Veri kümelerini test ve eğitim
Modeli eğitmek için kullandığımız veriler genellikle eğitim veri kümesi olarak adlandırılır. Bunu zaten iş başında gördük. Sinir bozucu bir şekilde, modeli gerçek dünyada kullandığımızda, eğitimden sonra modelimizin ne kadar iyi çalışacağını bilmiyoruz. Bunun nedeni eğitim veri kümemizin gerçek dünyadaki verilerden farklı olmasıdır.
Fazla uygunluk nedir?
Bir model, eğitim verileri üzerinde diğer verilerden daha iyi çalışıyorsa fazla uygun olur. Bu ad, modelin diğer verilere uygulanacak geniş kurallar bulmak yerine eğitim kümesinin ezberlenmiş ayrıntılarına uygun olduğu gerçeğini ifade eder. Fazla uygunluk yaygındır, ancak arzu edilmez. Günün sonunda yalnızca modelimizin gerçek dünya verileri üzerinde ne kadar iyi çalıştığına dikkat ederiz.
Fazla uygunluktan nasıl kaçınabiliriz?
Çeşitli yollarla fazla uygunluktan kaçınabiliriz. En basit yol, daha basit bir modele sahip olmak veya gerçek dünyada görülenlerin daha iyi bir gösterimini sağlayan bir veri kümesi kullanmaktır. Bu yöntemleri anlamak için gerçek dünya verilerinin şöyle göründüğü bir senaryo düşünün:
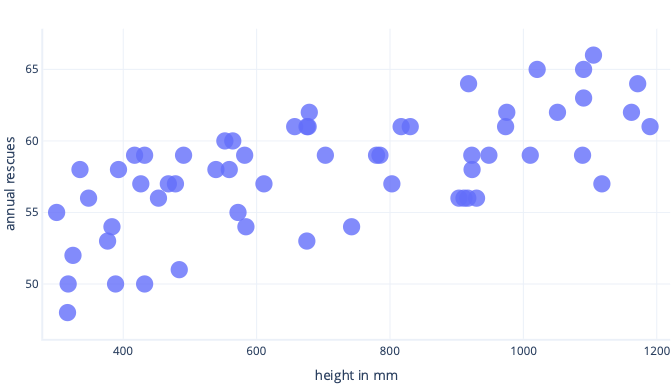
Ancak yalnızca beş köpek hakkında bilgi topladığımızı ve bunu karmaşık bir çizgiye uyacak şekilde eğitim veri kümemiz olarak kullandığımızı düşünelim. Bunu yapabilirsek, çok iyi sığdırabiliriz:
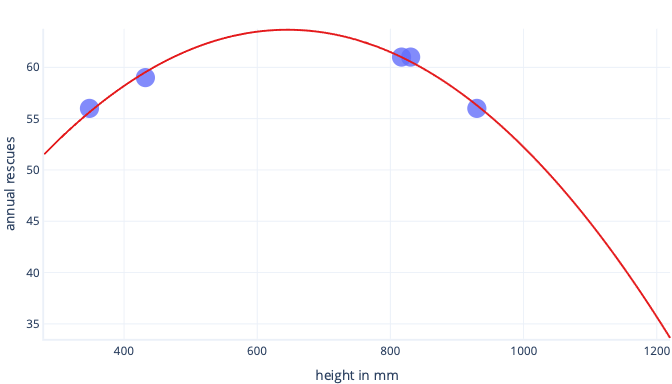
Bu gerçek dünyada kullanıldığında, yanlış olduğu ortaya çıkan tahminler yaptığını göreceğiz:
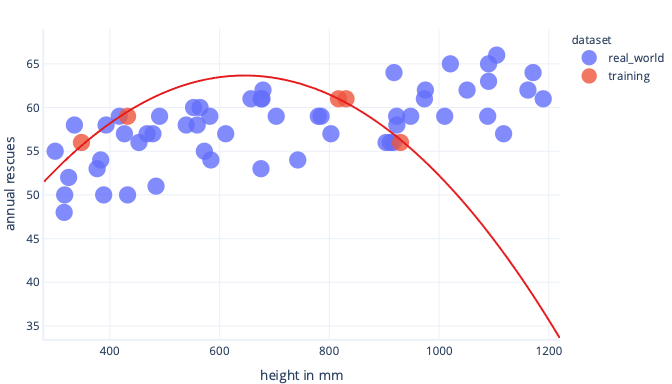
Daha temsili bir veri kümemiz ve daha basit bir modelimiz varsa, sığdırdığımız çizgi daha iyi (mükemmel olmasa da) tahminler yapar:
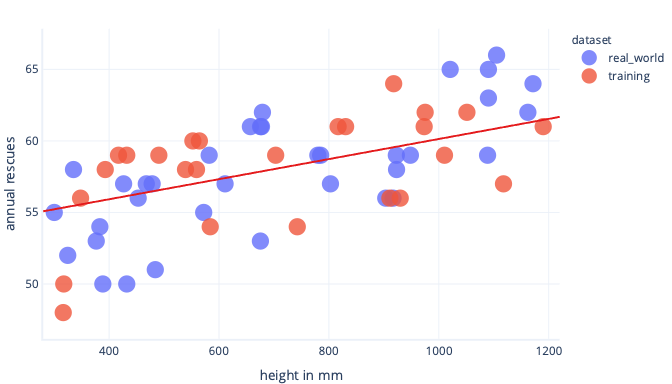
