Sorunlu sorgu planlarını tanımlama
DTA'ların sorgu performansıyla ilgili sorunları gidermeye yönelik tipik yaklaşımı, önce sorunlu sorguyu tanımlamayı, genellikle en çok sistem kaynağını kullanan sorguyu ve ardından yürütme planını almayı içerir. İki ana senaryo vardır. Bir senaryo, sorgunun tutarlı bir şekilde düşük performans göstermesini sağlar. Bunun nedeni donanım kaynağı kısıtlamaları (genellikle yalıtımda çalışan tek bir sorguyu etkilemese de), alt optimum sorgu yapısı, veritabanı uyumluluk ayarları, eksik dizinler veya sorgu iyileştiricisi tarafından hatalı plan seçimleri gibi çeşitli sorunlardan kaynaklanabilir. İkinci senaryo, sorgunun bazı yürütmelerde iyi performans göstermesi, bazılarında ise kötü olmasıdır. Bu tutarsızlık, bazı yürütmeler için verimli bir plana ve diğerleri için kötü bir plana sahip olan parametreli sorgudaki veri dengesizliği gibi faktörlerden kaynaklanabilir. Diğer yaygın faktörler arasında, bir sorgunun, başka bir sorgunun tamamlanmasını bekleyerek tabloya erişim sağladığı "engelleme" durumu veya donanım üzerinde yaşanan kaynak çatışması yer alır.
Şimdi bu senaryoların her birini daha ayrıntılı bir şekilde inceleyelim.
Donanım kısıtlamaları
Donanım kısıtlamaları genellikle tek sorgu yürütmeleri sırasında bildirim vermez, ancak CPU iş parçacıkları ve bellek sınırlı olduğunda üretim yükü altında belirginleşir. CPU çekişmesi, sunucu CPU kullanımını ölçen '% İşlemci Süresi' performans izleyici sayacı gözlemlenerek algılanabilir. SQL Server'da SOS_SCHEDULER_YIELD ve CXPACKET bekleme türleri CPU baskısını gösterebilir. Düşük depolama sistemi performansı, iyileştirilmiş tek sorgu yürütmelerini bile yavaşlatabilir. Depolama performansı, işletim sistemi düzeyinde performans izleyici sayaçları Disk Seconds/Read ve Disk Seconds/Write kullanılarak en iyi şekilde izlenir; bu sayaçlar, G/Ç işlemlerinin tamamlanma sürelerini ölçer. SQL Server, bir G/Ç işlemi 15 saniyeden uzun sürdüğünde başarısız depolama performansını günlüğe kaydeder. SQL Server'da yüksek PAGEIOLATCH_SH bekleme süreleri depolama performansı sorunlarını gösterebilir. Donanım performansı genellikle değerlendirme kolaylığı nedeniyle sorun giderme sürecinin erken aşamalarında değerlendirilir.
Veritabanı performans sorunlarının çoğu, donanım üzerinde gereksiz baskı oluşturabilen yetersiz sorgu desenlerinden kaynaklanabilir. Örneğin, eksik dizinler gerektiğinden daha fazla veri alarak CPU, depolama ve bellek baskısına yol açabilir. Donanım sorunlarıyla başa çıkmadan önce optimal olmayan sorguların ele alınması ve ayarlanması önerilir. Sonrasında sorgu ayarlarına göz atacağız.
Uygun olmayan sorgu yapıları
İlişkisel veritabanları, kümelerdeki verileri (INSERT, UPDATE, DELETEve SELECT) işleyen ve tek bir değer veya sonuç kümesi oluşturan küme tabanlı işlemleri yürütürken en iyi performansı gösterir. Alternatif, imleçler veya while döngüleri kullanılarak yapılan ve etkilenen satır sayısıyla doğrusal olarak maliyeti artıran satır tabanlı işlemedir; bu, veri hacimleri arttıkça sorunlu bir ölçek haline gelir.
