Optik karakter tanıma (OCR)
Uyarı
Daha fazla ayrıntı için Metin ve resimler sekmesine bakın!
Optik Karakter Tanıma (OCR), taranmış belgelerden, fotoğraflardan veya dijital dosyalardan görsel metinleri düzenlenebilir, aranabilir metin verilerine otomatik olarak dönüştüren bir teknolojidir. OCR, bilgileri el ile çevirmek yerine aşağıdakilerden otomatik veri ayıklamayı etkinleştirir:
- Taranan faturalar ve makbuzlar
- Belgelerin dijital fotoğrafları
- Metin resimleri içeren PDF dosyaları
- Ekran görüntüleri ve yakalanan içerik
- Formlar ve el yazısı notlar
OCR işlem hattı: Adım adım bir işlem
OCR işlem hattı, görsel bilgileri metin verilerine dönüştürmek için birlikte çalışan beş temel aşamadan oluşur.
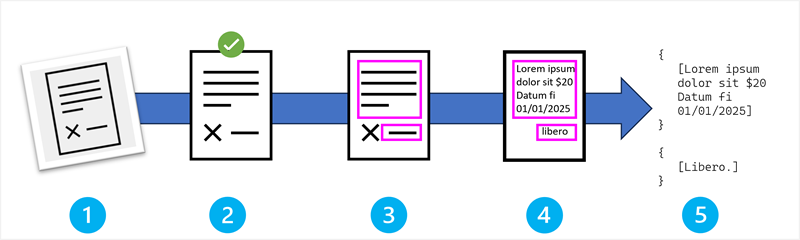
OCR işleminin aşamaları şunlardır:
- Görüntü alma ve giriş.
- Ön işleme ve görüntü geliştirme.
- Metin bölgesi algılama.
- Karakter tanıma ve sınıflandırma.
- Çıktı üretme ve çıktı sonrası işleme.
Şimdi her aşamayı daha ayrıntılı inceleyelim.
1. Aşama: Görüntü alma ve giriş
İşlem hattı, metin içeren bir görüntü sisteme girdiğinde başlar. Bu şu olabilir:
- Akıllı telefon kamerasıyla çekilen bir fotoğraf.
- Düz yataklı veya belge tarayıcısından taranmış bir belge.
- Video akışından ayıklanan bir çerçeve.
- Resim olarak işlenen bir PDF sayfası.
Tip
Bu aşamadaki görüntü kalitesi, metin ayıklamanın son doğruluğunu önemli ölçüde etkiler.
2. Aşama: Ön işleme ve görüntü geliştirme
Metin algılama başlamadan önce, görüntüyü daha iyi tanıma doğruluğu için iyileştirmek için aşağıdaki teknikler kullanılır:
Gürültü azaltma özelliği, metin algılamayı engelleyebilecek görsel yapıtları, toz noktalarını ve tarama kusurlarını ortadan kaldırır. Gürültü azaltmayı gerçekleştirmek için kullanılan belirli teknikler şunlardır:
- Filtreleme ve görüntü işleme algoritmaları: Gauss filtreleri, ortanca filtreler ve morfolojik işlemler.
- Makine öğrenmesi modelleri: Belge görüntüsü temizleme için özel olarak eğitilen gürültü giderici otomatik kodlayıcılar ve konvolüsyonel sinir ağları (CNN).
Karşıtlık ayarı , karakterleri daha belirgin hale getirmek için metin ve arka plan arasındaki farkı artırır. Yine, birden çok olası yaklaşım vardır:
- Klasik yöntemler: Histogram eşitlemesi, uyarlamalı eşik ve gama düzeltmesi.
- Makine öğrenmesi: Farklı belge türleri için en iyi geliştirme parametrelerini öğrenen derin öğrenme modelleri.
Eğme düzeltmesi , belge döndürmeyi algılar ve düzelterek metin çizgilerinin yatay olarak düzgün hizalandığından emin olur. Dengesizlik düzeltme teknikleri şunlardır:
- Matematiksel teknikler: Çizgi algılama, projeksiyon profilleri ve bağlı bileşen analizi için Hough dönüşümü.
