Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Şunlar için geçerlidir:![]() SQL Server
SQL Server![]() Azure SQL Veritabanı
Azure SQL Veritabanı![]() Azure SQL Yönetilen Örneği
Azure SQL Yönetilen Örneği![]() Microsoft Fabric'te SQL veritabanı
Microsoft Fabric'te SQL veritabanı
SQL veritabanı projesinin geliştirme döngüsü, veritabanı geliştirmenin geliştirme için en iyi yöntem olarak bilinen sürekli tümleştirme ve sürekli dağıtım (CI/CD) iş akışlarıyla tümleştirilmesini sağlar. SQL veritabanı projesinin dağıtımı el ile yapılsa da, devam eden dağıtımlar ek çaba harcamadan devam eden yerel geliştirmenize göre çalıştırılacak şekilde dağıtım işlemini otomatikleştirmek için bir dağıtım işlem hattı kullanmanız önerilir.
Bu makalede yeni bir SQL projesi oluşturma, projeye nesne ekleme ve GitHub eylemleriyle projeyi derlemek ve dağıtmak için sürekli bir dağıtım işlem hattı ayarlama adımları gösterilmektedir. Kılavuz, SQL veritabanı projelerine giriş makalesinin içeriğinin üst kümesidir. Öğreticide GitHub eylemlerinde dağıtım işlem hattı uygulanırken Azure DevOps, GitLab ve diğer otomasyon ortamları için de aynı kavramlar geçerlidir.
Bu eğitimde, siz:
- Yeni bir SQL projesi oluşturma
- Projeye nesne ekleme
- Projeyi yerel olarak oluşturma
- Projeyi kaynak kontrolüne kaydet
- Sürekli dağıtım işlem hattına proje derleme adımı ekleme
- Sürekli dağıtım işlem hattına bir
.dacpacdağıtım adımı ekleyin
SQL veritabanı projelerini kullanmaya başlama adımlarını tamamladıysanız 4. adıma atlayabilirsiniz. Bu öğreticinin sonunda SQL projeniz otomatik olarak oluşturacak ve değişiklikleri hedef veritabanına dağıtacaktır.
Prerequisites
- .NET 10 SDK
- Visual Studio 2022 Community, Professional veya Enterprise sürümü
- visual studio için SQL Server Veri Araçları'nı (SSDT) yükleme
- .NET 8 SDK
- Visual Studio 2022 Community, Professional veya Enterprise sürümü
- SQL Server Veri Araçları, SDK stili (önizleme)
- .NET 10 SDK
- SqlPackage CLI
- Microsoft.Build.Sql.Templates .NET şablonlarını
# install SqlPackage CLI
dotnet tool install -g Microsoft.SqlPackage
# install Microsoft.Build.Sql.Templates
dotnet new install Microsoft.Build.Sql.Templates
GitHub'da işlem hattı kurulumunu tamamlamak için aşağıdaki öğelere sahip olduğunuzdan emin olun:
Depo oluşturabileceğiniz bir GitHub hesabı. Ücretsiz bir tane oluşturun.
GitHub eylemleri deponuzda etkinleştirilir .
Note
SQL veritabanı projesinin dağıtımını tamamlamak için Azure SQL veya SQL Server örneğine erişmeniz gerekir. Windows'da veya kapsayıcılarında SQL Server geliştirici sürümü ile ücretsiz olarak yerel olarak geliştirebilirsiniz.
1. Adım: Yeni proje oluşturma
El ile nesne eklemeden önce yeni bir SQL veritabanı projesi oluşturarak projemize başlıyoruz. Var olan bir veritabanındaki nesnelerle projeyi hemen doldurmayı sağlayan bir proje oluşturmanın, şema karşılaştırma araçlarını kullanma gibi başka yolları da vardır.
Dosya, Yeni, ardından Proje'yi seçin.
Yeni Proje iletişim kutusunda, arama kutusunda SQL Server terimini kullanın. En üstteki sonuç SQL Server Veritabanı Projesiolmalıdır.

Sonraki seçerek sonraki adıma geçin. Veritabanı adıyla eşleşmesi gerekmeyen bir proje adı girin. Proje konumunu gerektiği gibi doğrulayın ve değiştirin.
Projeyi oluşturmak için Oluştur'u seçin. Boş proje açılır ve Çözüm Gezgini'nde düzenleme için görünür.
Dosya, Yeni, ardından Proje'yi seçin.
