Anlamsal modeller için yıldız şeması tasarlama
Verilerin anlam modelinize nasıl aktığını seçtiniz. Şimdi net ve performanslı sorgular için onu düzenleyen yıldız şemasını tasarlayın. Yıldız şeması, olgu tablolarını ilişkiler aracılığıyla boyut tablolarına bağlayarak raporların ve yapay zeka tüketiminin bağımlı olduğu filtre yollarını oluşturur. Power BI Desktop'ta yıldız şeması oluşturmayı biliyorsanız bu ünite, modellerin karmaşıklığı ve ölçeği büyüdükçe önemli olan ilişki tasarımı kararlarına odaklanır.
Anlamsal modelde yıldız şeması
Yıldız şemasında olgu tabloları ölçülebilir iş olaylarını (satış işlemleri, sipariş satırları ve web ziyaretleri gibi) depolar ve boyut tabloları açıklayıcı bağlamı (ürün ayrıntıları, müşteri bilgileri ve tarih öznitelikleri gibi) sağlar. Boyut tabloları olgu tablolarını ilişkiler aracılığıyla filtreleyerek kullanıcıların ölçümleri açıklayıcı özniteliklere göre dilimlemesini sağlar.
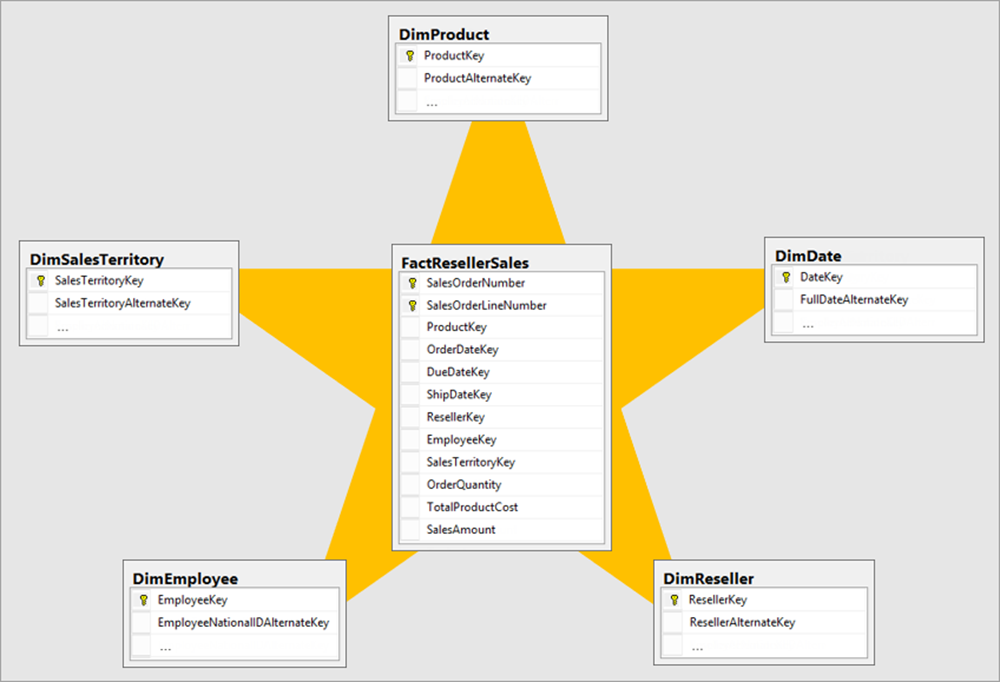
Fabric anlamsal modelde, bu desen hem raporlar hem de yapay zeka tüketimi için temiz filtre yayma sağlar. Copilot veya veri aracısı doğal dil sorgusu oluşturduğunda, iyi düzenlenmiş bir yıldız şeması yapay zekaya doğru verilerin açık yollarını verir. Belirsiz veya döngüsel ilişkiler hem rapor tüketicilerinin hem de yapay zeka araçlarının kafasını karıştırır.
Depolama modu ilişkileri nasıl etkiler?
Anlamsal modeldeki ilişkiler, depolama moduna bağlı olarak farklı davranır. Bu farklılıkları anlamak, farklı senaryolarda iyi performans gösteren yıldız şeması tasarlamak için gereklidir.
Direct Lake ilişkileri
Direct Lake modunda altyapı, ilişkileri doğrudan Delta tablosu meta verilerinden okur. İlişkiler en iyi performansı şu durumlarda gerçekleştirir:
- Boyut anahtarı sütunları olgu tablosu satırlarına göre düşük kardinaliteye sahiptir.
