Alıştırma - Bir Nöral Ağ Derleme ve Eğitme
Bu ünitede, metinde yaklaşım analizi yapan bir nöral ağ derlemek ve eğitmek için Keras kullanacaksınız. Bir nöral ağ eğitmek için, onunla birlikte eğitilecek verilere ihtiyacınız vardır. Harici bir veri kümesi indirmek yerine, Keras’ta bulunan IMDB film incelemeleri yaklaşım sınıflandırması veri kümesini kullanacaksınız. IMDB veri kümesi, pozitif (1) veya negatif (0) olarak tek tek puanlanmış 50.000 film incelemesi içermektedir. Veri kümesindeki 25.000 inceleme eğitim için, 25.000 inceleme ise test için ayrılmıştır. Bu incelemelerde ifade edilen yaklaşım, nöral ağınızın kendisine sunulan metni analiz edeceği ve yaklaşım puanlaması yapacağı temeldir.
IMDB veri kümesi, Keras’a dahil edilmiş birkaç yararlı veri kümesinden biridir. Yerleşik veri kümelerinin tam listesi için, bkz. https://keras.io/datasets/.
Not defterinin ilk hücresine aşağıdaki kodu yazın veya yapıştırın ve yürütmek için Çalıştır düğmesine tıklayın (veya Shift+Enter tuşlarına basın) ve altına yeni bir hücre ekleyin:
from keras.datasets import imdb top_words = 10000 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=top_words)Bu kod, Keras'lara dahil olan IMDB veri kümesini yükler ve 50.000 incelemenin tümündeki sözcüklerin, göreli rastlanma sıklığını gösteren tam sayılara eşlendiği bir sözlük oluşturur. Her sözcüğe benzersiz bir tamsayı atanır. En sık rastlanan sözcüğe 1 sayısı, en sık rastlanan ikinci sözcüğe 2 sayısı atanır ve bu şekilde devam eder.
load_dataayrıca film incelemelerini içeren bir çift tanımlama grubu (bu örnekte,x_trainvex_test) ve bu incelemeleri pozitif ve negatif olarak sınıflandıran 1’ler ile 0’ları da (y_trainvey_test) döndürür.Keras’ın arka ucunda TensorFlow kullandığını gösteren "TensorFlow arka ucu kullanma" iletisini gördüğünüzü onaylayın.
IMDB veri kümesini yükleme
Keras’ın Microsoft Cognitive Toolkit’i, diğer adıyla CNTK’yi kendi arka ucu olarak kullanmasını istediyseniz, bunu not defterinin başlangıcına birkaç satır kod ekleyerek yapabilirsiniz. Örneğin, bkz. Azure Notebooks’ta CNTK ve Keras.
Yani,
load_dataişlevi tam olarak ne yükledi?x_trainadlı değişken, her biri bir film incelemesini temsil eden 25.000 listeden oluşan listedir. (x_testayrıca 25.000 incelemeyi temsil eden 25.000 listeden oluşan bir listedir.x_traineğitim için kullanılırkenx_test, test için kullanılacaktır.) Ancak film incelemelerini temsil eden iç listeler sözcük içermez; tamsayılar içerir. Keras belgelerinde şu şekilde açıklanmıştır: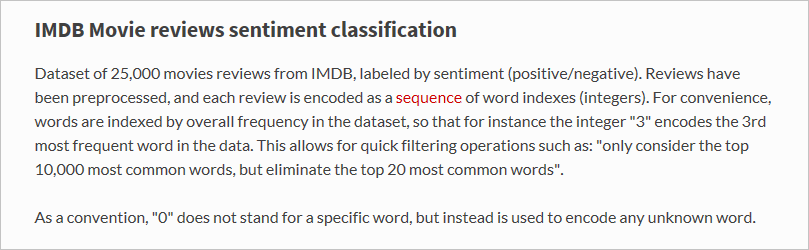
İç listelerin metin yerine sayılar içermesinin nedeni, bir nöral ağı metinle değil, sayılarla eğitmenizdir. Özellikle, tensorlarla eğitmenizdir. Bu durumda her inceleme, incelemedeki sözcükleri tanımlayan tamsayıları içeren 1 boyutlu bir tensordur (1 boyutlu dizi düşünün). Göstermek için, aşağıdaki Python deyimini boş bir hücreye yazın ve eğitim kümesindeki ilk incelemeyi temsil eden tamsayıları görmek için yürütün:
x_train[0]
IMDB eğitim kümesindeki ilk incelemeyi içeren tamsayılar
Listedeki ilk sayı — 1 — bir sözcüğü temsil etmez. İncelemenin başlangıcını işaretler ve veri kümesindeki her inceleme için aynıdır. 0 ve 2 sayıları da ayrılmıştır ve bir incelemedeki tamsayıyı sözlükte karşılık gelen tamsayıya eşlemek için 3'ü diğer sayılardan çıkarırsınız. İkinci sayı — 14 — sözlükte 11 sayısına karşılık gelen sözcüğe başvurur, Üçüncü sayı sözlükte 19 sayısına karşılık gelen sözcüğe başvurur ve bu şekilde devam eder.
