Azure Synapse Analytics ile verileri hazırlama ve dönüştürme
Eşleme Veri Akışı görevini kullanarak Azure Synapse işlem hatları kodu ücretsiz olarak yerel olarak veri dönüştürmeleri gerçekleştirebilirsiniz. Eşleme Veri Akışı, kodlama gerektirmeden tamamen görsel bir deneyim sağlar. Veri akışlarınız, ölçeği genişletilen veri işleme için kendi yürütme kümenizde çalışır. Veri akışı etkinlikleri mevcut Data Factory zamanlama, denetim, akış ve izleme özellikleri aracılığıyla kullanıma hazır hale getirilebilir.
Veri akışları oluştururken, küçük bir etkileşimli Spark kümesini açan hata ayıklama modunu etkinleştirebilirsiniz. Yazma modülünün üst kısmındaki kaydırıcıyı kaydırarak hata ayıklama modunu açın. Hata ayıklama kümelerinin ısınması birkaç dakika sürer, ancak dönüştürme mantığınızın çıktısını etkileşimli olarak önizlemek için kullanılabilir.

Eşleme Veri Akışı eklendiğinde ve Spark kümesi çalıştığında, bu dönüştürmeyi gerçekleştirmenize ve verileri çalıştırmanıza ve önizlemenize olanak tanır. Azure Data Factory, veri akışı işlerinizin tüm kod çevirisini, yol iyileştirmesini ve yürütülmesini işlediğinden kodlama gerekmez.
Eşleme Veri Akışı kaynak verileri ekleme
Eşleme Veri Akışı tuvalini açın. Veri Akışı tuvalinde Kaynak Ekle düğmesine tıklayın. Kaynak veri kümesi açılan listesinde veri kaynağınızı seçin; bu örnekte ADLS 2. Nesil veri kümesi kullanılır
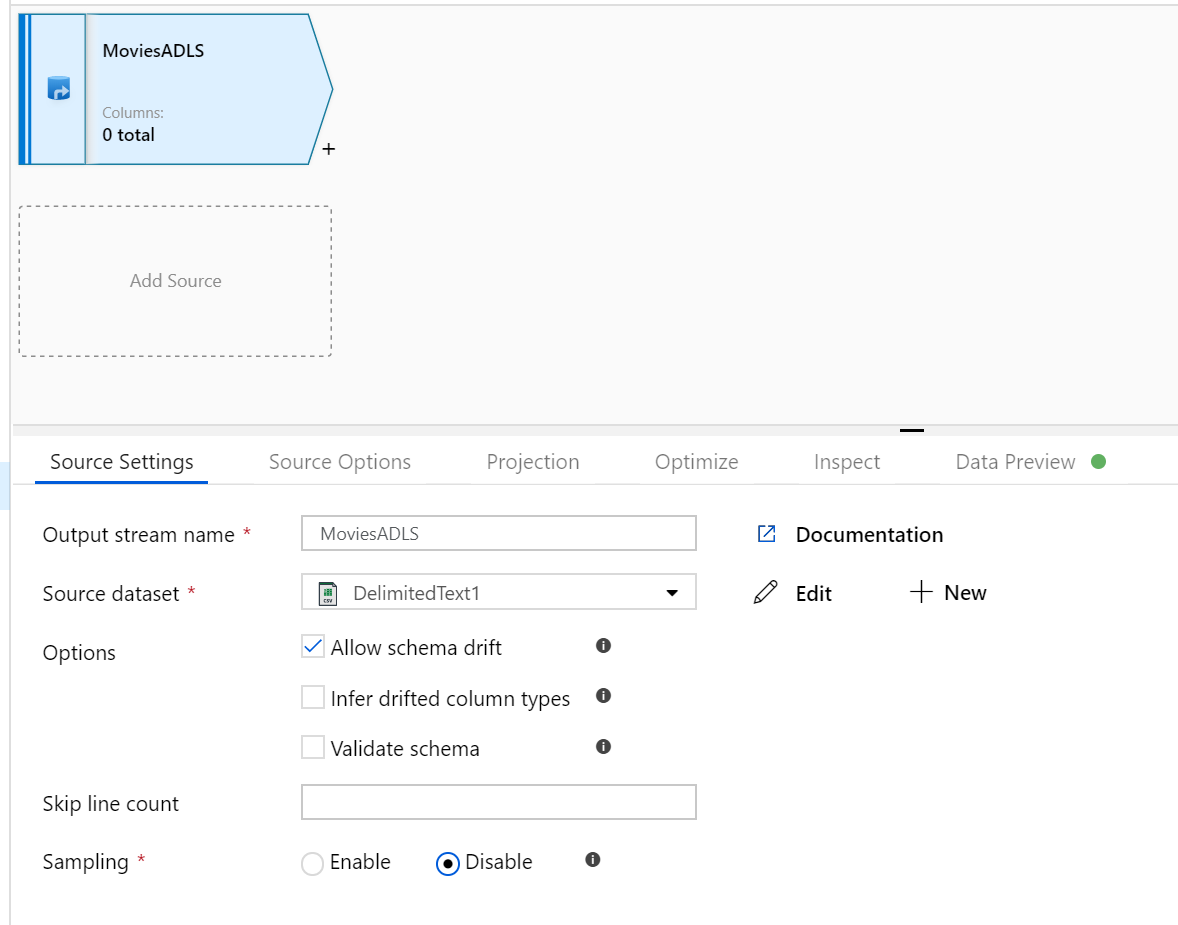
Dikkate alınacak birkaç nokta vardır:
