Azure Machine Learning ile özel yapay zeka modelleri oluşturma
Gelişmiş yapay zeka modellerinin kullanılabilirliği, kuruluşların bir veri bilimi projesinin gerektirebileceği göz korkutucu kaynak miktarını önemli ölçüde azaltmaya yardımcı olabilir. Şimdi kuruluşların Azure Machine Learning ile makine öğrenmesi zorluklarının ve işlemlerinin üstesinden nasıl gelebileceğini görelim.
Makine öğrenmesi zorlukları ve makine öğrenmesi işlemleri
Yapay zeka çözümlerinin korunması için genellikle verilerin, kodun, model ortamlarının ve makine öğrenmesi modellerinin kendilerinin belgelenmesi ve yönetilmesi için makine öğrenmesi yaşam döngüsü yönetimi gerekir. Modelleri geliştirmek, paketlemek ve dağıtmak, performanslarını izlemek ve zaman zaman yeniden eğitmek için süreçler oluşturmanız gerekir. Üstelik çoğu kuruluş aynı anda birden fazla modeli üretim aşamasına geçirdiğinden sürecin karmaşıklığını daha da artırmaktadır.
Bu karmaşıklık ile etkili bir şekilde başa çıkmak için bazı en iyi yöntemler gereklidir. Ekipler arası işbirliğine, süreçleri otomatikleştirmeye ve standartlaştırmaya ve modellerin kolayca denetlenmesini, açıklanabilmesini ve yeniden kullanılmasını sağlamaya odaklanır. Bunu yapmak için veri bilimi ekipleri makine öğrenmesi işlemleri yaklaşımını kullanır. Bu metodoloji, geliştiricilerin ve veri bilim insanlarının mücadeleleri benzer olduğundan, uygulama geliştirme döngüsü için operasyonları yönetmeye yönelik endüstri standardı olan DevOps'tan (geliştirme ve operasyonlar) esinlenilmiştir.
Azure Machine Learning
Veri bilimciler, makine öğrenmesi yaşam döngüsü yönetimi ve operasyon uygulamalarını kolaylaştırmak için Microsoft'un bir platformu olan Azure Machine Learning'den makine öğrenmesi DevOps'u yönetebilir ve yürütebilir. Bu tür araçlar, ekiplerin otomasyon aracılığıyla birçok işlemin iyileştirilebildiği paylaşılan, denetlenebilir ve güvenli bir ortamda işbirliği yapmasına yardımcı olur.
Makine öğrenmesi yaşam döngüsü yönetimi
Azure Machine Learning, önceden eğitilmiş ve özel modellerin uçtan uca makine öğrenmesi yaşam döngüsü yönetimini destekler. Tipik yaşam döngüsü şu adımları içerir: veri hazırlama, model eğitimi, model paketleme, model doğrulama, model dağıtımı, model izleme ve yeniden eğitme.
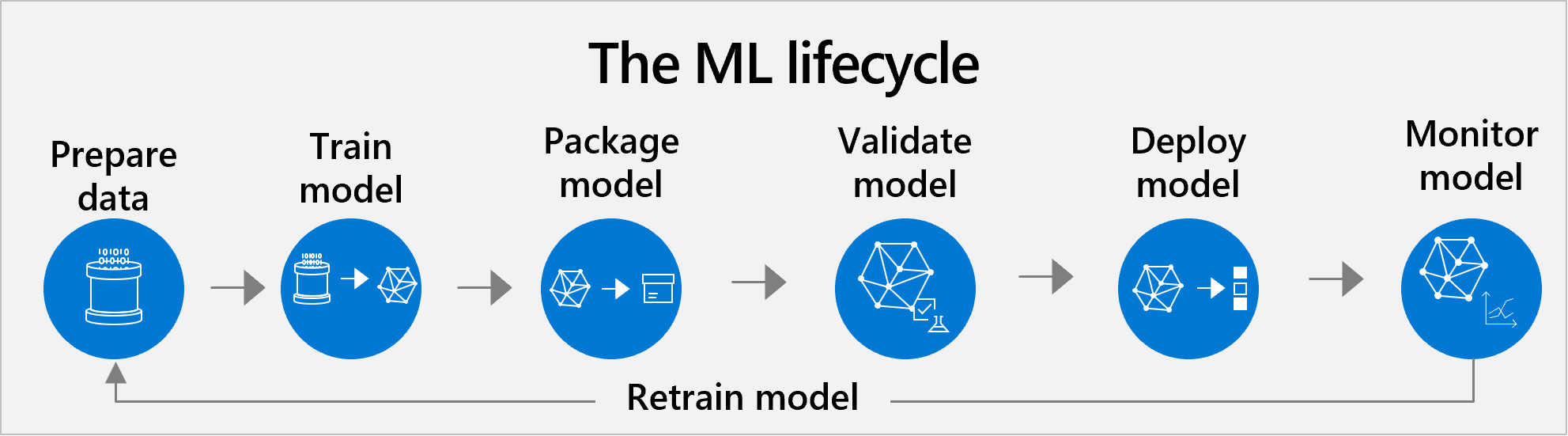
Klasik yaklaşım, bir veri bilimi projesinin tüm olağan adımlarını kapsar.
