Regresyon
Regresyon modelleri, hem özellikleri hem de bilinen etiketleri içeren eğitim verilerine göre sayısal etiket değerlerini tahmin etmek için eğitilir. Regresyon modelini (veya gerçekten de herhangi bir denetimli makine öğrenmesi modelini) eğitme işlemi, modeli eğitmek, modelin tahmine dayalı performansını değerlendirmek ve kabul edilebilir bir tahmin doğruluğu düzeyi elde edene kadar eğitim sürecini farklı algoritmalar ve parametrelerle tekrarlayarak modeli iyileştirmek için uygun bir algoritma (genellikle bazı parametreli ayarlarla) kullandığınız birden çok yinelemeyi içerir.
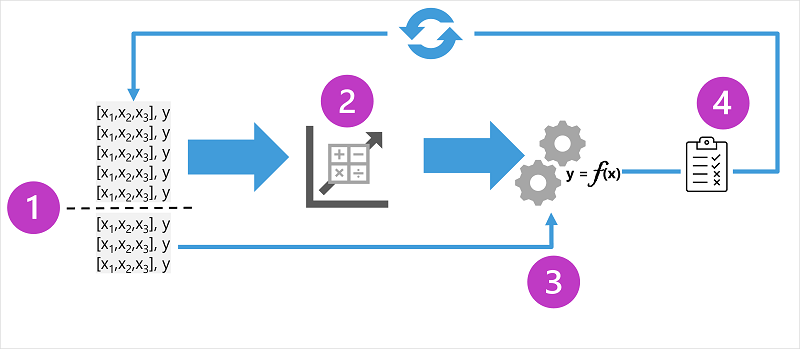
Diyagramda denetimli makine öğrenmesi modelleri için eğitim sürecinin dört temel öğesi gösterilmektedir:
- Eğitilen modeli doğrulamak için kullanacağınız verilerin bir alt kümesini tutarken modeli eğitebileceğiniz bir veri kümesi oluşturmak için eğitim verilerini (rastgele) bölün.
- Eğitim verilerini bir modele sığdırmak için algoritma kullanın. Regresyon modeli söz konusu olduğunda doğrusal regresyon gibi bir regresyon algoritması kullanın.
- Özelliklerin etiketlerini tahmin ederek modeli test etmek için yedeklediğiniz doğrulama verilerini kullanın.
- Doğrulama veri kümesindeki bilinen gerçek etiketleri modelin tahmin edilen etiketlerle karşılaştırın. Ardından tahmin edilen ve gerçek etiket değerleri arasındaki farkları toplayarak modelin doğrulama verileri için ne kadar doğru tahminde bulunduğunu gösteren bir ölçümü hesaplayın.
Her tren, doğrulama ve değerlendirme yinelemesinin ardından, kabul edilebilir bir değerlendirme ölçümü elde edilene kadar işlemi farklı algoritmalar ve parametrelerle tekrarlayabilirsiniz.
Örnek - regresyon
Şimdi bir modeli tek bir özellik değerine (x) göre sayısal etiket (y) tahmin edecek şekilde eğiteceğimiz basitleştirilmiş bir örnekle regresyonu inceleyelim. Gerçek senaryoların çoğu birden çok özellik değeri içerir ve bu da biraz karmaşıklık ekler; ama ilke aynıdır.