- Veri kümeniz başka dosyaların olduğu bir klasörü işaret ediyorsa ve yalnızca bir dosya kullanmak istiyorsanız, yalnızca belirli bir dosyanın okundığından emin olmak için başka bir veri kümesi oluşturmanız veya parametreleştirmeyi kullanmanız gerekebilir
- Şemanızı ADLS'nize aktarmadıysanız ancak verilerinizi zaten aldıysanız veri kümesinin 'Şema' sekmesine gidin ve veri akışınızın şema projeksiyonunu bilmesi için 'Şemayı içeri aktar'a tıklayın.
Eşleme Veri Akışı ayıklama, yükleme, dönüştürme (ELT) yaklaşımını izler ve tümü Azure'da bulunan hazırlama veri kümeleriyle çalışır. Şu anda aşağıdaki veri kümeleri bir kaynak dönüşümünde kullanılabilir:
- Azure Blob Depolama (JSON, Avro, Metin, Parquet)
- Azure Data Lake Storage 1. Nesil (JSON, Avro, Metin, Parquet)
- Azure Data Lake Storage 2. Nesil (JSON, Avro, Metin, Parquet)
- Azure Synapse Analytics
- Azure SQL Veritabanı
- Azure Cosmos DB
Azure Data Factory'nin 80'den fazla yerel bağlayıcıya erişimi vardır. Veri akışınıza diğer kaynaklardan veri eklemek için Kopyalama Etkinliği'ni kullanarak bu verileri desteklenen hazırlama alanlarından birine yükleyin.
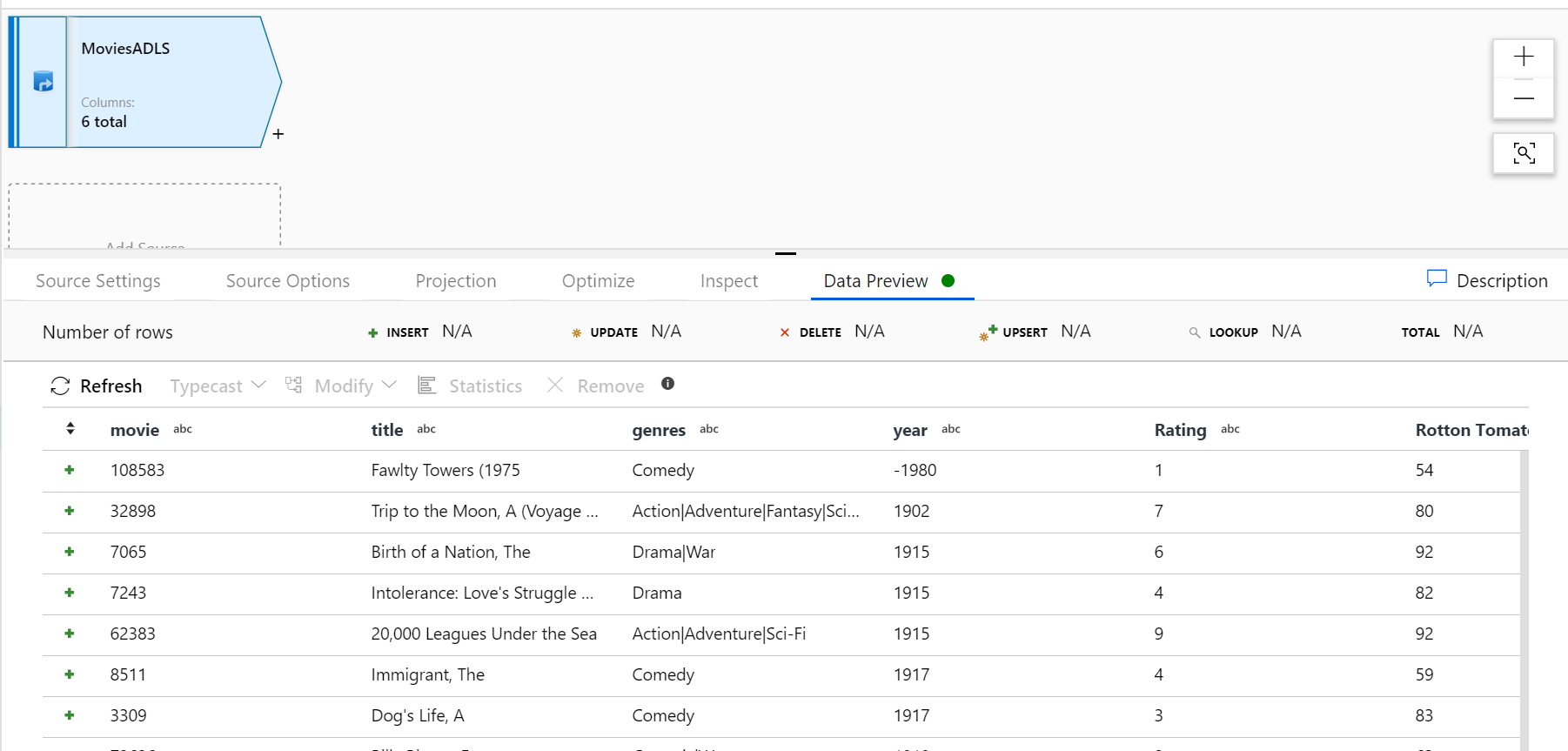
Hata ayıklama kümeniz ısındıktan sonra Veri Önizleme sekmesi aracılığıyla verilerinizin doğru yüklendiğini doğrulayın. Yenile düğmesine tıkladığınızda Eşleme Veri Akışı, verilerinizin her dönüştürme sırasında nasıl göründüğüne ilişkin bir anlık görüntü gösterir.
Eşleme Veri Akışı dönüştürmeleri kullanma
Verileri Azure Data Lake Store 2. Nesil'e taşıdığınıza göre, verilerinizi bir spark kümesi aracılığıyla büyük ölçekte dönüştürecek ve ardından bir Veri Ambarı'na yükleyecek bir Eşleme Veri Akışı oluşturmaya hazırsınız.
