Alıştırma - Verileri temizleme ve hazırlama
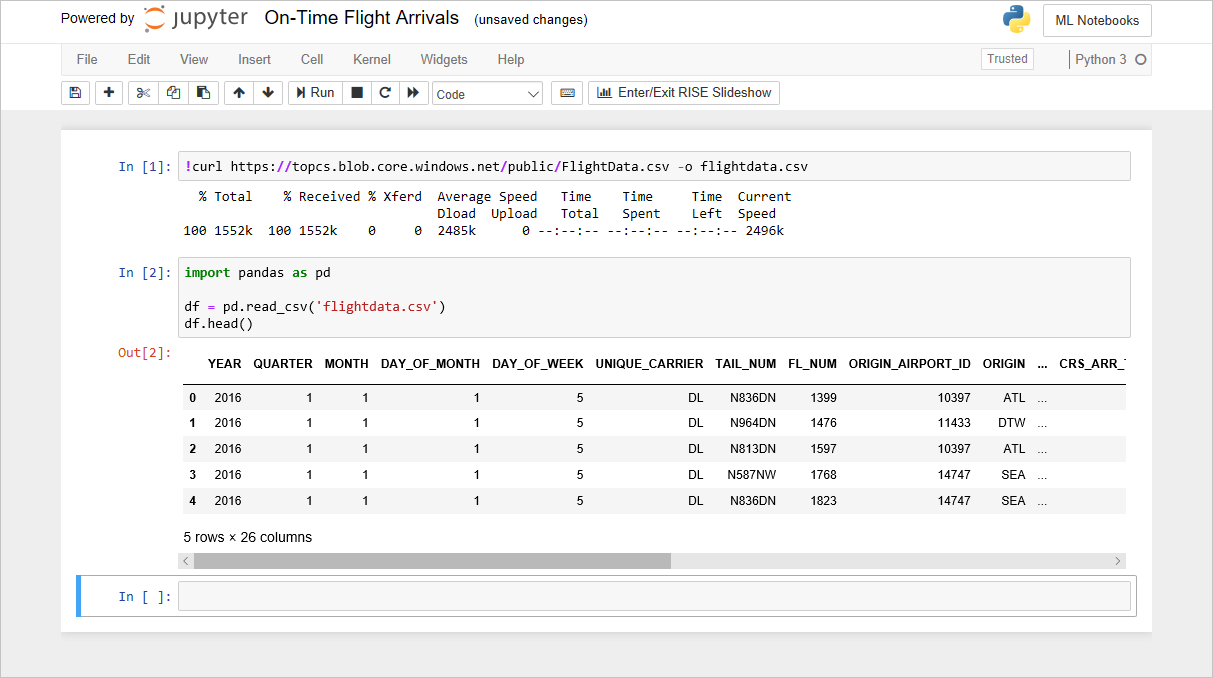
Bir veri kümesi hazırlayabilmeniz için öncelikle bunun içeriğini ve yapısını anlamanız gerekir. Önceki laboratuvarda, ABD’nin önemli havayollarından birinin zamanında varış bilgilerini içeren bir veri kümesini içeri aktarmıştınız. 26 sütundan ve binlerce satırdan oluşan bu verilerdeki her satır bir uçuşu temsil ediyordu ve uçuşun kalkış yeri, varış yeri ve planlanan kalkış saati gibi bilgileri içeriyordu. Ayrıca bu verileri bir Jupyter not defterine yükleyip basit bir Python betiği kullanarak verilerden bir Pandas DataFrame’i oluşturmuştunuz.
DataFrame, iki boyutlu ve etiketlenmiş bir veri yapısıdır. DataFrame’deki sütunlar, tıpkı bir elektronik tablo veya veritabanı tablosundaki sütunlar gibi farklı türlerde olabilir. Pandas’ta en sık kullanılan nesnedir. Bu alıştırmada DataFrame’i ve içindeki verileri daha yakından inceleyeceksiniz.
Önceki bölümde oluşturduğunuz Azure not defterine dönün. Not defterini kapattıysanız, Microsoft Azure Notebooks portalında yeniden oturum açabilir, not defterinizi açabilir ve hücreyi açtıktan sonra not defterindeki tüm hücreleri yeniden çalıştırmak için Tümünü Çalıştır Hücresini> kullanabilirsiniz.
