu İyileştiricisi'nin en iyi yürütme planlarını oluşturma becerisini artırır.
Bölümlenmiş tablo ve dizinlerde sorgu işleme geliştirmeleri
SQL Server 2008 (10.0.x) birçok paralel plan için bölümlenmiş tablolarda sorgu işleme performansını geliştirdi, paralel ve seri planların temsili şeklini değiştirdi ve hem derleme zamanı hem de çalışma zamanı yürütme planlarında sağlanan bölümleme bilgilerini geliştirdi. Bu makalede bu geliştirmeler açıklanır, bölümlenmiş tabloların ve dizinlerin sorgu yürütme planlarının nasıl yorumlandığına ilişkin yönergeler sağlanır ve bölümlenmiş nesnelerde sorgu performansını geliştirmeye yönelik en iyi yöntemler sağlanır.
Uyarı
SQL Server 2014 (12.x) tarihine kadar bölümlenmiş tablolar ve dizinler yalnızca SQL Server Enterprise, Developer ve Evaluation sürümlerinde desteklenir. SQL Server 2016 (13.x) SP1'den başlayarak, bölümlenmiş tablolar ve dizinler SQL Server Standard sürümünde de desteklenir.
Yeni bölünmeye duyarlı arama işlemi
SQL Server'da, bölümlenmiş tablonun iç gösterimi, sorgu işlemcisinde tablonun birden fazla sütunlu dizinin öncü sütunu olarak PartitionID ile görüneceği şekilde değiştirilir.
PartitionID , belirli bir satırı içeren bölümü temsil ID etmek için dahili olarak kullanılan gizli bir hesaplanan sütundur. Örneğin, olarak T(a, b, c)tanımlanan T tablosunun a sütununda bölümlendiğini ve b sütununda kümelenmiş dizini olduğunu varsayalım. SQL Server'da, bu bölümlenmiş tablo, dahili olarak şeması T(PartitionID, a, b, c) ve bileşik anahtar (PartitionID, b) üzerinde kümelenmiş dizini olan bölümlenmemiş bir tablo olarak görülür. Bu, Sorgu İyileştiricisi'nin bölümlenmiş herhangi bir tabloya veya dizine göre PartitionID arama işlemleri gerçekleştirmesini sağlar.
Bölüm eleme işlemi artık bu arama işleminde gerçekleştirilir.
Buna ek olarak, Sorgu İyileştiricisi genişletilir, böylece bir koşula sahip bir arama veya tarama işlemi (mantıksal baştaki sütun olarak) ve büyük olasılıkla diğer dizin anahtarı sütunlarında PartitionID yapılabilir ve sonra farklı bir koşula sahip ikinci düzey bir arama, birinci düzey arama işleminin niteliğini karşılayan her ayrı değer için bir veya daha fazla ek sütunda yapılabilir. Başka bir ifadeyle, atlama taraması olarak adlandırılan bu işlem, Sorgu İyileştiricisi'nin erişilecek bölümleri belirlemek için bir arama veya tarama işlemi gerçekleştirmesine ve farklı bir koşula uyan bu bölümlerden satır döndürmek için bu işleç içindeki ikinci düzey dizin arama işlemine olanak tanır. Örneğin, aşağıdaki sorguyu göz önünde bulundurun.
SELECT * FROM T WHERE a < 10 and b = 2;
Bu örnekte, olarak T(a, b, c)tanımlanan T tablosunun a sütununda bölümlendiğini ve b sütununda kümelenmiş dizini olduğunu varsayalım. T tablosunun bölüm sınırları aşağıdaki bölüm işlevi tarafından tanımlanır:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
Sorguyu çözmek için sorgu işlemcisi, koşulunu T.a < 10karşılayan satırları içeren her bölümü bulmak için birinci düzey bir arama işlemi gerçekleştirir. Bu, erişilecek bölümleri tanımlar. Tanımlanan her bölümde, işlemci, T.b = 2 ve T.a < 10 koşulunu karşılayan satırları bulmak için b sütunundaki kümelenmiş dizine ikinci düzey bir arama gerçekleştirir.