Sözlüğün nasıl göründüğünü merak mı ediyorsunuz? Yeni bir not defteri hücresinde aşağıdaki ifadeyi yürütün:
imdb.get_word_index()Sözlük girişlerinin yalnızca bir alt kümesi gösterilir, ancak hepsinde, sözlük 88.000'den fazla sözcük ve bunlara karşılık gelen tamsayılar içerir.
load_dataher çağrıldığında sözlük yeniden oluşturulduğu için, gördüğünüz çıktı büyük olasılıkla ekran görüntüsündeki çıktıyla eşleşmeyecektir.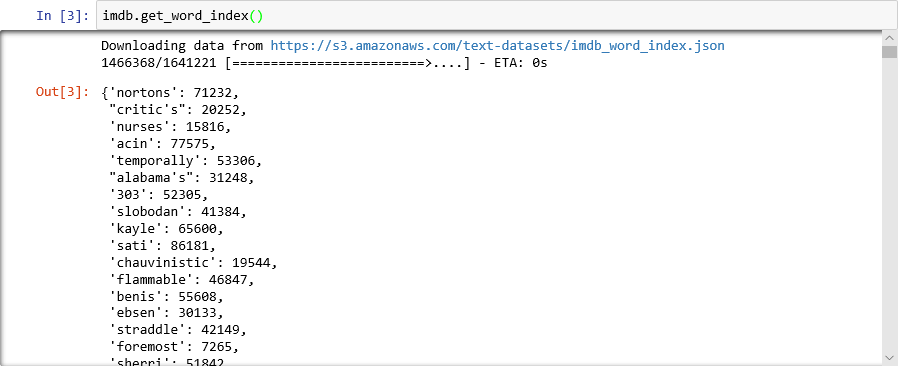
Sözcükleri tamsayılara eşleyen sözlük
Görmüş olduğunuz gibi, veri kümesindeki her inceleme, sözcük yerine bir tamsayı koleksiyonu olarak kodlanmıştır. Bir incelemeyi, onu oluşturan orijinal metni görebilmek için ters kodlamak mümkün mü? Aşağıdaki ifadeleri yeni bir hücreye girin ve ilk incelemeyi
x_train’de metin biçiminde göstermek için yürütün:word_dict = imdb.get_word_index() word_dict = { key:(value + 3) for key, value in word_dict.items() } word_dict[''] = 0 # Padding word_dict['>'] = 1 # Start word_dict['?'] = 2 # Unknown word reverse_word_dict = { value:key for key, value in word_dict.items() } print(' '.join(reverse_word_dict[id] for id in x_train[0]))Çıktıda ">", incelemenin başlangıcını işaretlerken "?" veri kümesindeki en yaygın 10.000 sözcük arasında olmayan sözcükleri işaretler. Bu "bilinmeyen" sözcükler, bir incelemeyi temsil eden tamsayılar listesinde 2’lerle temsil edilir.
