Anlamsal dil modelleri
Uyarı
Daha fazla ayrıntı için Metin ve resimler sekmesine bakın!
NLP için son teknolojinin ilerlemesi nedeniyle belirteçler arasındaki semantik ilişkiyi kapsülleyen modelleri eğitebilme özelliği güçlü derin öğrenme dil modellerinin ortaya çıkmasına yol açmıştır. Bu modellerin merkezinde, dil belirteçlerinin ekleme olarak bilinen vektörler (çok değerli sayı dizileri) olarak kodlanması yer alır.
Metin modellemeye yönelik vektör tabanlı bu yaklaşım, metin belirteçlerinin birden çok boyuta sahip yoğun vektörler olarak gösterildiği Word2Vec ve GloVe gibi tekniklerle yaygınlaştı. Model eğitimi sırasında boyut değerleri, eğitim metnindeki kullanımlarına göre her belirtecin anlamsal özelliklerini yansıtacak şekilde atanır. Daha sonra vektörler arasındaki matematiksel ilişkiler, yaygın metin çözümleme görevlerinin eski tamamen istatistiksel tekniklere göre daha verimli bir şekilde gerçekleştirilmesi için kullanılabilir. Bu yaklaşımda daha yeni bir ilerleme, bağlam içindeki her belirteci dikkate almak ve etrafındaki belirteçlerin etkisini hesaplamak için dikkat olarak adlandırılan bir teknik kullanmaktır. GpT model ailesinde bulunanlar gibi sonuçta elde edilen bağlamsal eklemeler, modern üretken yapay zekanın temelini sağlar.
Metni vektör olarak temsil etme
Vektörler, birden çok eksen boyunca koordinatlarla tanımlanan çok boyutlu alanda noktaları temsil eder. Her vektör bir yönü ve kaynaktan uzaklığı açıklar. Anlamca benzer belirteçler, benzer yönlendirmeye sahip vektörler oluşturmalı – yani, aynı yöne işaret etmelidirler.
Örneğin, bazı yaygın sözcükler için aşağıdaki üç boyutlu eklemeleri göz önünde bulundurun:
| Kelime | Vector |
|---|---|
dog |
[0.8, 0.6, 0.1] |
puppy |
[0.9, 0.7, 0.4] |
cat |
[0.7, 0.5, 0.2] |
kitten |
[0.8, 0.6, 0.5] |
young |
[0.1, 0.1, 0.3] |
ball |
[0.3, 0.9, 0.1] |
tree |
[0.2, 0.1, 0.9] |
Bu vektörleri burada gösterildiği gibi üç boyutlu alanda görselleştirebiliriz:

"dog" ve "cat" vektörleri benzerdir (her ikisi de evcil hayvan), ayrıca "puppy" ve "kitten" de benzerdir (her ikisi genç hayvandır). , "tree"ve "young" sözcükleri ball"farklı anlam anlamlarını yansıtan farklı vektör yönlendirmelerine sahiptir.
Vektörlerde kodlanan anlamsal özellik, sözcükleri karşılaştıran ve analitik karşılaştırmaları etkinleştiren vektör tabanlı işlemlerin kullanılmasını mümkün kılar.
İlgili terimleri bulma
Vektörlerin yönü boyut değerlerine göre belirlendiğinden, benzer anlam anlamlarına sahip sözcükler benzer yönlendirmelere sahip olma eğilimindedir. Bu, anlamlı karşılaştırmalar yapmak için vektörler arasındaki kosinüs benzerliği gibi hesaplamaları kullanabileceğiniz anlamına gelir.
Örneğin, "dog", "cat" ve "tree" arasındaki "uyumsuz" öğeyi belirlemek için vektör çiftleri arasındaki kosinüs benzerliğini hesaplayabilirsiniz. Kosinüs benzerliği şu şekilde hesaplanır:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
Burada A · B nokta çarpımı ve ||A|| A vektörünün büyüklüğüdür.