Bunun ana görevleri şunlardır:
Ortamı hazırlama
Veri Kaynağı Ekleme
Eşleme Veri Akışı dönüştürmeyi kullanma
Veri Havuzuna Yazma
Görev 1: Ortamı hazırlama
hata ayıklamaVeri Akışı açma Yazma modülünün en üstünde bulunan Veri Akışı Hata Ayıklama kaydırıcısını açın.
Dekont
Veri Akışı kümelerinin ısınması 5-7 dakika sürer.
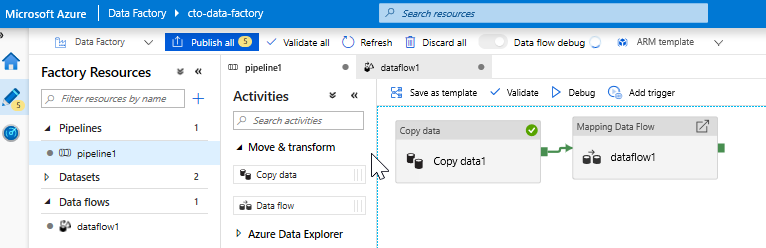
Veri Akışı etkinliği ekleyin. Etkinlikler bölmesinde Taşı ve Dönüştür akordeonunu açın ve Veri Akışı etkinliğini işlem hattı tuvaline sürükleyin. Açılan dikey pencerede Yeni Veri Akışı oluştur'a tıklayın, Eşleme Veri Akışı'ni seçin ve ardından Tamam'a tıklayın. İşlem hattı1 sekmesine tıklayın ve Kopyalama etkinliği yeşil kutuyu Veri Akışı Etkinliği'ne sürükleyerek başarı koşulu oluşturun. Tuvallerde aşağıdakileri görürsünüz:
Görev 2: Veri Kaynağı Ekleme
BIR ADLS kaynağı ekleyin. Tuvaldeki Eşleme Veri Akışı nesnesine çift tıklayın. Veri Akışı tuvalinde Kaynak Ekle düğmesine tıklayın. Kaynak veri kümesi açılan listesinde, Kopyalama etkinliği'nizde kullanılan ADLSG2 veri kümenizi seçin
- Veri kümeniz başka dosyalar içeren bir klasöre işaret ediyorsa, yalnızca moviesDB.csv dosyasının okundığından emin olmak için başka bir veri kümesi oluşturmanız veya parametreleştirmeyi kullanmanız gerekebilir
- Şemanızı ADLS'nize aktarmadıysanız ancak verilerinizi zaten aldıysanız veri kümesinin 'Şema' sekmesine gidin ve veri akışınızın şema projeksiyonunu bilmesi için 'Şemayı içeri aktar'a tıklayın.
