Azure Databricks ile veri alma
Azure Databricks'te verilerle çalışabilmek için önce verileri platforma almanız gerekir. Platforma girdikten sonra bulut tabanlı işlem, büyük hacimli verileri verimli bir şekilde işlemenizi sağlar.
Azure Databricks'teki veriler, ilişkisel tabloların tanımlanıp sorgulanabildiği veri dosyalarını yönetmeye yönelik açık kaynak bir sistem olan Apache Delta Lake kullanılarak depolanır. Delta lake dosyalarının gerçek depolama konumu farklılık gösterebilir. Azure Databricks, Azure Depolama ve Azure Data Lake gibi bulut veri depolama hizmetlerine bağlanmayı destekler. Azure Databricks, birden çok bağlı veri deposunda veri erişimini ve kökenini yönetmek ve izlemek için bir idare çözümü olarak Unity Kataloğu da sağlar.
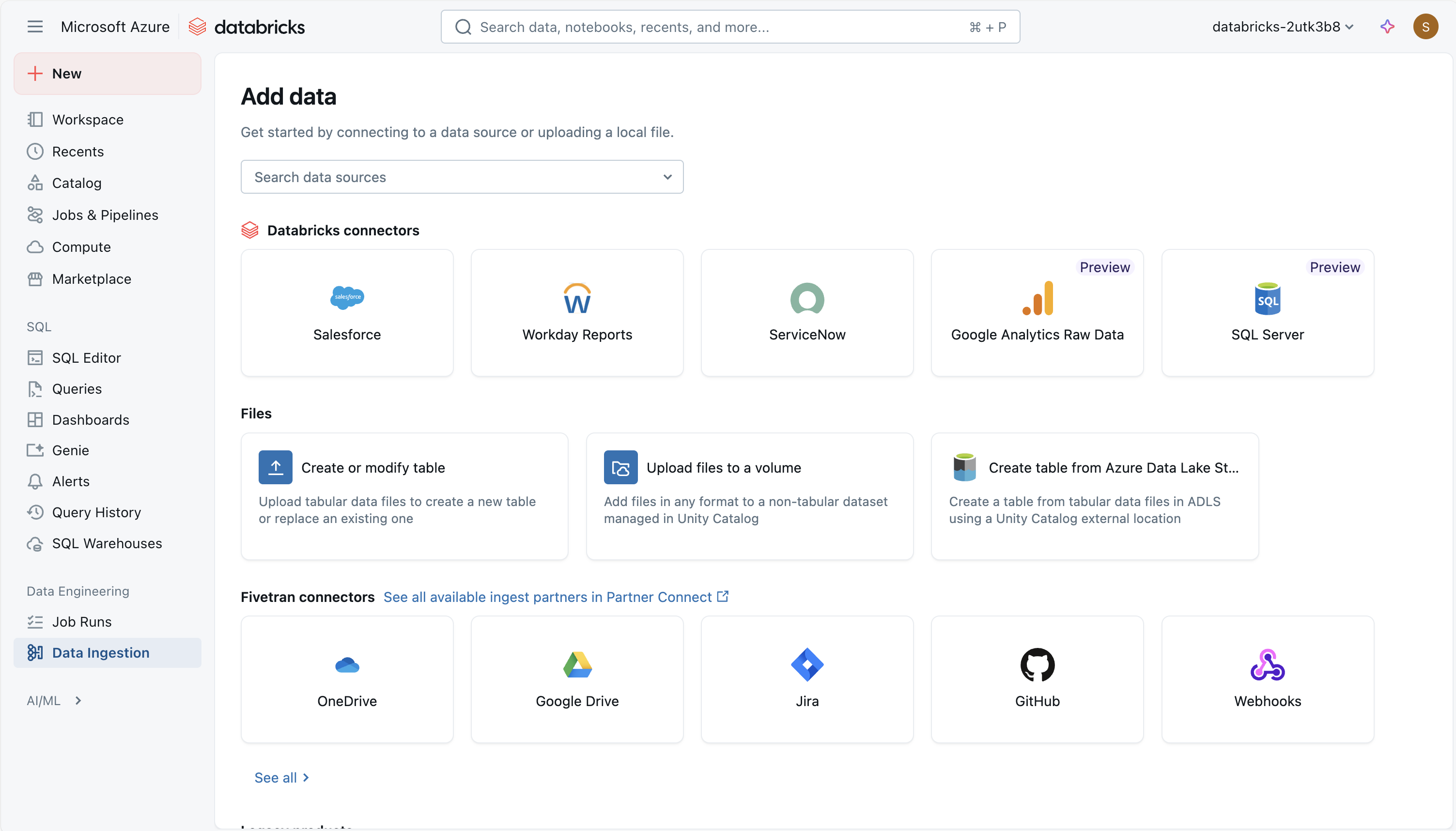
Azure Databricks'e veri almanın birden çok yolu vardır ve bu da aşağıdakiler dahil olmak üzere veri analizi için çok yönlü ve güçlü bir araçtır:
Lakeflow Connect'te Yönetilen Databricks Bağlayıcısı Kullanma
Azure Databricks Lakeflow Connect , yönetilen bağlayıcıları kullanarak SaaS uygulamalarından, veritabanlarından ve diğer kaynaklardan lakehouse'a veri almak için bir çerçeve sağlar. Bu bağlayıcılar kimlik doğrulamasının, işlem hatlarının ve hedef tabloların nasıl ayarlandığını ve korunyacağını tanımlar. SaaS kaynakları için ana parçalar bir bağlantı (kimlik doğrulaması için), sunucusuz alım işlem hattı ve alınan verileri depolayan