Veri dengesizlikleri
Veri etiketlerimiz bir kategoriden diğerine daha fazla olduğunda, veri dengesizliği olduğunu söyleriz. Örneğin, senaryomuzda insansız hava aracı algılayıcıları tarafından bulunan nesneleri belirlemeye çalıştığımızı hatırlayın. Eğitim verilerimizde çok sayıda yürüyüşçü, hayvan, ağaç ve kaya bulunduğundan verilerimiz dengesizdir. Bu verileri tabloya kaydederek bunu görebiliriz:
| Etiket | Hiker | Hayvan | Ağaç | Taş |
|---|---|---|---|---|
| Sayı | 400 | 200 | 800 | 800 |
Veya çizim yapmak için:
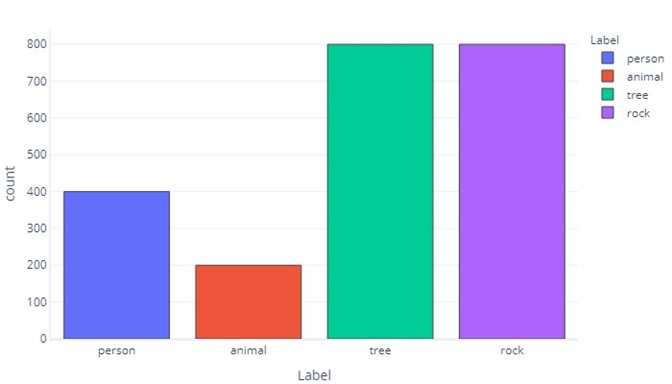
Verilerin çoğunun ağaç veya kaya olduğunu unutmayın. Dengeli bir veri kümesinde bu sorun yoktur.
Örneğin, bir nesnenin yürüyüşçü, hayvan, ağaç veya kaya olup olmadığını tahmin etmeye çalışıyor olsaydık, ideal olarak tüm kategorilerin eşit sayıda olmasını isterdik, örneğin:
| Etiket | Hiker | Hayvan | Ağaç | Taş |
|---|---|---|---|---|
| Sayı | 550 | 550 | 550 | 550 |
Bir nesnenin yürüyüşçü olup olmadığını tahmin etmeye çalışıyor olsaydık, ideal olarak eşit sayıda yürüyüşçü ve yürüyüşçü olmayan nesneler isterdik:
| Etiket | Hiker | YürüyüşÇü Olmayan |
|---|---|---|
| Sayı | 1100 | 1100 |
Veri dengesizliklerinin önemi nedir?
Veri dengesizliklerinin önemi vardır çünkü modeller istendiğinde bu dengesizliklerin taklit etmeyi öğrenebilir. Örneğin, nesneleri yürüyüşçü veya yürüyüşçü olmayan olarak tanımlamak için lojistik regresyon modeli eğitmişiz gibi davranın. Eğitim verilerine büyük ölçüde "yürüyüşçü" etiketleri hakim olsaydı, eğitim modeli neredeyse her zaman "yürüyüşçü" etiketleri döndürmek için sapmaya neden olurdu. Gerçek dünyada, insansız hava araçlarının çoğu ağaçla karşılaşmış olabilir. Yanlı model büyük olasılıkla bu ağaçların çoğunu yürüyüşçü olarak etiketleyebilir.
Maliyet işlevleri varsayılan olarak doğru yanıtın verilip verilmediğini belirlediği için bu fenomen gerçekleşir. Başka bir deyişle, yanlı bir veri kümesi için modelin en iyi performansa ulaşmanın en basit yolu, sağlanan özellikleri hemen hemen her zaman yoksaymak ve her zaman veya neredeyse her zaman aynı yanıtı döndürmek olabilir. Bunun yıkıcı sonuçları olabilir. Örneğin, yürüyüşçü/yürüyüşçü olmayan modelimizin her 1000 örnekte yalnızca bir yürüyüşçü içeren veriler üzerinde eğitildiğini düşünün. Her seferinde "yürüyüş yapmayan" döndürmeyi öğrenen bir model %99,9 doğruluk oranına sahiptir! Bu istatistiğin olağanüstü olduğu görülüyor, ancak model işe yaramaz çünkü bize dağda birinin olup olmadığını asla söylemez ve bir çığın çarpması durumunda onları kurtarmayı bilemeyiz.
