Karışıklık matrisleri
Verileri sürekli, kategorik veya sıralı (kategorik ancak sıralı) olarak düşünebilirsiniz. Karışıklık matrisleri, kategorik modelin performansını değerlendirmenin bir aracıdır. Bunların nasıl çalıştığına ilişkin bağlam için öncelikle sürekli veriler hakkındaki bilgilerimizi yenileyelim. Bu şekilde karışıklık matrislerinin zaten bildiğimiz histogramların bir uzantısı olduğunu görebiliriz.
Sürekli veri dağıtımları
Sürekli verileri anlamak istediğimizde, ilk adım genellikle nasıl dağıtıldığını görmektir. Aşağıdaki histogramı göz önünde bulundurun:
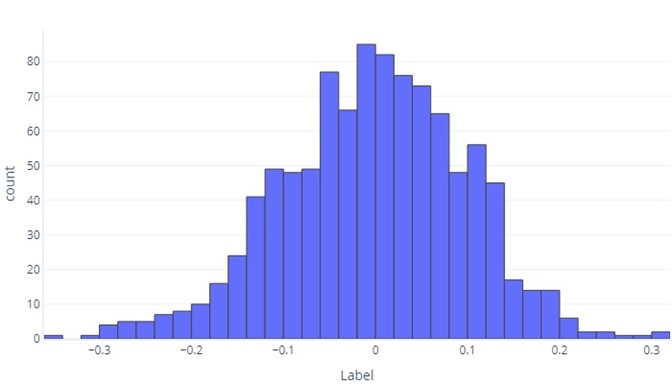
Etiketin ortalama olarak sıfır olduğunu ve çoğu veri noktasının -1 ile 1 arasında olduğunu görebiliriz. Simetrik olarak görünür; ortalamadan daha küçük ve daha büyük sayıların yaklaşık eşit sayısı vardır. İsteseydik, histogram yerine tablo kullanabilirdik, ancak bu çok kolay olmayabilir.
Kategorik veri dağıtımları
Bazı açılardan kategorik veriler sürekli verilerden çok farklı değildir. Her etiket için sık kullanılan değerlerin nasıl göründüğünü değerlendirmek için histogramlar üretmeye devam edebiliriz. Örneğin, bir ikili etiket (true/false) şu sıklıkta görünebilir:
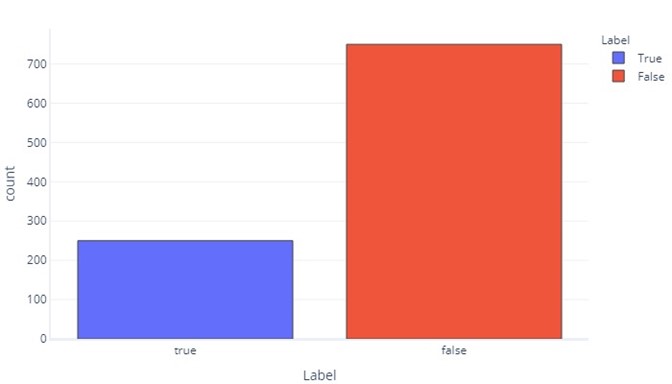
Bu bize etiket olarak "false" içeren 750 örnek ve etiket olarak "true" ile 250 örnek olduğunu bildirir.
Üç kategori için bir etiket benzerdir:
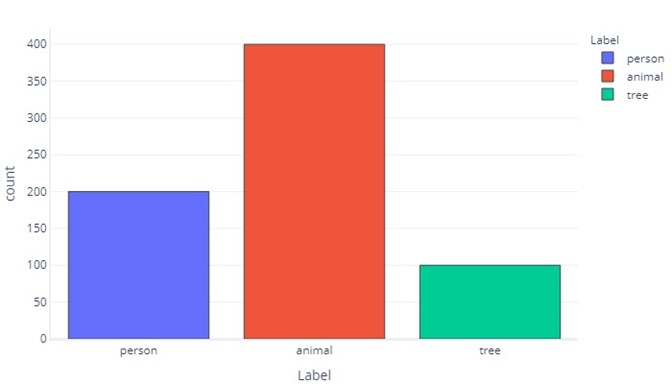
Bu, "kişi" olan 200, "hayvan" olan 400 ve "ağaç" olan 100 örnek olduğunu bildirir.