Yeni Proje iletişim kutusunda, arama kutusunda SQL Server terimini kullanın. En üstteki sonuç SQL Server Veritabanı Projesi, SDK stili (önizleme)olmalıdır.

Sonraki seçerek sonraki adıma geçin. Veritabanı adıyla eşleşmesi gerekmeyen bir proje adı girin. Proje konumunu gerektiği gibi doğrulayın ve değiştirin.
Projeyi oluşturmak için Oluştur'u seçin. Boş proje açılır ve Çözüm Gezgini'nde düzenleme için görünür.
Visual Studio Code'un Veritabanı Projeleri görünümünde Yeni Proje düğmesini seçin.
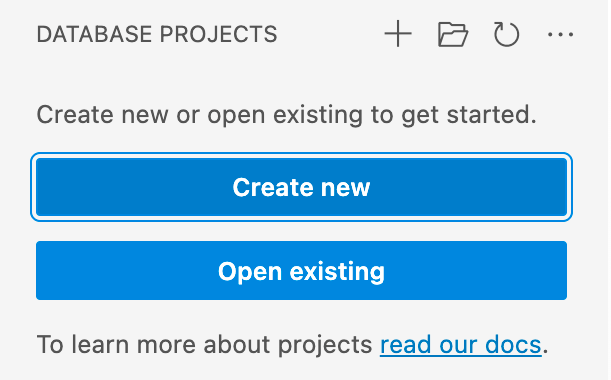
İlk istem, öncelikli olarak hedef platformun SQL Server mı yoksa Azure SQL mi olduğuna bağlı olarak hangi proje şablonunun kullanılacağını belirler. SQL'in belirli bir sürümünü seçmeniz istenirse, hedef veritabanıyla eşleşen sürümü seçin, ancak hedef veritabanı sürümü bilinmiyorsa, değer daha sonra değiştirilebileceği için en son sürümü seçin.
Görüntülenen metin girişine veritabanı adıyla eşleşmesi gerekmeyen bir proje adı girin.
Görüntülenen "Klasör Seç" iletişim kutusunda, projenin klasörü, .sqlproj dosyası ve içinde bulunabilecek diğer içerikler için bir dizin seçin.
SDK stili proje oluşturulup oluşturulmayacağı sorulduğunda evet seçin.
İşlem tamamlandıktan sonra boş proje açılır ve düzenleme için Veritabanı Projeleri görünümünde görünür.
Dosya, Yeni, ardından Proje'yi seçin.
Yeni Proje iletişim kutusunda SQL Veritabanı Projesi'ni seçin.

Sonraki seçerek sonraki adıma geçin. Veritabanı adıyla eşleşmesi gerekmeyen bir proje adı girin. Proje konumunu gerektiği gibi doğrulayın ve değiştirin.
Projeyi oluşturmak için Oluştur'u seçin. Boş proje açılır ve Çözüm Gezgini'nde düzenleme için görünür.
Microsoft.Build.Sql projeleri için .NET şablonları yüklüyse, komut satırından yeni bir SQL veritabanı projesi oluşturabilirsiniz.
-n seçeneği projenin adını, -tp seçeneği ise proje hedef platformunu belirtir.
Tüm kullanılabilir seçenekleri görmek için -h seçeneğini kullanın.
# create a new SQL database project
dotnet new sqlproj -n MyDatabaseProject
2. Adım: Projeye nesne ekleme
Çözüm Gezgini'nde proje düğümüne sağ tıklayın ve Ekle'yi seçin, ardından Tablo'yu seçin. Tablo adını belirtebileceğiniz Yeni Öğe Ekle iletişim kutusu görüntülenir. TABLOYU SQL projesinde oluşturmak için Ekle'yi seçin.
Tablo Visual Studio tablo tasarımcısında, sütun, dizin ve diğer tablo özelliklerini ekleyebileceğiniz şablon tablo tanımıyla açılır. İlk düzenlemeleri bitirdiğinizde dosyayı kaydedin.
Yeni Öğe Ekle iletişim kutusu aracılığıyla görünümler, saklı yordamlar ve işlevler gibi daha fazla veritabanı nesnesi eklenebilir. Çözüm Gezgini proje düğümüne sağ tıklayıp Ekleve ardından istediğiniz nesne türünü seçerek iletişim kutusuna erişin. Projedeki dosyalar, Eklealtındaki Yeni Klasör seçeneği aracılığıyla klasörler halinde düzenlenebilir.