Üç sözcük arasındaki benzerlikleri hesaplama:
dog[0.8, 0.6, 0.1] vecat[0.7, 0.5, 0.2]:- Noktalı ürün: (0,8 × 0,7) + (0,6 × 0,5) + (0,1 × 0,2) = 0,56 + 0,30 + 0,02 = 0,88
-
dog'nin büyüklüğü: √(0,8² + 0,6² + 0,1²) = √(0,64 + 0,36 + 0,01) = √1,01 ≈ 1,005 -
catBüyüklük: √(0,7² + 0,5² + 0,2²) = √(0,49 + 0,25 + 0,04) = √0,78 ≈ 0,883 - Kosinüs benzerliği: 0,88 / (1,005 × 0,883) ≈ 0,992 (yüksek benzerlik)
dog[0.8, 0.6, 0.1] vetree[0.2, 0.1, 0.9]:- Noktalı ürün: (0,8 × 0,2) + (0,6 × 0,1) + (0,1 × 0,9) = 0,16 + 0,06 + 0,09 = 0,31
- Büyüklük
tree: √(0,2² + 0,1² + 0,9²) = √(0,04 + 0,01 + 0,81) = √0,86 ≈ 0,927 - Kosinüs benzerliği: 0,31 / (1,005 × 0,927) ≈ 0,333 (düşük benzerlik)
cat[0.7, 0.5, 0.2] vetree[0.2, 0.1, 0.9]:- Noktalı ürün: (0,7 × 0,2) + (0,5 × 0,1) + (0,2 × 0,9) = 0,14 + 0,05 + 0,18 = 0,37
- Kosinüs benzerliği: 0,37 / (0,883 × 0,927) ≈ 0,452 (düşük benzerlik)
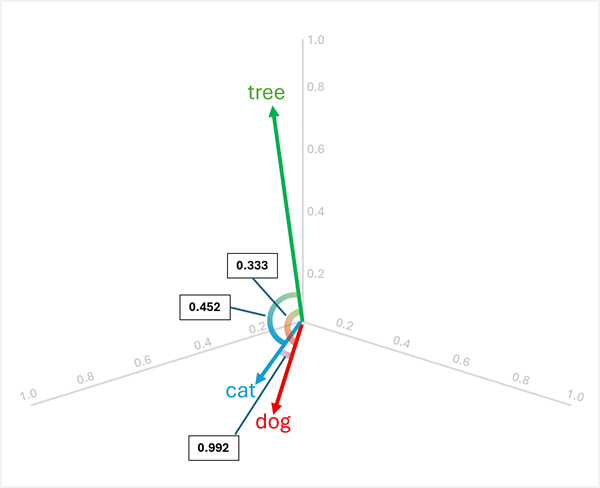
Sonuçlar, "dog" ve "cat"'nin son derece benzer olduğunu (0,992) gösterirken, "tree"'nin hem "dog" (0,333) hem de "cat" (0,452) ile daha düşük benzerlik gösterdiğini ortaya koymaktadır. Bu nedenle, tree açıkça aykırı olan.
Toplama ve çıkarma yoluyla vektör çevirisi
Vektör tabanlı yeni sonuçlar üretmek için vektör ekleyebilir veya çıkarabilirsiniz; daha sonra eşleşen vektörlere sahip belirteçleri bulmak için kullanılabilir. Bu teknik, dil ilişkilerine dayalı uygun terimleri belirlemek için sezgisel aritmetik tabanlı mantık sağlar.
Örneğin, daha önceki vektörleri kullanarak:
-
dog+young= [0,8, 0,6, 0,1] + [0,1, 0,1, 0,3] = [0,9, 0,7, 0,4] =puppy -
cat+young= [0,7, 0,5, 0,2] + [0,1, 0,1, 0,3] = [0,8, 0,6, 0,5] =kitten
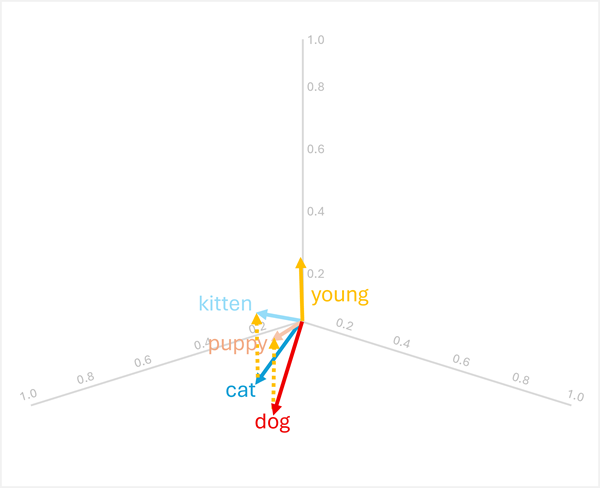
Bu işlemler işe yaramaktadır çünkü vektör, "young" yetişkin bir hayvandan genç karşılığına semantik dönüşümü kodlar.