Satır tabanlı işlemlerin imleçlerle veya WHILE döngüleriyle verimsiz kullanımını tespit etmek önemlidir, fakat tanınması gereken başka SQL Server anti-desenleri de vardır. Tablo değerli işlevler (TVF'ler), özellikle çok deyimli TVF'ler, SQL Server 2017'den önce sorunlu yürütme planı desenlerine neden oldu. Geliştiriciler genellikle tek bir işlev içinde birden çok sorgu yürütmek ve sonuçları tek bir tabloda toplamak için çok deyimli TVF'ler kullanır. Ancak, TVF'leri kullanmak performans cezalarına yol açabilir.
SQL Server'da iki tür TVF vardır: satır içi ve çok deyimli. Satır içi TVF'ler görünüm olarak değerlendirilirken, çok deyimli TVF'ler sorgu işleme sırasında tablolar gibi değerlendirilir. TVF'ler dinamik olduğundan ve istatistik eksik olduğundan, SQL Server sorgu planı maliyetini tahmin etmek için sabit bir satır sayısı kullanır. Bu küçük satır sayıları için uygun olabilir, ancak binlerce veya milyonlarca satır için verimsiz olabilir.
Diğer bir anti-desen, benzer tahmin ve yürütme sorunları olan skaler işlevlerin kullanılmasıdır. Microsoft, 140 ve 150 uyumluluk düzeyleri altında Akıllı Sorgu İşleme ile önemli performans geliştirmeleri yapmıştır.
SARGability
İlişkisel veritabanlarında SARGable terimi, sorgu yürütmeyi hızlandırmak için dizin kullanmak üzere biçimlendirilmiş bir koşula (WHERE yan tümce) başvurur. Doğru biçimdeki önermelere 'Arama Argümanları' veya SARG'lar adı verilir. SQL Server'da SARG kullanmak, optimizatörün bir değeri almak için dizinin veya tablonun tamamını taramak yerine, SEEK işlemi için SARG'de başvurulan sütunda kümelenmemiş bir dizin kullanarak değerlendirme yapmasını sağlar.