Çözüm Gezgini'ndeproje düğümüne sağ tıklayın, Ekle'yiseçin ve ardından Yeni Öğe'yiseçin. Yeni Öğe Ekle iletişim kutusu görüntülenir, Tüm Şablonları Göster ve ardından Tablo seçin. Tablo adını dosya adı olarak belirtin ve SQL projesinde tablo oluşturmak için ekle'yi seçin.
Tablo Visual Studio sorgu düzenleyicisinde, sütun, dizin ve diğer tablo özelliklerini ekleyebileceğiniz şablon tablo tanımıyla açılır. İlk düzenlemeleri bitirdiğinizde dosyayı kaydedin.
Yeni Öğe Ekle iletişim kutusu aracılığıyla görünümler, saklı yordamlar ve işlevler gibi daha fazla veritabanı nesnesi eklenebilir. Çözüm Gezgini proje düğümüne sağ tıklayıp Ekle'i seçin, ardından Tüm Şablonları Gösterseçeneği ile istediğiniz nesne türünü belirleyin ve iletişim kutusuna erişin. Projedeki dosyalar, Eklealtındaki Yeni Klasör seçeneği aracılığıyla klasörler halinde düzenlenebilir.
Visual Studio Code'un Veritabanı Projeleri görünümünde proje düğümüne sağ tıklayın ve Tablo Ekle'yi seçin. Görüntülenen iletişim kutusunda tablo adını belirtin.
Tablo, sütun, dizin ve diğer tablo özelliklerini ekleyebileceğiniz şablon tablo tanımıyla metin düzenleyicisinde açılır. İlk düzenlemeleri bitirdiğinizde dosyayı kaydedin.
Proje düğümündeki bağlam menüsü aracılığıyla görünümler, saklı yordamlar ve işlevler gibi daha fazla veritabanı nesnesi eklenebilir. Visual Studio Code'un Veritabanı Projeleri görünümünde proje düğümüne sağ tıklayıp istediğiniz nesne türüne tıklayarak iletişim kutusuna erişin. Projedeki dosyalar, Eklealtındaki Yeni Klasör seçeneği aracılığıyla klasörler halinde düzenlenebilir.
Çözüm Gezgini'ndeproje düğümüne sağ tıklayın, Ekle'yiseçin ve ardından Yeni Öğe'yiseçin. Yeni Öğe Ekle iletişim kutusu görüntülenir, Tüm Şablonları Göster ve ardından Tablo seçin. Tablo adını dosya adı olarak belirtin ve SQL projesinde tablo oluşturmak için ekle'yi seçin.
Tablo, sütun, dizin ve diğer tablo özelliklerini ekleyebileceğiniz şablon tablo tanımıyla SQL Server Management Studio sorgu düzenleyicisinde açılır. İlk düzenlemeleri bitirdiğinizde dosyayı kaydedin.
Yeni Öğe Ekle iletişim kutusu aracılığıyla görünümler, saklı yordamlar ve işlevler gibi daha fazla veritabanı nesnesi eklenebilir. Çözüm Gezgini proje düğümüne sağ tıklayıp Ekle'i seçin, ardından Tüm Şablonları Gösterseçeneği ile istediğiniz nesne türünü belirleyin ve iletişim kutusuna erişin. Projedeki dosyalar, Eklealtındaki Yeni Klasör seçeneği aracılığıyla klasörler halinde düzenlenebilir.
Dosyalar proje dizininde veya iç içe klasörlerde oluşturularak projeye eklenebilir. Dosya uzantısının .sql olması ve nesne türüne veya şemaya ve nesne türüne göre düzenlenmesi önerilir.
Bir tablonun temel şablonu, projede yeni bir tablo nesnesi oluşturmak için başlangıç noktası olarak kullanılabilir:
CREATE TABLE [dbo].[Table1]
(
[Id] INT NOT NULL PRIMARY KEY
);
3. Adım: Projeyi oluşturma
Derleme işlemi, nesneler arasındaki ilişkileri ve söz dizimini proje dosyasında belirtilen hedef platforma göre doğrular. Derleme işleminden alınan yapıt çıkışı, projeyi hedef veritabanına dağıtmak için kullanılabilen ve veritabanı şemasının derlenmiş modelini içeren bir .dacpac dosyasıdır.
Çözüm Gezginibölümünde proje düğümüne sağ tıklayın ve Derlemeseçin.
Derleme işlemini görüntülemek için çıkış penceresi otomatik olarak açılır. Hatalar veya uyarılar varsa, bunlar çıkış penceresinde görüntülenir. Başarılı bir derlemede, derleme yapıtı (.dacpac dosyası) oluşturulur ve konumu derleme çıkışına eklenir (varsayılan değer bin\Debug\projectname.dacpac).
