Alıştırma - Modern veri ambarı mimarisi bileşenlerini tanımlama
Veri ambarı için yalnızca iş verilerini depolamaktan daha fazlası vardır. Veriler, yıldan yıla üstel bir hızda büyür. Yalnızca veri hacmi değil, aynı zamanda yapılandırılmış, yarı yapılandırılmış ve daha büyük bir ölçüde yapılandırılmamış olan ve yönetilmesi gereken çeşitli veriler. Verilerin hızı ve çeşitliliği, verileri makine öğrenmesi, raporlama ve diğer amaçlar için alma, dönüştürme ve hazırlama konusunda veri mühendisliğinde zorluklara yol açar.
Modern veri ambarı bu zorlukları gidermeye hizmet eder. İyi bir veri ambarı, tüm verileriniz için merkezi bir konum işlevi görür, zamanla büyüdükçe verilerle ölçeklendirilir ve veri mühendisleriniz, veri analistleriniz, veri bilimcileriniz ve geliştiricileriniz için tanıdık araçlar ve ekosistemler sağlar.
Şimdi bu öğelerin her birine ayrıntılı olarak bakalım.
Tüm verileriniz için tek bir yer
Modern bir veri ambarı ile Synapse Analytics kullanırken tüm veriler için tek bir hub'ız vardır.
Synapse Analytics, düzenleme işlem hatları aracılığıyla birden çok veri kaynağından veri almanızı sağlar.
Tümleştirme hub'ını seçin.
Tümleştirme hub'ı içindeki tümleştirme işlem hatlarını yönetin. Azure Data Factory 'yi (ADF) biliyorsanız, kendinizi bu hub'da evinizde gibi hissedeceksiniz. İşlem hattı oluşturma deneyimi, Azure Synapse Analytics'te yerleşik olarak bulunan ve veri taşıma ve dönüştürme işlem hatları için Azure Data Factory'yi kullanma gereksinimini ortadan kaldıran başka bir güçlü tümleştirme sağlayan ADF ile aynıdır.
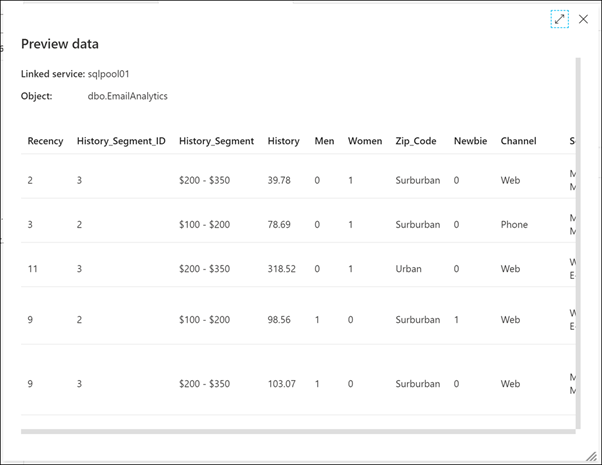
İşlem Hatları'yı genişletin ve E-posta Analizini Özelleştir (1)'i seçin. Tuvalde veri kopyalama etkinliğini seçin (2), Kaynak sekmesini (3) ve ardından Verileri önizle (4)'i seçin.
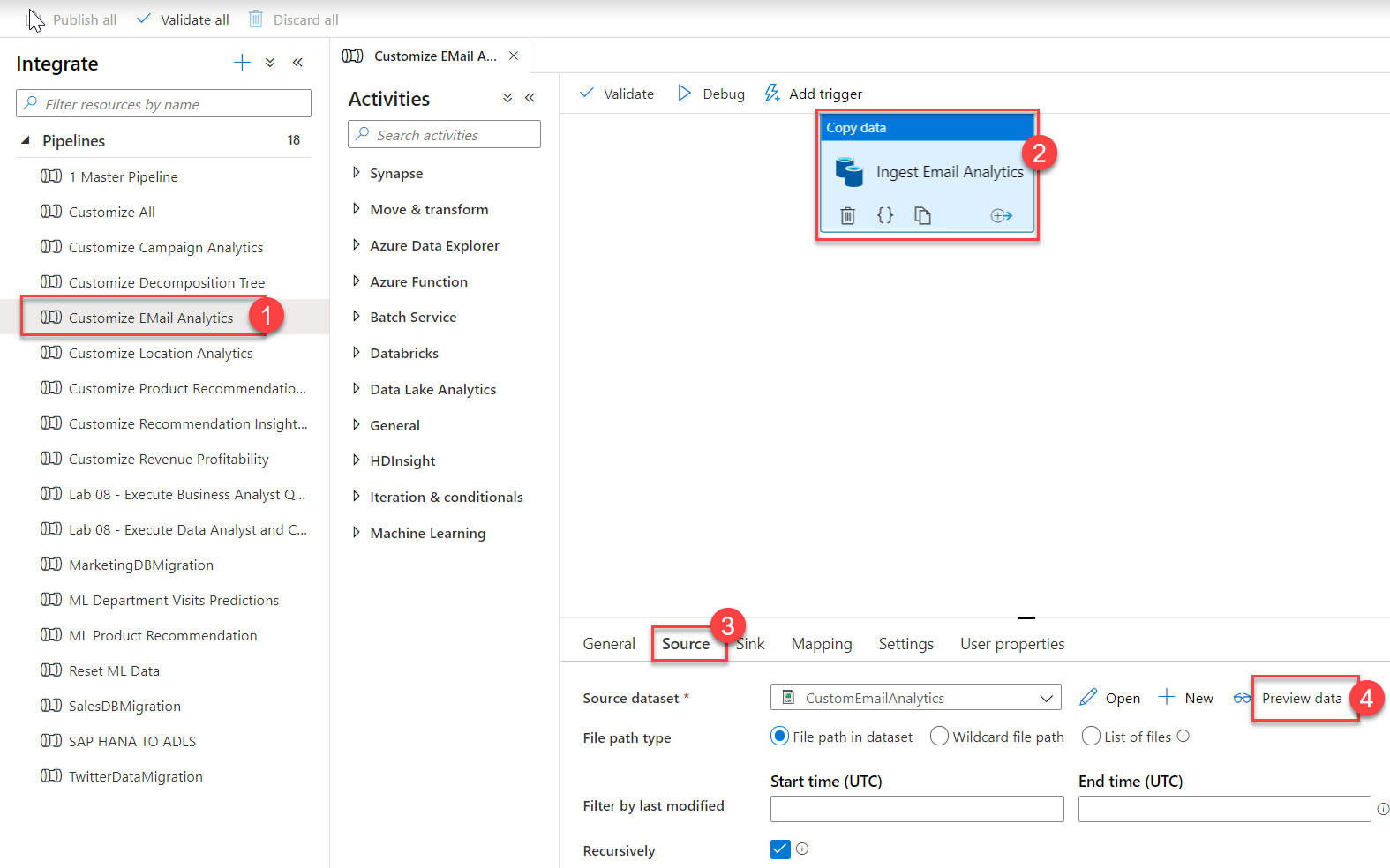
Burada işlem hattının alınan kaynak CSV verilerini görüyoruz.