- Veri kümesini hazırlama. Yapay zeka verilerle başlar. İlk olarak, veri bilimciler modeli eğitecek verileri hazırlamaları gerekir. Veri hazırlama genellikle yaşam döngüsündeki en büyük zaman taahhüdüdür. Bu görev, kendi veri kümenizi bulmayı veya derlemeyi ve makineler tarafından kolayca okunabilmesi için temizlemeyi içerir. Verilerin temsili bir örnek olduğundan, değişkenlerinizin hedefinize uygun olduğundan ve bu şekilde devam ettiğinden emin olmak istiyorsunuz.
- Eğit ve test et. Daha sonra veri bilimciler, makine öğrenmesi modelini eğitmek için verilere algoritmalar uygular. Sonrasında bu model yeni verilerle test edilerek tahminlerin ne kadar isabetli olduğuna bakılır.
- Paket. Model bir uygulamaya doğrudan yerleştirilemiyor. Kapsayıcılı olması gerekir, böylece yerleşik tüm araçlar ve çerçevelerle çalışabilir.
-
Doğrula'yı seçin. Bu noktada ekip, modelin performansının iş hedeflerine kıyasla ne durumda olduğunu değerlendirir. Test yeterince iyi ölçümler döndürebilir, ancak yine de model gerçek bir iş senaryosunda kullanıldığında beklendiği gibi çalışmayabilir.
- 1-4 arası adımları yineleyin. Tatmin edici bir modele ulaşmak için yüzlerce saat eğitim yapılması gerekebilir. Geliştirme ekibi eğitim verilerini ayarlayarak, algoritma hiper parametreleri ayarlayarak veya farklı algoritmaları deneyerek modelin birçok sürümünü eğitebilir. İdeal bir senaryoda her ayarlamadan sonra daha iyi bir model elde edilir. Gelinen noktada modelin iş kullanım örneğine en uygun olan sürümünü belirlemek geliştirme ekibinin görevidir.
- Dağıtma. Son olarak modeli dağıtırlar. Dağıtım seçenekleri şunlardır: bulutta, şirket içi sunucuda ve kameralar, IoT ağ geçitleri veya makineler gibi cihazlarda.
- İzleme ve yeniden eğitme. Başlangıçta iyi çalışan modellerin dahi sürekli izlenmesi, konuyla olan ilgisinin ve doğruluk düzeyinin korunması için yeniden eğitilmesi gerekir.
Not
Önceden eğitilmiş modelleri tümleştirmek ve bunları iş gereksinimlerinize uyarlamak için özel modelleri tümleştiren farklı bir iş akışı gerekir. Azure Machine Learning'i kullanarak önceden eğitilmiş modelleri kullanabilir veya kendi modellerinizi oluşturabilirsiniz. Bir yaklaşımı başka bir yaklaşıma göre seçmek senaryoya bağlıdır. Önceden eğitilmiş modellerle çalışmak, daha az kaynak gerektirme ve sonuçları daha hızlı sunma avantajına sahiptir. Ancak, önceden oluşturulmuş modeller çok çeşitli kullanım örneklerini çözmek için eğitilir, bu nedenle çok özel ihtiyaçları karşılamakta zorlanabilirler. Bu gibi durumlarda, tam bir özel model daha iyi bir fikir olabilir. Her iki yaklaşımın esnek bir karışımı genellikle tercih edilir ve ölçeklendirmeye yardımcı olur. Yapay zeka ekipleri, en kolay kullanım örnekleri için önceden eğitilmiş modelleri kullanarak kaynak tasarrufu sağlarken, bu kaynakları en zor senaryolar için özel yapay zeka modelleri oluşturmaya yatırım yapabilir. Daha fazla yineleme, önceden oluşturulmuş modelleri yeniden eğiterek geliştirebilir.