load_data’ye geçirdiğiniznum_wordsparametresini hatırlıyor musunuz? Burası onun devreye girdiği yer. Sözlüğün boyutunu azaltmaz ancak incelemeleri kodlamak için kullanılan tamsayıların aralığını kısıtlar.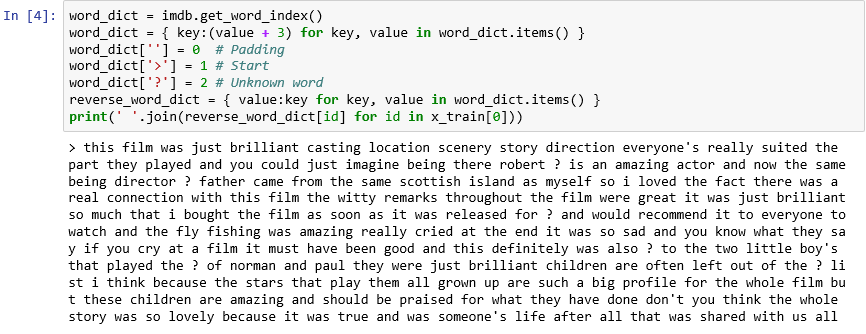
Metin biçimindeki ilk inceleme
İncelemeler, harflerin küçük harfe dönüştürülmesi ve noktalama işaretlerinin kaldırılması bakımından "temizdir". Ancak, metinde yaklaşım analizi yapmak için bir nöral ağı eğitmeye hazır değillerdir. Bir nöral ağı tensor koleksiyonuyla eğittiğinizde, her tensorun aynı uzunlukta olması gerekir. Şu anda,
x_trainvex_test'deki incelemeleri temsil eden listeler değişen uzunluklara sahiptir.Neyse ki Keras, listelerden oluşan listeyi giriş olarak alan ve iç listeleri gerektiğinde keserek veya 0’larla doldurarak belirli bir uzunluğa dönüştüren bir işlev içermektedir. Aşağıdaki kodu not defterine girin ve
x_trainilex_testlistelerinde film incelemelerini temsil eden tüm listeleri 500 tam sayı uzunluğuna zorlamak için çalıştırın:from keras.preprocessing import sequence max_review_length = 500 x_train = sequence.pad_sequences(x_train, maxlen=max_review_length) x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)Eğitim ve test verileri hazır olduğuna göre, modeli derleme zamanı geldi! Yaklaşım analizi gerçekleştiren bir nöral ağ oluşturmak için aşağıdaki kodu not defterinde çalıştırın:
from keras.models import Sequential from keras.layers import Dense from keras.layers.embeddings import Embedding from keras.layers import Flatten embedding_vector_length = 32 model = Sequential() model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length)) model.add(Flatten()) model.add(Dense(16, activation='relu')) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy']) print(model.summary())Çıktının şuna benzediğini onaylayın:
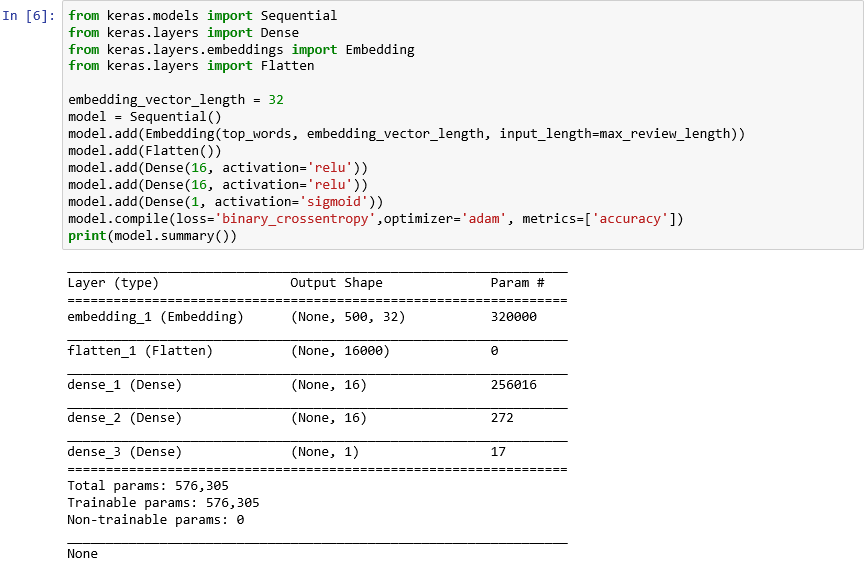
Keras ile bir sinir ağı oluşturma
Bu kod, Keras'la bir nöral ağ oluşturmanızın özüdür. Önce, bir katmandaki çıktının bir sonrakine girdi sağladığı uçtan uca katmanlar yığınından oluşan "sıralı" modeli temsil eden bir