- Sinir ağı modelleri: Döndürme açılarını doğrudan görüntü özelliklerinden tahmin eden regresyon CNN'leri.
Çözünürlük iyileştirmesi , görüntü çözünürlüğünü karakter tanıma algoritmaları için en uygun düzeye ayarlar. Görüntü çözünürlüğünü şu şekilde iyileştirebilirsiniz:
- İlişkilendirme yöntemleri: Bikübik, bilinear ve Lanczos yeniden örnekleme algoritmaları.
- Süper çözünürlüklü modeller: Düşük çözünürlüklü metin görüntülerini akıllıca ölçeklendiren üretici karşıt ağlar (GAN'lar) ve kalıntı ağlar.
3. Aşama: Metin bölgesi algılama
Sistem, aşağıdaki teknikleri kullanarak metin içeren alanları belirlemek için önceden işlenmiş görüntüyü analiz eder:
Düzen analizi metin bölgelerini, resimleri, grafikleri ve boşluk alanlarını birbirinden ayırır. Düzen analizi teknikleri şunlardır:
- Geleneksel yaklaşımlar: Bağlı bileşen analizi, çalışma uzunluğu kodlaması ve projeksiyon tabanlı segmentasyon.
- Derin öğrenme modelleri: U-Net, Mask R-CNN gibi anlamsal segmentasyon ağları ve özelleştirilmiş belge düzeni çözümleme modelleri (örneğin, LayoutLM veya PubLayNet tarafından eğitilen modeller).
Metin bloğu tanımlama, tek tek karakterleri uzamsal ilişkilere göre sözcükler, satırlar ve paragraflar halinde gruplandırmaktadır. Yaygın yaklaşımlar şunlardır:
- Klasik yöntemler: Uzaklık tabanlı kümeleme, boşluk analizi ve morfolojik işlemler
- Sinir ağları: Uzamsal belge yapısını anlayan graf sinir ağları ve transformatör modelleri
Okuma sırası belirleme , metnin okunacağı sırayı (İngilizce için soldan sağa, yukarıdan aşağıya) oluşturur. Doğru sıra şu şekilde belirlenebilir:
- Kural tabanlı sistemler: Sınırlayıcı kutu koordinatlarını ve uzamsal buluşsal yöntemleri kullanan geometrik algoritmalar.
- Makine öğrenmesi modelleri: Eğitim verilerinden okuma desenlerini öğrenen sıra tahmin modelleri ve graf tabanlı yaklaşımlar.
Bölge sınıflandırması farklı metin bölgesi türlerini (üst bilgiler, gövde metni, resim yazıları, tablolar) tanımlar.
- Özellik tabanlı sınıflandırıcılar: Yazı tipi boyutu, konum ve biçimlendirme gibi el ile oluşturulmuş özellikleri kullanarak vektör makinelerini (SVM) destekleme
- Derin öğrenme modelleri: Etiketlenmiş belge veri kümelerinde eğitilen kıvrımlı sinir ağları ve görüntü transformatörleri
4. Aşama: Karakter tanıma ve sınıflandırma
Bu, tek tek karakterlerin tanımlandığı OCR işleminin çekirdeğidir:
Özellik ayıklama: Her karakterin veya sembolün şeklini, boyutunu ve ayırt edici özelliklerini analiz eder.
- Geleneksel yöntemler: Anlar, Fourier tanımlayıcıları ve yapısal özellikler (döngüler, uç noktalar, kesişimler) gibi istatistiksel özellikler
- Derin öğrenme yaklaşımları: Ham piksel verilerinden ayrımcı özellikleri otomatik olarak öğrenen kıvrımlı sinir ağları
Desen eşleştirme: Ayıklanan özellikleri farklı yazı tiplerini, boyutları ve yazma stillerini tanıyan eğitilmiş modellerle karşılaştırır.