Hata ayıklama kümeniz ısındıktan sonra Veri Önizleme sekmesi aracılığıyla verilerinizin doğru yüklendiğini doğrulayın. Yenile düğmesine tıkladığınızda Eşleme Veri Akışı, verilerinizin her dönüştürme sırasında nasıl göründüğüne ilişkin bir anlık görüntü gösterir.
Görev 3: Eşleme Veri Akışı dönüştürmeyi kullanma
Sütunu yeniden adlandırmak ve bırakmak için Bir Select dönüştürmesi ekleyin. Verilerin önizlemesinde "Rotton Domatesleri" sütununun yanlış yazıldığını fark etmiş olabilirsiniz. Doğru adlandırmak ve kullanılmayan Derecelendirme sütununu bırakmak için, ADLS kaynak düğümünüzün yanındaki + simgesine tıklayıp Şema değiştiricisi altında Seç'i seçerek bir Select dönüşümü ekleyebilirsiniz.
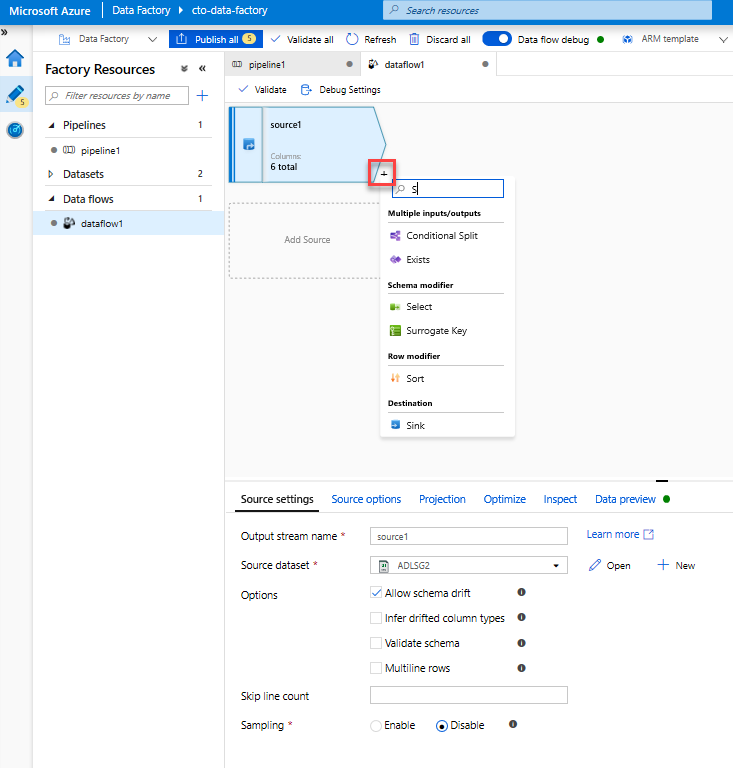
Ad olarak alanında , 'Rotton' değerini 'Rotten' olarak değiştirin. Derecelendirme sütununu bırakmak için üzerine gelin ve çöp kutusu simgesine tıklayın.
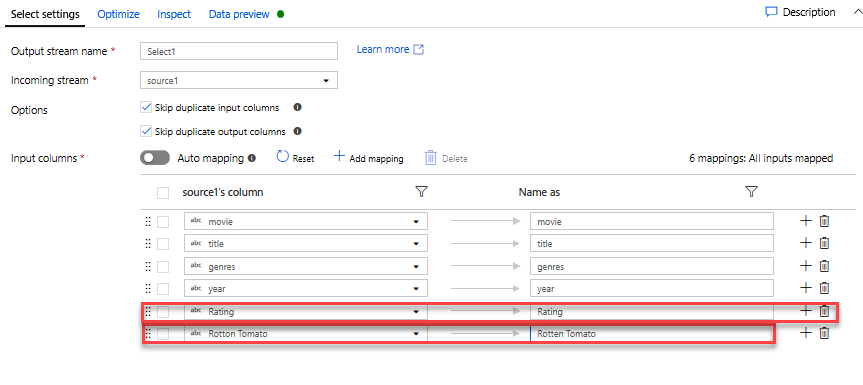
İstenmeyen yılları filtrelemek için filtre dönüştürmesi ekleyin. Sadece 1951'de yapılan filmlerle ilgilendiğinizi varsayalım. Seçim dönüştürmenizin yanındaki + simgesine tıklayıp Satır Değiştirici'nin altında Filtre'yi seçerek filtre koşulu belirtmek için filtre dönüştürmesi ekleyebilirsiniz. İfade oluşturucusunu açmak için ifade kutusuna tıklayın ve filtre koşulunuzu girin. Eşleme Veri Akışı ifade dilinin söz dizimini kullanarak toInteger(year) > 1950, dize yılı değerini bir tamsayıya dönüştürür ve bu değer 1950'nin üzerindeyse satırları filtreler.