Kategorik etiketler daha basit olduğundan, bunları genellikle basit tablolar olarak gösterebiliriz. Yukarıdaki iki grafik şöyle görünür:
| Etiket | False | Doğru |
|---|---|---|
| Sayı | 750 | 250 |
Ve:
| Etiket | Kişi | Hayvan | Ağaç |
|---|---|---|---|
| Sayı | 200 | 400 | Kategori 100 |
Tahminlere bakma
Modelin yaptığı tahminlere verilerimizdeki temel gerçeklik etiketlerine baktığımız gibi bakabiliriz. Örneğin, test kümesinde modelimizin 700 kez "false" ve 300 kez "true" tahmininde bulunduğunu görebiliriz.
| Model Tahmini | Sayı |
|---|---|
| False | 700 |
| Doğru | 300 |
Bu, modelimizin yaptığı tahminler hakkında doğrudan bilgi sağlar, ancak bunların hangilerinin doğru olduğunu bize göstermez. Doğru yanıtların ne sıklıkta verildiğini anlamak için maliyet işlevini kullanabiliriz ancak maliyet işlevi hangi tür hataların yapıldığını bize söylemez. Örneğin, model tüm "true" değerlerini doğru tahmin edebilir, ancak aynı zamanda "false" tahmin etmesi gerektiğinde "true" değerini de tahmin edebilir.
Karışıklık matrisi
Model performansını anlamanın anahtarı, model tahmini tablosunu temel gerçeklik veri etiketleri tablosuyla birleştirmektir:
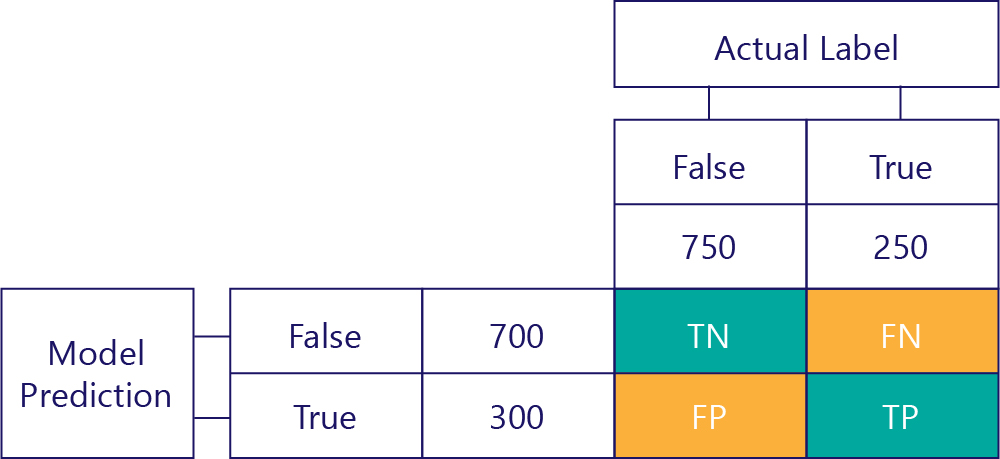
Doldurmadığımız kareye karışıklık matrisi adı verilir.
Karışıklık matrisindeki her hücre, modelin performansı hakkında bize bir şey söyler. Bunlar Gerçek Negatifler (TN), Hatalı Negatifler (FN), Hatalı Pozitifler (FP) ve Doğru Pozitifler (TP) değerleridir.
Şimdi bunları tek tek açıklayalım ve bu kısaltmaları gerçek değerlerle değiştirelim. Mavi-yeşil kareler, modelin doğru tahminde bulunup, turuncu kareler ise modelin yanlış tahmin yaptığı anlamına gelir.
