Kafka ve Spark mimarisi oluşturma
Kafka ve Spark'ı Azure HDInsight'ta birlikte kullanmak için bunları aynı sanal ağa yerleştirmeniz veya kümelerin DNS Adı çözümlemesiyle çalışması için sanal ağları eşlemeniz gerekir.
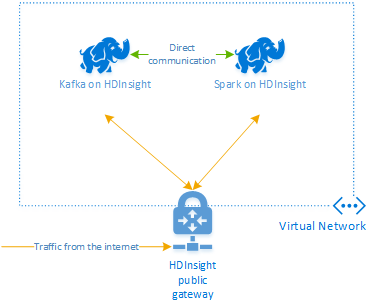
Aynı sanal ağda küme oluşturmak için yordam şudur:
- Kaynak grubu oluşturma
- Kaynak grubuna sanal ağ ekleme
- Aynı sanal ağa bir Kafka kümesi ve spark kümesi ekleyin veya alternatif olarak bu hizmetlerin DNS ad çözümlemesiyle çalıştığı sanal ağları eşleyin.
HDInsight Kafka ve Spark kümesini bağlamanın önerilen yolu, Spark kümesinin Kafka kümesindeki verilerin tek tek bölümlerine erişmesini sağlayan yerel Spark-Kafka bağlayıcısıdır. Bu bağlayıcı gerçek zamanlı işleme işinizde sahip olduğunuz paralelliği artırır ve çok yüksek aktarım hızı sağlar.
Her iki küme de aynı sanal ağda olduğunda, Spark akış kodunda Kafka Aracısı FQDN'lerini de kullanabilir ve kurumsal güvenlik için sanal ağda NSG kuralları oluşturabilirsiniz.
Çözüm mimarisi
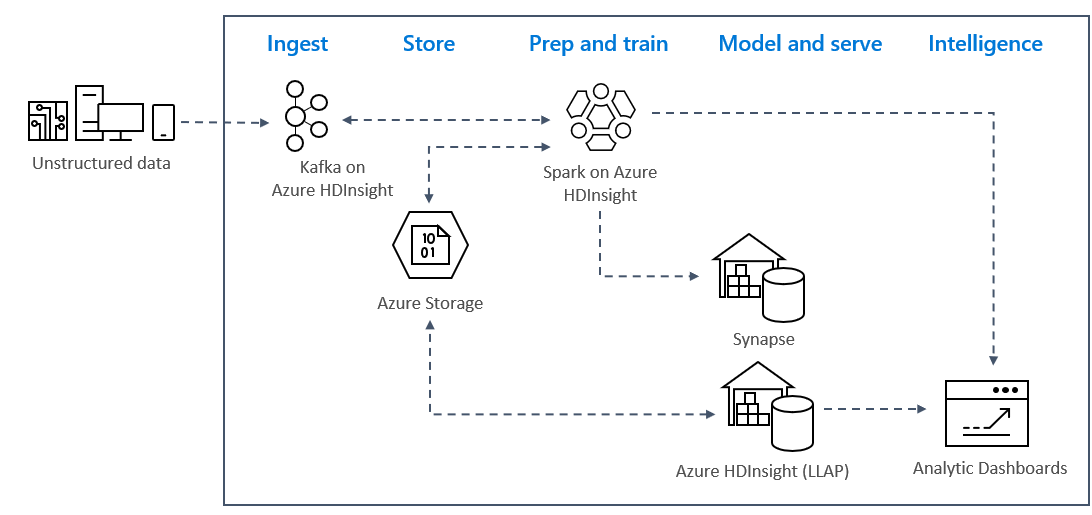
Azure'da gerçek zamanlı akış analizi desenleri genellikle aşağıdaki çözüm mimarisini kullanır.
- Alma: Yapılandırılmamış veya yapılandırılmış veriler Azure HDInsight'ta bir Kafka kümesine alınır.
- Hazırlama ve eğitme: HdInsight üzerinde Spark ile veriler hazırlanıp eğitilir.
- Model ve hizmet: Veriler Azure Synapse veya HDInsight Etkileşimli Sorgu gibi bir veri ambarı içine alınır.
- Zeka: Veriler Power BI veya Tableau gibi analiz panosuna sunulur.
- Depolama: Veriler Azure Depolama gibi bir soğuk depolama çözümüne konur ve daha sonra sunulur.
Örnek Senaryo Mimarisi
Sonraki ünitede örnek uygulama için çözüm mimarisini oluşturmaya başlayacaksınız. Bu örnekte kaynak grubu, sanal ağ, Spark kümesi ve Kafka kümesi oluşturmak için bir Azure Resource Manager şablon dosyası kullanılır.
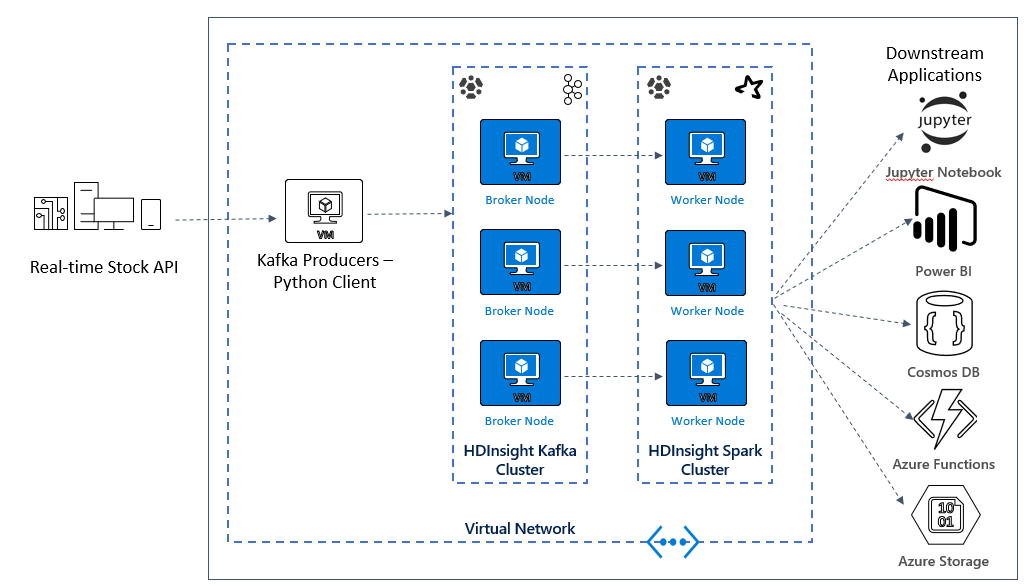
Kümeler dağıtıldıktan sonra Kafka aracılarından birine bağlanacak ve Python üretici dosyasını baş düğüme kopyalayacaksınız. Bu üretici dosyası her 10 saniyede bir yapay hisse senedi fiyatları sağlar, ayrıca iletinin bölüm numarasını ve uzaklığını konsola yazar.
Yapımcı çalıştırıldıktan sonra Jupyter not defterini Spark kümesine yükleyebilirsiniz. Not defterinde Spark ve Kafka kümelerini bağlayacak ve bir olay penceresinde hisse senedi için yüksek ve düşük değerleri bulma da dahil olmak üzere veriler üzerinde bazı örnek sorgular çalıştıracaksınız.