FlightData not defteri
Önceki laboratuvarda not defterine eklediğiniz kod, flightdata.csv dosyasından bir DataFrame oluşturur ve ilk beş satırı görüntülemek için bunun üzerinde DataFrame.head öğesini çağırır. Öncelikle bir veri kümesinin kaç satırdan oluştuğunu bilmeniz gerekir. Bu sayıyı öğrenmek için aşağıdaki deyimi not defterinin sonundaki boş bir hücreye yazıp çalıştırın:
df.shapeDataFrame’in 11.231 satır ve 26 sütun içerdiğini onaylayın:

Satır ve sütun sayısını öğrenme
Şimdi veri kümesindeki 26 sütunu inceleyin. Bu sütunlarda uçuşun gerçekleştiği tarih (YEAR, MONTH ve DAY_OF_MONTH), kalkış ve varış noktası (ORIGIN ve DEST), planlanan kalkış ve varış zamanları (CRS_DEP_TIME ve CRS_ARR_TIME), planlanan varış zamanıyla gerçek varış zamanı arasındaki farkın dakika cinsinden gösterimi (ARR_DELAY) ve uçuş gecikmesinin 15 dakikadan az olup olmadığı (ARR_DEL15) gibi önemli bilgiler yer alır.
Veri kümesindeki tüm sütunların listesini burada bulabilirsiniz. Saatler, 24 saatlik askeri biçimde gösterilir. Örneğin, 1130, 11:30'a, 1500 de 1500'e 15:00'e eşittir.
Sütun Açıklama YEAR Uçuşun gerçekleştiği yıl QUARTER Uçuşun yılın hangi çeyreğinde gerçekleştiği (1-4) MONTH Uçuşun yılın hangi ayında gerçekleştiği (1-12) DAY_OF_MONTH Uçuşun ayın hangi gününde gerçekleştiği (1-31) DAY_OF_WEEK Uçuşun haftanın hangi gününde gerçekleştiği (1=Pazartesi, 2=Salı vb.) UNIQUE_CARRIER Havayolunun taşıyıcı kodu (DL gibi) TAIL_NUM Uçağın kuyruk numarası FL_NUM Uçuş numarası ORIGIN_AIRPORT_ID Kalkış yapılan havaalanının kimliği ORIGIN Kalkış yapılan havaalanı kodu (ATL, DFW, SEA vb.) DEST_AIRPORT_ID Varılan havaalanının kimliği DEST Varılan havaalanının kodu (ATL, DFW, SEA vb.) CRS_DEP_TIME Planlanan kalkış saati DEP_TIME Gerçek kalkış saati DEP_DELAY Kalkışın kaç dakika geciktiği DEP_DEL15 0=Kalkış 15 dakikadan az gecikmeli, 1=Kalkış 15 dakika veya daha fazla gecikmeli CRS_ARR_TIME Planlanan varış saati ARR_TIME Gerçek varış saati ARR_DELAY Uçuşun kaç dakika geç vardığı ARR_DEL15 0=15 dakikadan az gecikmeli varış, 1=15 dakika veya daha fazla gecikmeli varış CANCELLED 0=Uçuş iptal edilmedi, 1=Uçuş iptal edildi DIVERTED 0=Varış noktası değiştirilmedi, 1=Varış noktası değiştirildi CRS_ELAPSED_TIME Dakika cinsinden planlanan uçuş süresi ACTUAL_ELAPSED_TIME Dakika cinsinden gerçek uçuş süresi DISTANCE Katedilen mesafe
Veri kümesindeki tarihler, yaklaşık olarak yıl içinde eşit biçimde dağılmış durumdadır. Minneapolis’ten kalkan bir uçağın kar fırtınası nedeniyle ertelenmesi Temmuz ayına kıyasla Ocak ayında daha olası olduğundan, bu önemli bir ayrıntıdır. Ancak bu veri kümesinin “temiz” ve kullanıma hazır olduğunu söyleyemeyiz. Verileri temizlemek için Pandas kodu yazalım.