- Şablon eşleştirme: Bağıntı tekniklerini kullanarak depolanan karakter şablonlarıyla doğrudan karşılaştırma
- İstatistiksel sınıflandırıcılar: Gizli Markov Modelleri (HMM), Destek Vektör Makineleri ve k-en yakın komşular ile özellik vektörlerinin kullanımı
- Sinir ağları: Çok katmanlı algılamalar, CNN'ler ve basamak tanıma için LeNet gibi özel mimariler
- Gelişmiş derin öğrenme: Sağlam karakter sınıflandırması için artık ağlar (ResNet), DenseNet ve EfficientNet mimarileri
Bağlam analizi: Sözlük aramaları ve dil modelleri aracılığıyla tanıma doğruluğunu geliştirmek için çevresindeki karakterleri ve sözcükleri kullanır.
- N-gram modelleri: Olasılık dağılımlarına göre karakter dizilerini tahmin eden istatistiksel dil modelleri.
- Sözlük tabanlı düzeltme: Yazım denetimi için uzaklık algoritmalarını düzenleme ( Levenshtein uzaklığı gibi) ile sözlük araması.
- Nöral dil modelleri: Bağlamsal ilişkileri anlayan LSTM ve transformatör tabanlı modeller (BERT çeşitleri gibi).
- Dikkat mekanizmaları: Karakter tahminleri yaparken girişin ilgili bölümlerine odaklanan transformatör modelleri.
Güvenilirlik puanlaması: Sistemin tanımlamasıyla ilgili olarak ne kadar kesin olduğuna bağlı olarak tanınan her karaktere olasılık puanları atar.
- Bayes yaklaşımları: Karakter tahminlerindeki belirsizliği ölçen olasılıksal modeller.
- Softmax çıkışları: Sinir ağı son katman etkinleştirmeleri olasılık dağılımlarına dönüştürülür.
- Topluluk yöntemleri: Güvenilirlik tahminlerini geliştirmek için birden çok modelden gelen tahminleri birleştirme.
5. Aşama: Çıktı oluşturma ve işleme sonrası
Son aşama, tanıma sonuçlarını kullanılabilir metin verilerine dönüştürür:
Metin derleme: Tek tek karakter tanımalarını tam sözcükler ve cümleler halinde birleştirir.
- Kural tabanlı derleme: Uzamsal yakınlık ve güvenilirlik eşiklerini kullanarak karakter tahminlerini birleştiren belirlenimci algoritmalar.
- Sıralı modeller: Metni sıralı veri olarak modelleyen yinelenen sinir ağları (RNN) ve Uzun Short-Term Bellek (LSTM) ağları.
- Dikkate dayalı modeller: Değişken uzunlukta dizileri ve karmaşık metin düzenlerini işleyebilen Transformatör mimarileri.
Biçim koruma: Paragraflar, satır sonları ve aralıklar dahil olmak üzere belge yapısını korur.
- Geometrik algoritmalar: Sınırlayıcı kutu koordinatlarını ve boşluk analizini kullanan kural tabanlı sistemler.
- Düzen anlama modelleri: Grafik sinir ağları ve yapısal ilişkileri öğrenen belgelerde kullanılan yapay zeka modelleri.
- Çok modali transformatörler: Yapı koruması için metin ve düzen bilgilerini birleştiren LayoutLM gibi modeller.
Koordinat eşlemesi: Özgün görüntüdeki her metin öğesinin tam konumunu kaydeder.
- Koordinat dönüşümü: Görüntü pikselleri ile belge koordinatları arasında matematiksel eşleme.
- Uzamsal dizin oluşturma: Verimli uzamsal sorgular için R ağaçları ve dörtlü ağaçlar gibi veri yapıları.
- Regresyon modelleri: Hassas metin konumlandırma koordinatlarını tahmin etmek için eğitilen sinir ağları.
Kalite doğrulaması: Olası tanıma hatalarını belirlemek için yazım ve dil bilgisi denetimleri uygular.
- Sözlük tabanlı doğrulama: Kapsamlı sözcük listelerine ve özel etki alanı sözlüklerine göre arama yapın.
- İstatistiksel dil modelleri: Dil bilgisi ve bağlam doğrulaması için N-gram modelleri ve olasılık ayrıştırıcıları.
- Sinir dili modelleri: OCR hata algılama ve düzeltmesi için GPT veya BERT gibi önceden eğitilmiş modeller.
- Grup doğrulama: Hata algılama doğruluğunu geliştirmek için birden çok doğrulama yaklaşımını birleştirme.