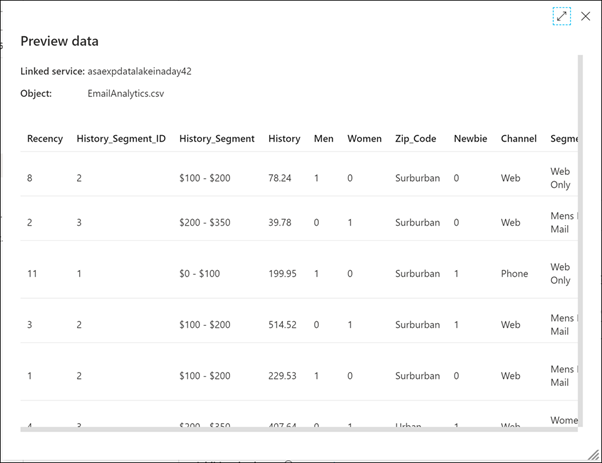
Önizlemeyi kapatın, ardından CustomEmailAnalytics kaynak veri kümesinin yanındaki Aç'ı seçin.
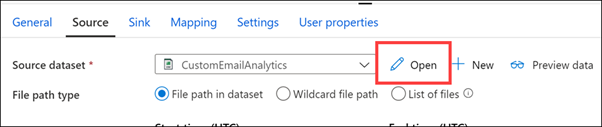
Veri kümesinin bağlantısıyla ilişkili Bağlı hizmeti ve CSV dosya yolunu (1) gösterin. İşlem hattına dönmek için veri kümesini kapatın (2).
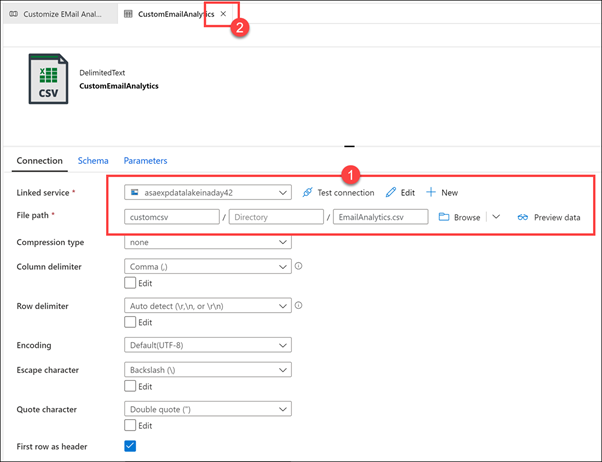
İşlem hattında Havuz sekmesini (1) seçin. Toplu ekleme kopyalama yöntemi seçilir ve CSV kaynağından (2) verileri kopyalamadan önce çalışan EmailAnalytics tablosunu kesen bir kopyalama öncesi betiği vardır. EmailAnalytics havuz veri kümesinin (3) yanındaki Aç'ı seçin.
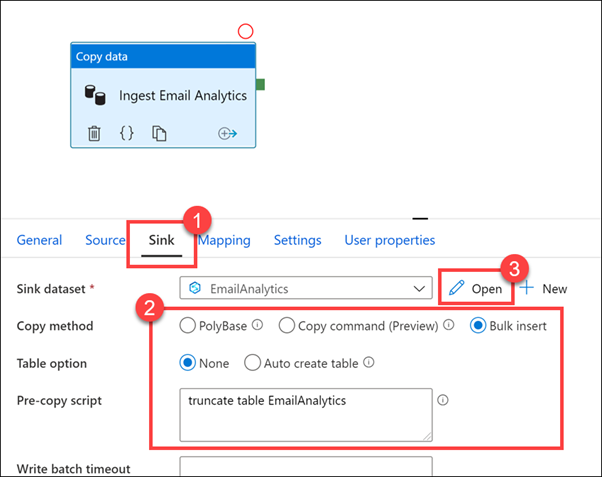
Bağlı hizmet, Azure Synapse Analytics SQL havuzu ve Tablo ise EmailAnalytics (1)'dir. İşlem hattındaki Veri kopyalama etkinliği, CSV veri kaynağındaki verileri SQL havuzuna kopyalamak için bu veri kümesindeki bağlantı ayrıntılarını kullanır. Verileri önizle (2)'yi seçin.
Tabloda zaten veri olduğunu görebiliriz; bu da geçmişte işlem hattını başarıyla çalıştırdığımız anlamına gelir.
EmailAnalytics veri kümesini kapatın.

