Normalleştirmeyi açıklama
Veritabanı normalleştirmesi, verileri bir veritabanındaki tablolar ve sütunlar halinde düzenlemek için kullanılan bir tasarım işlemidir. Her tablo belirli bir varlıkla ilgili verileri içermeli ve yalnızca bu varlığı destekleyen bilgileri içermelidir. Normalleştirmenin birincil hedefi, eklemeler ve güncelleştirmeler sırasında performans düşüşünü önlemeye yardımcı olan veritabanındaki yinelenen verileri en aza indirmektir. Örneğin, bir müşterinin adresinin güncelleştirilmesi gerekiyorsa, adres tablo gibi Customers tek bir konumda depolanıyorsa değişikliği uygulamak daha kolaydır.
En yaygın normalleştirme biçimleri birinci, ikinci ve üçüncü normal formlardır.
İlk normal form
İlk normal formda aşağıdaki belirtimler bulunur:
- İlişkili her veri kümesi için ayrı bir tablo oluşturma
- Tek tek tablolarda yinelenen grupları ortadan kaldırma
- Birincil anahtarla ilgili her veri kümesini tanımlama
Bu modelde, benzer verileri depolamak için tek bir tabloda birden çok sütun kullanmaktan kaçınmanız gerekir. Örneğin, bir ürün birden çok renkle gelebiliyorsa, farklı renk değerlerini içeren tek bir satırda birden çok sütuna sahip olmamanız gerekir. Aşağıdaki ilk tablo olan ProductColors, renk için yinelenen değerler içerdiğinden ilk normal biçimde değildir. Yalnızca bir rengi olan ürünlerde boş alan vardır. Ayrıca, bir ürün üçten fazla renkle geliyorsa, maksimum sütun sayısı ayarlamak pratik olmaz. Bunun yerine, ikinci tabloda gösterildiği gibi tabloyu yeniden oluşturabiliriz. ProductColor
İlk normal form ayrıca, değeri her satırı benzersiz olarak tanımlayan bir sütun (veya sütunlar) olan tablo için benzersiz bir anahtar olmasını gerektirir. İkinci tabloda, sütunların hiçbiri tek başına benzersiz değildir, ancak birlikte ProductID ve Color birleşimi benzersiz bir anahtar oluşturur. Benzersiz bir anahtar oluşturmak için birden çok sütun gerektiğinde bileşik anahtar olarak adlandırılır.
ProductColorsmasa:#B0 ProductID #C1 #B0 Color1 #C1 Color2 #B0 Color3 #C1 1 Kırmızı Yeşil Sarı 2 Sarı 3 Mavi Kırmızı 4 Mavi 5 Kırmızı ProductColormasa:#B0 ProductID #C1 Renk 1 Kırmızı 1 Yeşil 1 Sarı 2 Sarı 3 Mavi 3 Kırmızı 4 Mavi 5 Kırmızı
Üçüncü tablo, ProductInfoher satır belirli bir ürüne başvurduğundan, yinelenen grup olmadığından ve Birincil Anahtar olarak kullanılacak ProductID sütununa sahip olduğumuzdan ilk normal biçimdedir.
| #B0 ProductID #C1 | ProductName | Fiyat | #B0 ProductionCountry #C1 | #B0 ShortLocation #C1 |
|---|---|---|---|---|
| 1 | Widget | 15.95 | Amerika Birleşik Devletleri | ABD |
| 2 | Foop | 41.95 | Birleşik Krallık | Birleşik Krallık |
| 3 | Glombit | 49.95 | Birleşik Krallık | Birleşik Krallık |
| 4 | Sorfin | 99.99 | Filipinler Cumhuriyeti | RepPhil |
| 5 | Sap Cıvatası | 29.95 | Amerika Birleşik Devletleri | ABD |
İkinci normal form
İkinci normal form, ilk normal formun gerektirdiği özelliklere ek olarak aşağıdaki belirtime sahiptir:
- Tabloda bileşik anahtar varsa, tüm öznitelikler yalnızca bir parçasına değil tam anahtara bağlı olmalıdır.