- Kaynak verilerde bilgi tutarlılığı korunur. Başvuru bütünlüğü sağlandığında, motor, sorgu performansını artıran LEFT OUTER birleşimleri yerine INNER birleşimlerini kullanır.
- İlişkilerde kullanılan sütunlar temel delta tablolarında dizine eklenir.
Uyarı
Sorgu, modelin bellek sınırlarını aşmasına veya desteklenmeyen işlemler kullanmasına neden olan bir ilişki içeriyorsa, Direct Lake DirectQuery'ye geri döner ve ilişki davranışı DirectQuery semantiğiyle eşleşecek şekilde değişir.
Kaynaklar arası ilişkiler
Fabric anlamsal modeller farklı veri depolarındaki tabloları bağlayabilir. Lakehouse'taki olgu tablosunun bir depodaki boyut tablosu ya da bir SQL analiz uç noktası üzerinden erişilen tablo ile ilişkisi olabilir. Bu kaynaklar arası bağlantılar bileşik model özelliklerini kullanır.
Tablolar farklı kaynaklardan geldiğinde, her tablonun depolama modu, ilişkinin sorgu zamanında nasıl çalıştığını belirler. Motor her iki tarafı bağımsız olarak çözümler ve sonuçları birleştirir.
İlişki türleri
Bire çok ilişkiler
Bire çok, yıldız şemasındaki en yaygın ilişki türüdür. Boyut tablosundaki benzersiz bir değer olgu tablosundaki birçok satırla ilgilidir. Örneğin, Ürün boyutundaki bir ürün satırı Sales fact tablosundaki binlerce sipariş satırıyla eşleşir.
Boyuttan (bir" taraf) olgu tablosuna ("çok" tarafı) akan filtre yönüyle bire çok ilişkileri yapılandırın. Bu, standart yıldız şeması filtre desenidir.
Çok-a-çok ilişkiler
İki tabloda da ilişki sütunu için benzersiz değerler olmadığında çoka çok ilişkiler gerekir. Bu ilişkileri çözmek için bir köprü tablosu kullanın. Köprü tablosu, iki tablonun arasında yer alır ve her iki taraftan gelen anahtarların eşsiz kombinasyonlarını barındırır.
Örneğin, bir müşterinin birden çok hesabı varsa ve bir hesap birden çok müşteriye ait olabilirse, Customer-Account köprü tablosu ilişkiyi çözer. Köprü tablosunun hem Müşteri hem de Hesap tabloları ile bire çok ilişkileri vardır.
Filtre yönü
Çoğu yıldız şeması uygulamasında, boyuttan olguya tek yönlü filtreleme kullanın. Bu, tahmin edilebilir filtre yayma sağlar ve sorgu sonuçlarında belirsizliği önler.
Çift yönlü filtreleme bazen çoka çok ilişkiler için veya boyut tablolarının olgu tablosundaki değerlere göre filtrelenmesi gerektiğinde gereklidir. Sorgu performansını düşürebileceğinden ve raporlarda beklenmeyen filtre davranışı oluşturabildiğinden çift yönlü filtreleri dikkate almadan kullanın.
Referans bütünlüğü
Referans bütünlüğünü varsay ayarı, motora bir ilişkiyi sorgularken LEFT OUTER birleşimler yerine INNER birleşimleri kullanmasını belirtir. Direct Lake ve DirectQuery modlarında, bu ayar motorun işlediği satır sayısını azalttığı için performansı önemli ölçüde artırabilir.
Olgu tablosundaki her yabancı anahtar değerinin boyut tablosunda eşleşen bir değere sahip olduğundan emin olduğunuzda bu ayarı etkinleştirin. Bilgi tutarlılığı ihlal edilirse, eşleşmeyen anahtarlara sahip satırlar sorgu sonuçlarından sessizce kaybolur.
Etkin olmayan ilişkiler ve USERELATIONSHIP
Aynı anda iki tablo arasında yalnızca bir etkin ilişki bulunabilir. Birden çok ilişki yoluna (sipariş tarihi ve aynı Tarih boyutuyla ilgili bir sevk tarihi gibi) ihtiyacınız olduğunda, bir ilişkiyi etkin, diğerlerini devre dışı yapın.