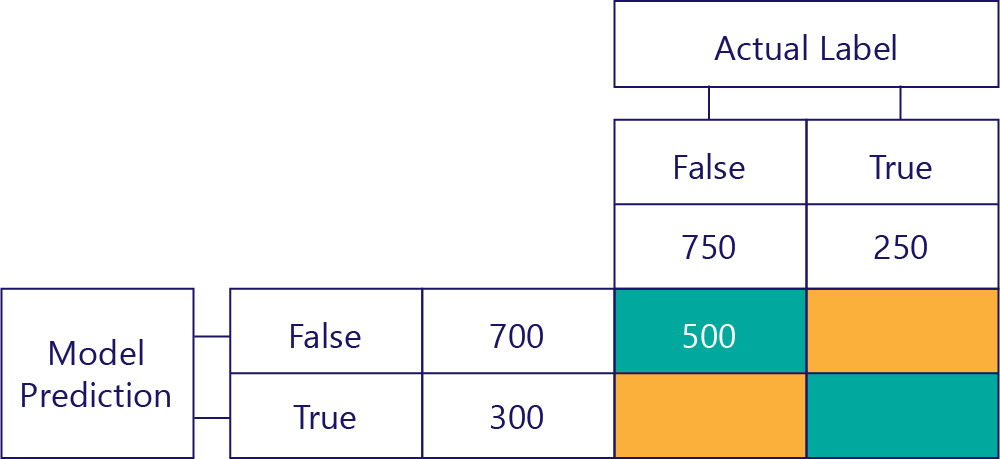
Gerçek Negatifler (TN)
Sol üstteki değer, modelin kaç kez false tahmininde bulundu ve gerçek etiketin de false olduğunu listeler. Başka bir deyişle bu, modelin kaç kez yanlış tahminde bulunduğunu listeler. Örneğin, bunun 500 kez gerçekleştiğini düşünelim:
Hatalı Negatifler (FN)
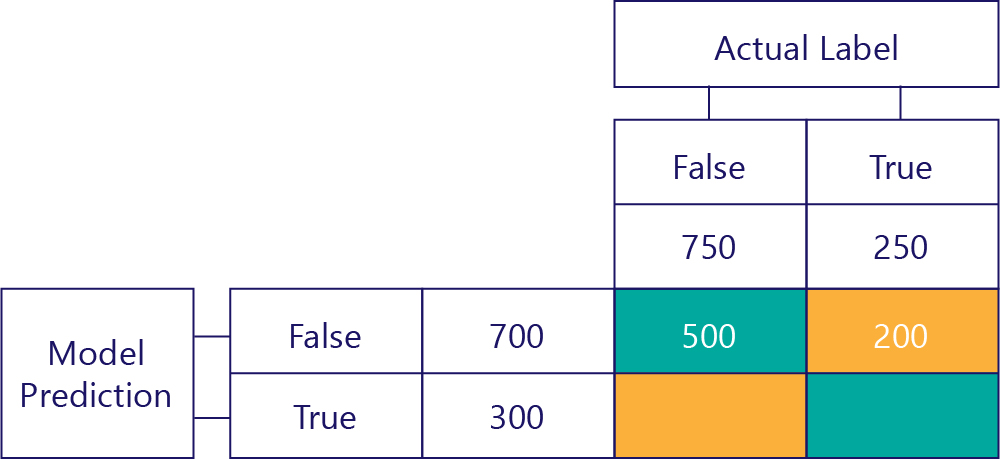
Sağ üstteki değer, modelin kaç kez false tahmininde bulunduysa da gerçek etiketin doğru olduğunu bildirir. Bunun 200 olduğunu biliyoruz. Nasıl? Çünkü model false değerini 700 kez ve 500 kez doğru tahmin etti. Bu nedenle, 200 kez yanlış tahmin etmesi gerekirken tahmin etmemelidir.