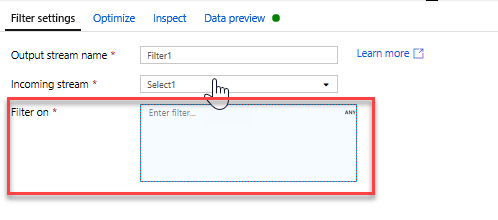
Koşulunuzun düzgün çalıştığını doğrulamak için ifade oluşturucusunun eklenmiş Veri önizleme bölmesini kullanabilirsiniz
Birincil türü hesaplamak için Türet Dönüştürmesi ekleyin. Fark etmiş olabileceğiniz gibi, tarzlar sütunu '|' karakteriyle sınırlandırılmış bir dizedir. Her sütunda yalnızca ilk türe önem veriyorsanız, Filtre dönüştürmenizin yanındaki + simgesine tıklayıp Şema Değiştirici'nin altında Türetilmiş'i seçerek Türetilmiş Sütun dönüşümü aracılığıyla PrimaryGenre adlı yeni bir sütun türetebilirsiniz. Filtre dönüşümüne benzer şekilde, türetilen sütun, yeni sütunun değerlerini belirtmek için Eşleme Veri Akışı ifade oluşturucusunu kullanır.

Bu senaryoda, 'genre1|genre2|...| olarak biçimlendirilmiş tarzlar sütunundan ilk türü ayıklamaya çalışıyorsunuzgenreN'. tür dizesinde '|' öğesinin ilk 1 tabanlı dizinini almak için locate işlevini kullanın. iif işlevi kullanıldığında, bu dizin 1'den büyükse, birincil tür bir dizinin solundaki bir dizedeki tüm karakterleri döndüren sol işlev aracılığıyla hesaplanabilir. Aksi takdirde, PrimaryGenre değeri tarzlar alanına eşittir. İfade oluşturucusunun Veri önizleme bölmesi aracılığıyla çıkışı doğrulayabilirsiniz.
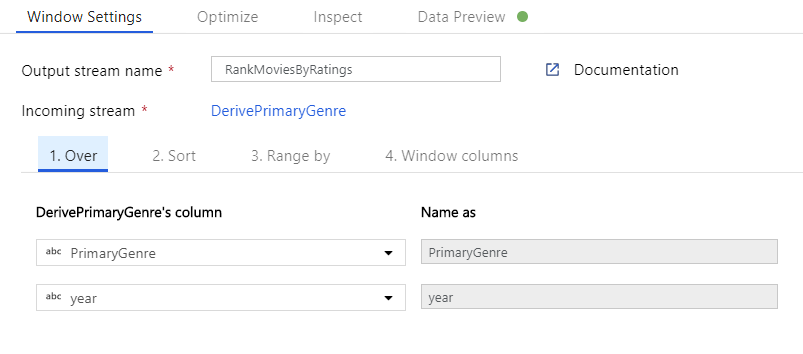
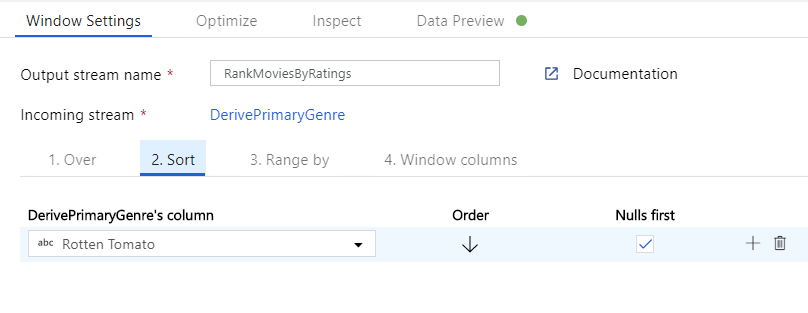
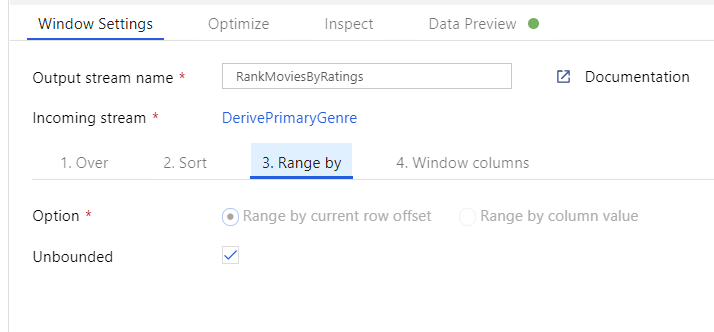
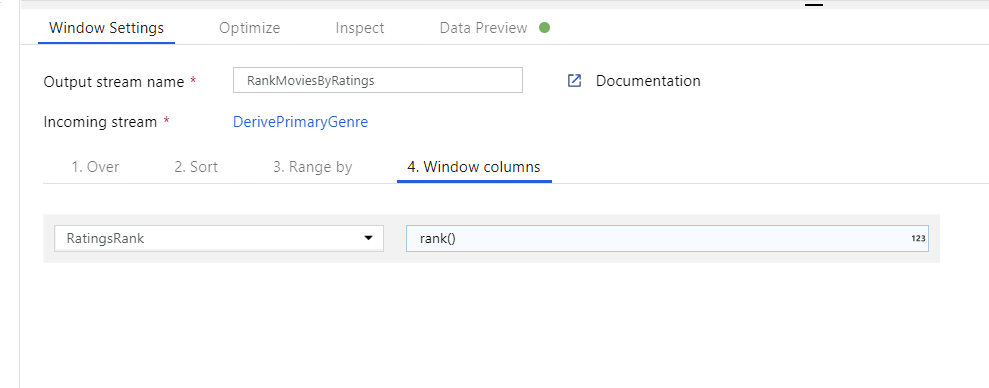