Çözüm Gezginibölümünde proje düğümüne sağ tıklayın ve Derlemeseçin.
Derleme işlemini görüntülemek için çıkış penceresi otomatik olarak açılır. Hatalar veya uyarılar varsa, bunlar çıkış penceresinde görüntülenir. Başarılı bir derlemede, derleme yapıtı (.dacpac dosyası) oluşturulur ve konumu derleme çıkışına eklenir (varsayılan değer bin\Debug\projectname.dacpac).
Visual Studio Code'un Veritabanı Projeleri görünümünde proje düğümüne sağ tıklayın ve Oluştur'a tıklayın.
Derleme işlemini görüntülemek için çıkış penceresi otomatik olarak açılır. Hatalar veya uyarılar varsa, bunlar çıkış penceresinde görüntülenir. Başarılı bir derlemede, derleme yapıtı (.dacpac dosyası) oluşturulur ve konumu derleme çıkışına eklenir (varsayılan değer bin/Debug/projectname.dacpac).
Çözüm Gezginibölümünde proje düğümüne sağ tıklayın ve Derlemeseçin.
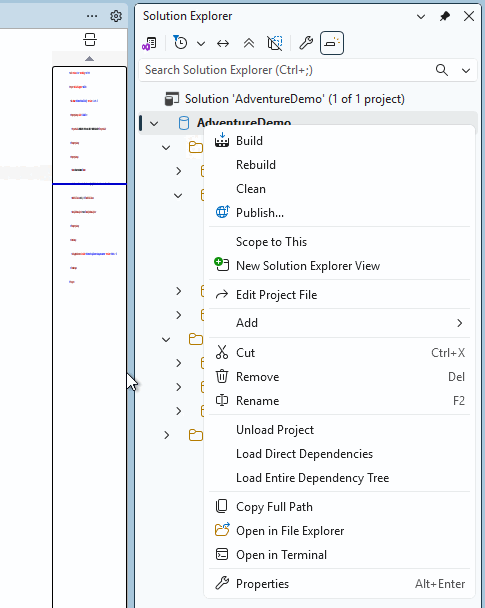
Derleme işlemini görüntülemek için çıkış penceresi otomatik olarak açılır. Hatalar veya uyarılar varsa, bunlar çıkış penceresinde görüntülenir. Başarılı bir derlemede, derleme yapıtı (.dacpac dosyası) oluşturulur ve konumu derleme çıkışına eklenir (varsayılan değer bin\Debug\projectname.dacpac).
SQL veritabanı projeleri, dotnet build komutu kullanılarak komut satırından oluşturulabilir.
dotnet build
# optionally specify the project file
dotnet build MyDatabaseProject.sqlproj
Derleme çıktısı, hataları veya uyarıları ve bunların oluştuğu belirli dosyaları ve satır numaralarını içerir. Başarılı bir derlemede, derleme yapıtı (.dacpac dosyası) oluşturulur ve konumu derleme çıkışına eklenir (varsayılan değer bin/Debug/projectname.dacpac).
4. Adım: Projeyi kaynak denetimine denetleme
Projemizi git deposu olarak başlatacak ve proje dosyalarını kaynak denetimine işleyeceğiz. Bu adım, projenin başkalarıyla paylaşılabilmesini ve sürekli dağıtım işlem hattında kullanılmasını sağlamak için gereklidir.
Visual Studio'daki Git menüsünde Git Deposu Oluştur'u seçin.
Git deposu oluşturma Create a Git repository iletişim kutusunda, Yeni bir uzak deposuna gönder bölümünde GitHub GitHub seçin.
Git deposu oluştur iletişim kutusunun Yeni bir GitHub deposu oluştur bölümünde, oluşturmak istediğiniz deponun adını girin. (GitHub hesabınızda henüz oturum açmadıysanız, bunu bu ekrandan da yapabilirsiniz.)