Uyarı
Pratikte vektör aritmetiği nadiren tam eşleşmeler üretir; bunun yerine, vektör sonucuna en yakın (en benzer) sözcüğünü ararsınız.
Aritmetik de ters çalışır:
-
puppy-young= [0,9, 0,7, 0,4] - [0,1, 0,1, 0,3] = [0,8, 0,6, 0,1] =dog -
kitten-young= [0,8, 0,6, 0,5] - [0,1, 0,1, 0,3] = [0,7, 0,5, 0,2] =cat
Analog mantık
Vektör aritmetiği ayrıca "puppy'nin dog'ye olduğu gibi, kitten'nin 'ye olup olmadığını" gibi benzetme sorularını yanıtlayabilir.
Bunu çözmek için şunları hesaplayın: kitten - puppy + dog
- [0.8, 0.6, 0.5] - [0.9, 0.7, 0.4] + [0.8, 0.6, 0.1]
- = [-0.1, -0.1, 0.1] + [0.8, 0.6, 0.1]
- = [0,7, 0,5, 0,2]
- =
cat
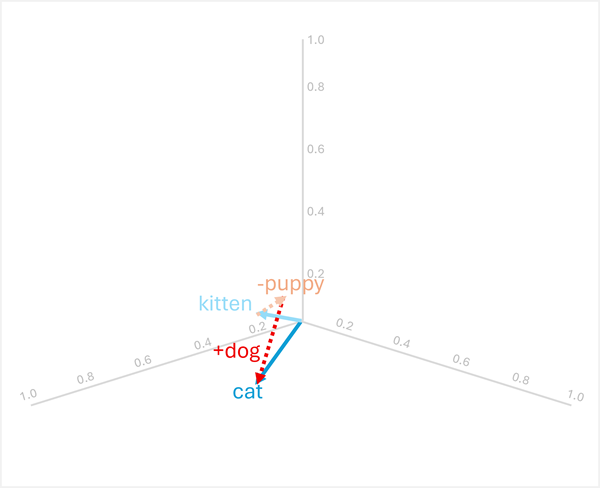
Bu örnekler, vektör işlemlerinin dil ilişkilerini nasıl yakalayabileceğini ve anlamsal desenler hakkında akıl yürütmeyi nasıl etkinleştirebileceğini gösterir.
Metin analizi için anlamsal modelleri kullanma
Vektör tabanlı anlam modelleri, birçok yaygın metin analizi görevi için güçlü özellikler sağlar.
Metin özetleme
Anlamsal eklemeler, tümceleri belgenin genelini en çok temsil eden vektörlerle tanımlayarak ayıklayıcı özetleme sağlar. Her tümceyi bir vektör olarak kodlayarak (genellikle bir araya gelen sözcüklerin eklemelerini ortalama veya havuza alarak), belgenin anlamının en merkezi olan cümleleri hesaplayabilirsiniz. Bu merkezi cümleler, önemli temaları yakalayan bir özet oluşturmak için ayıklanabilir.
Anahtar kelime çıkarma
Vektör benzerliği, her sözcüğün eklemesini belgenin genel anlamsal gösterimiyle karşılaştırarak belgedeki en önemli terimleri tanımlayabilir. Vektörleri belge vektörlerine en çok benzeyen veya belgedeki tüm sözcük vektörleri dikkate alındığında en merkezi olan sözcükler, büyük olasılıkla ana konuları temsil eden önemli terimlerdir.
Adlandırılmış varlık tanıma
Anlamsal modeller, benzer varlık türlerini birlikte kümeleyen vektör gösterimlerini öğrenerek adlandırılmış varlıkları (kişiler, kuruluşlar, konumlar vb.) tanıyacak şekilde ince ayarlanabilir. Çıkarım sırasında model, her belirtecin eklemesini ve bağlamını inceleyerek adlandırılmış bir varlığı ve varsa hangi türü temsil edip etmediğini belirler.
Metin sınıflandırması
Yaklaşım analizi veya konu kategorisi gibi görevler için, belgeler toplama vektörleri (belgedeki tüm sözcük eklemelerinin ortalaması gibi) olarak gösterilebilir. Bu belge vektörleri daha sonra makine öğrenmesi sınıflandırıcıları için özellik olarak kullanılabilir veya kategorileri atamak için doğrudan sınıf prototip vektörleriyle karşılaştırılabilir. Benzer belgelerde benzer vektör yönlendirmeleri olduğundan, bu yaklaşım ilgili içeriği etkili bir şekilde gruplandırır ve farklı kategorileri ayırt eder.