Aşağıdaki çizim, taramayı atlama işleminin mantıksal bir gösterimidir.
T tablosunu, sütunlarda a ve b veri içererek gösterir. Bölümler, bölüm sınırları kesikli dikey çizgilerle gösterilen 1 ile 4 arasında numaralandırılır. Bölümlere yönelik birinci düzey arama işlemi (çizimde gösterilmez), 1, 2 ve 3 bölümlerinin tablo için tanımlanan bölümleme ve sütunundaki akoşulun ima ettiği arama koşulunu karşıladığını belirlemiştir. Yani, T.a < 10. Eğri çizgi, atlama tarama işleminin ikinci düzey arama kısmı tarafından geçilen yolu gösterir. Temel olarak, atlama tarama işlemi, b = 2 koşuluna uyan satırları bulmak için bu bölümlerin her birinde arama yapar. Taramayı atlama işleminin toplam maliyeti, üç ayrı dizin aramasıyla aynıdır.
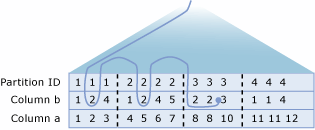
Sorgu yürütme planlarında bölümleme bilgilerini görüntüleme
Bölümlenmiş tablo ve dizinlerdeki sorguların yürütme planları, Transact-SQL SET ifadeleri SET SHOWPLAN_XML veya SET STATISTICS XML kullanılarak ya da SQL Server Management Studio'daki grafiksel yürütme planı kullanılarak görülebilir. Örneğin, Sorgu Düzenleyicisi araç çubuğunda Tahmini Yürütme Planını Görüntüle'yi ve Gerçek Yürütme Planını Dahil Et'i seçerek çalışma zamanı planını görüntüleyebilirsiniz.
Bu araçları kullanarak aşağıdaki bilgileri onaylayabilirsiniz:
- Bölümlenmiş tablolara veya dizinlere erişen
scans,seeks,inserts,updates,mergesvedeletesgibi işlemler. - Sorgu tarafından erişilen bölümler. Örneğin, erişilen bölümlerin toplam sayısı ve erişilen bitişik bölüm aralıkları çalışma zamanı yürütme planlarında kullanılabilir.
- Taramayı atlama işlemi bir veya daha fazla bölümden veri almak için bir arama veya tarama işleminde kullanıldığında.
Bölüm bilgi geliştirmeleri
SQL Server hem derleme zamanı hem de çalışma zamanı yürütme planları için gelişmiş bölümleme bilgileri sağlar. Yürütme planları artık aşağıdaki bilgileri sağlar:
- İsteğe bağlı
Partitionedözniteliği,seek,scan,insert,update,merge, veyadeletegibi bir işlecin bölümlenmiş tabloda gerçekleştirildiğini gösterir. - Yeni bir
SeekPredicateNewöğesi,SeekKeysalt öğesi ile birliktePartitionIDönde gelen dizin anahtarı sütunu vePartitionIDüzerinde aralık aramaları belirten filtre koşullarını içerir. İkiSeekKeysalt öğesinin varlığı,PartitionIDüzerinde bir atlama tarama işleminin kullanıldığını gösterir. - Erişilen bölümlerin toplam sayısını sağlayan özet bilgiler. Bu bilgiler yalnızca çalışma zamanı planlarında kullanılabilir.
Bu bilgilerin hem grafik yürütme planı çıkışında hem de XML Showplan çıkışında nasıl görüntülendiğini göstermek için, bölümlenmiş tabloda fact_salesaşağıdaki sorguyu göz önünde bulundurun. Bu sorgu iki bölümdeki verileri güncelleştirir.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
Aşağıdaki çizimde, bu sorgu için Clustered Index Seek çalışma zamanı yürütme planındaki işlecin özellikleri gösterilmektedir. Tablonun tanımını fact_sales ve bölüm tanımını görüntülemek için bu makaledeki "Örnek" bölümüne bakın.

Bölümlenmiş öznitelik
Bölümlenmiş bir tablo veya dizinde bir işleç, Dizin Arama gibi, yürütüldüğünde, Partitioned öznitelik derleme zamanı ve çalışma zamanı planında görünür ve True (1) değeri olarak ayarlanır. (0) olarak ayarlandığında False öznitelik görüntülenmez.