Örneğimizde, daha önce ele aldığımız dondurma satış senaryosuna bağlı kalalım. Özelliğimiz için sıcaklığı dikkate alacağız (değerin belirli bir gündeki en yüksek sıcaklık olduğunu varsayalım) ve modeli tahmin etmek için eğitmek istediğimiz etiket, o gün satılan dondurma sayısıdır. Günlük sıcaklıkların (x) ve dondurma satışlarının (y) kayıtlarını içeren bazı geçmiş verilerle başlayacağız:
 |
 |
|---|---|
| Sıcaklık (x) | Dondurma satışları (y) |
| 51 | 1 |
| 52 | 0 |
| 67 | 14 |
| 65 | 14 |
| 70 | 23 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 73 | 22 |
| 81 | 30 |
| Kategori 78 | 26 |
| 83 | 36 |
Regresyon modelini eğitme
İlk olarak verileri bölerek ve modeli eğitmek için bir alt kümesini kullanarak başlayacağız. Eğitim veri kümesi aşağıdadır:
| Sıcaklık (x) | Dondurma satışları (y) |
|---|---|
| 51 | 1 |
| 65 | 14 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 81 | 30 |
Bu x ve y değerlerinin birbiriyle nasıl ilişkili olabileceğine ilişkin bir içgörü elde etmek için, bunları iki eksen boyunca koordinatlar olarak çizebiliriz, örneğin:
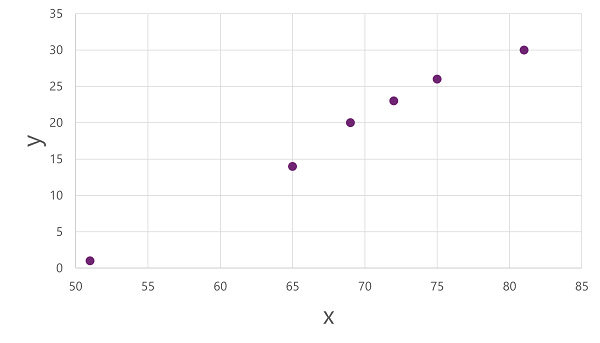
Şimdi eğitim verilerimize bir algoritma uygulamaya ve bunu x'e y hesaplama işlemiuygulayan bir işleve sığdırmaya hazırız. Bu tür algoritmalardan biri, x ve y değerlerinin kesişimleri arasında düz bir çizgi oluşturan ve çizgi ile çizilen noktalar arasındaki ortalama uzaklığı en aza indiren bir işlev türeterek çalışan doğrusal regresyondur:
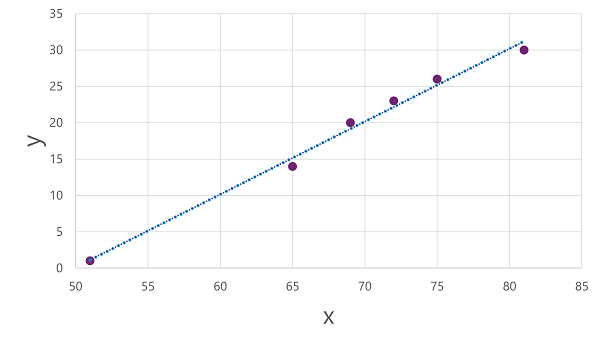
Çizgi, çizginin eğiminin belirli bir x değeri için y değerinin nasıl hesapileceğini açıkladığı işlevin görsel bir gösterimidir. Çizgi x eksenini 50'de durdurur, bu nedenle x 50 olduğunda y 0 olur. Çizimdeki eksen işaretleyicilerinden görebileceğiniz gibi, çizgi eğimleri x ekseni boyunca 5'in her artışı y ekseninde 5 artışla sonuçlanır; dolayısıyla x 55 olduğunda y 5 olur; x 60 olduğunda y 10 olur vb. Belirli bir x değeri için y değerini hesaplamak için işlev yalnızca 50'yi çıkarır; başka bir deyişle işlev şu şekilde ifade edilebilir:
f(x) = x-50
Belirli bir sıcaklıkla bir günde satılan dondurma sayısını tahmin etmek için bu işlevi kullanabilirsiniz. Örneğin, hava tahmininin bize yarının 77 derece olacağını söylediğini varsayalım. Modelimizi uygulayarak 77-50'yi hesaplayabilir ve yarın 27 dondurma satacağımızı tahmin edebiliriz.
Peki modelimiz ne kadar doğru?