DAX'ta, hesaplama içinde etkin olmayan bir ilişkiyi etkinleştirmek için USERELATIONSHIP işlevini kullanın.
Shipped Amount =
CALCULATE(
SUM(Sales[Amount]),
USERELATIONSHIP(Sales[ShipDate], 'Date'[Date])
)
Bu desen, modeli temiz tutarken aynı veriler üzerinde birden çok analitik perspektifi destekler.
Anlam modellerinde kar tanesi şemasını işleme
Kaynak veriler genellikle boyut tablolarının birden çok ilişkili tabloya ayrıldığı normalleştirilmiş bir kar tanesi şemasına ulaşır. Örneğin, bir Ürün boyutu, her birinin yabancı anahtarlar aracılığıyla bağlantılı olduğu Product, Subcategory ve Category tablolarına ayrılabilir.
Anlamsal modelde iki seçeneğiniz vardır: kar tanesi bir yıldız şemasına düzleştirin veya normalleştirilmiş yapıyı koruyun.
Yıldız şemasına düzleştirme
Düzleştirme, normalleştirilmiş boyut tablolarını tek bir denormalize edilmiş boyut tablosunda birleştirme anlamına gelir. Product tablosu doğrudan Alt Kategori ve Kategori sütunlarını içerir ve ek tabloları ve ilişkileri ortadan kaldırır.
Şu durumlarda düzleştirme:
- Birleştirilmiş boyut tablosu olgu tablosuna göre hala küçüktür (boyutlar için neredeyse her zaman böyledir).
- Boyuttan olguya daha basit filtre yolları istiyorsunuz. Her filtre, zincir yerine tek bir ilişkide ilerler.
- Yapay zeka tüketimi önceliklidir. Daha az tablo ve daha basit ilişkiler, Copilot ve veri aracılarına doğru veriler için daha net yollar sağlar.
Veriler, anlam modeline ulaşmadan önce, veri lakehouse'larında veya veri akışlarında veri hazırlama sırasında boyut tablolarını düzleştirin. Normalleştirilmiş tabloları tek bir boyutta birleştirmek için Power Query birleştirmelerini, SQL birleşimlerini veya not defteri dönüştürmelerini kullanın.
Kar tanesi yapısını koruma
Bazı durumlarda, normalleştirilmiş yapıyı korumak mantıklıdır:
- Boyut hiyerarşisinin birden çok düzeyi vardır ve düzleştirme onlarca yedekli sütun oluşturur.
- Birden çok olgu tablosu alt boyut tablolarını (hem Satış hem de Envanter olguları tarafından kullanılan paylaşılan Kategori tablosu gibi) paylaşır ve denormalizasyon tutarsız kopyalar oluşturur.
- Satır düzeyi güvenliğin hiyerarşide belirli bir düzeyde uygulanması gerekir.
Kar tanesi yapısını koruduğunuzda ilişkileri dikkatle yapılandırın. Zincirdeki her ilişki, filtrelerin doğru yayılması için en dıştaki tablodan olgu tablosuna doğru tek yönlü filtreleme kullanmalıdır. Kategorideki bir filtrenin Alt Kategori'ye, ardından Ürün'e ve olgu tablosuna akması gerekir.
Uyarı
Anlamsal model senaryolarının çoğunda boyutları yıldız şemasına düzleştirme daha iyi bir seçimdir. Daha az tablo daha az ilişki, daha basit DAX, daha hızlı sorgular ve daha iyi yapay zeka tüketimi anlamına gelir. Kar tanesi yapısını yalnızca güçlü bir neden olduğunda koruyun.
Kaynaklar arası senaryolar için bileşik modeller ne zaman kullanılır?
Yıldız şemanız birden çok Fabric veri deposuna yayıldığında veya dış kaynaklar içerdiğinde bileşik modelleri kullanın. Yaygın senaryolar şunlardır:
- Fact tabloları, boyut tablolarının veri ambarında korunduğu bir lakehouse içinde yer alır.
- Bir olay evindeki gerçek zamanlı akış verileri, bir göl evindeki geçmiş verilerle birleştirilir.
- Dış kaynaktan aktarılan referans verileri, Fabric yerel olgu tabloları (Direct Lake) ile birleştirilmiştir.
Bu senaryolarda, her tablo için depolama modunu bağımsız olarak yapılandırın ve kaynaklar arası ilişkilerin beklenen veri birimlerinizde kabul edilebilir bir şekilde çalıştığını doğrulayın.