Karışıklık matrisinde sapma
Karışıklık matrisleri, veri dengesizliklerini veya model sapmalarını tanımlamanın anahtarıdır. İdeal bir senaryoda, test verileri yaklaşık çift sayıda etikete sahiptir ve model tarafından yapılan tahminler de etiketlere yaklaşık olarak yayılır. 1000 örnek için, taraflı olmayan ancak çoğunlukla yanlış yanıtlar alan bir model şöyle görünebilir:
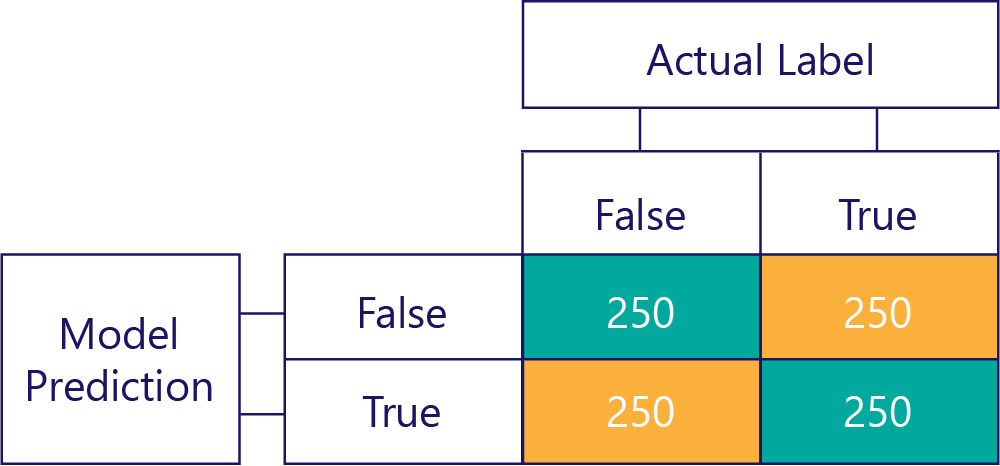
Satır toplamları aynı (her biri 500) olduğundan, etiketlerin yarısının "true" ve yarısının "false" olduğunu gösteren giriş verilerinin taraflı olmadığını anlayabiliriz. Benzer şekilde, modelin zaman içinde doğru, diğer yarısında yanlış döndüreceği için taraflı olmayan yanıtlar verdiğine de bakabiliriz.