Makine öğreniminde kullanılmak üzere bir veri kümesi hazırlamanın en önemli yönlendiren biri, “özellik” sütunlarını belirlerken tahmin etmeye çalıştığınız sonuçla alakalı olanları seçmektir. Sonucu etkilemeyecek, negatif bir biçimde sapmaya neden olabilecek veya çoklu doğrusallığa yol açabilecek sütunları dahil etmemek gerekir. Bir diğer önemli görev ise eksik değerleri ortadan kaldırmaktır. Bunu, satırları ya da sütunları silerek veya bunların yerine anlamlı değerler ekleyerek yapabilirsiniz. Bu alıştırmada, alakasız sütunları ortadan kaldıracak ve kalan sütunlardaki eksik değerleri değiştireceksiniz.
Veri bilimciler veri kümelerini incelerken öncelikle eksik değerlere bakar. Pandas’ta eksik değerler olup olmadığını denetlemenin kolay bir yolu vardır. Göstermek için şu kodu not defterinin sonundaki bir hücrede çalıştırın:
df.isnull().values.any()Çıktının “True” olduğunu onaylayın. Bu, veri kümesinin herhangi bir yerinde en az bir değerin eksik olduğunu gösterir.

Eksik değerleri denetleme
Şimdi eksik değerlerin nerede olduğunu bulmak gerekir. Bunu yapmak için şu kodu yürütün:
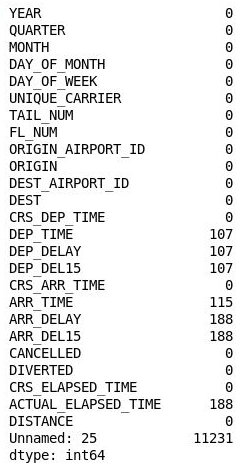
df.isnull().sum()Her sütundaki eksik değerlerin sayısını listeleyen şu çıktıyı gördüğünüzü onaylayın:
Her sütundaki eksik değer sayısı
Merakla, 26. sütun ("Adsız: 25"), veri kümesindeki satır sayısına eşit olan 11.231 eksik değer içeriyor. İçeri aktardığınız CSV dosyasındaki her satırın sonunda bir virgül bulunduğundan bu sütun yanlışlıkla oluşturulmuş. Bu sütunu kaldırmak için not defterine şu kodu ekleyip çalıştırın:
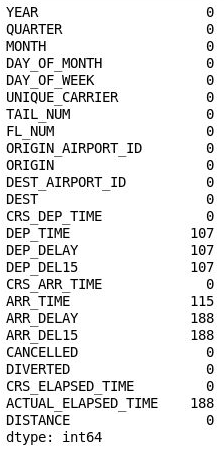
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()Çıktıyı inceleyin ve 26. sütunun DataFrame’den kaldırıldığını onaylayın:
26. sütunu kaldırılan DataFrame
DataFrame’de hala birçok eksik değer var, ancak bunların bazılarının bulunduğu sütunlar oluşturduğunuz model ile ilgili olmadığından eksik veriler de önemli değil. Bu modelin amacı, yer ayırtmayı planladığınız bir uçuşun zamanında gelip gelmeyeceğini tahmin etmektir. Söz konusu uçuşun büyük olasılıkla gecikeceğini bildiğinizde başka bir uçuşta yer ayırtabilirsiniz.
Bu nedenle sıradaki adımda, bu tahmin modeliyle alakalı olmayan sütunları veri kümesinde filtrelemeniz gerekir. Örneğin uçağın kuyruk numarası, uçuşun zamanında gelip gelmeyeceğini pek etkilemeyecektir. Ayrıca bilet rezervasyonu yaptığınızda uçuşun iptal olup olmayacağını, varış noktasının değişip değişmeyeceğini veya gecikme yaşanıp yaşanmayacağını bilemezsiniz. Ancak planlanan kalkış zamanı, uçuşun zamanında varıp varamayacağı üzerinde büyük etki sahibi olabilir. Çoğu havayolu şirketinin kullandığı topla ve dağıt sistemi nedeniyle, sabah uçuşlarının zamanında gerçekleşmesi akşam veya gece uçuşlarına göre genelde daha olasıdır. Ayrıca bazı büyük havaalanlarında gün içinde trafik birikir ve bu da sonraki uçuşların gecikmesi olasılığını yükseltir.