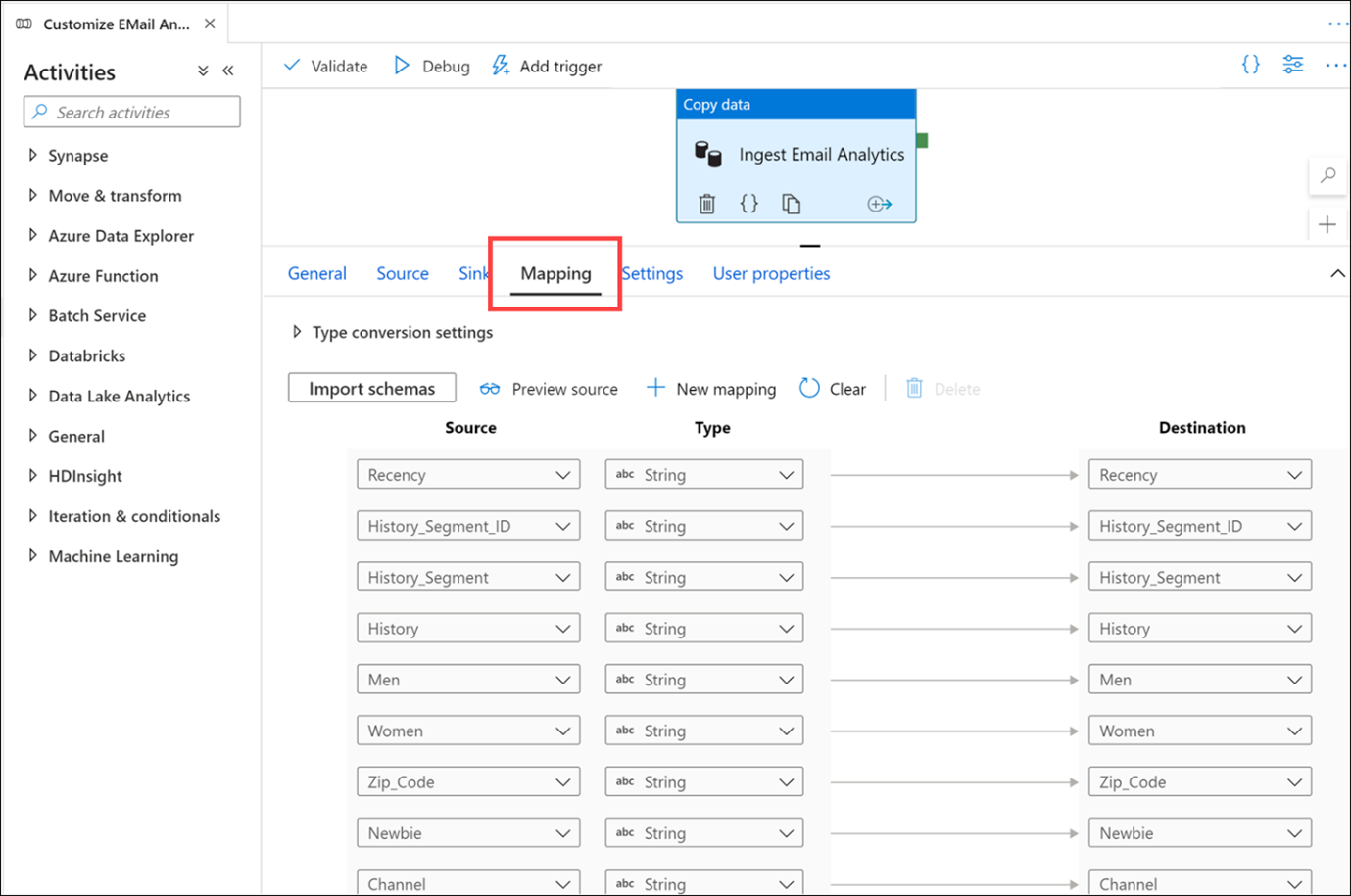
Eşleme sekmesini seçin. Burası, kaynak ve havuz veri kümeleri arasındaki eşlemeyi yapılandırdığınız yerdir. Şemaları içeri aktar düğmesi, CSV veya JSON dosyaları gibi yapılandırılmamış veya yarı yapılandırılmış veri kaynaklarını temel alan veri kümelerinizin şemasını çıkarsamaya çalışır. Ayrıca Synapse Analytics SQL havuzları gibi yapılandırılmış veri kaynaklarından şemayı okur. Ayrıca + Yeni eşleme'ye tıklayarak veya veri türlerini değiştirerek şema eşlemenizi el ile oluşturma seçeneğiniz de vardır.
MarketingDBMigration (1) işlem hattını seçin. Dikkatinizi işlem hattının tuvaline (2) yönlendirin.
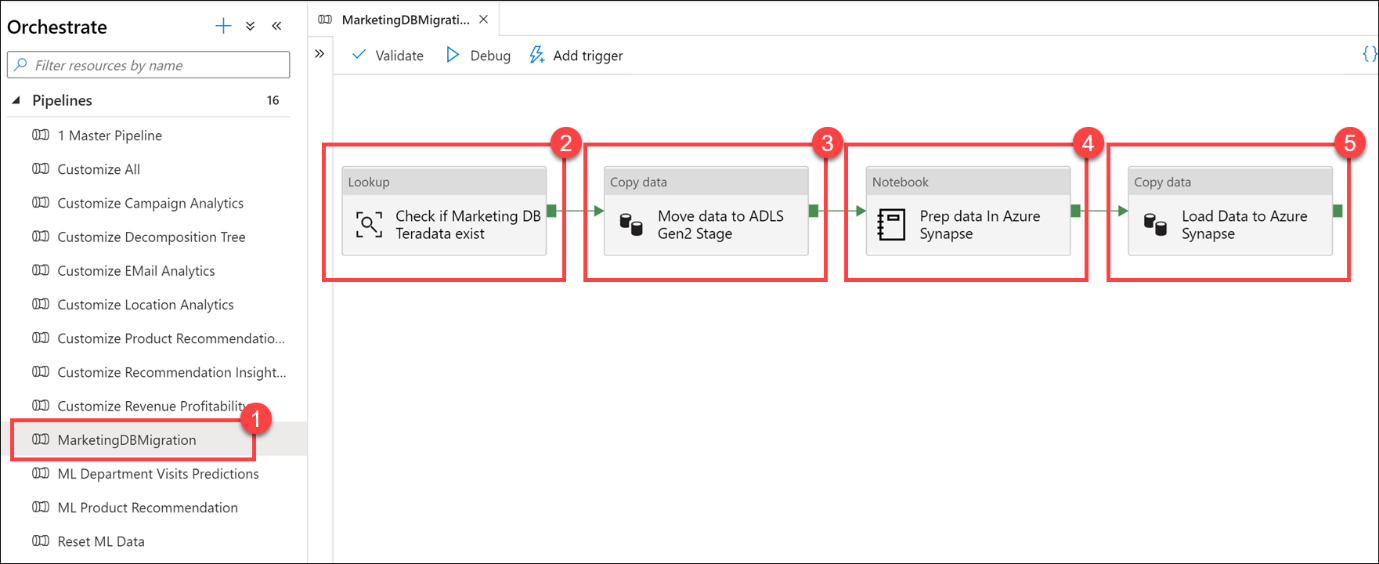
Bu işlem hattı, Teradata veritabanından veri kopyalamaktan sorumludur. İlk etkinlik, kaynak verilerin mevcut olduğundan emin olmak için yapılan bir aramadır (2 ). Veriler varsa, kaynak verileri veri gölüne (ADLS 2. Nesil birincil veri kaynağı) taşımak için veri kopyalama etkinliğine (3) akar. Sonraki adım, veri mühendisliği görevlerini gerçekleştirmek için Synapse Notebook içindeki Apache Spark'ı kullanan bir Not Defteri etkinliğidir (4). Son adım, hazırlanan verileri yükleyen ve bir Azure Synapse SQL havuz tablosuna depolayan başka bir kopyalama veri etkinliğidir (5 ).
Bu iş akışı, veri taşıma düzenlemesi yapılırken yaygındır. Synapse Analytics işlem hatları, veri taşıma ve dönüştürme adımlarını tanımlamayı kolaylaştırır ve bu adımları modern veri ambarınız içinde koruyabileceğiniz ve izleyebileceğiniz yinelenebilir bir işleme dönüştürür.
SalesDBMigration (1) işlem hattını seçin. Dikkatinizi işlem hattının tuvaline (2) yönlendirin.