İkinci normal form, yalnızca ikinci tablo olan tablosundaki ProductColorgibi bileşik anahtarlara sahip tablolarla ilgilidir. Tabloda ürünün fiyatının da bulunduğu ProductColor durumu göz önünde bulundurun. Bu tabloda ve ProductIDüzerinde Color bileşik anahtar vardır çünkü yalnızca her iki sütun değerini kullanarak bir satırı benzersiz olarak tanımlayabiliriz. Bir ürünün fiyatı renkle değişmezse verileri bu tabloda gösterildiği gibi görebiliriz.
| #B0 ProductID #C1 | Renk | Fiyat |
|---|---|---|
| 1 | Kırmızı | 15.95 |
| 1 | Yeşil | 15.95 |
| 1 | Sarı | 15.95 |
| 2 | Sarı | 41.95 |
| 3 | Mavi | 49.95 |
| 3 | Kırmızı | 49.95 |
| 4 | Mavi | 99,95 |
| 5 | Kırmızı | 29.95 |
Bu tablo ikinci normal biçimde değil. Fiyat değeri öğesine bağlıdır ancak değerine bağımlı ProductIDColordeğildir. için ProductID 1üç satır vardır, bu nedenle bu ürünün fiyatı üç kez tekrarlanır. İkinci normal formu ihlal etmeyle ilgili sorun, fiyatı güncelleştirmemiz gerekirse her yerde güncelleştirildiğinden emin olmamız gerektiğidir. birinci satırdaki fiyatı güncelleştirir, ancak ikinci veya üçüncü satırda güncelleştirmezsek bir güncelleştirme anomalisi ile karşılaşırız. Güncelleştirmeden sonra için gerçek fiyatı ProductID 1belirleyemiyoruz. Çözüm, sütunu tek sütun anahtarı olan Price bir tabloya taşımaktır ProductID çünkü bu, bağımlı olan tek sütundurPrice. Örneğin, tablo 3'i kullanarak depolayabiliriz Price.
Bir ürünün fiyatı rengine göre farklıysa, dördüncü tablo ikinci normal formda olacaktır, çünkü fiyat anahtarın her iki bölümüne de bağlı olacaktır: ProductID ve Color.
Üçüncü normal form
Üçüncü normal form genellikle ÇOĞU OLTP veritabanının amacıdır. Üçüncü normal form, ikinci normal formun gerektirdiği özelliklere ek olarak aşağıdaki belirtime sahiptir:
- Anahtar olmayan tüm sütunlar, birincil anahtara bağımlı değildir.
Geçişli ilişki, bir tablodaki bir sütunun ikinci sütun aracılığıyla diğer sütunlarla ilişkili olduğunu gösterir. Bağımlılık, bir sütunun değerini bu ilişkinin bir sonucu olarak başka bir sütundan türetebileceği anlamına gelir. Örneğin yaşınız doğum tarihinize göre belirlenebilir ve bu da yaşınızı doğum tarihinize bağlı hale getirir. Üçüncü tablo ProductInfoolan öğesine geri bakın. Bu tablo ikinci normal biçimdedir ancak üçüncü durumda değildir. Sütun ShortLocation , anahtar olmayan sütuna bağlıdır ProductionCountry . İkinci normal form gibi, üçüncü normal formu ihlal etmek de anomalilerin güncelleştirilmesine neden olabilir. Bir satırda güncelleştirdiğimiz halde bu konumun ShortLocation oluştuğu tüm satırlarda güncelleştirmediysek tutarsız verilerle sonuçlarız. Bunu önlemek için ülke/bölge adlarını ve kısaltılmış formlarını depolamak için ayrı bir tablo oluşturabiliriz.