Delta tablolarıdır . Veritabanı bağlayıcıları aynı öğeleri içerir, ancak ayıklanan verileri geçici olarak tutmak için klasik bilgi işlemde çalışan bir alım ağ geçidine ve Unity Kataloğu'nda bir hazırlama depolama alanına da dayanır. Orkestrasyon, Databricks görevleri aracılığıyla gerçekleştirilir ve erişim kontrolü ve izleme, Unity Kataloğu aracılığıyla yönetilir.
Yönetilen bağlayıcıları kullanmak, özel alma kodu yazmak zorunda kalmadan veri işlem hatlarının zamanlanması, yeniden denenmesi ve ölçeklendirilmesine olanak tanır. Artımlı veri alma desteklenir ve bu, tabloları güncel tutarken kaynak sistemlerdeki yükü azaltmaya yardımcı olur. Bu yaklaşım farklı veri kaynakları arasında tutarlı idare, şema işleme ve izlemeyi vurgular.
Aşağıdaki yönetilen bağlayıcılar kullanılabilir:
- Google Analytics
- Salesforce
- Çalışma Günü Raporları
- SQL Server
- ServiceNow
- SharePoint
Azure Databricks'e dosya yükleme
Delta tablosu oluşturmak için yerel CSV, TSV, JSON, XML, Avro, Parquet veya düz metin dosyalarını Databricks'e aktarabilirsiniz. Bu yaklaşım, doğrudan bilgisayarınızdan aktarılan daha küçük dosyalara (2 GB'ın altında) yöneliktir. ZIP veya TAR gibi sıkıştırılmış arşivler desteklenmez. Karşıya yükleme işlemi sırasında Databricks, 50 satıra kadar bir önizleme sağlar ve format ayarlarını ayarlayarak CSV veya JSON dosyalarındaki sütunların ve veri türlerinin doğru şekilde tanındığından emin olabilirsiniz.