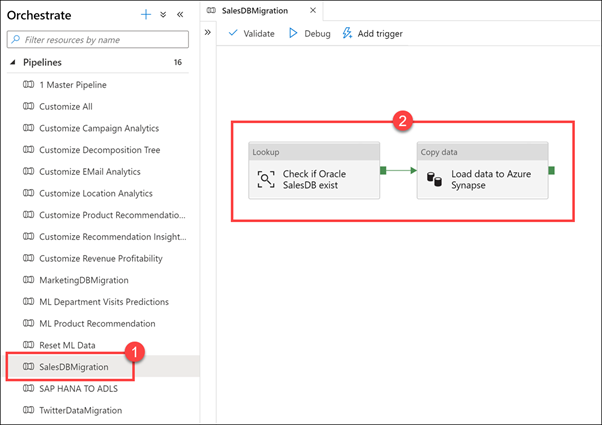
Aşağıda, dış veri kaynaklarını ambarımızda birleştirmemize yardımcı olan bir veri taşıma düzenleme işlem hattı örneği verilmiştir. Bu durumda, bir Oracle satış veritabanındaki verileri Azure Synapse SQL havuz tablosuna yükleriz.
SAP HANA TO ADLS işlem hattını seçin. Bu işlem hattı, finansal SAP HANA veri kaynağındaki verileri SQL havuzuna kopyalar.
+ Yeni bir işlem hattı oluşturmak için Orchestrate dikey penceresinin üst kısmındaki düğmeyi ve ardından İşlem Hattı'nı seçin.
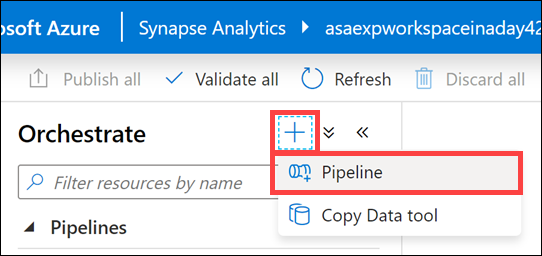
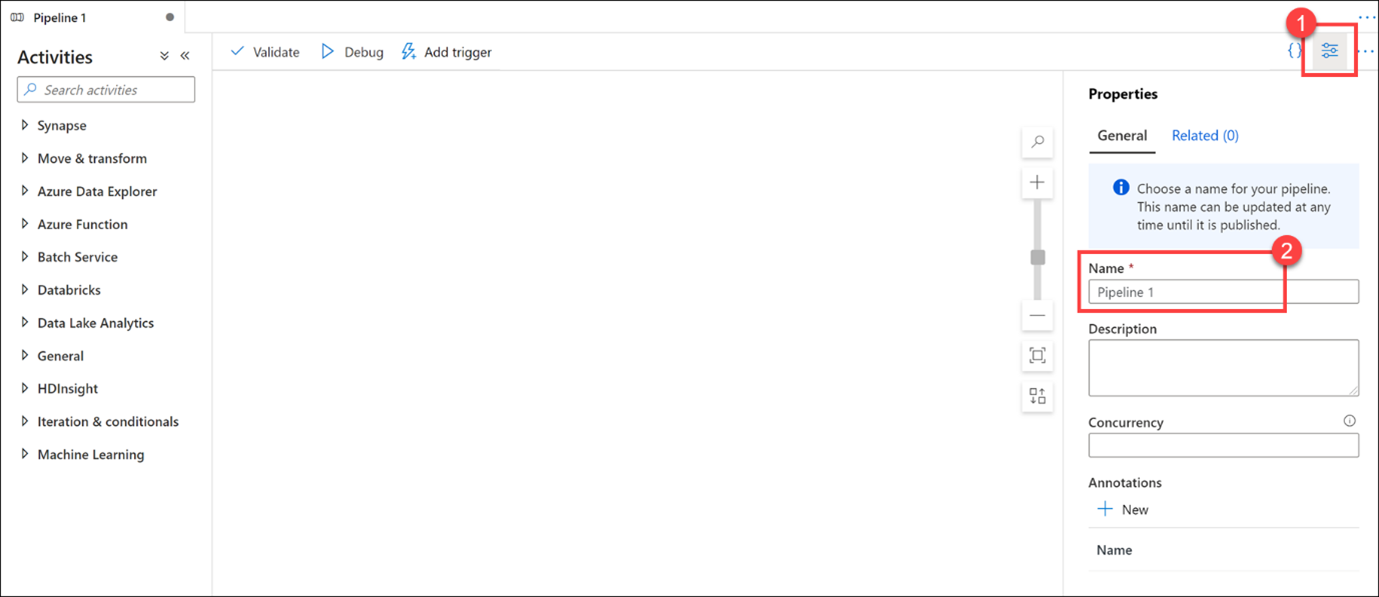
Yeni işlem hattı açıldığında Özellikler dikey penceresi (1) görüntülenir ve işlem hattını (2) adlandırmanıza olanak sağlar.
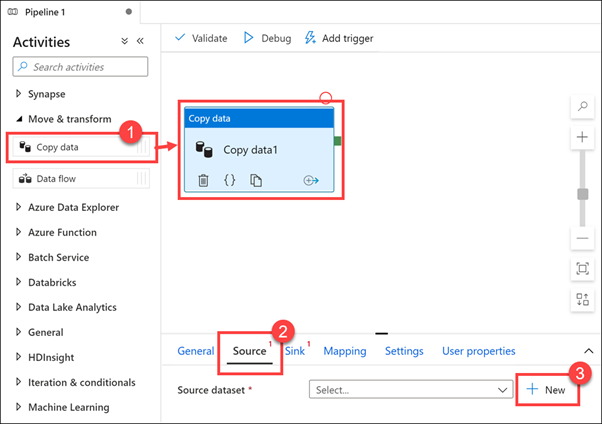
Taşı ve dönüştür etkinlik grubunu genişletin, ardından Veri kopyalama etkinliğini tasarım tuvaline (1) sürükleyin. Veri kopyalama etkinliği seçili durumdayken Kaynak sekmesini (2) ve ardından kaynak veri kümesinin yanındaki + Yeni (3) öğesini seçin.