BIR SARG'nin varlığı, BIR SEEK için dizin kullanımını garanti etmez. İyileştiricinin maliyetlendirme algoritmaları, özellikle bir SARG tablodaki satırların büyük bir yüzdesine başvuruyorsa dizinin çok pahalı olduğunu belirlemeye devam edebilir. SARG'ın yokluğu, iyileştiricinin kümelenmemiş bir indeks üzerinde seek'i değerlendirmeyeceği anlamına gelir.
SARGable olmayan ifadelere örnek olarak, joker karakterin dizenin başında kullanıldığı bir yan LIKE tümcesine sahip olanlar verilebilir. Örneğin WHERE lastName LIKE '%SMITH%'. SARGable olmayan diğer koşullar, WHERE CONVERT(CHAR(10), CreateDate,121) = '2020-03-22' gibi bir sütunda işlevler kullanıldığında meydana gelir. Bu sorgular genellikle, aksi takdirde aramaların gerçekleşmesi gereken dizin veya tablo taramaları için yürütme planları incelenerek tanımlanır.
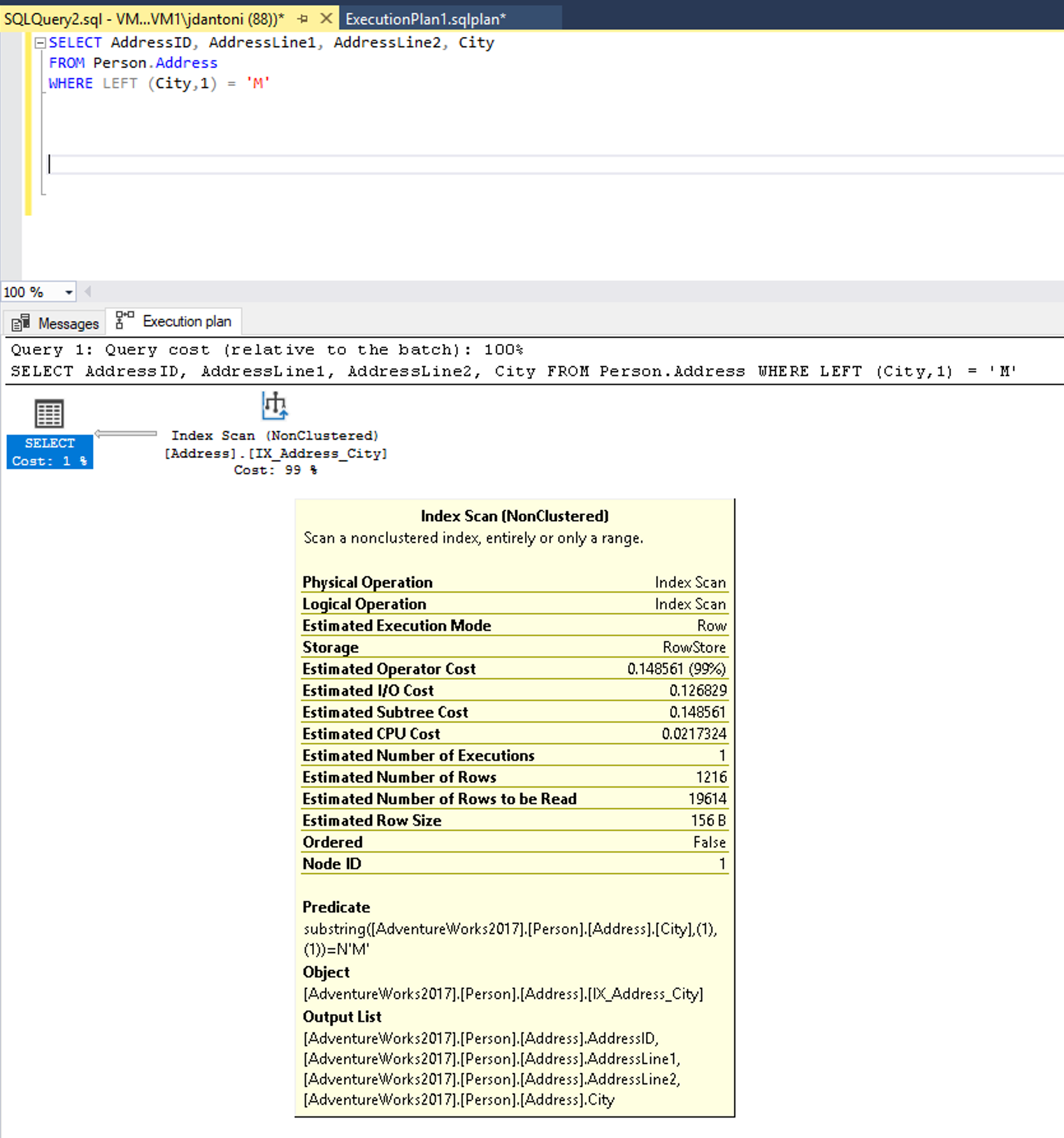
City sütununda sorgunun WHERE yan tümcesinde kullanılan bir dizin vardır ve bu yukarıdaki yürütme planında kullanılırken dizinin tarandığını görebilirsiniz, bu da dizinin tamamının okunduğu anlamına gelir. koşuldaki LEFT işlevi bu ifadeyi SARGable değil yapar. İyileştirici, City sütunundaki dizin üzerinden aramayı kullanarak değerlendirme yapmaz.
Bu sorgu, SARGable bir ön koşul kullanmak için yazılabilir. İyileştirici daha sonra City sütunundaki dizinde bir SEEK işlemi değerlendirir. Bu durumda bir dizin arama işleci daha küçük bir satır kümesini okur.