Partitioned özniteliği aşağıdaki fiziksel ve mantıksal işleçlerde görünebilir:
- Tablo Tarama
- Dizin Taraması
- Dizin Arama
- Yerleştir
- Güncelleştir
- Sil
- Birleştir
Önceki çizimde gösterildiği gibi, bu öznitelik tanımlandığı işlecin özelliklerinde görüntülenir. XML Showplan çıkışında bu öznitelik, tanımlandığı işlecin Partitioned="1" düğümünde RelOp olarak görünür.
Yeni arama koşulu
XML Showplan çıkışında SeekPredicateNew , öğesi tanımlandığı işleçte görünür.
SeekKeys alt öğesinden en fazla iki tane içerebilir. İlk SeekKeys öğe, mantıksal dizinin bölüm kimliği düzeyinde birinci düzey arama işlemini belirtir. Yani, bu arama sorgunun koşullarını karşılamak için erişilmesi gereken bölümleri belirler. İkinci SeekKeys öğe, ilk düzey aramada tanımlanan her bölüm içinde gerçekleşen atlama tarama işleminin ikinci düzey arama bölümünü belirtir.
Bölüm özeti bilgileri
Çalışma zamanı yürütme planlarında bölüm özeti bilgileri, erişilen bölümlerin sayısını ve erişilen gerçek bölümlerin kimliğini sağlar. Sorguda doğru bölümlere erişildiğini ve diğer tüm bölümlerin dikkate alınmadığını doğrulamak için bu bilgileri kullanabilirsiniz.
Aşağıdaki bilgiler sağlanır: Actual Partition Count, ve Partitions Accessed.
Actual Partition Count sorgu tarafından erişilen toplam bölüm sayısıdır.
Partitions Accessed, XML Showplan çıkışında, tanımlandığı işlecin RuntimePartitionSummary düğümünde, yeni RelOp öğesinde görünen bölüm özet bilgisidir. Aşağıdaki örnek, toplam iki bölüme (bölüm 2 ve 3) erişildiğini gösteren öğesinin içeriğini RuntimePartitionSummary gösterir.
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Diğer Showplan yöntemlerini kullanarak bölüm bilgilerini görüntüleme
Showplan yöntemleri SHOWPLAN_ALL, SHOWPLAN_TEXTve STATISTICS PROFILE aşağıdaki özel durumla birlikte bu makalede açıklanan bölüm bilgilerini raporlamaz. Koşulun SEEK bir parçası olarak, erişilecek bölümler bölüm kimliğini temsil eden hesaplanan sütundaki bir aralık koşulu tarafından tanımlanır. Aşağıdaki örnek, bir SEEK işleci için Clustered Index Seek predikatı göstermektedir. Bölüm 2 ve Bölüm 3'e erişim sağlanır, ve arama operatörü date_id BETWEEN 20080802 AND 20080902 koşulunu karşılayan satırları filtreler.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Bölümlenmiş yığınlar için yürütme planlarını yorumlama
Bölümlenmiş yığın, bölüm kimliğinde mantıksal dizin olarak kabul edilir. Bölümlenmiş bir yığında bölüm eleme, bir yürütme planında bölüm kimliği koşuluna sahip bir Table ScanSEEK işleç olarak temsil edilir. Aşağıdaki örnekte sağlanan Showplan bilgileri gösterilmektedir:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Birlikte bulunan birleşimler için yürütme planlarını yorumlama
Birleştirmede konumlandırma, iki tablo aynı veya eşdeğer bölümleme işlevi kullanılarak bölümlendiğinde ve birleştirmenin her iki tarafındaki bölümleme sütunları sorgunun birleştirme koşulunda belirtildiğinde oluşabilir. Sorgu İyileştiricisi, eşit bölüm kimliklerine sahip her tablonun bölümlerinin ayrı olarak birleştirildiği bir plan oluşturabilir. Birlikte bulunan birleşimler, daha az bellek ve işlem süresi gerektirebileceğinden, birlikte konumlandırılmamış birleşimlerden daha hızlı olabilir. Sorgu Düzenleyicisi, maliyet hesaplamasına göre çakışmayan bir plan veya çakışan bir plan seçer.