Buna karşılık, taraflı veriler çoğunlukla tek bir etiket türü içerir, örneğin:
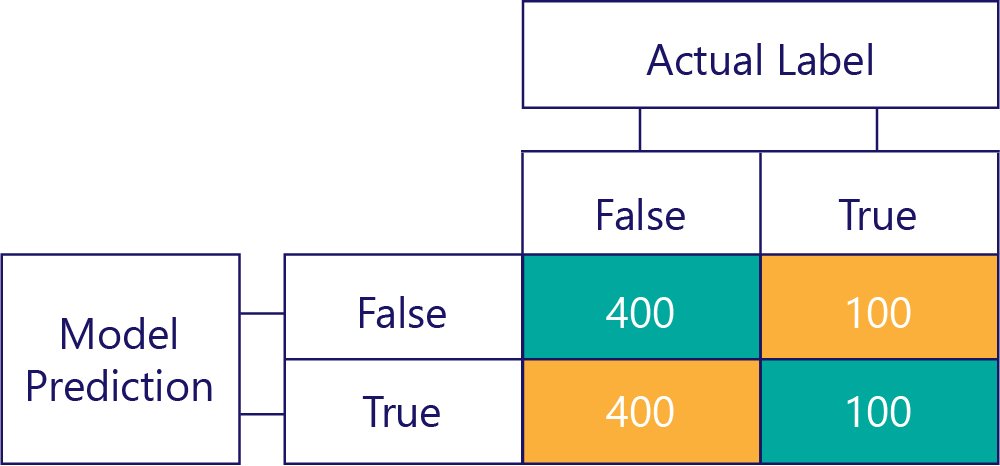
Benzer şekilde, taraflı bir model çoğunlukla bir tür etiket üretir, örneğin:
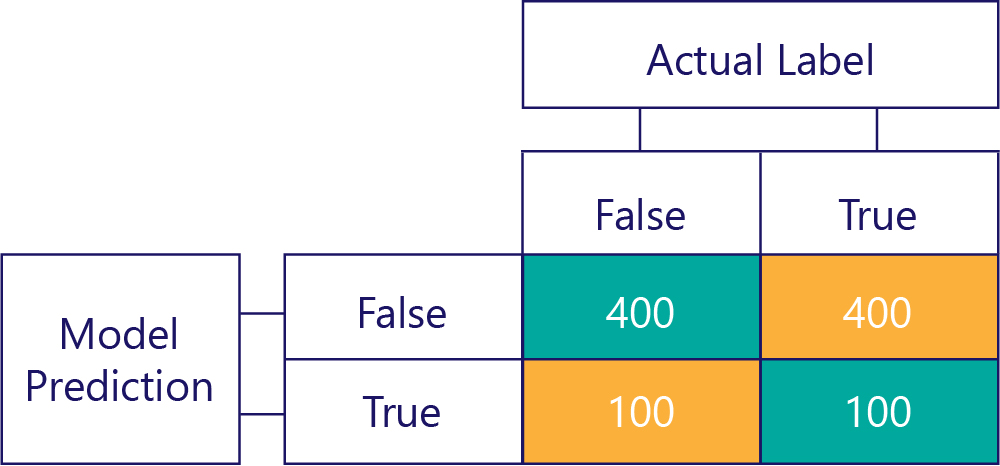
Model sapma doğruluğu değildir
Önyargının doğruluk olmadığını unutmayın. Örneğin, önceki örneklerden bazıları taraflıdır, bazıları yanlı değildir, ancak bunların tümü% 50 oranında doğru yanıtı alan bir model gösterir. Daha aşırı bir örnek olarak, aşağıdaki matriste hatalı bir sapma olmayan model gösterilmektedir:
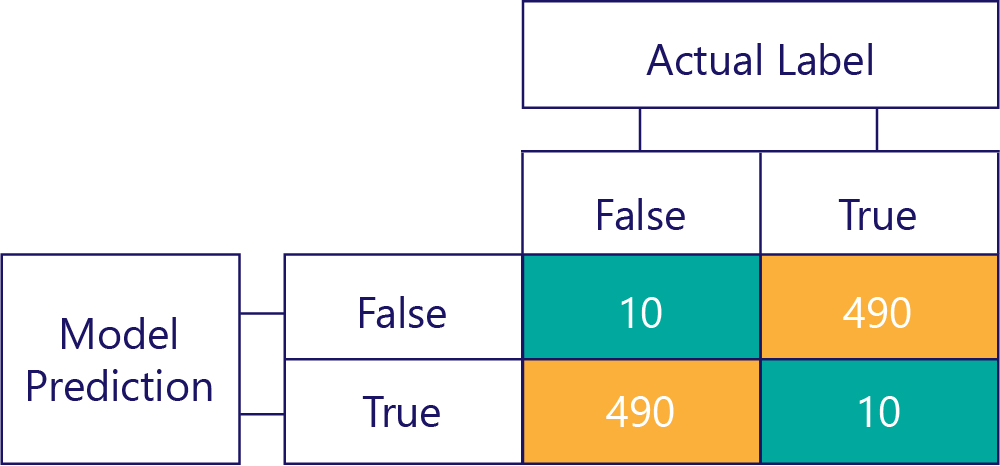
Satır ve sütun sayısının 500'e eklendiğine ve her iki verinin de dengeli olduğunu ve modelin yanlı olmadığının gösterildiğine dikkat edin. Ancak bu model neredeyse tüm yanıtları yanlış alıyor!