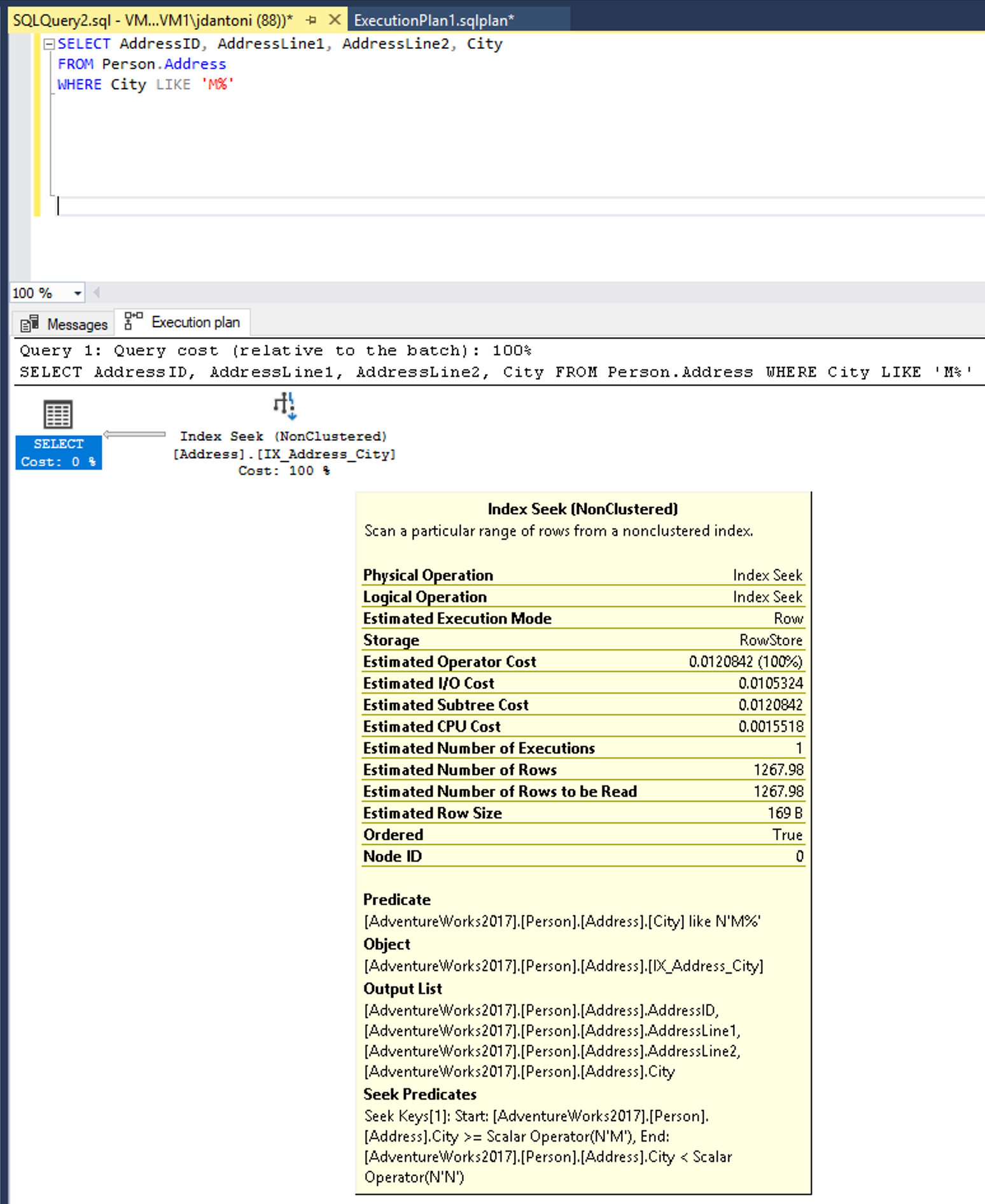
İşlevi bir LIKE dizin aramasına dönüştürerek LEFT sonuç elde edin.
Uyarı
LIKE Bu örnekte anahtar sözcüğün sol tarafında joker karakter yok, bu yüzden M ile başlayan şehirleri arar. "İki taraflı" veya joker karakter ('%M%' veya '%M') ile başlasaydı SARG ile uyumlu olmazdı. Arama işleminin, SARGable olmayan koşula sahip sorgunun tahminine göre yaklaşık %15 oranında, yani 1.267 satır döndüreceği tahmin edilmektedir.
Diğer bazı veritabanı geliştirme anti-desenleri, veritabanını veri deposu yerine bir hizmet olarak ele alır. Verileri JSON'a dönüştürmek, dizeleri işlemek veya karmaşık hesaplamalar yapmak için veritabanı kullanmak aşırı CPU kullanımına ve gecikme süresinin artmasına neden olabilir. Tüm kayıtları almaya ve sonra veritabanında hesaplamalar gerçekleştirmeye çalışan sorgular aşırı GÇ ve CPU kullanımına yol açabilir. İdeal olarak, veri erişim işlemleri ve toplama gibi iyileştirilmiş veritabanı yapıları için veritabanını kullanmanız gerekir.