Eşleşmiş bir planda, Nested Loops iç tarafındaki bir veya daha fazla birleştirilmiş tablo veya dizin bölümünü okur. İşleçler içindeki Constant Scan sayılar bölüm numaralarını temsil eden sayılardır.
Bölümlenmiş tablolar veya dizinler için birlikte görünen birleşimler için paralel planlar oluşturulduğunda, Constant Scan ve Nested Loops birleştirme işleçleri arasında bir Paralellik işleci görünür. Bu durumda, birleştirmenin dış kısmındaki her bir çalışan iş parçacığı, farklı bir bölümü okur ve üzerinde çalışır.
Aşağıdaki çizimde, eş konumlu birleştirme için paralel sorgu planı gösterilmektedir.
Bölümlenmiş nesneler için paralel sorgu yürütme stratejisi
Sorgu işlemcisi, bölümlenmiş nesnelerden seçim yapılan sorgular için paralel yürütme stratejisi kullanır. Yürütme stratejisinin bir parçası olarak, sorgu işlemcisi sorgu için gereken tablo bölümlerini ve her bölüme ayrılacak çalışan iş parçacıklarının oranını belirler. Çoğu durumda, sorgu işlemcisi her bölüme eşit veya neredeyse eşit sayıda çalışan iş parçacığı ayırır ve ardından sorguyu bölümler arasında paralel olarak yürütür. Aşağıdaki paragraflarda çalışan iş parçacığı ayırma işlemi daha ayrıntılı açıklanmaktadır.
Çalışan iş parçacığı sayısı bölüm sayısından azsa, sorgu işlemcisi her çalışan iş parçacığını farklı bir bölüme atar ve başlangıçta atanmış bir çalışan iş parçacığı olmadan bir veya daha fazla bölüm bırakır. Bir çalışan iş parçacığı bir bölümde yürütmeyi bitirdiğinde, her bölüme tek bir çalışan iş parçacığı atanana kadar sorgu işlemcisi bunu bir sonraki bölüme atar. Bu, sorgu işlemcisinin çalışan iş parçacıklarını diğer bölümlere yeniden ayırması için tek durumdur.
Bir iş parçacığını tamamladıktan sonra yeniden atanan çalışan ipliği gösterir. Çalışan iş parçacığı sayısı bölüm sayısına eşitse, sorgu işlemcisi her bölüme bir çalışan iş parçacığı atar. Bir çalışan iş parçacığı tamamlandığında, başka bir bölüme yeniden ayrılmaz.

Çalışan iş parçacığı sayısı bölüm sayısından büyükse, sorgu işlemcisi her bölüme eşit sayıda çalışan iş parçacığı ayırır. Çalışan iş parçacığı sayısı bölüm sayısının tam katı değilse, sorgu işlemcisi kullanılabilir tüm çalışan iş parçacıklarını kullanmak için bazı bölümlere bir ek çalışan iş parçacığı ayırır. Yalnızca bir bölüm varsa, tüm çalışan iş parçacıkları bu bölüme atanır. Aşağıdaki diyagramda dört bölüm ve 14 iş parçacığı vardır. Her bölüme 3 çalışan iş parçacığı atanmıştır ve iki bölüm için fazladan birer çalışan iş parçacığı daha atanmıştır, bu da toplamda 14 çalışan iş parçacığı ataması yapıldığı anlamına gelir. Bir çalışan iş parçacığı tamamlandığında, başka bir bölüme yeniden atanmaz.

Yukarıdaki örnekler çalışan iş parçacıklarını ayırmak için basit bir yol önerse de, gerçek strateji daha karmaşıktır ve sorgu yürütme sırasında oluşan diğer değişkenleri sınar. Örneğin, tablo bölümlenmişse ve A sütununda kümelenmiş bir dizine sahipse ve sorgunun koşul yan tümcesi WHERE A IN (13, 17, 25)varsa, sorgu işlemcisi her tablo bölümü yerine bu üç arama değerine (A=13, A=17 ve A=25) bir veya daha fazla çalışan iş parçacığı ayırır. Sorgunun yalnızca bu değerleri içeren bölümlerde yürütülmesi gerekir ve eğer arama koşulları aynı tablo bölümünde yer alıyorsa, tüm iş parçacıkları bu tablo bölümüne atanacaktır.