Sequentialnesnesi örneği oluşturur.Sonraki birkaç deyim, modele katmanlar ekler. İlki, sözcükler işleyen nöral ağlar için önemli olan bir ekleme katmanıdır. Ekleme katmanı esas olarak, tamsayı sözcük dizinleri içeren çok boyutlu dizileri, daha az boyutlar içeren kayan noktalı dizilerle eşler. Ayrıca, benzer anlamlara sahip sözcüklerin benzer şekilde değerlendirilmesini de sağlar. Sözcük eklemelerinin tam değerlendirilmesi bu laboratuvarın kapsamı dışındadır ancak Neden Ekleme Katmanlarını Kullanmaya Başlamalısınız bölümünü okuyarak daha fazla bilgi edinebilirsiniz. Daha bilimsel bir açıklamayı tercih ederseniz, Vektör Uzayda Sözcük Temsillerinin Verimli Tahmini bölümüne başvurun. Ekleme katmanının eklenmesinin ardından Flatten ifadesinin çağrılması, çıktıyı bir sonraki katmana giriş için yeniden şekillendirir.
Modele eklenen sonraki üç katman, tam olarak bağlı katmanlar olarak da bilinen yoğun katmandır. Bunlar, nöral ağlarda sık rastlanan geleneksel katmanlardır. Her katman n düğüm veya nöron içerir ve her nöron önceki katmandaki tüm nöronlardan giriş alır, bu nedenle "tamamen bağlı" terimini kullanır. Bir sinir ağının çıkışta yinelemeli olarak tahmin yaparak, sonuçları denetleyerek ve daha iyi sonuçlar elde etmek için bağlantılarda ince ayar yaparak giriş verilerinden "öğrenmesine" izin veren bu katmanlardır. Bu ağdaki ilk iki yoğun katmanın her biri 16 nöron içerir. Bu sayı rasgele seçilmiştir; farklı boyutlarla denemeler yaparak modelin doğruluğunu geliştirebilirsiniz. Ağın nihai amacı 0,0 ile 1,0 arasındaki yaklaşım puanı olarak adlandırılan bir çıktı tahmin etmek olduğu için, son yoğun katman yalnız bir nöron içerir.
Sonuç, aşağıda gösterilen nöral ağdır. Ağ; bir girdi katmanı, bir çıktı katmanı ve iki gizli katman içerir (her biri 16 nöron içeren yoğun katmanlar). Karşılaştırma olması için belirtmek gerekirse, günümüzün daha karmaşık nöral ağlarda 100’de fazla katman bulunmaktadır. Örneğin, fotoğraflardaki nesneleri tanımlama doğruluğu bazen bir insanı aşan, Microsoft Research’e ait ResNet-152. Keras’la ResNet-152 derleyebilirsiniz ancak sıfırdan eğitmek için bir GPU kümesine sahip bilgisayarlara ihtiyacınız olur.