Regresyon modelini değerlendirme
Modeli doğrulamak ve ne kadar iyi tahminde bulunduğunu değerlendirmek için etiket (y) değerini bildiğimiz bazı verileri yedekledik. İşte elimizde tuttuğumuz veriler:
| Sıcaklık (x) | Dondurma satışları (y) |
|---|---|
| 52 | 0 |
| 67 | 14 |
| 70 | 23 |
| 73 | 22 |
| Kategori 78 | 26 |
| 83 | 36 |
Modeli kullanarak bu veri kümesindeki her gözlem için özellik (x) değerine göre etiketi tahmin edebilir ve ardından tahmin edilen etiketi (ŷ) bilinen gerçek etiket değeriyle (y) karşılaştırabiliriz.
F(x) = x-50 işlevini kapsülleyen daha önce eğitilen modelin kullanılması aşağıdaki tahminlerle sonuçlanır:
| Sıcaklık (x) | Gerçek satışlar (y) | Tahmin edilen satışlar (ŷ) |
|---|---|---|
| 52 | 0 | 2 |
| 67 | 14 | 17 |
| 70 | 23 | 20 |
| 73 | 22 | 23 |
| Kategori 78 | 26 | 28 |
| 83 | 36 | 33 |
Aşağıdaki gibi özellik değerlerine göre hem tahmin edilenhem de gerçek etiketleri çizebiliriz:
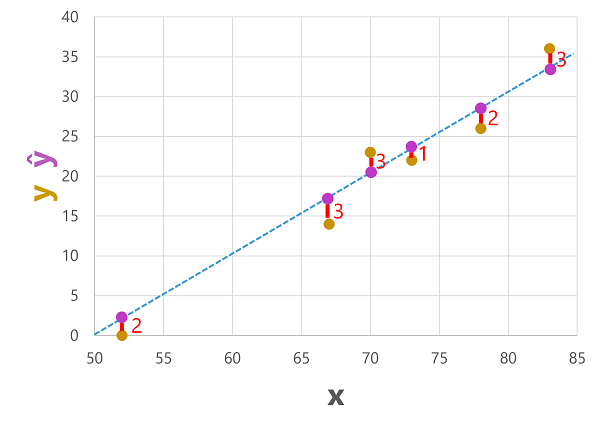
Tahmin edilen etiketler model tarafından hesaplandığından işlev satırındadır, ancak işlev tarafından hesaplanan ŷ değerleri ile doğrulama veri kümesindeki gerçek y değerleri arasında bir fark vardır; çizimde tahminin gerçek değerden ne kadar uzak olduğunu gösteren ŷ ve y değerleri arasında bir çizgi olarak gösterilir.
Regresyon değerlendirme ölçümleri
Tahmin edilen ve gerçek değerler arasındaki farklara bağlı olarak, regresyon modelini değerlendirmek için kullanılan bazı yaygın ölçümleri hesaplayabilirsiniz.
Ortalama Mutlak Hata (MAE)
Bu örnekteki varyans, her tahminde kaç dondurmanın yanlış olduğunu gösterir. Tahminin gerçek değerin üzerinde mi yoksa altında mı olduğu önemli değildir (örneğin, -3 ve +3 değerleri 3'ün varyansını gösterir). Bu ölçüm, her tahmin için mutlak hata olarak bilinir ve doğrulama kümesinin tamamı için ortalama mutlak hata (MAE) olarak özetlenebilir.
Dondurma örneğinde mutlak hataların (2, 3, 3, 1, 2 ve 3) ortalaması (ortalama) 2,33'tür.
Ortalama Kare Hatası (MSE)
Ortalama mutlak hata ölçümü, tahmin edilen ve gerçek etiketler arasındaki tüm tutarsızlıkları eşit olarak dikkate alır. Ancak, az miktarda tutarlı bir şekilde yanlış olan bir modele sahip olmak, daha az ama daha büyük hatalar yapan bir modele sahip olmak daha cazip olabilir. Tek tek hataların karesini oluşturarak ve kare değerlerin ortalamasını hesaplayarak daha büyük hataları "yükselten" bir ölçüm oluşturmanın bir yolu. Bu ölçüm ortalama hata karesi (MSE) olarak bilinir.