Başka bir örnek vermek gerekirse, Tablonun A sütununda sınır noktaları (10, 20, 30), B sütununda bir dizin ve sorgunun koşul yan tümcesi WHERE B IN (50, 100, 150)bulunan dört bölümü olduğunu varsayalım. Tablo bölümleri A değerlerini temel alarak olduğundan, B değerleri tablo bölümlerinin herhangi birinde oluşabilir. Bu nedenle, sorgu işlemcisi dört tablo bölümünün her birinde B'nin üç değerinin (50, 100, 150) her birini arar. Sorgu işlemcisi, bu 12 sorgu taramasını paralel olarak yürütebilmesi için çalışan iş parçacıklarını orantılı olarak atar.
| A sütununa dayalı tablo bölümleri | Her bir tablo bölümünde B sütununu arama işlemi yapar |
|---|---|
| Tablo Bölümü 1: A < 10 | B=50, B=100, B=150 |
| Tablo Bölümü 2: A >= 10 VE A < 20 | B=50, B=100, B=150 |
| Tablo Bölümü 3: A >= 20 VE A < 30 | B=50, B=100, B=150 |
| Tablo Bölümü 4: A >= 30 | B=50, B=100, B=150 |
En iyi yöntemler
Büyük bölümlenmiş tablo ve dizinlerden büyük miktarda veriye erişen sorguların performansını artırmak için aşağıdaki en iyi yöntemleri öneririz:
- Her bölümü birçok disk arasında şeritleme. Bu özellikle dönen diskler kullanılırken geçerlidir.
- Mümkün olduğunda, G/Ç maliyetini azaltmak için sık erişilen bölümleri veya tüm bölümleri belleğe sığdırmak için yeterli ana belleğe sahip bir sunucu kullanın.
- Sorguladığınız veriler belleğe sığmıyorsa tabloları ve dizinleri sıkıştırın. Bu, G/Ç maliyetini düşürür.
- Paralel sorgu işleme özelliğinden yararlanmak için hızlı işlemcilere ve mümkün olduğunca çok işlemci çekirdeğine sahip bir sunucu kullanın.
- Sunucunun yeterli G/Ç denetleyicisi bant genişliğine sahip olduğundan emin olun.
- B ağacı tarama iyileştirmelerinden yararlanmak için her büyük bölümlenmiş tabloda kümelenmiş dizin oluşturun.
- Verileri bölümlenmiş tablolara toplu yüklerken Veri Yükleme Performansı Kılavuzu raporundaki en iyi uygulama tavsiyelerini izleyin.
Örnek
Aşağıdaki örnek, yedi bölüm içeren tek bir tablo içeren bir test veritabanı oluşturur. Bu örnekteki sorguları yürütürken daha önce açıklanan araçları kullanarak hem derleme zamanı hem de çalışma zamanı planlarının bölümleme bilgilerini görüntüleyin.
Uyarı
Bu örnek tabloya 1 milyondan fazla satır ekler. Bu örneği çalıştırmak, donanımınıza bağlı olarak birkaç dakika sürebilir. Bu örneği yürütmeden önce 1,5 GB'tan fazla disk alanınız olduğunu doğrulayın.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
İlgili içerik
- Mantıksal ve Fiziksel Showplan İşleç Referansı
- Genişletilmiş olaylara genel bakış
- Sorgu Deposu ile iş yüklerini izlemeye yönelik en iyi yöntemler
- Kardinalite Tahmini (SQL Server)
- SQL veritabanlarında akıllı sorgu işleme
- İşleç Önceliği (Transact-SQL)
- Yürütme planına genel bakış
- SQL Server Veritabanı Altyapısı ve Azure SQL Veritabanı için Performans Merkezi