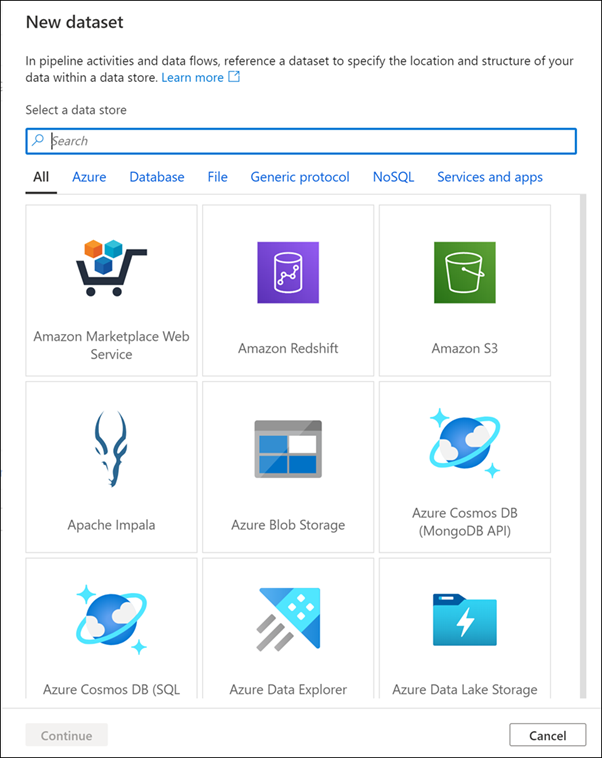
Çok sayıda veri bağlantısının kullanımınızda olduğunu göstermek için veri kümesi kaynakları listesinde ilerleyin ve ardından İptal'e tıklayın.
Sınırsız veri ölçeği
Yönet hub'ını seçin.
SQL havuzları (1) öğesini seçin. SQLPool01'in üzerine gelin ve Ölçek düğmesini (2) seçin.
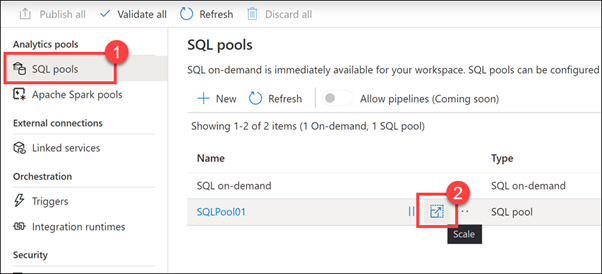
Performans düzeyi kaydırıcısını sağa ve sola sürükleyin.
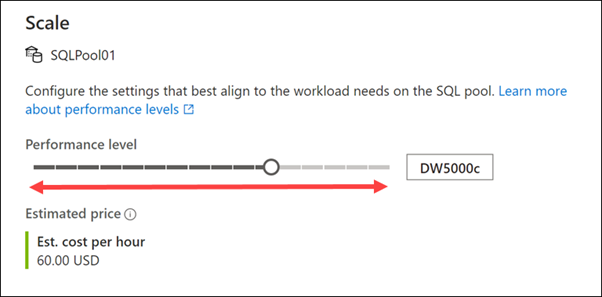
SQL havuzunuza atanan Veri Ambarı Birimi (DWU) sayısını ayarlayarak işlem ölçeğini genişletebilir veya geri alabilirsiniz. Bu, siz daha fazla birim ekledikçe yükleme ve sorgu performansını doğrusal olarak ayarlar.
Ölçeklendirme işlemi gerçekleştirmek için SQL havuzu önce tüm gelen sorguları öldürür ve ardından tutarlı bir durum sağlamak için işlemleri geri alır. Ölçeklendirme ancak işlemlerin geri alınması tamamlandıktan sonra gerçekleşir.
Bu kaydırıcıyı kullanarak ISTEDIĞINIZ zaman SQL işlem ölçeğini genişletebilirsiniz. Ayrıca, program aracılığıyla Veri Ambarı Birimlerini ayarlayabilir ve havuzunuzu bir zamanlamaya veya diğer faktörlere göre otomatik olarak ölçeklendirdiğiniz senaryoları etkinleştirebilirsiniz.
Ölçek iletişim kutusunu iptal edin ve ardından Merkezi yönet sol menüsünde Apache Spark havuzları (1) seçeneğini belirleyin. SparkPool01'in üzerine gelin ve otomatik ölçeklendirme ayarları düğmesini (2) seçin.
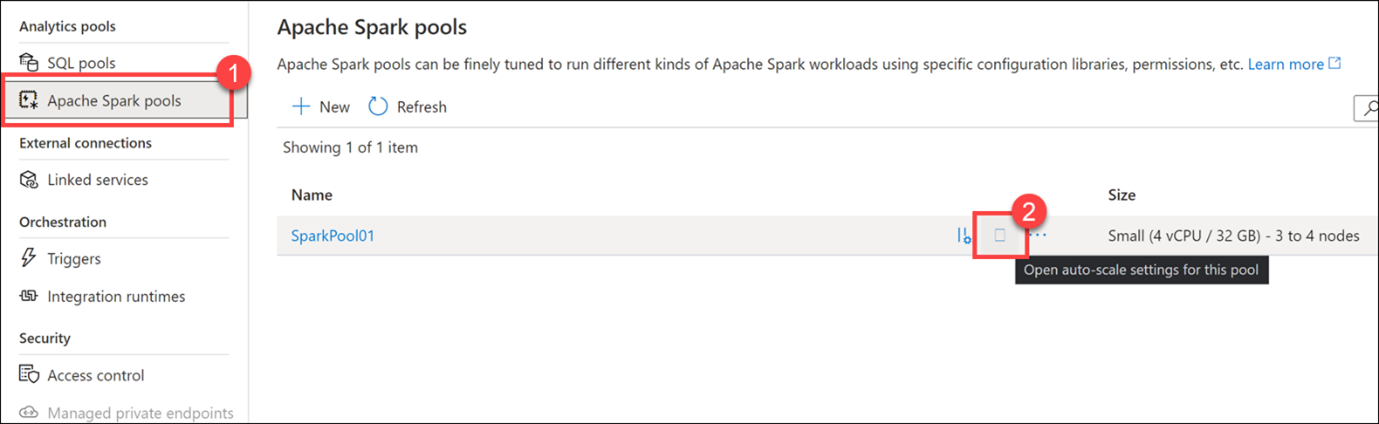
Düğüm sayısı kaydırıcısını sağa ve sola sürükleyin.
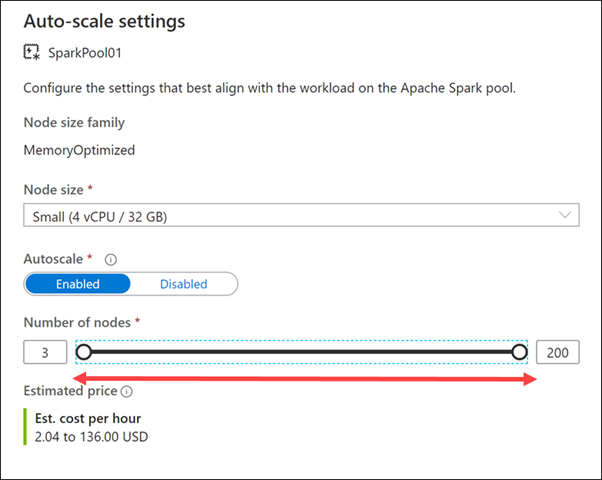
Otomatik ölçeklendirme ayarını devre dışı bırakarak Apache Spark havuzunu sabit bir boyuta sahip olacak şekilde yapılandırabilirsiniz. Burada otomatik ölçeklendirmeyi etkinleştirdik ve uygulanan ölçek miktarını denetlemek için en az ve en fazla düğüm sayısını ayarladık. Otomatik ölçeklendirmeyi etkinleştirdiğinizde Synapse Analytics yükün kaynak gereksinimlerini izler ve düğüm sayısını yukarı veya aşağı ölçeklendirir. Bunu, bekleyen CPU, bekleyen bellek, boş CPU, boş bellek ve düğüm başına kullanılan bellek ölçümlerini sürekli izleyerek yapar. Bu ölçümleri her 30 saniyede bir denetler ve değerlere göre ölçeklendirme kararları alır.