Dondurma örneğimizde, kare mutlak değerlerin (4, 9, 9, 1, 4 ve 9) ortalaması 6'dır.
Kök Ortalama Kare Hatası (RMSE)
Ortalama hata karesi hataların büyüklüğünü dikkate almaya yardımcı olur, ancak hata değerlerinin karesini oluşturduğundan, sonuçta elde edilen ölçüm artık etiket tarafından ölçülen miktarı temsil etmemektedir. Başka bir deyişle, modelimizin MSE'sinin 6 olduğunu söyleyebiliriz, ancak bu, yanlış beyan edilen dondurma sayısı açısından doğruluğunu ölçmez; 6, doğrulama tahminlerindeki hata düzeyini gösteren sayısal bir puandır.
Hatayı dondurma sayısı bakımından ölçmek istiyorsak MSE'nin karekökünü hesaplamamız gerekir; bu, şaşırtıcı olmayan bir şekilde Kök Ortalama Kare Hatası adlı bir ölçüm üretir. Bu durumda 2,45 (dondurma) olan √6.
Belirleme katsayısı (R2)
Şimdiye kadarki tüm ölçümler, modeli değerlendirmek için tahmin edilen ve gerçek değerler arasındaki tutarsızlığı karşılaştırır. Ancak gerçekte, modelin dikkate aldığı günlük dondurma satışlarında bazı doğal rastgele varyanslar vardır. Doğrusal regresyon modelinde eğitim algoritması, işlev ile bilinen etiket değerleri arasındaki ortalama varyansı en aza indiren düz bir çizgiye uyar. Belirleme katsayısı (daha yaygın olarak R2 veya R Karesi olarak adlandırılır), doğrulama verilerinin bazı anormal yönlerinin (örneğin, yerel festival nedeniyle son derece sıra dışı sayıda dondurma satışının olduğu bir gün) aksine, model tarafından açıklanabilen doğrulama sonuçlarında varyansın oranını ölçen bir ölçümdür.
R2 hesaplaması önceki ölçümlere göre daha karmaşıktır. Tahmin edilen ve gerçek etiketler arasındaki kare farkların toplamını, gerçek etiket değerleri ile gerçek etiket değerlerinin ortalaması arasındaki kare farkların toplamıyla karşılaştırır, örneğin:
R2 = 1- ∑(y-ŷ)2 ÷ ∑(y-ȳ)2
Karmaşık görünüyorsa çok fazla endişelenmeyin; çoğu makine öğrenmesi aracı ölçümü sizin için hesaplayabilir. Önemli nokta, sonucun model tarafından açıklanan varyansın oranını açıklayan 0 ile 1 arasında bir değer olmasıdır. Basit bir ifadeyle, bu değer 1'e ne kadar yakın olursa, model doğrulama verilerini o kadar iyi sığdırıyor olur. Dondurma regresyon modeli söz konusu olduğunda, doğrulama verilerinden hesaplanan R2 0,95'tir.
Yinelemeli eğitim
Yukarıda açıklanan ölçümler genellikle regresyon modelini değerlendirmek için kullanılır. Gerçek dünya senaryolarının çoğunda, veri bilimcisi bir modeli sürekli olarak eğitmek ve değerlendirmek için yinelemeli bir süreç kullanır ve bunlar değişir:
- Özellik seçimi ve hazırlığı (modele hangi özelliklerin dahil edilmesinin seçildiği ve daha iyi uyum sağlanmasına yardımcı olmak için bunlara uygulanan hesaplamalar).
- Algoritma seçimi (Önceki örnekte doğrusal regresyonu inceledik, ancak başka birçok regresyon algoritması var)
- Algoritma parametreleri (algoritma davranışını denetlemek için sayısal ayarlar, bunları x ve y parametrelerinden ayırt etmek için hiper parametreler olarak daha doğru bir şekilde adlandırılır).
Birden çok yinelemeden sonra, belirli bir senaryo için kabul edilebilir en iyi değerlendirme ölçümüne neden olan model seçilir.