Pencere Dönüşümü aracılığıyla filmleri sıralama. Bir filmin belirli bir türü için yıl içinde nasıl derece aldığıyla ilgilendiğinizi varsayalım. Türetilmiş Sütun dönüştürmenizin yanındaki + simgesine ve Şema değiştirici'nin altındaki Pencere'ye tıklayarak pencere tabanlı toplamaları tanımlamak için bir Pencere dönüşümü ekleyebilirsiniz. Bunu başarmak için neleri pencerelediğiniz, nelere göre sıraladığınız, aralığın ne olduğunu ve yeni pencere sütunlarınızın nasıl hesaplanacağını belirtin. Bu örnekte PrimaryGenre ve yıl boyunca sınırsız aralıkla pencere oluşturacak, Çürük Domates'e göre azalan düzende sıralayacağız ve her filmin belirli bir tarz yılı içinde sahip olduğu dereceye eşit RatingsRank adlı yeni bir sütun hesaplayacağız.
Toplam Dönüştürme ile derecelendirmeleri toplama. Artık gerekli tüm verilerinizi topladığınıza ve türetdiğinize göre, Pencere dönüştürmenizin yanındaki + simgesine ve Şema değiştiricisi altında Toplama'ya tıklayarak ölçümleri istenen gruba göre hesaplamak için bir Toplama dönüşümü ekleyebiliriz. Pencere dönüşümünde yaptığınız gibi, filmleri PrimaryGenre ve yıla göre gruplandırmanızı sağlar
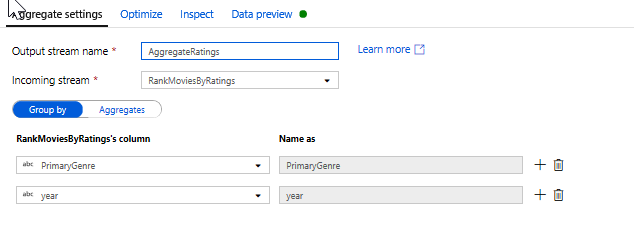
Toplamalar sekmesinde, belirtilen sütunlara göre gruplanmış toplamaları görebilirsiniz. Her tür ve yıl için, ortalama Rotten Tomatoes derecelendirmesini, en yüksek ve en düşük dereceli filmi (pencereleme işlevini kullanarak) ve her gruptaki film sayısını alalım. Toplama, dönüştürme akışınızdaki satır sayısını önemli ölçüde azaltır ve yalnızca dönüştürmede belirtilen gruplara ve toplama sütunlarına yayılır.