Ölçeklendirme işleminin tamamlanması 1-5 dakika sürebilir.
Otomatik ölçeklendirme iletişim kutusunu iptal edin ve ardından Merkezi yönet sol menüsünde Bağlı hizmetler (1) öğesini seçin. WorkspaceDefault Depolama ADLS 2. Nesil depolama hesabını (2) not edin.
Yeni bir Azure Synapse Analytics çalışma alanı sağladığınızda, varsayılan depolama Azure Data Lake Storage 2. Nesil hesabını tanımlarsınız. Data Lake Storage 2. Nesil, Azure'Depolama Azure'da kurumsal veri gölleri oluşturmanın temelini oluşturur. Başlangıçtan petabaytlarca bilgiye hizmet vermeye kadar yüzlerce gigabit aktarım hızı sağlarken tasarlanan Data Lake Storage 2. Nesil çok büyük miktarda veriyi kolayca yönetmenizi sağlar.
Hiyerarşik ad alanı, verimli erişim ve daha ayrıntılı güvenlik için dosyaları dosya düzeyine kadar bir dizin hiyerarşisinde düzenler.
ADLS 2. Nesil, data lake'iniz için neredeyse sınırsız ölçek sağlar. Gerektiğinde daha fazla ölçek ve esneklik için ek ADLS 2. Nesil hesapları ekleyebilirsiniz.
Tanıdık araçlar ve ekosistem
Geliştirme hub'ını seçin.
SQL betiklerini genişletin ve Synapse ile 1 SQL Sorgusu (1)'i seçin. SQLPool01 'e (2) bağlı olduğunuzdan emin olun. Betiğin ilk satırını vurgulayın (3) ve yürütür. Sales tablosundaki kayıt sayısının 3.443.486 (4) olduğunu gözlemleyin.
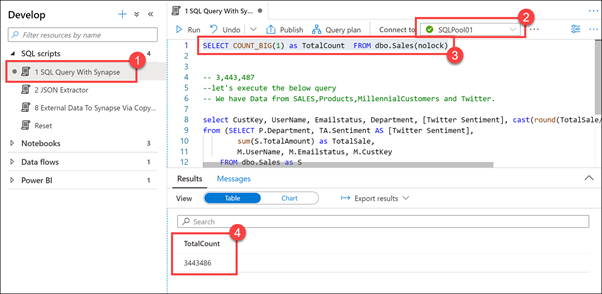
Bu SQL betiğinde ilk satırı yürütürsek, içinde neredeyse 3,5 milyon satır bulunduğunu görebiliriz.
Betiğin geri kalanını vurgulayın (satır 8 - 18) ve yürütür.
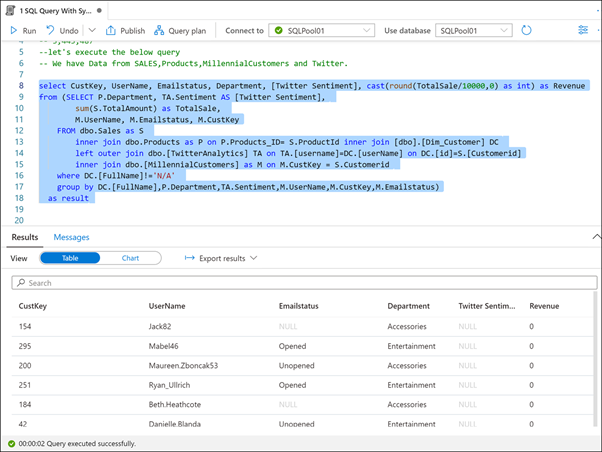
Synapse Analytics gibi modern bir veri ambarı kullanmanın avantajlarından biri, tüm verilerinizi tek bir yerde birleştirebilmenizdir. Az önce yürüttüğümiz betik, bir satış veritabanından, ürün kataloğundan, demografik verilerden ayıklanan bin yıllık müşterilerden ve twitter'dan verileri birleştirir.
2 JSON Ayıklayıcı (1) betiğini seçin ve SQLPool01'e bağlı olduğunuzdan emin olun. İlk select deyimini (2) (3. satır) vurgulayın. TwitterData sütununda (3) depolanan verilerin JSON biçiminde olduğuna dikkat edin.