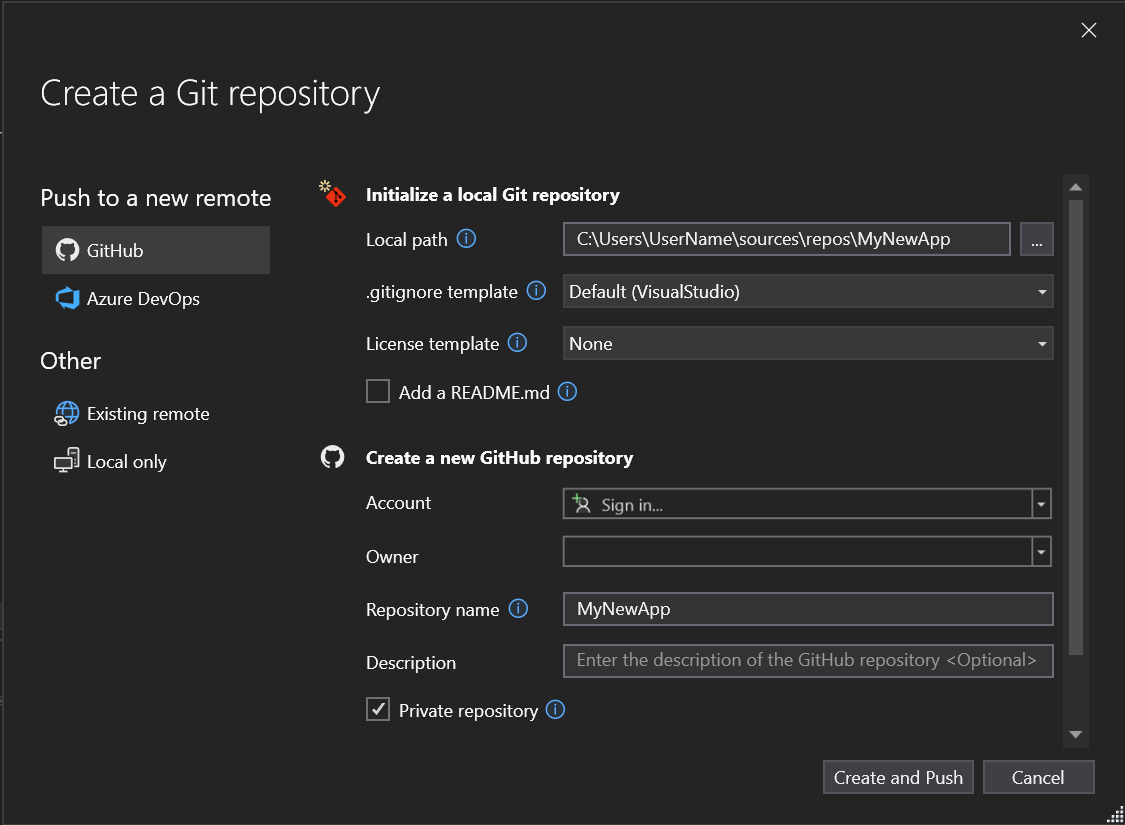
Yerel Git Deposunu başlat'ın altında Git'in yoksaymasını istediğiniz kasıtlı olarak izlenmeyen dosyaları belirtmek için .gitignore şablonu seçeneğini kullanmanız gerekir. .gitignore hakkında daha fazla bilgi edinmek için bkz. dosyaları yok sayma. Lisanslama hakkında daha fazla bilgi edinmek için Bir depo lisanslamabölümüne bakın.
Oturum açıp depo bilgilerinizi girdikten sonra, deponuzu oluşturmak ve uygulamanızı eklemek için Oluştur ve gönder düğmesini seçin.

Visual Studio'daki Git menüsünde Git Deposu Oluştur'u seçin.
Git deposu oluşturma Create a Git repository iletişim kutusunda, Yeni bir uzak deposuna gönder bölümünde GitHub GitHub seçin.
Git deposu oluştur iletişim kutusunun Yeni bir GitHub deposu oluştur bölümünde, oluşturmak istediğiniz deponun adını girin. (GitHub hesabınızda henüz oturum açmadıysanız, bunu bu ekrandan da yapabilirsiniz.)
Yerel Git Deposunu başlat'ın altında Git'in yoksaymasını istediğiniz kasıtlı olarak izlenmeyen dosyaları belirtmek için .gitignore şablonu seçeneğini kullanmanız gerekir. .gitignore hakkında daha fazla bilgi edinmek için bkz. dosyaları yok sayma. Lisanslama hakkında daha fazla bilgi edinmek için Bir depo lisanslamabölümüne bakın.
Oturum açıp depo bilgilerinizi girdikten sonra, deponuzu oluşturmak ve uygulamanızı eklemek için Oluştur ve gönder düğmesini seçin.
Yerel depo başlatabilir ve Visual Studio Code'dan doğrudan GitHub'da yayımlayabilirsiniz. Bu eylem GitHub hesabınızda yeni bir depo oluşturur ve yerel kod değişikliklerinizi tek bir adımda uzak depoya iletir.
