Görüntü transformatörleri ve çok modüllü modeller
Uyarı
Daha fazla ayrıntı için Metin ve resimler sekmesine bakın!
CNN'ler uzun yıllardır görüntü işleme çözümlerinin temelini oluşturur. Bunlar genellikle daha önce açıklandığı gibi görüntü sınıflandırma sorunlarını çözmek için kullanılırken, daha karmaşık görüntü işleme modellerinin de temelini oluşturur. Örneğin, nesne algılama modelleri, aynı görüntüdeki birden çok nesne sınıfını bulmak için CNN özellik ayıklama katmanlarını görüntülerdeki ilgi çekici bölgelerin belirlenmesiyle birleştirir. Onlarca yıldır görüntü işlemede birçok ilerleme, CNN tabanlı modellerde yapılan iyileştirmelerle sağlanmıştır.
Ancak, başka bir yapay zeka uzmanlık alanında - doğal dil işleme (NLP), transformatör olarak adlandırılan başka bir sinir ağı mimarisi türü, dil için gelişmiş modellerin geliştirilmesini sağlamıştır.
Dil için anlamsal modelleme - Transformatörler
Transformatörler, çok büyük hacimlerdeki verileri işleyerek ve dil belirteçlerini (tek tek sözcükleri veya tümcecikleri temsil eden) vektör tabanlı eklemeler (sayısal değer dizileri) olarak kodlayarak çalışır. Dikkat olarak adlandırılan bir teknik, her belirtecin diğer belirteçler bağlamında nasıl kullanıldığının farklı yönlerini yansıtan ekleme değerleri atamak için kullanılır. Yerleştirmeleri, çok boyutlu uzayda yer alan vektörler olarak düşünebilirsiniz; her boyut, eğitim metni bağlamında bir belirtecin dilsel özniteliğini yerleştirir ve belirteçler arasında anlamsal ilişkiler oluşturur. Benzer bağlamlarda yaygın olarak kullanılan belirteçler, ilişkisiz sözcüklere göre daha yakın hizalanmış vektörleri tanımlar.
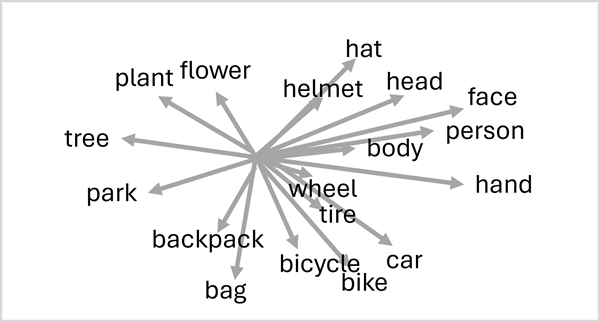
Anlamsal olarak benzer belirteçler benzer yönlerde kodlanır ve metin analizi, çeviri, dil oluşturma ve diğer görevler için gelişmiş NLP çözümleri oluşturmayı mümkün kılan anlamsal bir dil modeli oluşturulur.
Uyarı
Gerçekte transformatör ağlarındaki kodlayıcılar, doğrusal cebirsel hesaplamalar temelinde belirteçler arasında karmaşık anlamsal ilişkiler tanımlayarak çok daha fazla boyuta sahip vektörler oluşturur. Bir transformatör modelinin mimarisi gibi ilgili matematik karmaşıktır. Buradaki amacımız, kodlamanın varlıklar arasındaki ilişkileri kapsülleyen bir model oluşturma şekli hakkında kavramsal bir anlayış sağlamaktır.
Görüntüler için anlamsal model - Görüntü transformatörleri
Dil modelleri oluşturmanın bir yolu olarak transformatörlerin başarısı yapay zeka araştırmacılarının aynı yaklaşımın görüntü verileri için etkili olup olmayacağını düşünmesine neden oldu. Sonuç, bir modelin büyük hacimli görüntüler kullanılarak eğitildiği görüntü transformatörü (ViT) modellerinin geliştirilmesidir. Dönüştürücü, metin tabanlı belirteçleri kodlamak yerine görüntüden piksel değerlerinin düzeltme eklerini ayıklar ve piksel değerlerinden doğrusal bir vektör oluşturur.