Pandas, istemediğiniz sütunları filtrelemenin kolay bir yolunu sunar. Şu kodu not defterinin sonunda yeni bir hücrede çalıştırın:
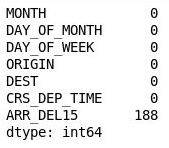
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()Elde edilen çıktı, DataFrame’in artık yalnızca model ile alakalı sütunları içerdiğini ve eksik değerlerin sayısının büyük oranda düştüğünü gösteriyor:
Filtrelenen DataFrame
Şimdi yalnızca ARR_DEL15 sütununda eksik değerler var. Bu, zamanında varan uçuşlar için 0 ve zamanında varmayan uçuşlar içinse 1 değerinin kullanıldığı sütundur. Değerlerin eksik olduğu ilk beş satırı göstermek için şu kodu kullanın:
df[df.isnull().values.any(axis=1)].head()Pandas eksik değerleri
NaNolarak gösterir. Bu Not a Number (Sayı Değil) anlamına gelir. Bu çıktı, aşağıdaki satırların ARR_DEL15 sütunundaki değerlerinin eksik olduğunu gösteriyor: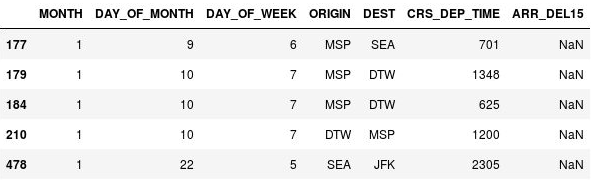
Eksik değerleri olan satırlar
Bu satırların ARR_DEL15 değerlerinin eksik olmasının nedeni, tümünün iptal edilmiş veya varış noktası değiştirilmiş uçuşları temsil etmesidir. Bu satırları kaldırmak için DataFrame’de dropna çağrısı yapabilirsiniz. Ancak iptal edilen veya başka bir havaalanına yönlendirilen uçuşun da “geç” olduğu söylenebileceğinden, eksik değerleri 1 olarak değiştirmek için fillna yöntemini kullanalım.
ARR_DEL15 sütunundaki eksik değerleri 1 olarak değiştirmek ve 177 ila 184 arasındaki satırları görüntülemek için şu kodu kullanın:
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]177, 179 ve 184. satırlardaki
NaNdeğerlerinin, uçuşların geç vardığını gösteren 1 olarak değiştirildiğini onaylayın: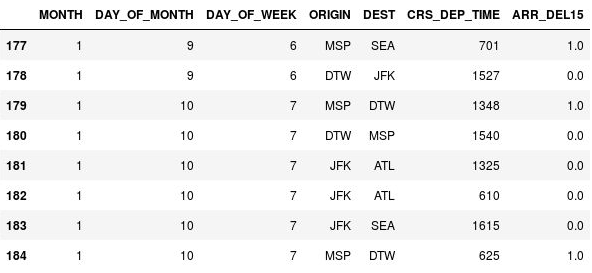
NaN değerleri 1 olarak değiştirildi
Artık eksik değerlerin değiştirildiğini ve sütun listesinde yalnızca model ile alakalı olanların kaldığını göz önünde bulundurarak veri kümesinin “temiz” olduğunu söyleyebiliriz. Ancak henüz işimiz bitmedi. Veri kümesinin makine öğrenmesinde kullanıma hazır olması için yapılması gereken başka şeyler de var.
Kullanmakta olduğunuz veri kümesinin CRS_DEP_TIME sütunu, planlanan kalkış saatlerini gösterir. 500’den fazla benzersiz değer içeren bu sütundaki sayıların tanecikliği, makine öğrenmesi modelinin doğruluğunu olumsuz yönde etkileyebilir. Bu durum, gruplama veya bölme denen bir teknik ile çözülebilir. Bu sütundaki her sayıyı 100’e bölüp en yakın tamsayıya yuvarladığınızı düşünün. Örneğin 1030 değeri 10 olarak, 1925 değeri ise 19 olarak gösterilir. Böylece sütunda en fazla 24 benzersiz değer olur. Sezgisel olarak mantıklıdır, çünkü bir uçuşun 10:30'da mı yoksa 10:40'ta mı kalktığı önemli değildir. 10:30'da ya da 17:30'da ayrılması çok önemlidir.