Makine öğrenmesi işlemleri
Makine öğrenmesi işlemleri (MLOps), makine öğrenmesi yaşam döngüsünü daha verimli bir şekilde yönetmek için DevOps (geliştirme ve operasyonlar) metodolojisini uygular. Tüm paydaşlar arasında yapay zeka ekiplerinde daha çevik ve üretken bir işbirliği sağlar. Bu işbirliğiler veri bilimciler, yapay zeka mühendisleri, uygulama geliştiricileri ve diğer BT ekiplerini kapsar.
MLOps süreçleri ve araçları ekiplerin işbirliği yapmasını sağlar ve paylaşılan, denetlenebilir belgeler sayesinde görünürlük sunar. MLOps teknolojileri, kullanıcıların veri, kod, model ve diğer araçlar gibi tüm kaynaklarda yapılan değişiklikleri kaydetmesine ve izlemesine olanak tanır. Bu teknolojiler ayrıca otomasyon, yinelenebilir iş akışları ve yeniden kullanılabilir varlıklar sayesinde verimlilik sunar ve yaşam döngüsünü hızlandırır. Tüm bu uygulamalar yapay zeka projelerini daha çevik ve verimli hale getirir.
Azure Machine Learning aşağıdaki MLOps uygulamalarını destekler:
Model yeniden üretilebilirliği: Farklı ekip üyelerinin modelleri aynı veri kümesinde çalıştırabileceği ve benzer sonuçlar alabildiği anlamına gelir. Üretimdeki modellerin sonuçlarını güvenilir hale getirmek için yeniden üretilebilirlik kritik öneme sahiptir. Azure Machine Learning; ortamlar, kod, veri kümeleri, modeller ve makine öğrenmesi işlem hatları gibi varlıkları merkezi olarak yöneterek model yeniden üretilebilirliğini destekler.
Model doğrulama: Bir model dağıtılmadan önce performans ölçümlerini doğrulamak kritik önem taşır. "En iyi" modeli belirtmek için kullanılan birden çok ölçüme sahip olabilirsiniz. Performans ölçümlerini iş kullanım örneğiyle ilgili yollarla doğrulamak kritik önem taşır. Azure Machine Learning, kayıp işlevleri ve karışıklık matrisleri gibi model ölçümlerini değerlendirmek için birçok araçla model doğrulamayı destekler.
Model dağıtımı: Bir model dağıtıldığında en iyi dağıtım seçeneğini belirlemek için veri bilimciler ile yapay zeka mühendislerinin birlikte çalışması önemlidir. Bu seçenekler arasında bulut, şirket içi ve uç cihazlar (kameralar, insansız hava araçları, makineler) bulunur.
Model yeniden eğitme: Performans sorunlarını düzeltmek ve daha yeni eğitim verilerinden yararlanmak için modellerin izlenmesi ve düzenli aralıklarla yeniden eğitilmesi gerekir. Azure Machine Learning, modelin doğruluğunu sürekli iyileştirmek ve güvence altına almak için sistematik ve yinelemeli bir süreci destekler.
İpucu

Müşteri hikayesi: Bir sağlık kuruluşu, cerrahi prosedürler sırasında komplikasyon olasılığını tahmin eden özel makine öğrenmesi modelleri eğitmek için Azure Machine Learning'i kullanır. Modeller yaş, etnik köken, sigara içme tarihi, vücut kitle indeksi ve kan platelet sayısı gibi faktörler de dahil olmak üzere çok büyük hacimli veriler üzerinde eğitilir. Bu modellerin kullanılması, tıbbi uzmanların riski daha iyi değerlendirmesine ve bireysel hastalar için ameliyat veya yaşam tarzı değişikliği önerileri seçeneklerini belirlemesine olanak tanır. Azure Machine Learning'deki sorumlu yapay zeka panosu, tahmine dayalı faktörleri açıklamaya ve demografik faktörlerden sapmayı azaltmaya yardımcı olur. Sonuç olarak, tahmine dayalı modelleme çözümü riski ve belirsizliği azaltmaya ve cerrahi sonuçları iyileştirmeye yardımcı olur. Müşteri hikayesinin tamamını burada okuyun: https://aka.ms/azure-ml-customer-story.
İpucu
Kuruluşunuzun özel modeller oluşturmak için veri bilimi ve makine öğrenmesi uzmanlığını nasıl kullanabileceğini düşünmek için bir dakikanızı ayırın.

Şimdi bilgi kontrolüyle her şeyi toparlayalım.