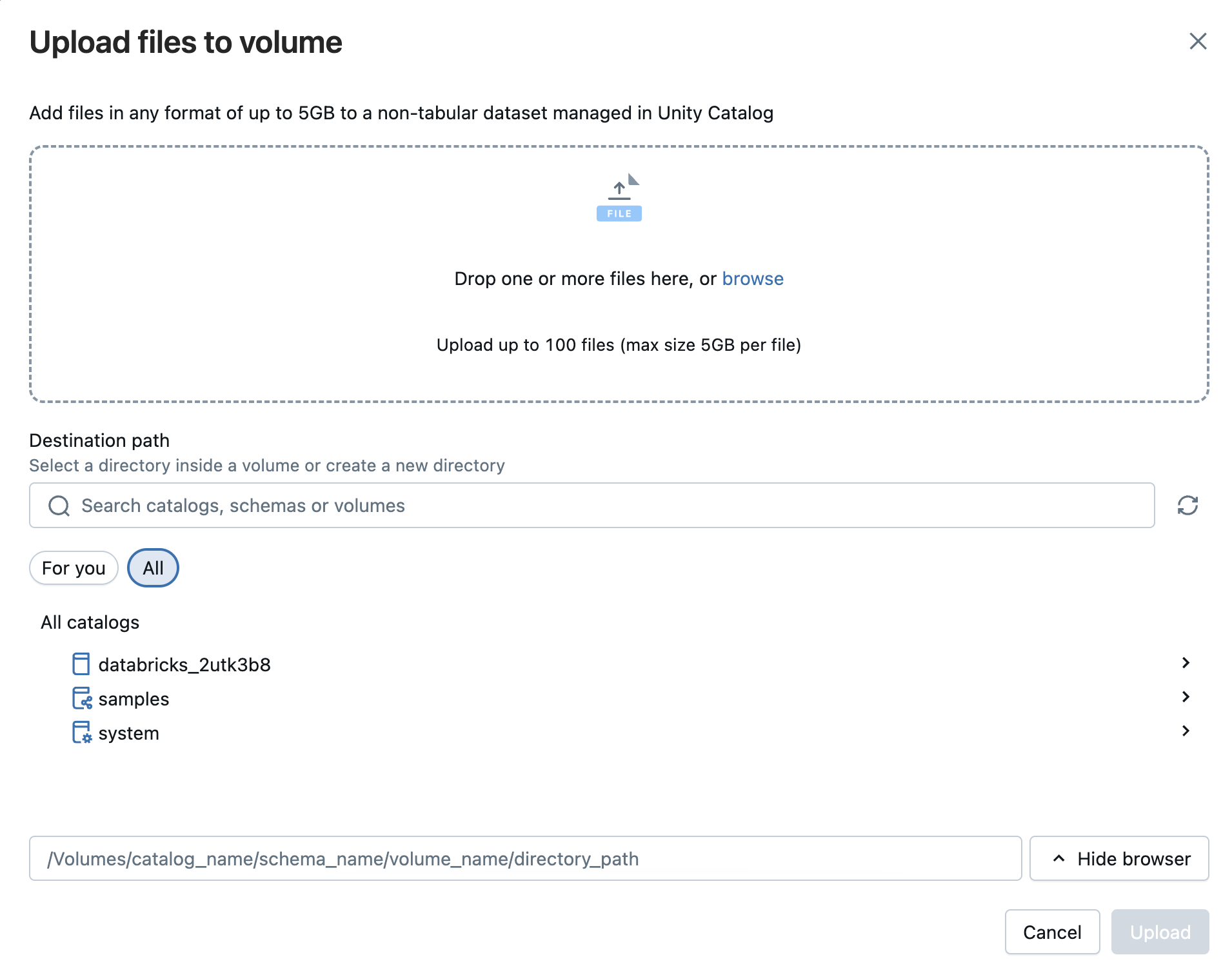
Ayrıca yapılandırılmış, yarı yapılandırılmış veya yapılandırılmamış herhangi bir biçimdeki dosyaları bir birime yükleyebilirsiniz. Birim, tablosal olmayan veri kümeleri için idare sağlayan ve bir bulut nesne deposu içindeki mantıksal depolama alanını temsil eden bir Unity Kataloğu nesnesidir. Birimler dosyalara erişmenize, bunları depolamanıza, düzenlemenize ve dosyalara idare uygulamanıza olanak sağlar. İki tür hacim vardır:
- Yönetilen birimler: Basit kullanım örnekleri için Databricks tarafından yönetilen depolama.
- Dış birimler: Mevcut olan bulut nesne depolama konumlarına uygulanan yönetişim.
Uyarı
DBFS seçeneği, eski Databricks Dosya Sistemi dosya yüklemesini kullanmanıza olanak tanır. Bu artık desteklenmiyor.
Apache Spark API'lerini kullanarak dosyaları alma
Apache Spark, Azure Databricks için yerel işlem platformudur ve Scala, Java, PySpark (Python'ın Spark için iyileştirilmiş bir değişkeni) ve SQL gibi birden çok programlama dili için API'leri destekler. Uzak depolamada verilerin basit bir şekilde alınması için gerekli verilere bağlanan ve içeri aktaran kodlar yazabilirsiniz.