Eksik dizinler
Veritabanı yöneticileri için en yaygın performans sorunları, altyapının sorgu sonuçlarını döndürmek için gerekenden daha fazla sayfa okumasına neden olan kullanışlı dizinlerin olmamasından kaynaklanıyor. Dizinler kaynakları (yazma performansını etkileyen ve alan tüketen) tüketirken, performans artışları genellikle ek kaynak maliyetlerinden daha ağır basar. Bu sorunlarla ilgili yürütme planları , Kümelenmiş Dizin Taraması sorgu işleci veya mevcut bir dizinde eksik sütunları gösteren Kümelenmemiş Dizin Arama ve Anahtar Arama birleşimi tarafından tanımlanabilir.
Veritabanı altyapısı, yürütme planlarındaki eksik dizinleri bildirerek yardımcı olur. Önerilen dizinlerin adları ve ayrıntıları dinamik yönetim görünümü sys.dm_db_missing_index_detailsaracılığıyla kullanılabilir. Diğer DMV'ler, sys.dm_db_index_usage_stats ve sys.dm_db_index_operational_stats, mevcut dizinlerin kullanımını vurgular.
Kullanılmayan dizini bırakmak mantıklı olabilir. Eksik dizin DMV'leri ve plan uyarıları, sorguları ayarlamak için başlangıç noktaları olmalıdır. Temel sorguları anlamak ve bunları desteklemek için dizinler oluşturmak çok önemlidir. Tüm eksik dizinlerin bağlam içinde değerlendirilmeden oluşturulması önerilmez.
Eksik ve güncel olmayan istatistikler
Sütun ve dizin istatistiklerinin sorgu iyileştiricisi açısından önemini anlamak çok önemlidir. Ayrıca, güncel olmayan istatistiklere yol açabilecek koşulları ve bu sorunun SQL Server'da nasıl ortaya çıkabileceğini tanımak da önemlidir. Azure SQL teklifleri varsayılan olarak otomatik güncelleştirme istatistiklerinin ON olarak ayarlanmasını sağlar. SQL Server 2016'nın öncesinde otomatik güncelleştirme istatistiklerinin varsayılan davranışı, dizindeki sütunlarda yapılan değişikliklerin sayısı tablodaki satır sayısının yaklaşık 20% eşit olana kadar istatistikleri güncelleştirmemekti. Bu davranış, istatistikleri güncelleştirmeden sorgu performansını değiştiren önemli veri değişikliklerine neden olabilir ve güncel olmayan istatistiklere dayalı en iyi olmayan planlara yol açabilir.
SQL Server 2016'ya kadar izleme bayrağı 2371, gerekli değişiklik sayısını dinamik bir değere değiştirmek için kullanılabilirdi, böylece tablonuz büyüdükçe istatistik güncelleştirmesini tetiklemek için gereken satır değişiklikleri yüzdesi azaldı. SQL Server, Azure SQL Veritabanı ve Azure SQL Yönetilen Örneği'nin daha yeni sürümleri bu davranışı varsayılan olarak destekler. Dinamik yönetim işlevi sys.dm_db_stats_properties , istatistiklerin en son ne zaman güncelleştirildiğini ve son güncelleştirmeden bu yana yapılan değişikliklerin sayısını gösterir ve bu sayede el ile güncelleştirme gerekebilecek istatistikleri hızla belirleyebilirsiniz.
Kötü iyileştirici seçenekleri
Sorgu iyileştirici çoğu sorguyu başarılı bir şekilde gerçekleştirse de, maliyet tabanlı sorgu iyileştirme işleminin tam olarak anlaşılmayan etkili kararlar alabildiği bazı uç durumlar vardır. Kararlı ve en uygun sorgu planına ulaşmak için sorgu ipuçlarını, izleme bayraklarını, yürütme planı zorlamayı ve diğer ayarlamaları kullanma dahil olmak üzere bu sorunu gidermenin birçok yolu vardır. Microsoft'un bu senaryolarda sorun gidermeye yardımcı olabilecek bir destek ekibi vardır.