Visual Studio Code'da Kaynak Denetimi görünümündeki GitHub'da Yayımla düğmesini kullanın. Ardından, depo için bir ad ve açıklama belirtmeniz ve bunu genel mi yoksa özel mi yapacağınız sorulur.

Alternatif olarak, yerel depoyu başlatabilir ve GitHub'da boş bir depo oluşturduğunuzda sağlanan adımları izleyerek GitHub'a gönderebilirsiniz.
SQL Server Management Studio'daki Git menüsünde Git Deposu Oluştur'u seçin.
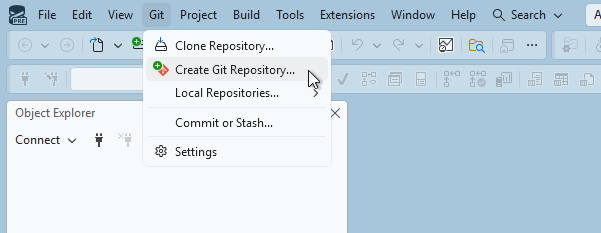
Git deposu oluşturma Create a Git repository iletişim kutusunda, Yeni bir uzak deposuna gönder bölümünde GitHub GitHub seçin.
Git deposu oluştur iletişim kutusunun Yeni bir GitHub deposu oluştur bölümünde, oluşturmak istediğiniz deponun adını girin. (GitHub hesabınızda henüz oturum açmadıysanız, bunu bu ekrandan da yapabilirsiniz.)
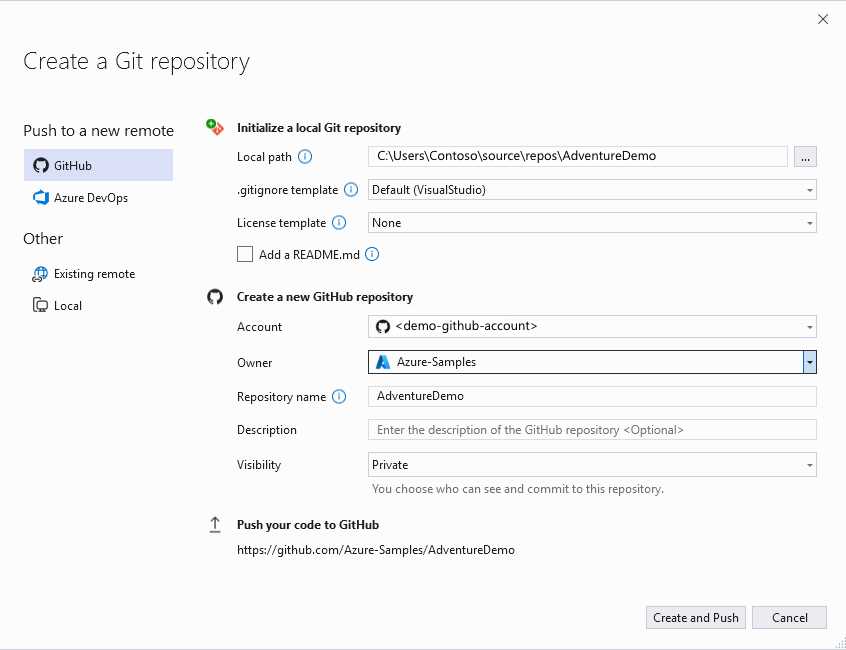
Yerel Git Deposunu başlat'ın altında Git'in yoksaymasını istediğiniz kasıtlı olarak izlenmeyen dosyaları belirtmek için .gitignore şablonu seçeneğini kullanmanız gerekir. .gitignore hakkında daha fazla bilgi edinmek için bkz. dosyaları yok sayma. Lisanslama hakkında daha fazla bilgi edinmek için Bir depo lisanslamabölümüne bakın.
Oturum açıp depo bilgilerinizi girdikten sonra, deponuzu oluşturmak ve uygulamanızı eklemek için Oluştur ve gönder düğmesini seçin.

Proje dizininde yeni bir Git deposu başlatın ve proje dosyalarını kaynak denetimine işleyin.
git init
git add .
git commit -m "Initial commit"
GitHub'da yeni bir depo oluşturun ve yerel depoyu uzak depoya gönderin.
git remote add origin <repository-url>
git push -u origin main
5. Adım: Sürekli dağıtım işlem hattına proje derleme adımı ekleme
SQL projeleri bir .NET kitaplığı tarafından desteklenir ve sonuç olarak projeler komutuyla dotnet build oluşturulur. Bu komut, en temel sürekli tümleştirme ve sürekli dağıtım (CI/CD) işlem hatlarının bile temel bir unsurudur. Derleme adımı, GitHub eylemlerinde oluşturduğumuz sürekli dağıtım işlem hattına eklenebilir.