Aşağıda wget kullanarak sürücü düğümünde /tmp/ içine uzak bir dosya çekme, spark kullanarak yerel yoldan okuma ve databricks'te Delta tablosu olarak kaydetme gibi bir örnek verilmiştir:
# Step 1: Use wget to download the file (e.g., a CSV from a public URL)
# In Databricks, prefix shell commands with "!"
!wget https://<location>/airtravel.csv -O /tmp/airtravel.csv
# Step 2: Load the downloaded file into a Spark DataFrame
df = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("file:/tmp/airtravel.csv")
# Step 3: Preview the data
df.show(5)
# Step 4: Save as a Delta table
df.write.format("delta").mode("overwrite").saveAsTable("default.airtravel")
Hizmet sorumlusuyla COPY INTO kullanarak veri yükleme
Azure hesabınızdaki bir Azure Data Lake Storage (ADLS) kapsayıcısından Databricks SQL'deki bir tabloya veri yüklemek için komutunu kullanabilirsiniz COPY INTO .
COPY INTO my_json_data
FROM 'abfss://container@storageAccount.dfs.core.windows.net/jsonData'
FILEFORMAT = JSON;
Lakeflow Deklaratif İşlem Hatları
Lakeflow Bildirimli İşlem Hatları, SQL ve Python'da toplu işlem ve akış veri işlem hatlarını geliştirmeye ve çalıştırmaya yönelik bildirim temelli bir çerçevedir. Otomatik düzenlemeyi, yeniden denemeleri, hata yalıtımını, şema evrimi, artımlı işlemeyi ve CDC Değişiklik Verileri Yakalama türü 1 ve 2'yi destekler.