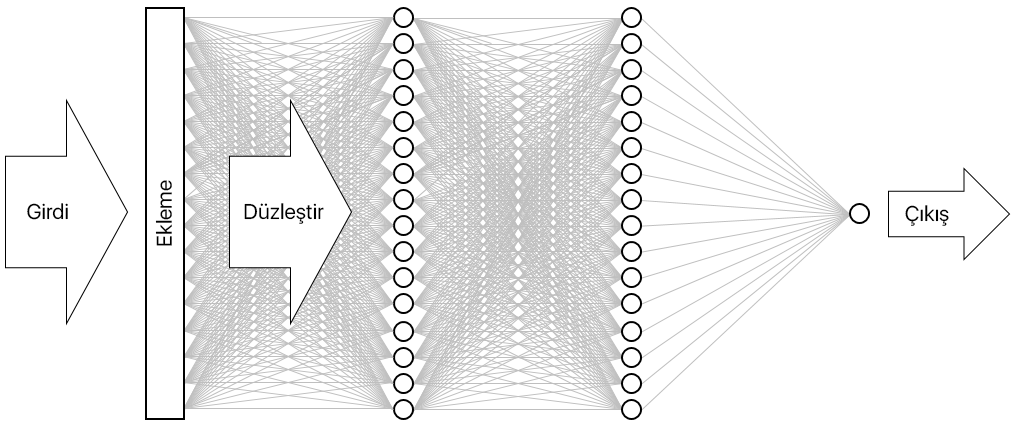
Nöral ağı görselleştirme
Derleme işlevinin çağrılması, modelin her eğitim adımındaki doğruluğunu kararlaştırmak için hangi iyileştiricinin ve hangi ölçümlerin kullanılacağı gibi önemli parametreleri belirterek modeli "derler". Siz modelin
fitişlevini çağırana kadar eğitim başlamaz, bu yüzdencompileçağrısı genellikle hızlı yürütülür.Şimdi, nöral ağı eğitmek için sığdır işlevini çağırın:
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5, batch_size=128)Eğitim yaklaşık 6 dakika veya dönem başına 1 dakikadan biraz fazla sürmelidir.
epochs=5, Keras’a model boyunca 5 ileri ve geri geçiş yapmasını söylüyor. Model, her geçişte eğitim verilerinden öğrenir ve test verilerini kullanarak ne kadar iyi öğrendiğini ölçer ("doğrular"). Ardından ayarlamalar yapıp, sonraki geçiş veya dönem için geri döner. Bu, her dönemin eğitim doğruluğunu (acc) ve doğruluk hassasiyetini (val_acc) gösterenfitişlevinin çıktısında yansıtılır.batch_size=128, Keras’a ağı eğitmesi için tek seferde 128 eğitim örneği kullanmasını söyler. Daha büyük toplu iş boyutları (eğitim verilerinin tümünü kullanmak için her dönemde daha az geçiş gereklidir) eğitim süresini hızlandırabilir ancak daha küçük toplu iş boyutları bazen doğruluğu artırabilir. Bu laboratuvarı tamamladıktan sonra geri dönüp, modelin doğruluğu üzerinde nasıl bir etkisi olduğunu görmek için, modeli 32 toplu iş boyutunda yeniden eğitmek isteyebilirsiniz. Bu, eğitim süresini yaklaşık iki katına çıkarır.
Modeli eğitme
Bu model, yalnızca birkaç dönemle iyi öğrendiği için olağan dışıdır. Eğitim doğruluğu hızla %100'e yakın bir değere yakınlaşırken, doğrulama doğruluğu bir veya iki dönem için yukarı çıkar ve ardından düz hale gelir. Bir modeli genellikle bu doğrulukların kararlı hale getirilmesi için gerekenden daha uzun süre eğitmek istemezsiniz. Risk, modelin test verilerine karşı iyi gerçekleşmesiyle ancak gerçek dünya verilerinde o kadar iyi olmamasıyla sonuçlanan fazla uygunluktur. Bir modelin fazla uygun olduğunun bir göstergesi de eğitim doğruluğu ve doğrulama hassasiyeti arasında artan bir tutarsızlıktır. Fazla uygunlukla ilgili harika bir giriş için bkz . Machine Learning'de Fazla Uygunluk: Nedir ve Nasıl Önlenir?