Hatalı Pozitifler (FP)
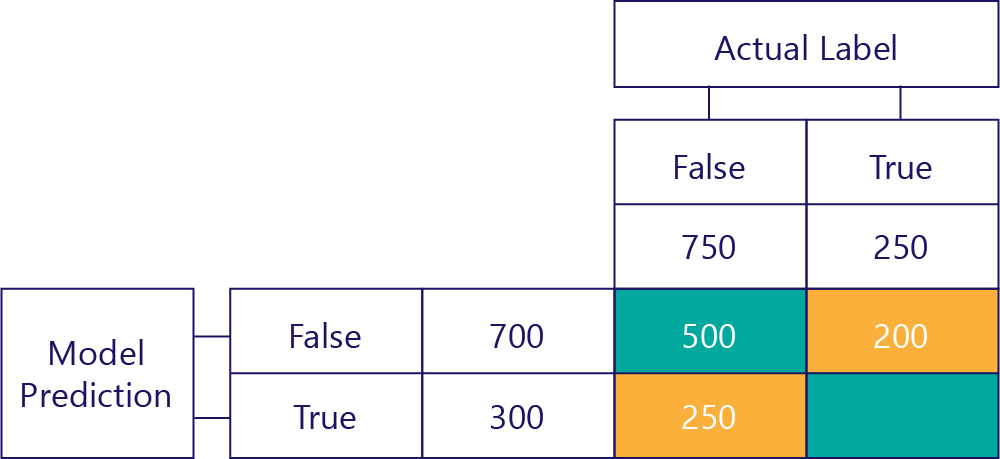
Sol alttaki değer hatalı pozitif değerleri barındırıyor. Bu, modelin kaç kez doğru tahminde bulunurken gerçek etiketin false olduğunu gösterir. Bunun 250 olduğunu biliyoruz, çünkü doğru yanıtın 750 kez yanlış olduğunu biliyoruz. Bu sürelerin 500'i sol üst hücrede (TN) görünür:
Gerçek Pozitifler (TP)
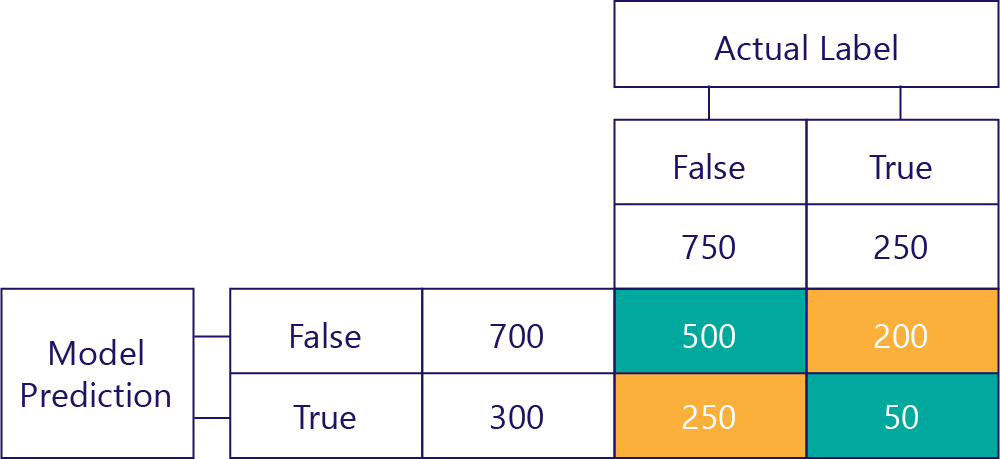
Son olarak, gerçek pozitifler elde ettik. Bu, modelin true değerini doğru tahmin etme sayısıdır. Bunun iki nedenden dolayı 50 olduğunu biliyoruz. İlk olarak, model 300 kez doğru tahmin etti, ancak 250 kez yanlıştı (sol alt hücre). İkinci olarak, true değerinin doğru yanıt olduğunu 250 kez, ancak modelin 200 katı false tahmini yaptı.