Veri akışı, hem akış hem de toplu iş semantiğini destekleyen Lakeflow Deklaratif İşlem Hatlarında temel veri işleme kavramıdır. Akış bir kaynaktan verileri okur, kullanıcı tanımlı işleme mantığını uygular ve sonucu bir hedefe yazar.
Verilerin hedefine yazılmadan önce gerekli standartları karşıladığından emin olmak için doğrulama kuralları tanımlamanıza olanak tanıyan işlem hattı beklentileriyle de veri kalitesini yönetebilirsiniz.
Bildirim temelli işlem hattı örneği aşağıda verilmiştir:
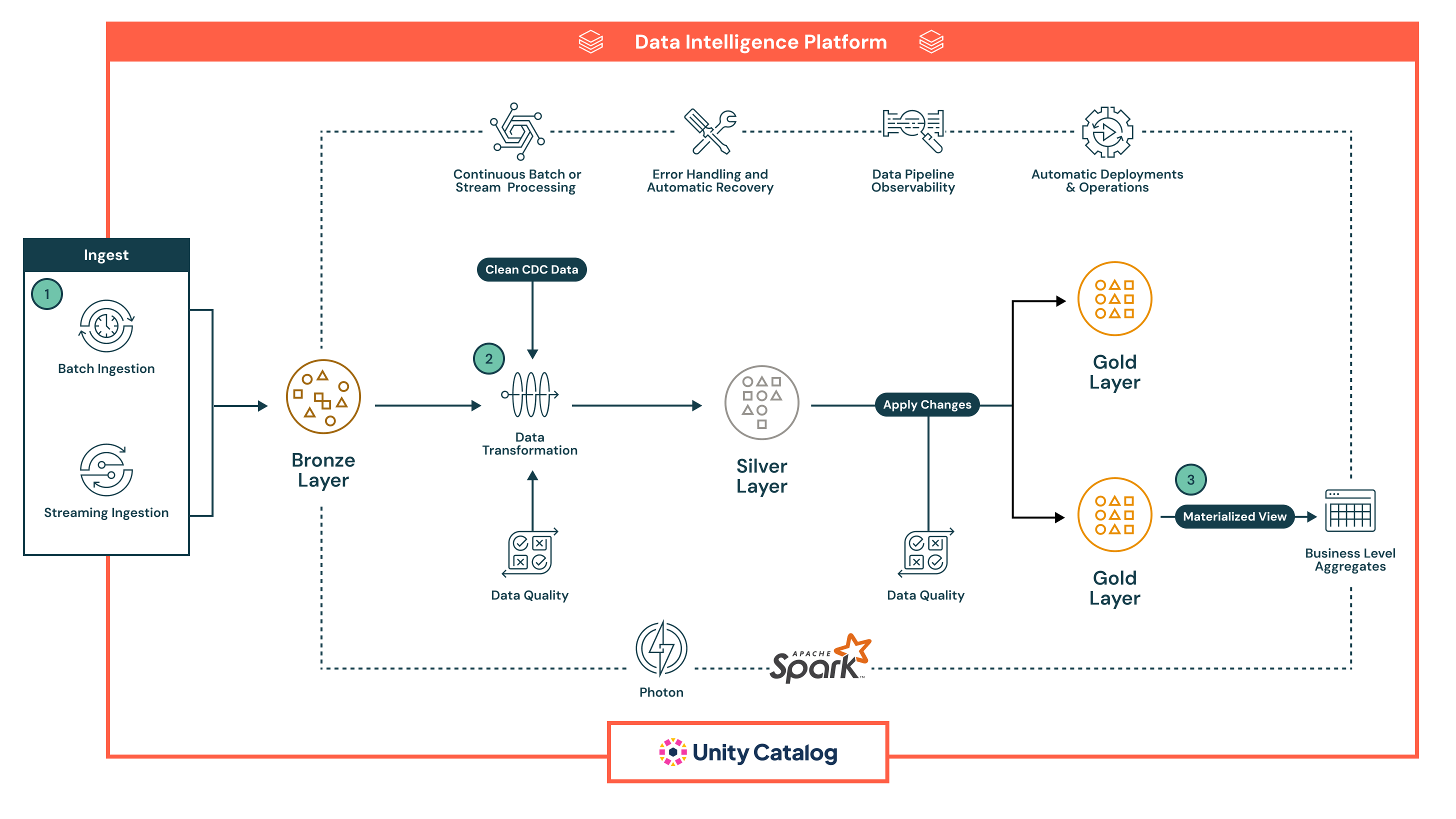
Bu örnekte veriler ilk olarak köken ve güvenli yeniden işleme için ham biçimde Bronz katmanına gelir, ardından temizlendiği, zenginleştirildiği, satır içi kalite denetimleriyle doğrulandığı ve Spark ile büyük ölçekte işlendiği Silver katmanına ilerler. Bu katman, BI, makine öğrenmesi ve geçmiş izleme gibi gelişmiş kullanım örnekleri için seçilmiş, işletmeye hazır veri kümeleri sunar.
Azure Data Factory
Azure Data Factory (ADF), yerleşik Kopyalama etkinliğini kullanarak Azure Databricks Delta Lake'e ve Azure Databricks Delta Lake'ten veri kopyalamanızı sağlar. Kaynak olarak hareket ederken, ADF Databricks'teki Delta tablolarından verileri ayıklayabilir ve desteklenen havuzlara taşıyabilir; havuz görevi görürken desteklenen kaynaklardan Delta Lake tablolarına veri yükleyebilir.
Veri taşıma işlemi, aktarımı işlemek için Databricks kümeniz çağrılarak gerçekleştirilir ve ADF, ortama bağlı olarak hem Azure tümleştirme çalışma zamanlarını hem de şirket içinde barındırılan tümleştirme çalışma zamanlarını destekler.