Dil modellerinde belirteçler arasındaki bağlamsal ilişkileri eklemek için kullanılan aynı dikkat tekniği, yamalar arasındaki bağlamsal ilişkileri belirlemek için de kullanılır. Temel fark, katıştırılmış vektörlere dilsel özellikleri kodlamak yerine, katıştırılmış değerlerin renk, şekil, karşıtlık, doku vb. görsel özelliklere dayalı olmasıdır. Sonuç, eğitim görüntülerinde yaygın olarak nasıl görüldüklerine bağlı olarak görsel özelliklerin çok boyutlu bir "haritası" oluşturan bir ekleme vektörleri kümesidir.
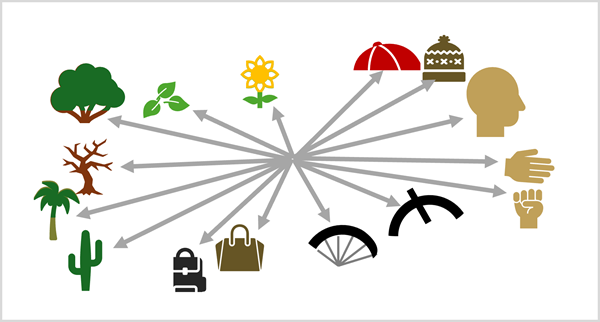
Dil modellerinde olduğu gibi eklemeler de benzer bağlamda kullanılan görsel özelliklerin benzer vektör yol tariflerine atanmasıyla sonuçlanır. Örneğin, şapkada ortak olan görsel özellikler, bir kafada ortak olan görsel özelliklerle bağlamsal olarak ilgili olabilir; çünkü iki şey genellikle birlikte görülür. Modelin "şapka" veya "kafa" ne olduğuna dair anlamına sahip olmadığı olmasına rağmen, görsel özellikler arasında anlamsal bir ilişki çıkarsayabilir.
Hepsini bir araya getirme - Çok modüllü modeller
Dil transformatörü, sözcükler arasındaki anlamsal ilişkileri kodlayan bir dil sözlüğü tanımlayan eklemeler oluşturur. Bir görüntü transformatörü, görsel özellikler için aynı işlemi gösteren görsel bir sözlük oluşturur. Eğitim verileri ilişkili metin açıklamalarına sahip görüntüler içerdiğinde, bu transformatörlerin her ikisinden kodlayıcıları çok modüllü bir modelde birleştirebiliriz; ve eklemelerin birleşik uzamsal gösterimini tanımlamak için çapraz model dikkati adlı bir teknik kullanın.
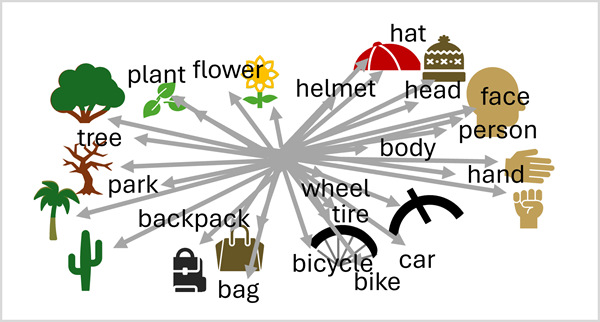
Bu dil ve görüntü ekleme birleşimi, modelin dil ve görsel özellikler arasındaki anlamsal ilişkileri ayırt etmesine olanak tanır. Bu özellik, modelin görsel özellikleri tanıyarak ve paylaşılan vektör alanında ilişkili dil araması yaparak daha önce görmediği görüntülerin karmaşık açıklamalarını tahmin etmelerini sağlar.

Bir parkta şapka ve sırt çantası olan bir kişi