Son matris
Normalde karışıklık matrisimizi biraz basitleştiririz, örneğin:
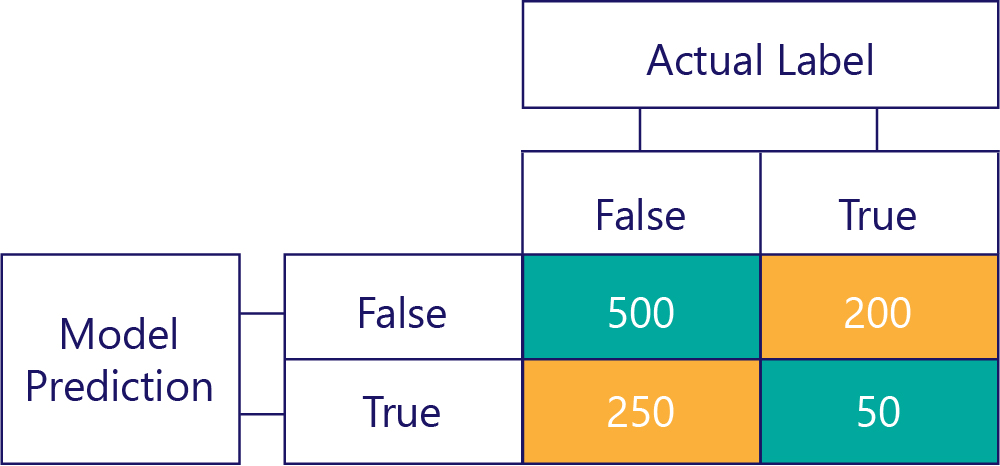
Modelin doğru tahminler yaptığı zamanları vurgulamak için buradaki hücreleri renklendirdik. Bundan, modelin belirli tahmin türlerini ne sıklıkta yaptığını değil, aynı zamanda bu tahminlerin ne sıklıkta doğru veya yanlış olduğunu da biliyoruz.
Daha fazla etiket olduğunda karışıklık matrisleri de oluşturulabilir. Örneğin, kişi/ hayvan/ağaç örneğimiz için şöyle bir matris elde edebiliriz:
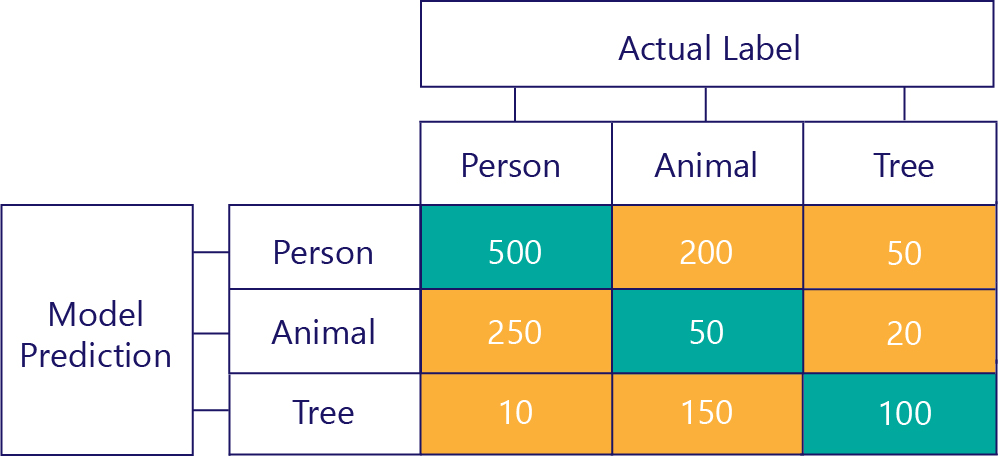
Üç kategori olduğunda, Gerçek Pozitifler gibi ölçümler artık geçerli değildir, ancak modelin belirli türlerdeki hataları tam olarak ne sıklıkta yaptığını görmeye devam edebiliriz. Örneğin, gerçek doğru sonuç "hayvan" olduğunda modelin bu "kişinin" 200 kez tahmin ettiğini görebiliriz.