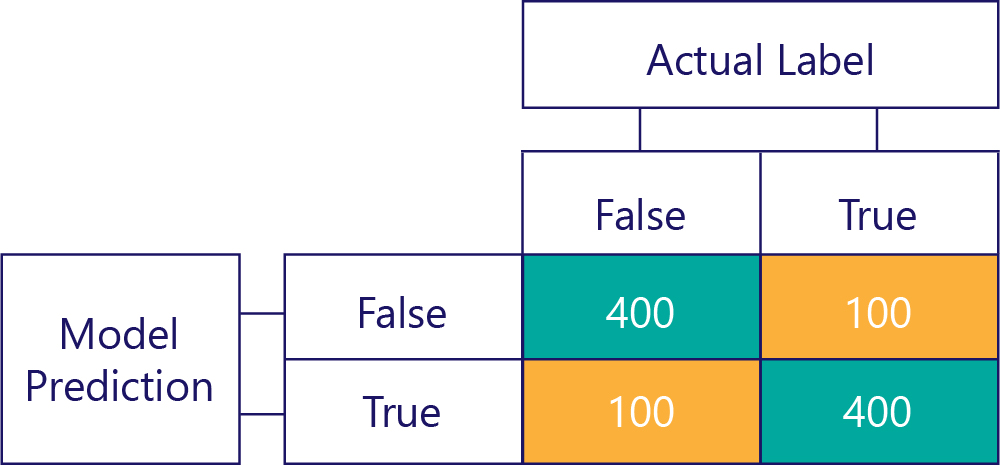
Elbette hedefimiz, modellerin doğru ve tarafsız olmasını sağlamaktır, örneğin:
... ancak doğru modellerimizin taraflı olmadığından emin olmamız gerekir çünkü veriler şunlardır:
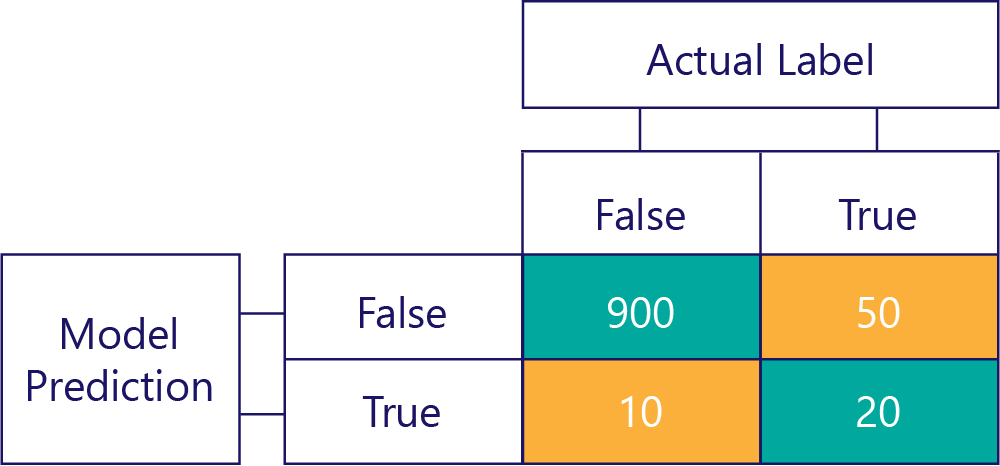
Bu örnekte, gerçek etiketlerin çoğunlukla yanlış (veri dengesizliği gösteren sol sütun) ve modelin sıklıkla false (model sapmasını gösteren üst satır) döndürdüğüne dikkat edin. Bu model doğru 'True' yanıtları vermede iyi değildir.
Dengesiz verilerin sonuçlarından kaçınma
Dengesiz verilerin sonuçlarından kaçınmanın en basit yollarından bazıları şunlardır:
- Daha iyi veri seçimiyle bundan kaçının.
- Verilerinizi azınlık etiket sınıfının yinelemelerini içermesi için "Yeniden örnekle".
- Maliyet işlevinde daha az yaygın etiketlere öncelik vermek için değişiklikler yapın. Örneğin, Tree'ye yanlış yanıt verilirse maliyet işlevi 1 döndürebilir; ancak Hiker'a yanlış yanıt verirseniz 10 döndürebilir.
Aşağıdaki alıştırmada bu yöntemleri keşfedeceğiz.