Spark'ı tanımaya başlama
Azure Databricks'te Apache Spark ile verileri işleme ve analiz etme hakkında daha iyi bilgi edinmek için temel mimariyi anlamak önemlidir.
Yüksek düzey genel bakış
Azure Databricks hizmeti yüksek düzeyden Azure aboneliğinizdeki Apache Spark kümelerini başlatır ve yönetir. Apache Spark kümeleri, tek bir bilgisayar olarak değerlendirilen ve not defterlerinden verilen komutların yürütülmesini işleyen bilgisayar gruplarıdır. Kümeler, ölçeği ve performansı geliştirmek için verilerin işlenmesinin birçok bilgisayarda paralelleştirilmesini sağlar. Spark sürücüsü ve çalışan düğümlerinden oluşur. Sürücü düğümü çalışan düğümlerine iş gönderir ve belirtilen veri kaynağından veri çekmelerini söyler.
Databricks'te not defteri arabirimi genellikle sürücü programıdır. Bu sürücü programı, programın ana döngüsünü içerir ve kümede dağıtılmış veri kümeleri oluşturur, ardından işlemleri bu veri kümelerine uygular. Sürücü programları, dağıtım konumundan bağımsız olarak Bir SparkSession nesnesi aracılığıyla Apache Spark'a erişir.
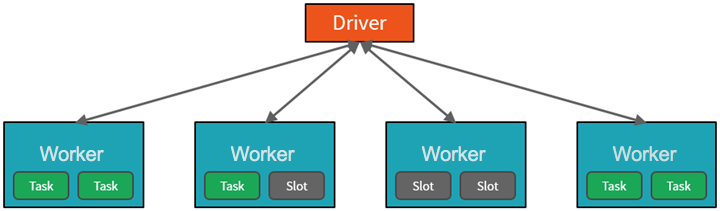
Microsoft Azure kümeyi yönetir ve kullanımınıza ve kümeyi yapılandırırken kullanılan ayara göre gerektiğinde otomatik olarak ölçeklendirir. Otomatik sonlandırma da etkinleştirilebilir ve bu da Azure'ın belirtilen sayıda işlem yapılmadığında kümeyi sonlandırmasına olanak tanır.
Spark işleri ayrıntılı olarak
Kümeye gönderilen çalışma, gerektiği kadar bağımsız işe bölünür. İş, Kümenin düğümleri arasında bu şekilde dağıtılır. İşler görevlere daha da alt bölümlere ayrılır. Bir işin girişi bir veya daha fazla bölüme ayrılır. Bu bölümler her yuva için çalışma birimidir. Görevler arasında bölümlerin yeniden düzenlenmesi ve ağ üzerinden paylaşılması gerekebilir.
Spark'ın yüksek performansının sırrı paralelliktir. Dikey ölçeklendirme (tek bir bilgisayara kaynak ekleyerek) sınırlı miktarda RAM, İş Parçacığı ve CPU hızıyla sınırlıdır, ancak kümeler yatay olarak ölçeklendirilir ve gerektiğinde kümeye yeni düğümler eklenir.
Spark işleri iki düzeyde paralelleştirir:
- İlk paralelleştirme düzeyi yürütücüdür : çalışan düğümünde çalışan bir Java sanal makinesi (JVM), genellikle düğüm başına bir örnek.
- İkinci paralelleştirme düzeyi, sayısı her düğümün çekirdek ve CPU sayısına göre belirlenen yuvadır .
- Her yürütücü, paralelleştirilmiş görevlerin atanabileceği birden çok yuvaya sahiptir.
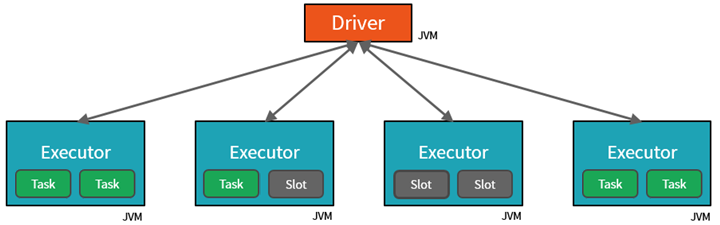
JVM doğal olarak çok iş parçacıklı olsa da, sürücüdeki çalışmayı koordine eden tek bir JVM'nin sınırlı bir üst sınırı vardır. Sürücü, çalışmayı görevlere bölerek, paralel yürütme için çalışan düğümlerindeki yürütücülerdeki *yuvalara iş birimleri atayabilir. Buna ek olarak, sürücü paralel işleme için dağıtılabilmesi için verilerin nasıl bölümleneceğini belirler. Bu nedenle, sürücü her göreve bir veri bölümü atar, böylece her görev hangi veri parçasını işlendiğini bilir. Başlatıldıktan sonra her görev kendisine atanan veri bölümünü getirir.
İşler ve aşamalar
Gerçekleştirilen çalışmaya bağlı olarak, birden çok paralelleştirilmiş iş gerekebilir. Her iş aşamalara ayrılır. Yararlı bir benzetme, işin bir ev inşa etmek olduğunu hayal etmektir:
- İlk aşama temeli atmak olacaktır.
- İkinci aşama duvarları dikmek olacaktır.
- Üçüncü aşama çatıyı eklemek olacaktır.
Bu adımlardan herhangi birini sıra dışı yapmaya çalışmak mantıklı değildir ve aslında imkansız olabilir. Benzer şekilde Spark, her şeyin doğru sırada yapıldığından emin olmak için her işi aşamalara ayırır.