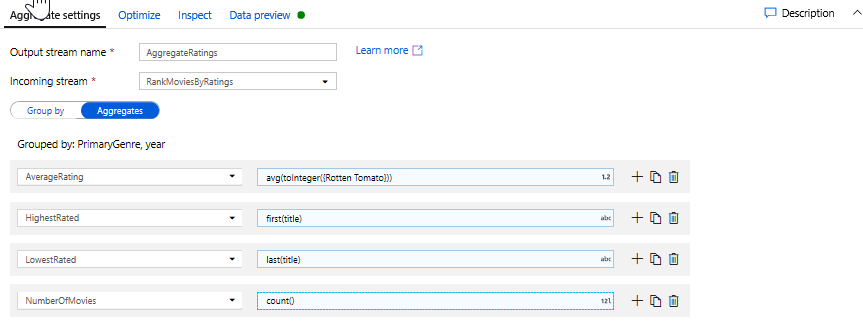
- Toplu dönüştürmenin verilerinizi nasıl değiştirdiğini görmek için Veri Önizleme sekmesini kullanın
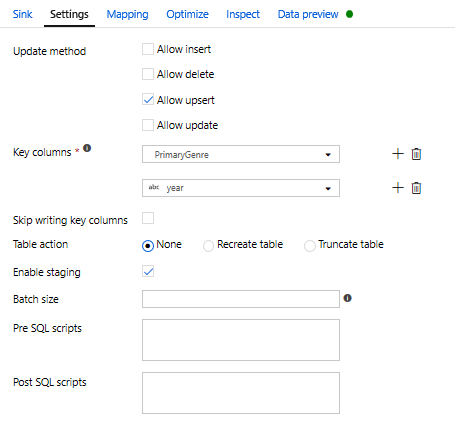
Değişiklik Satırı Dönüşümü aracılığıyla Upsert koşulunu belirtin. Tablosal havuza yazıyorsanız, Toplama dönüştürmenizin yanındaki + simgesine ve Satır değiştiricinin altında Satırı Değiştir'e tıklayarak Satır Değiştir dönüştürmesini kullanarak satırlara ekleme, silme, güncelleştirme ve ekleme ilkeleri belirtebilirsiniz. Her zaman ekleyip güncelleştirdiğiniz için, tüm satırların her zaman ekleneceğini belirtebilirsiniz.

Görev 4: Veri Havuzuna Yazma
- Azure Synapse Analytics Havuzuna yazma. Artık tüm dönüştürme mantığınızı tamamladığınıza göre, havuza yazmaya hazırsınız.
Upsert dönüşümünüzün yanındaki + simgesine ve Hedef altında Havuz'a tıklayarak Havuz ekleyin.
Havuz sekmesinde + Yeni düğmesi aracılığıyla yeni bir veri ambarı veri kümesi oluşturun.
Kutucuk listesinden Azure Synapse Analytics'i seçin.
Yeni bir bağlı hizmet seçin ve Azure Synapse Analytics bağlantınızı Modül 5'te oluşturulan DWDB veritabanına bağlanacak şekilde yapılandırın. Bitirdiğinizde Oluştur'a tıklayın.
Veri kümesi yapılandırmasında Yeni tablo oluştur'u seçin ve dbo şemasını ve Derecelendirmeler tablosunun adını girin. Tamamlandıktan sonra Tamam'a tıklayın.
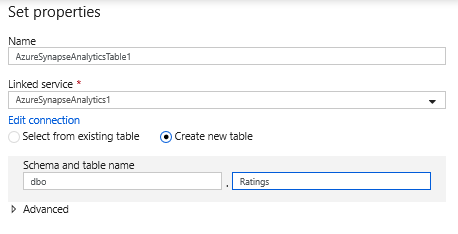
Upsert koşulu belirtildiğinden, Ayarlar sekmesine gitmeniz ve PrimaryGenre ve year anahtar sütunlarına göre 'Upsert'e izin ver'i seçmeniz gerekir.
Bu noktada, 8 dönüştürme Eşleme Veri Akışı derlemeyi tamamladınız. İşlem hattını çalıştırmanın ve sonuçları görmenin zamanı geldi!

Görev 5: İşlem hattını çalıştırma
Tuvalde işlem hattı1 sekmesine gidin. Veri Akışı'da Azure Synapse Analytics PolyBase kullandığından, bir blob veya ADLS hazırlama klasörü belirtmeniz gerekir. Veri Akışı yürüt etkinliğinin ayarlar sekmesinde PolyBase akordeonunu açın, ADLS bağlı hizmetinizi seçin ve bir hazırlama klasörü yolu belirtin.