Fazla uygunluktan kaçınmanın ücretsiz bir yolu, model genel kuralları öğrendikten sonra ancak model fazla uygun hale gelmeden önce eğitimi durdurmaktır. Bu, modelimize ne zaman fazla sığdırmaya başladığımızı algılamayı gerektirir. Bunu bir test veri kümesi kullanarak yapabiliriz.
Test veri kümesi nedir?
Doğrulama veri kümesi olarak da adlandırılan test veri kümesi, eğitim veri kümesine benzer bir veri kümesidir. Aslında test veri kümeleri genellikle büyük bir veri kümesi alınarak ve bölünerek oluşturulur. Bir kısmı eğitim veri kümesi, diğeri ise test veri kümesi olarak adlandırılır.
Eğitim veri kümesinin işi modeli eğitmektir; Eğitimi zaten gördük. Test veri kümesinin işi, modelin ne kadar iyi çalıştığını denetlemektir; doğrudan eğitime katkıda bulunmaz.
Tamam ama ne anlamı var ki?
Test veri kümesinin noktası iki kattır.
İlk olarak, eğitim sırasında test performansının iyileştirilmesi durursa durdurabiliriz; Devam etmenin bir anlamı yok. Devam ederse, modeli test veri kümesinde yer almayan ve fazla uygunluk gösteren eğitim veri kümesi hakkındaki ayrıntıları öğrenmesi için teşvik edebiliriz.
İkincisi, eğitimden sonra bir test veri kümesi kullanabiliriz. Bu, son modelin daha önce görmediği "gerçek dünya" verilerini gördüğünde ne kadar iyi çalışacağını gösterir.
Maliyet işlevleri için bu ne anlama gelir?
Hem eğitim hem de test veri kümelerini kullandığımızda iki maliyet işlevini hesaplıyoruz.
İlk maliyet işlevi, daha önce gördüğümüz gibi eğitim veri kümesini kullanmaktır. Bu maliyet işlevi iyileştiriciye beslenir ve modeli eğitmek için kullanılır.
İkinci maliyet işlevi test veri kümesi kullanılarak hesaplanır. Modelin gerçek dünyada ne kadar iyi çalışabileceğini denetlemek için bunu kullanırız. Maliyet işlevinin sonucu modeli eğitmek için kullanılmaz. Bunu hesaplamak için eğitimi duraklatacak, modelin test veri kümesinde ne kadar iyi performans sergilediğimize bakacağız ve ardından eğitimi sürdüreceğiz.