Normal dışıleştirme
Üçüncü normal form teorik olarak arzu edilir olsa da, tüm veriler için her zaman mümkün değildir. Buna ek olarak, normalleştirilmiş bir veritabanı size her zaman en iyi performansı vermez. Normalleştirilmiş veriler genellikle tek bir sorguda döndürülen tüm gerekli verileri almak için birden çok birleştirme işlemi gerektirir. Sorgu sonuçlarını döndürmek için gereken birleştirme sayısının yüksek CPU kullanımına sahip olması ve daha az birleştirme ve daha az CPU gerektiren normalleştirilmiş veriler olması durumunda verileri normalleştirme arasında bir fark vardır, ancak anomalileri güncelleştirme olasılığı açılır.
Normalleştirilmiş verilerin sorgulanması, özellikle de veri ambarı gibi yoğun okunan iş yükleri için daha verimli olabilir. Bu gibi durumlarda, ek sütunlara sahip olmak daha iyi sorgu desenleri ve/veya daha basit sorgular sunabilir.
Yıldız şeması
Çoğu normalleştirme OLTP iş yüklerini hedeflese de, veri ambarlarının genellikle normalleştirilmiş bir model olan kendi modelleme yapısı vardır. Bu tasarım, satış gibi belirli olaylara yönelik ölçümleri veya ölçümleri kaydetmek için olgu tablolarını kullanır ve bunları boyut tablolarına birleştirir. Boyut tabloları satır sayısı bakımından daha küçüktür, ancak olgu verilerini tanımlamak için çok sayıda sütuna sahip olabilir. Boyutlara örnek olarak envanter, zaman ve coğrafya verilebilir. Bu tasarım deseni, veritabanını sorgulamayı kolaylaştırır ve okuma iş yükleri için performans kazanımları sunar.