AdventureWorks2017 veritabanındaki aşağıdaki örnekte, veritabanı iyileştiricisinin her zaman Seattle şehir adını kullanmasını sağlaması için bir sorgu ipucu kullanılmaktadır. Bu ipucu tüm şehir değerleri için en iyi yürütme planını garanti etmez, ancak tahmin edilebilir.
@city_name için 'Seattle' değeri yalnızca optimizasyon sırasında kullanılacaktır. Yürütme sırasında sağlanan gerçek değer (‘Ascheim’) kullanılır.
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
Örnekte görüldüğü gibi, sorgu, optimizasyon aracına yürütme planını oluşturmak için belirli bir değişken değeri kullanmasını bildirmek amacıyla bir ipucu (OPTION yan tümcesi) kullanır.
Parametre algılama
SQL Server, sorgu yürütme planlarını gelecekte kullanmak üzere önbelleğe alır. Yürütme planı alma işlemi bir sorgunun karma değerini temel aldığı için, sorgu metninin önbelleğe alınmış plan için sorgunun her yürütülmesi için aynı olması gerekir. Aynı sorguda birden çok değeri desteklemek için, birçok geliştirici aşağıdaki örnekte görüldüğü gibi saklı yordamlar aracılığıyla geçirilen parametreleri kullanır:
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
Sorgular, sp_executesql yordamı kullanılarak açıkça parametrelendirilebilir. Ancak, tek tek sorguların açık parametreleştirilmesi, uygulama aracılığıyla PREPARE ve EXECUTE'ın bir biçimiyle (API'ye bağlı olarak) gerçekleştirilir. Veritabanı altyapısı bu sorguyu ilk kez yürüttüğünde, bu durumda parametrenin ilk değerine (bu örnekte 42) göre sorguyu iyileştirir. Parametre algılama olarak adlandırılan bu davranış, derleme sorgularının genel iş yükünün sunucuda azaltılmasını sağlar. Ancak veri dengesizliği varsa sorgu performansı büyük ölçüde farklılık gösterebilir.
Örneğin, 10 milyon kaydı olan bir tablo ve bu kayıtların 99% 1 kimliğine sahiptir ve diğer 1% benzersiz sayılardır; performans, sorguyu iyileştirmek için ilk olarak hangi kimliğin kullanıldığına bağlıdır. Bu dalgalı performans, veri dengesizliğini gösterir ve parametre koklama ile ilgili doğal bir sorun değildir. Bu davranış, farkında olmanız gereken oldukça yaygın bir performans sorunudur. Sorunu hafifletme seçeneklerini anlamanız gerekir. Bu sorunu çözmenin birkaç yolu vardır, ancak her birinin dezavantajları vardır:
- Sorgunuzdaki ipucunu
RECOMPILEveyaWITH RECOMPILEsaklı yordamlarınızdaki yürütme seçeneğini kullanın. Bu ipucu, sorgunun veya yordamın her yürütülürken yeniden derlenmelerine neden olur ve bu da sunucuda CPU kullanımını artırır ancak her zaman geçerli parametre değerini kullanır. - Siz.
OPTIMIZE FOR UNKNOWNsorgu ipucunu kullanabilirsiniz. Bu ipucu, iyileştiricinin parametreleri algılamamayı seçmesine ve değeri sütun veri histogramı ile karşılaştırmasına neden olur. Bu seçenek size mümkün olan en iyi planı vermez ancak tutarlı bir yürütme planı sağlar. - Yordamınızı veya sorgularınızı, yalnızca bilinen sorunlu parametreler için parametre değerlerine mantık ekleyerek RECOMPILE işlemi yapacak şekilde yeniden yazın. Aşağıdaki örnekte SalesPersonID parametresi NULL ise, sorgu ile
OPTION (RECOMPILE)yürütülür.
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
Bu örnek iyi bir çözümdür, ancak oldukça büyük bir geliştirme çabası ve veri dağıtımınızın kesin bir şekilde anlaşılmasını gerektirir. Veriler değiştikçe bakım gerektirir.