Ayrıca, veri kümesinin ORIGIN ve DEST sütunları, kategorik makine öğrenmesi değerlerini temsil eden havaalanı kodlarını içerir. Bu sütunların, gösterge değişkenlerini içeren ayrık sütunlara dönüştürülmesi gerekir. Buna bazen “kukla” değişkenler de denir. Diğer bir deyişle, beş havaalanı kodu içeren ORIGIN sütununun beş sütuna dönüştürülmesi gerekir. Böylece her havaalanı için bir sütun elde edilir ve her sütunda söz konusu uçuşun bu havaalanından kalkıp kalkmadığını gösteren 1 ve 0 değerleri bulunur. DEST sütununun da benzer şekilde dönüştürülmesi gerekir.
Bu alıştırmada, CRS_DEP_TIME sütunundaki kalkış saatlerini “gruplayıp” Pandas’ın get_dummies yöntemini kullanarak ORIGIN ve DEST sütunlarından gösterge sütunları oluşturacaksınız.
DataFrame’in ilk beş satırını görüntülemek için şu komutu kullanın:
df.head()CRS_DEP_TIME sütununda, askeri biçimde yazılmış saatleri ifade etmek üzere 0 ila 2359 arasında değerlerin bulunduğuna dikkat edin.
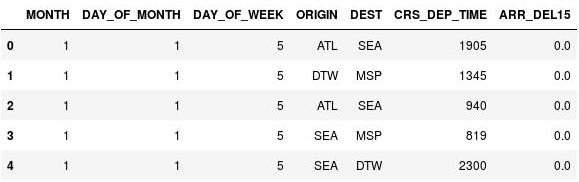
Kalkış saatleri gruplanmamış DataFrame
Kalkış saatlerini gruplamak için aşağıdaki deyimleri kullanın:
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()CRS_DEP_TIME sütunundaki sayıların şimdi 0 ila 23 arasında olduğunu onaylayın:
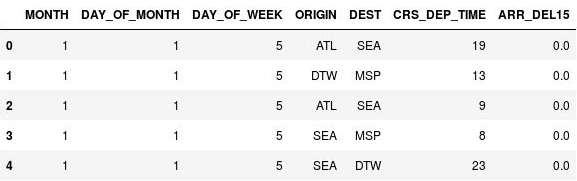
Kalkış saatleri gruplanmış DataFrame
Şimdi aşağıdaki deyimleri kullanarak ORIGIN ve DEST sütunlarından gösterge sütunları oluşturup ORIGIN ve DEST sütunlarını kaldırın:
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()Oluşturulan DataFrame’i incelediğinizde ORIGIN ve DEST sütunlarının yerine, özgün sütunlardaki havaalanı kodlarına karşılık gelen sütunlar olduğunu göreceksiniz. Yeni sütunlarda, bir uçuşun söz konusu havaalanından kalkıp kalkmadığını veya bu havaalanına varıp varmadığını belirten 1 ve 0 değerleri bulunur.
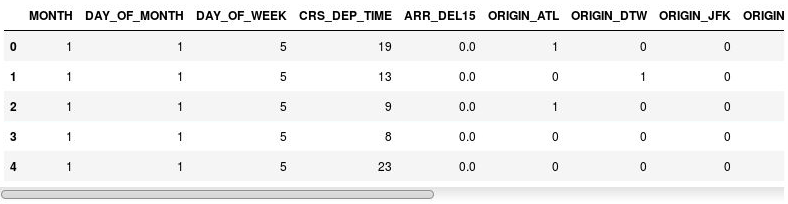
Gösterge sütunları içeren DataFrame
Not defterini kaydetmek için Dosya ->Kaydet ve Denetim Noktası komutunu kullanın.
Başlangıçtaki durumuna göre oldukça farklı görünen bu veri kümesi, artık makine öğrenmesi için iyileştirilmiş haldedir.