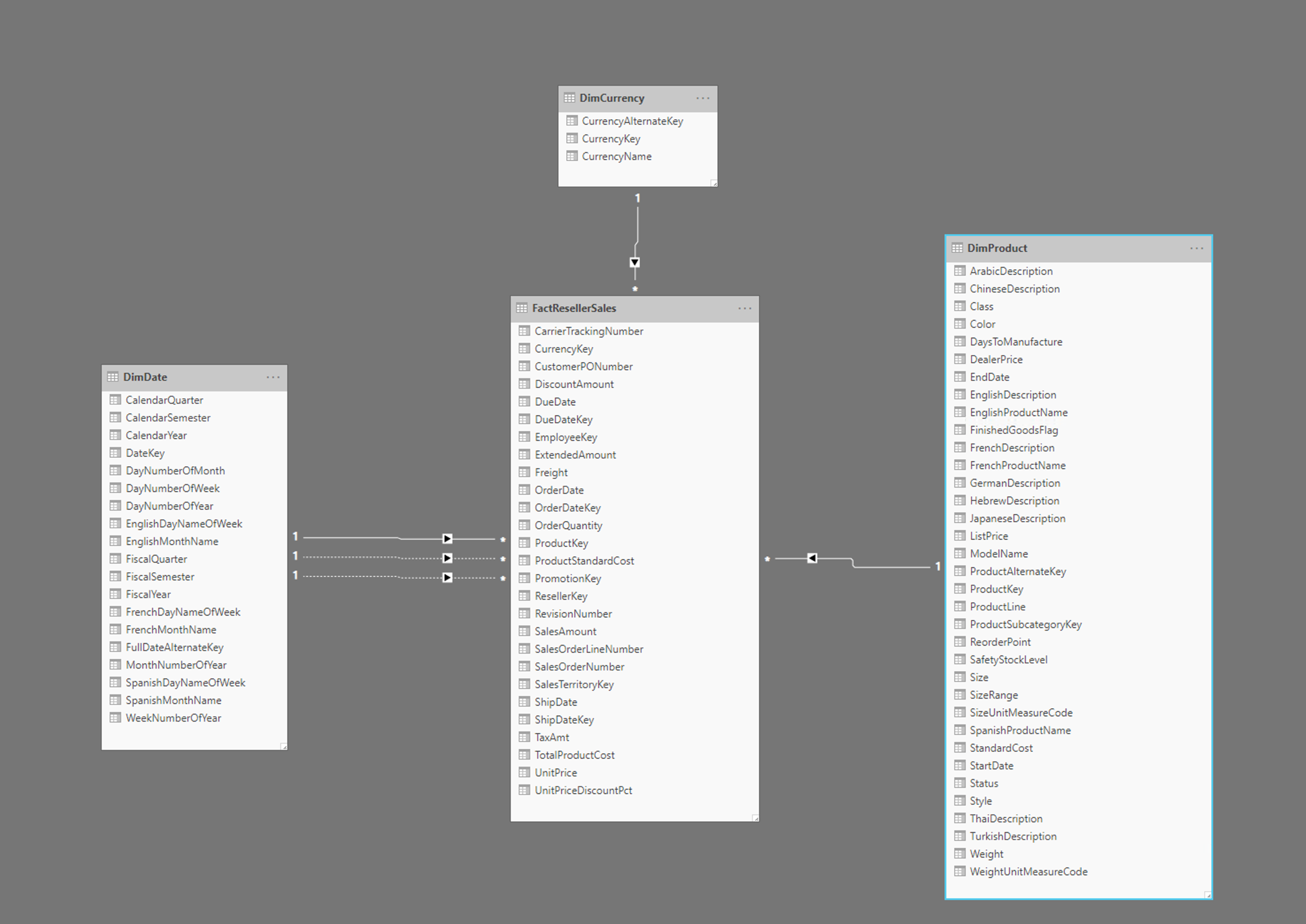
Görüntüde olgu tablosu ve tarih, para birimi ve ürünler için boyutlar içeren bir FactResellerSales yıldız şeması örneği gösterilmektedir. Olgu tablosu satış işlemleriyle ilgili verileri içerirken boyutlar yalnızca satış verilerinin belirli öğeleriyle ilgili verileri içerir. Örneğin, FactResellerSales tablo yalnızca hangi ürünün satıldığını belirtmek için bir ProductKey içerir. Her ürünle ilgili tüm ayrıntılar tabloda depolanır DimProduct ve sütununu kullanarak olgu tablosuyla ProductKey ilişkilidir.
Yıldız şeması tasarımıyla ilgili olarak, tek bir iş varlığı için daha normalleştirilmiş bir tablo kümesi kullanan kar tanesi şeması kullanılır. Aşağıdaki görüntüde, kar tanesi şemasındaki tek bir boyutun örneği gösterilmektedir. Ürünler boyutu normalleştirilir ve üç tabloda depolanır: DimProductCategory, DimProductSubcategoryve DimProduct.
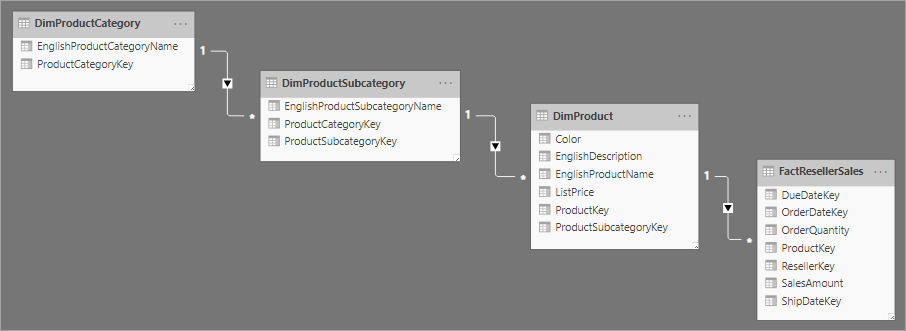
Yıldız ve kar tanesi şemaları arasındaki temel fark, bir kar tanesi şemasındaki boyutların yedekliliği azaltmak için normalleştirilmesidir ve bu da depolama alanından tasarruf sağlar. Bunun dezavantajı, sorgularınızın daha fazla birleşim gerektirmesi ve bu da karmaşıklığınızı artırabilir ve performansı düşürebilir.