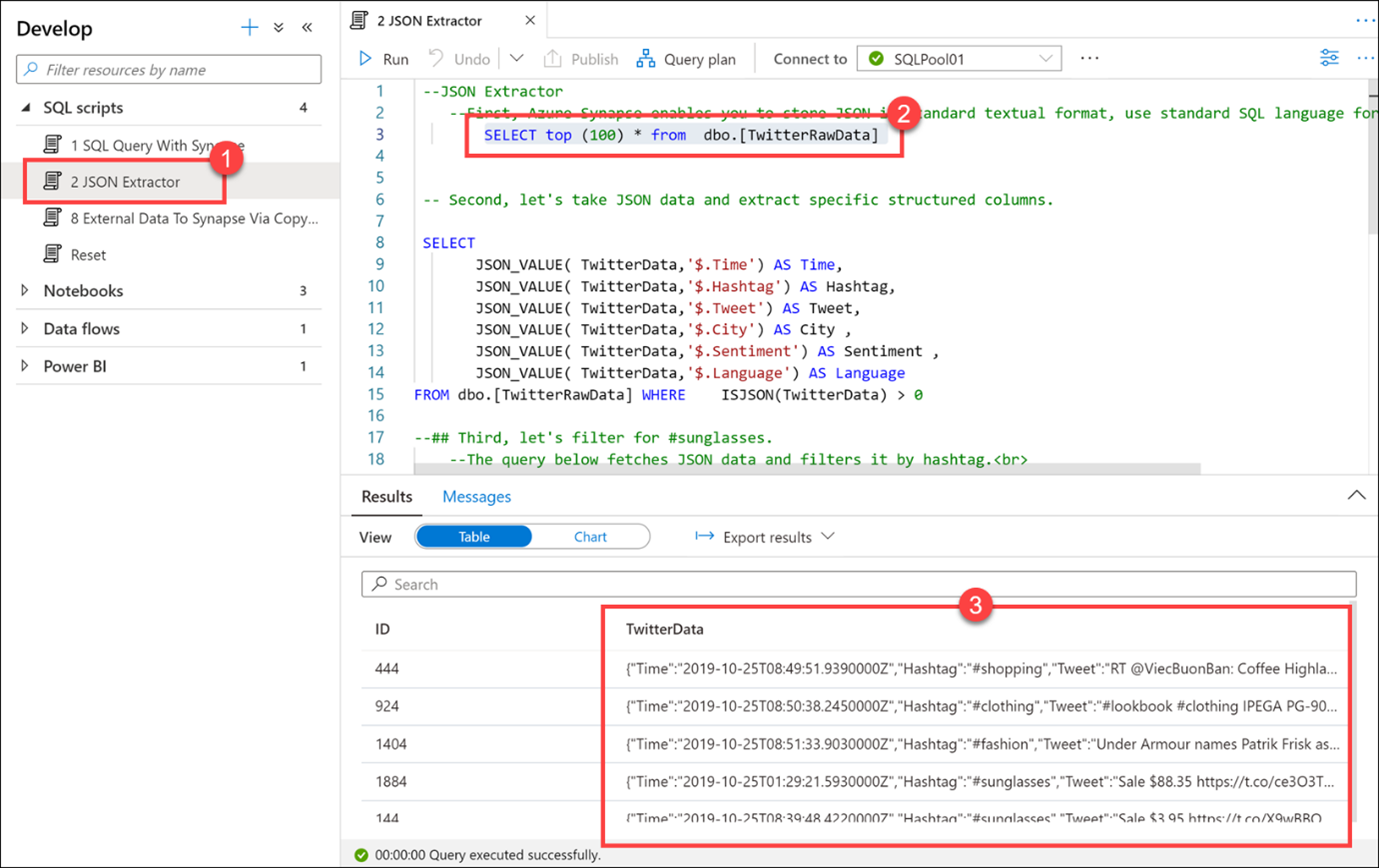
Azure Synapse, JSON'ı standart metin biçiminde depolamanıza olanak tanır. JSON verilerini sorgulamak için standart SQL dilini kullanın.
Sonraki SQL deyimini (satır 8 - 15) vurgulayın ve yürütür.
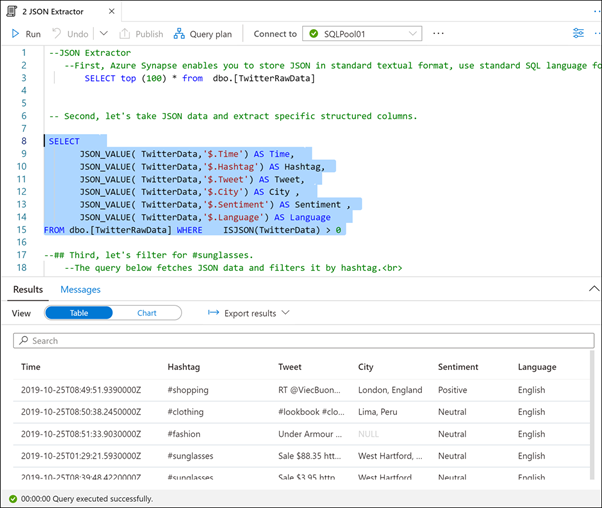
JSON verilerini ayıklamak ve belirli yapılandırılmış sütunlara ayıklamak için JSON_VALUE ve ISJSON gibi JSON işlevlerini kullanabiliriz.
Sonraki SQL deyimini (satır 21 - 29) vurgulayın ve yürütür.
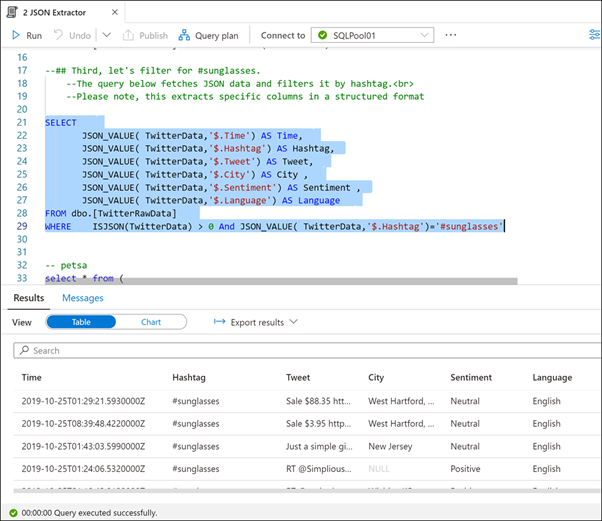
#sunglassess hashtag'ini filtrelemek istiyoruz. Bu sorgu JSON verilerini alıp yapılandırılmış sütunlara ayıklar, ardından türetilmiş Hashtag sütununa filtre ekler.
Son betik de aynı şeyi yapar, ancak yalnızca bir alt sorgu biçimi kullanılır.
8 Dış Veriden Synapse'e Kopyala (1) betiğini seçin. YÜRÜTMEYİN. Ne yaptığını açıklamak için aşağıdaki açıklamayı kullanarak betik dosyasını kaydırın.