Deponun kökünde adlı
.github/workflowsyeni bir dizin oluşturun. Bu dizin, sürekli dağıtım işlem hattını tanımlayan iş akışı dosyasını içerir.dizininde
.github/workflowsadlısqlproj-sample.ymlyeni bir dosya oluşturun.Proje adını projenizin adı ve yolu ile eşleşecek şekilde düzenleyip dosyaya aşağıdaki içeriği
sqlproj-sample.ymlekleyin:name: sqlproj-sample on: push: branches: [ "main" ] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - name: Setup .NET uses: actions/setup-dotnet@v4 with: dotnet-version: 8.0.x - name: Build run: dotnet build MyDatabaseProject.sqlprojİş akışı dosyasını depoya işleyin ve değişiklikleri uzak depoya gönderin.
GitHub.com deponun ana sayfasına gidin. Deponuzun adının altında Eylemler'i seçin. Sol kenar çubuğunda yeni oluşturduğunuz iş akışını seçin. İş akışı dosyasını depoya gönderdiğinizde iş akışı çalıştırmaları listesinde iş akışının son çalıştırması görünmelidir.
İlk GitHub eylemleri iş akışınızı oluşturmanın temelleri hakkında daha fazla bilgiyi GitHub Actions hızlı başlangıcında bulabilirsiniz.
6. Adım: Sürekli dağıtım işlem hattına dağıtım adımı ekleme .dacpac
.dacpac dosyasındaki bir veritabanı şemasının derlenmiş modeli, SqlPackage komut satırı aracı veya diğer dağıtım araçları kullanılarak hedef veritabanına dağıtılabilir. Dağıtım işlemi, hedef veritabanını .dacpactanımlanan şemayla eşleşecek şekilde güncelleştirmek için gerekli adımları belirler ve veritabanında zaten var olan nesnelere göre nesneleri oluşturur veya değiştirir. Örneğin, bir .dacpac dosyasını bağlantı dizesini temel alan bir hedef veritabanına dağıtmak için:
sqlpackage /Action:Publish /SourceFile:bin/Debug/MyDatabaseProject.dacpac /TargetConnectionString:{yourconnectionstring}

Dağıtım işlemi bir kez etkili olduğundan sorunlara neden olmadan birden çok kez çalıştırılabilir. Oluşturduğumuz işlem hattı, depomuzun dalında her değişiklik denetlenişinde main SQL projemizi derleyecek ve dağıtacak. Komutu doğrudan dağıtım işlem hattımızda yürütmek SqlPackage yerine, komutu soyutlayan ve günlüğe kaydetme, hata işleme ve görev yapılandırması gibi ek özellikler sağlayan bir dağıtım görevi kullanabiliriz.
GitHub sql-action dağıtım görevi, GitHub eylemlerinde sürekli dağıtım işlem hattına eklenebilir.
Note
Bir otomasyon ortamından dağıtım çalıştırmak için veritabanının ve ortamın, dağıtımın veritabanına ulaşıp kimlik doğrulaması yapabilecek şekilde yapılandırılması gerekir. Azure SQL Veritabanı'nda veya BIR VM'deki SQL Server'da bu, otomasyon ortamının veritabanına bağlanmasına izin vermek ve gerekli kimlik bilgilerini içeren bir bağlantı dizesi sağlamak için bir güvenlik duvarı kuralı ayarlamayı gerektirebilir. Yönergeler GitHub sql-action belgelerinde sağlanır.