Eğitim sürerken, eğitimdeki değişiklikleri ve doğruluk hassasiyetini görselleştirmek için yeni bir not defterinde aşağıdaki deyimleri yürütün:
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set() acc = hist.history['acc'] val = hist.history['val_acc'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, '-', label='Training accuracy') plt.plot(epochs, val, ':', label='Validation accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend(loc='upper left') plt.plot()historynesnesinden gelen doğruluk verileri, modelinfitişlevi tarafından döndürülür. Gördüğünüz grafiğe dayanarak, eğitim dönemlerinin sayısının artırılmasını mı, azaltılmasını mı yoksa aynı bırakılmasını mı tavsiye edersiniz?Fazla uygunluğu kontrol etmenin bir diğer yolu da, eğitim devam ederken eğitim kaybını doğrulama kaybıyla karşılaştırmaktır. Bunun gibi en iyi duruma getirme sorunları, bir kayıp işlevini en aza indirmeyi amaçlar. Buradan daha fazla bilgi edinebilirsiniz. Belirli bir dönem için, doğrulama kaybından çok daha fazla olan eğitim kaybı, fazla uygunluk kanıtı olabilir. Önceki adımda, eğitim ve doğruluk hassasiyetinin taslağını çıkarmak için
historynesnesininhistoryözelliğininaccveval_accözelliklerini kullandınız. Aynı özellik, sırasıyla eğitim ve doğrulama kaybını temsil edenlossveval_lossadlı değerleri de içerir. Aşağıdaki gibi bir grafik oluşturmak için bu değerlerin taslağını çıkarmak isteseydiniz, üzerindeki kodu nasıl değiştirirdiniz?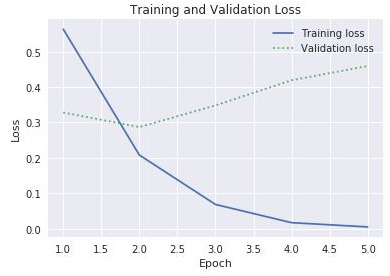
Eğitim ve doğrulama kaybı
Eğitim ve doğrulama kaybı arasındaki farkın üçüncü dönemde artmaya başladığı göz önüne alındığında, birisi dönem sayısını 10 ya da 20'ye çıkarmanızı önerdiğinde ne söylersiniz?
Modelin,
x_test(inceleme) vey_test’teki (hangi incelemelerin pozitif, hangi incelemelerin negatif olduğunu gösteren 0’lar ve 1’ler veya "etiketler") test verilerine dayanarak, metinde ifade edilen yaklaşımı ne kadar doğru ölçebildiğini belirlemek için modelinevaluateyöntemini çağırarak bitirin:scores = model.evaluate(x_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1] * 100))Modelinizi hesaplanan doğruluğu nedir?
Büyük olasılıkla %85 ila %90 doğruluk elde ettiniz. Modeli sıfırdan oluşturduğunuz (önceden eğitilmiş bir nöral ağ kullanmanın aksine) ve eğitim süresinin GPU yokken bile kısa olduğu dikkate alındığında bu kabul edilebilir bir değerdir. Alternatif nöral ağ mimarileriyle, özellikle Uzun Kısa Süreli Hafıza (LSTM) katmanları kullanan yinelenen nöral ağlarla (RNN’ler) %95 veya daha yüksek doğruluklar elde etmek mümkündür. Keras böyle ağ derlemeyi kolaylaştırır ancak eğitim süresi üstel olarak artabilir. Derlediğiniz model, doğruluk ve eğitim süresi arasında makul bir denge kurar. Ancak, Keras ile RNN’ler derleme hakkında daha fazla bilgi edinmek isterseniz, bkz. LSTM’yi ve Yaklaşım Analizi İçin Keras’ta Hızlı Uygulamasını Anlamak.