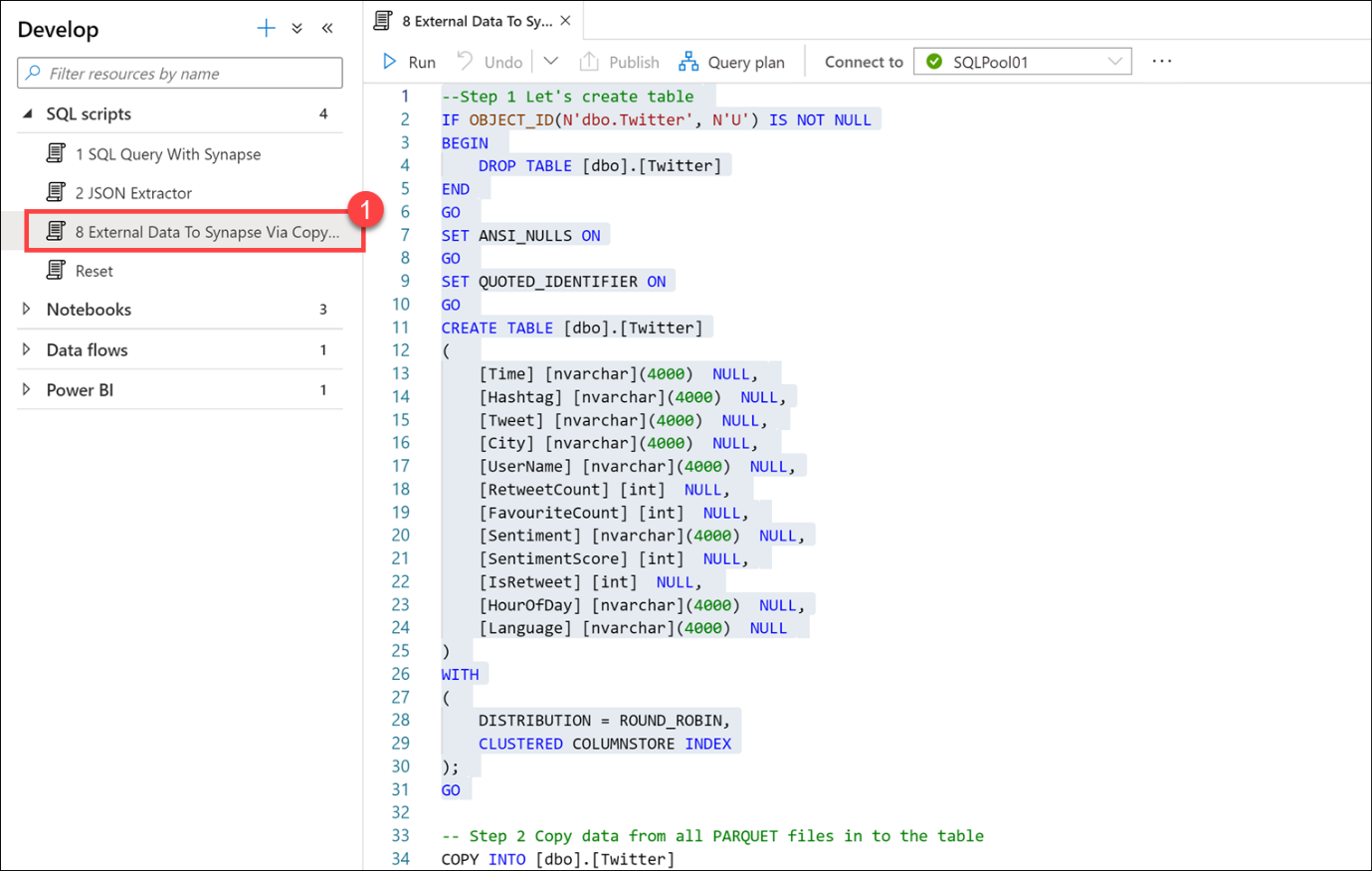
Bu betikte, Parquet dosyalarında depolanan Twitter verilerini depolamak için bir tablo oluşturacağız. Parquet dosyalarında depolanan tüm verileri yeni tabloya hızlı ve verimli bir şekilde yüklemek için COPY komutunu kullanırız.
Son olarak, veri yükünü doğrulamak için ilk 10 satırı seçiyoruz.
COPY komutu ve PolyBase, çeşitli biçimlerdeki verileri burada gördüğümüz gibi T-SQL betikleri aracılığıyla veya düzenleme işlem hatlarından SQL havuzuna aktarmak için kullanılabilir.
Veri hub'ını seçin.
Bağlı sekmesini (1) seçin, Azure Data Lake Storage 2. Nesil grubunu genişletin, Birincil depolama hesabını genişletin ve ardından twitterdata kapsayıcısını (2) seçin. Dbo'ya sağ tıklayın. TwitterAnalytics.parquet dosyası (3) ve ardından Yeni not defteri (4) öğesini seçin.
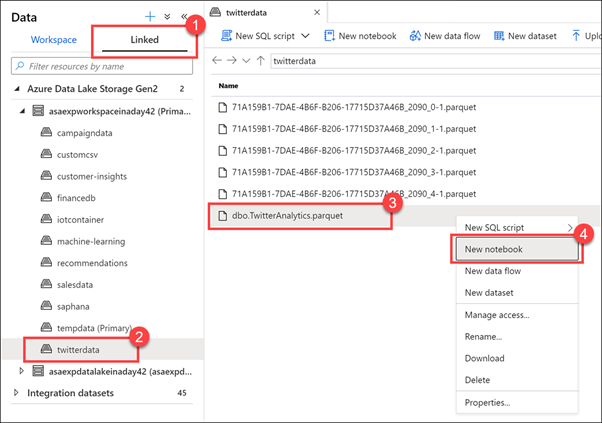
Synapse Studio, ekli depolama hesaplarında depolanan dosyalarla çalışmak için yeni SQL betiği, not defteri, veri akışı veya yeni veri kümesi oluşturma gibi çeşitli seçenekler sağlar.
Synapse Notebooks, apache Spark'ın gücünden yararlanarak verileri keşfetmenize ve analiz etmenizi, veri mühendisliği görevlerini yürütmenizi ve veri bilimi gerçekleştirmenizi sağlar. Birincil data lake storage hesabı gibi bağlı hizmetlerle kimlik doğrulaması ve yetkilendirme tamamen tümleşiktir ve hesap kimlik bilgileriyle uğraşmadan dosyalarla çalışmaya hemen başlamanızı sağlar.
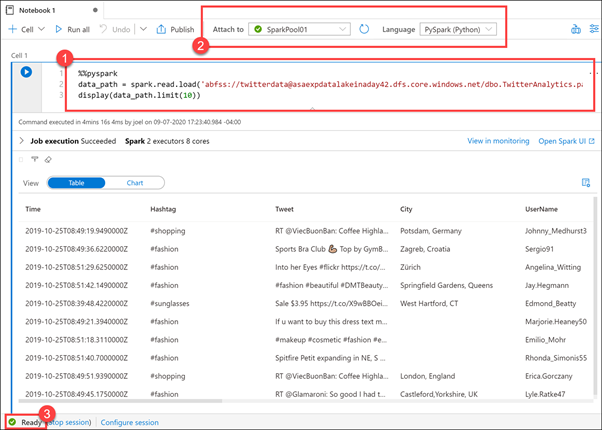
Burada, Veri hub'ında sağ tıkladığımız Parquet dosyasıyla bir Spark DataFrame (1) yükleyen yeni bir not defteri görüyoruz. Yalnızca birkaç basit adımda dosya içeriğini keşfetmeye hemen başlayabiliriz. Not defterinin üst kısmında SparkPool01'e, Spark havuzumuza ve not defteri dilinin Python (2) olarak ayarlandığını görüyoruz.
Spark havuzu hazır olmadığı sürece not defterini yürütmeyin (3). Boştaysa havuzun başlatılması 5 dakika kadar sürebilir. Alternatif olarak, not defterini yürütebilir ve daha sonra sonuçları görüntülemek için bu not defterine geri dönebilirsiniz.