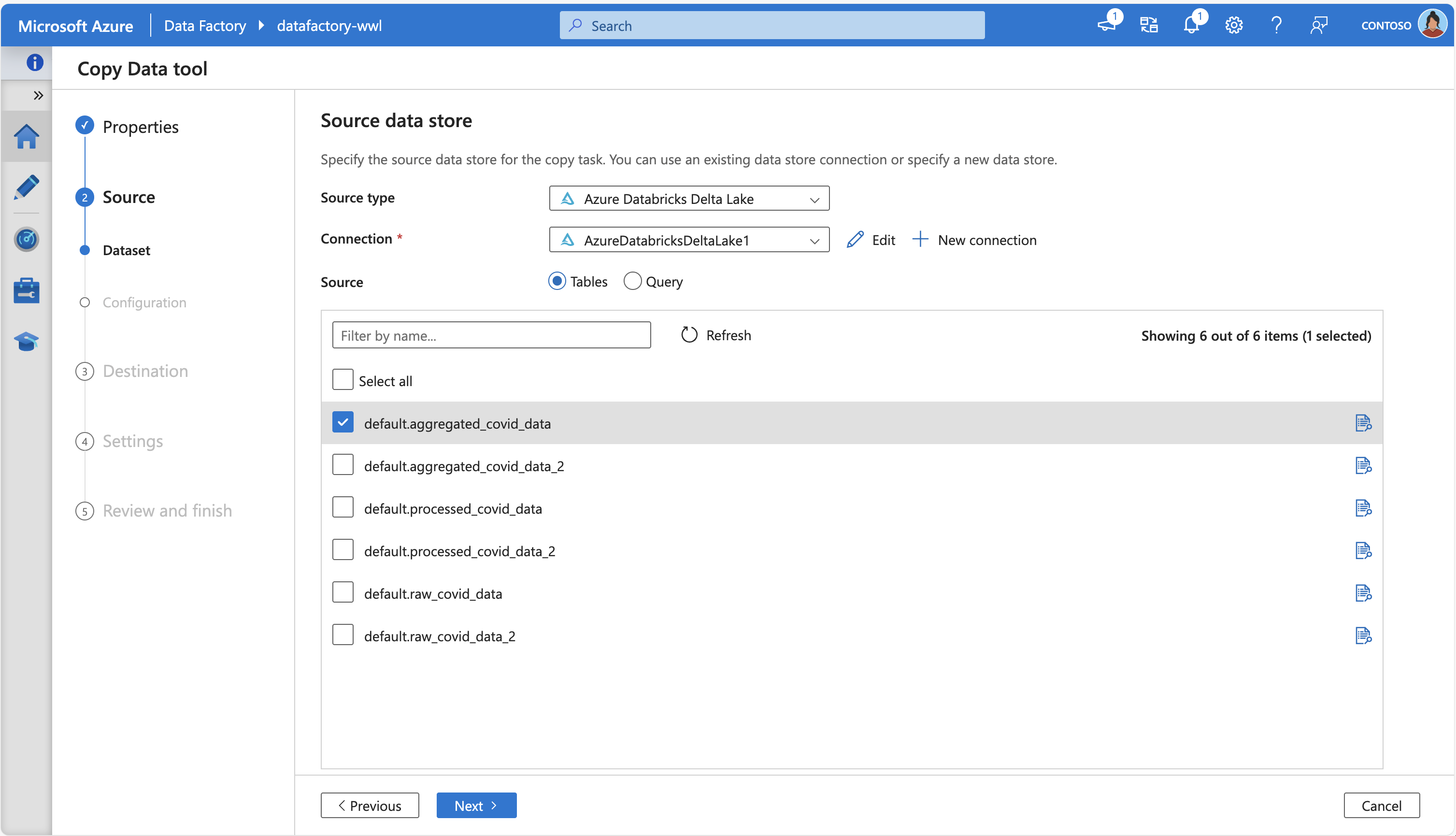
Aşağıdaki ekran görüntüsünde, bazı kaynak tabloları getirmek için Azure Databricks Delta Lake'e bağlanan Azure Data Factory Veri Kopyalama Aracı gösterilmektedir:
Buna ek olarak, ADF'nin Eşleme Veri Akışları kod içermeyen bir ETL deneyimi sunar. Azure Depolama'dan kaynak alabilir ve verileri Delta biçiminde Azure Depolama'ya aktarabilir. Kod yazmadan dönüşümleri gerçekleştirebilir ve yönetilen Azure Integration Runtime'da çalışır.
Azure Event Hubs ve IoT Hubs
Gerçek zamanlı veri alımı için Azure Event Hubs ve IoT Hubs en uygun seçeneklerdir. Verileri doğrudan Azure Databricks'e aktarmanıza olanak tanıyarak verileri geldikçe işleyip analiz etmenizi sağlar. Gerçek zamanlı veri alımı ve analizi, canlı etkinlikleri izleme veya Nesnelerin İnterneti (IoT) cihaz verilerini izleme gibi senaryolar için kullanışlıdır.
Azure Event Hubs, Databricks Runtime'daki Yapılandırılmış Akış Kafka bağlayıcısıyla çalışan Kafka uyumlu bir uç noktaya sahiptir. Lakeflow Bildirimsel İşlem Hatlarını bir Event Hubs örneğine bağlanmak ve bir konudaki olayları kullanmak üzere ayarlayabilirsiniz.