sqlproj-sample.ymlDosyasını dizininde.github/workflowsaçın.Derleme adımından sonra dosyaya
sqlproj-sample.ymlaşağıdaki adımı ekleyin:- name: Deploy uses: azure/sql-action@v2 with: connection-string: ${{ secrets.SQL_CONNECTION_STRING }} action: 'publish' path: 'bin/Debug/MyDatabaseProject.dacpac'Değişiklikleri işlemeden önce, hedef veritabanına bağlantı dizesini içeren depoya bir gizli dizi ekleyin. GitHub.com'daki depoda Ayarlar'a ve ardından Gizli Diziler'e gidin. Yeni depo gizliliği seçin ve bağlantı dizesinin değeri olan hedef veritabanına adlandırılmış
SQL_CONNECTION_STRINGbir gizli anahtar ekleyin.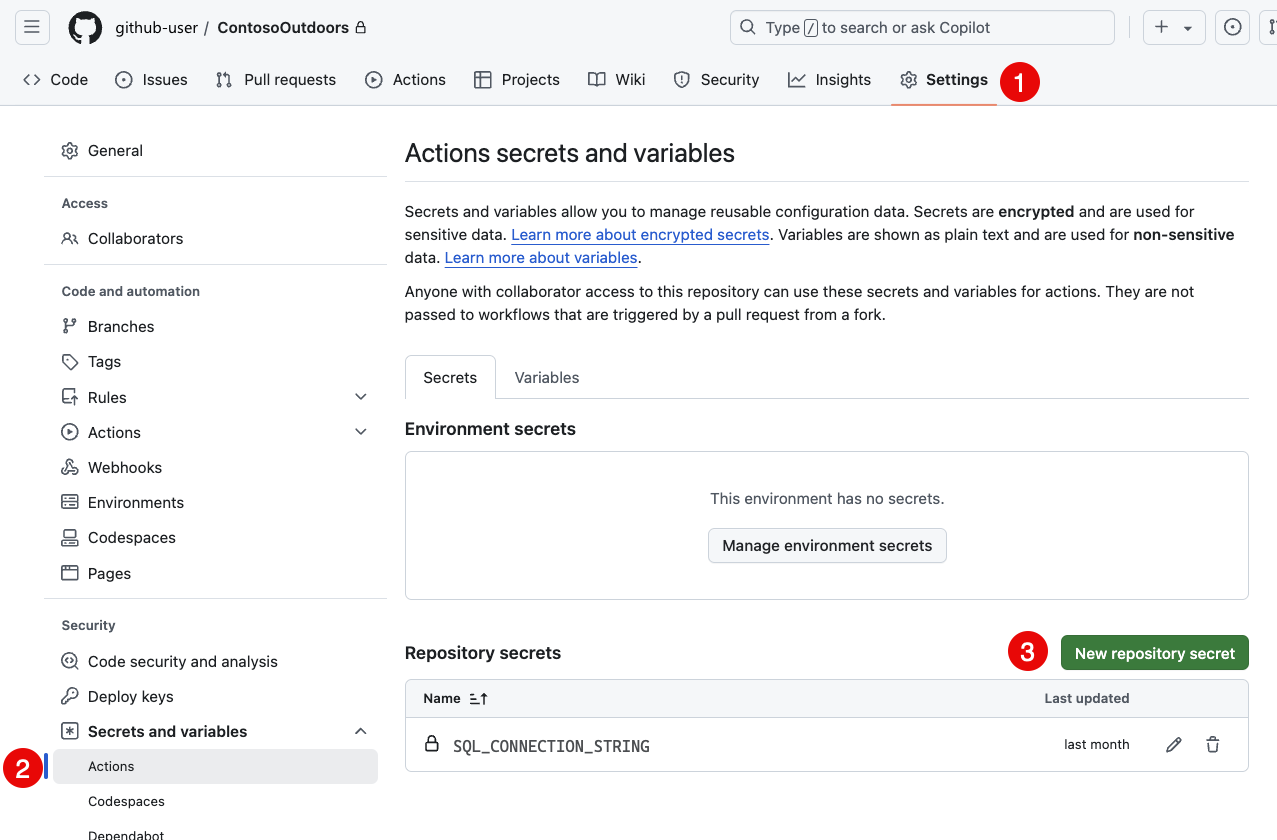
Değişiklikleri
sqlproj-sample.yml'dan depoya aktarın ve değişiklikleri uzak depoya gönderin.GitHub.com iş akışı geçmişine dönün ve iş akışının en son çalıştırmasını seçin. Dağıtım adımı, iş akışının çalıştırıldığı adımlar listesinde görünür olmalıdır ve iş akışı bir başarı kodu ile döner.
Hedef veritabanına bağlanarak ve projedeki nesnelerin veritabanında mevcut olup olmadığını denetleyerek dağıtımı doğrulayın.

GitHub dağıtımları, bir iş akışında ortam ilişkisi oluşturularak ve dağıtım çalıştırılmadan önce onay gerektirerek daha da güvenli hale getirilebilir. Ortam koruması ve gizli dizileri koruma hakkında daha fazla bilgiyi GitHub Actions belgelerinde bulabilirsiniz.