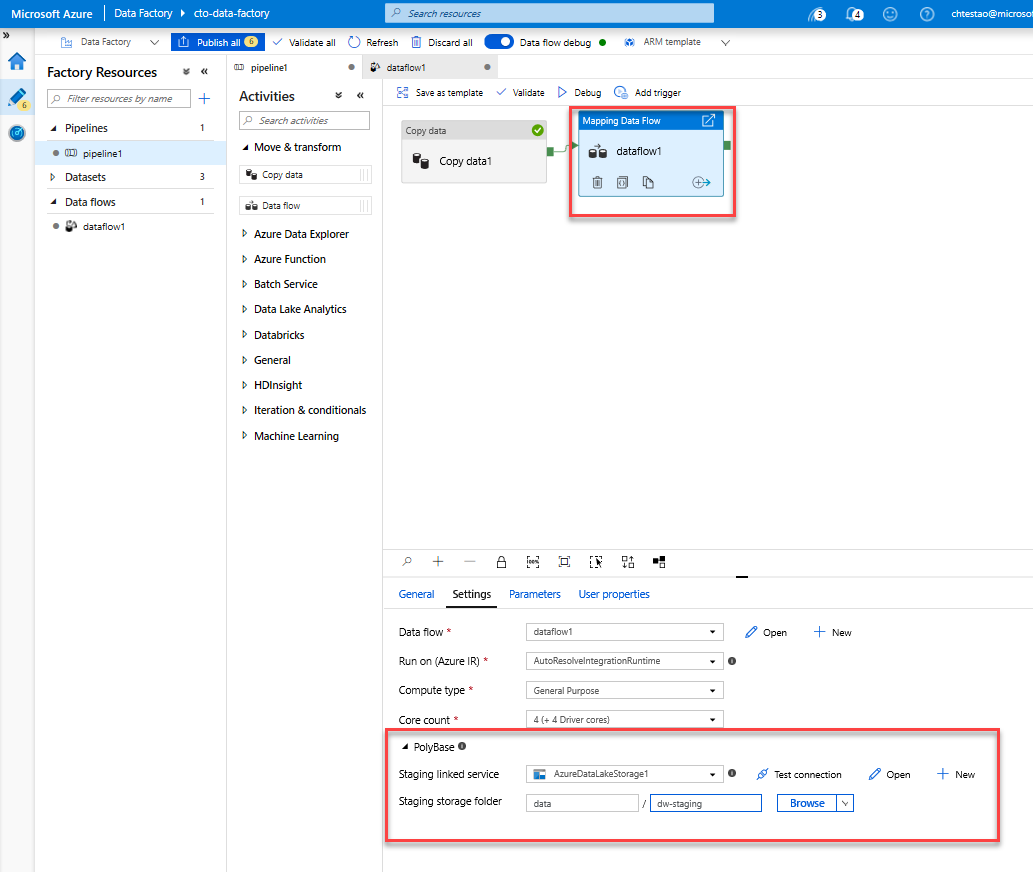
İşlem hattınızı yayımlamadan önce, beklendiği gibi çalıştığını onaylamak için başka bir hata ayıklama çalıştırması çalıştırın. Çıkış sekmesine baktığınızda, her iki etkinliğin de çalışır durumdaki durumunu izleyebilirsiniz.
her iki etkinlik de başarılı olduktan sonra, Veri Akışı çalıştırmaya daha ayrıntılı bir bakış elde etmek için Veri Akışı etkinliğinin yanındaki gözlük simgesine tıklayabilirsiniz.
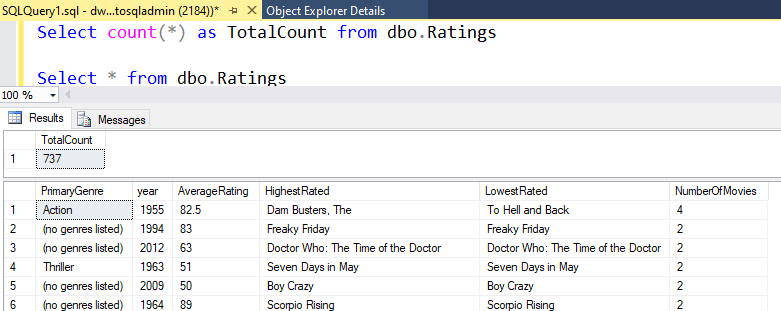
Bu laboratuvarda açıklanan mantığı kullandıysanız, Veri Akışı SQL DW'nize 737 satır yazar. İşlem hattının düzgün çalıştığını doğrulamak ve yazılanları görmek için SQL Server Management Studio'ya gidebilirsiniz.