Verileri görselleştirme
Veri sorgularının sonuçlarını analiz etmenin en sezgisel yollarından biri bunları grafik olarak görselleştirmektir. Azure Databricks'teki not defterleri kullanıcı arabiriminde grafik özellikleri sağlar ve bu işlevsellik ihtiyacınız olanı sağlamadığında, not defterinde veri görselleştirmeleri oluşturmak ve görüntülemek için birçok Python grafik kitaplığından birini kullanabilirsiniz.
Yerleşik not defteri grafiklerini kullanma
Azure Databricks'te spark not defterinde bir veri çerçevesi görüntüleyip SQL sorgusu çalıştırdığınızda, sonuçlar kod hücresinin altında görüntülenir. Varsayılan olarak, sonuçlar tablo olarak işlenir, ancak burada gösterildiği gibi sonuçları görselleştirme olarak görüntüleyebilir ve grafiğin verileri nasıl görüntüleyebileceğini özelleştirebilirsiniz:
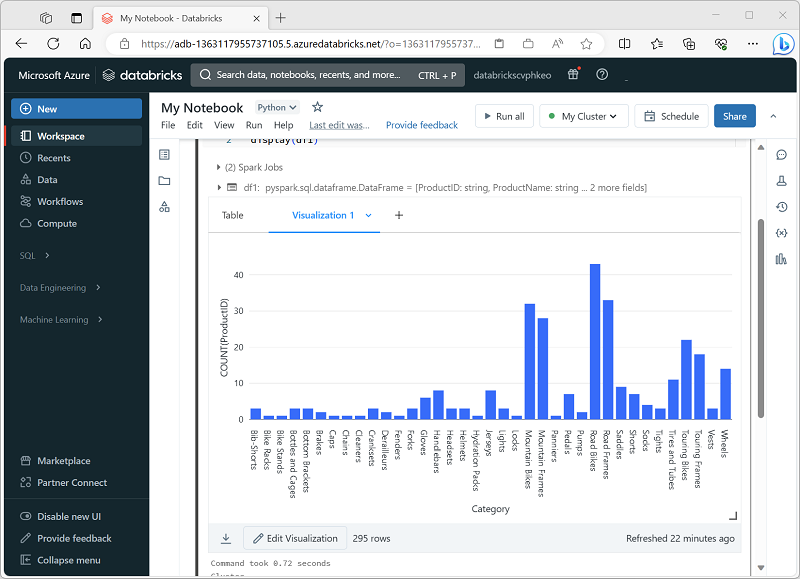
Not defterlerindeki yerleşik görselleştirme işlevi, verileri görsel olarak hızlı bir şekilde özetlemek istediğinizde kullanışlıdır. Verilerin nasıl biçimlendirildiğini daha fazla denetlemek veya sorguda zaten topladığınız değerleri görüntülemek istediğinizde, kendi görselleştirmelerinizi oluşturmak için grafik paketi kullanmayı düşünmelisiniz.
Kodda grafik paketlerini kullanma
Kodda veri görselleştirmeleri oluşturmak için kullanabileceğiniz birçok grafik paketi vardır. Python özellikle çok çeşitli paketleri destekler; çoğu temel Matplotlib kitaplığı üzerinde oluşturulmuş. Grafik kitaplığının çıkışı not defterinde işlenebilir ve satır içi veri görselleştirmeleri ve markdown hücreleriyle verileri almak ve işlemek için kodu birleştirerek açıklama sağlamayı kolaylaştırır.
Örneğin, bu modülde daha önce keşfedilen varsayımsal ürün verilerinden verileri toplamak için aşağıdaki PySpark kodunu kullanabilir ve toplanan verilerden bir grafik oluşturmak için Matplotlib'i kullanabilirsiniz.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Matplotlib kitaplığı, verilerin Spark veri çerçevesi yerine Pandas veri çerçevesinde olmasını gerektirir, bu nedenle toPandas yöntemi bunu dönüştürmek için kullanılır. Kod daha sonra belirtilen boyuta sahip bir şekil oluşturur ve sonuçta elde edilen çizimi göstermeden önce özel özellik yapılandırmasına sahip bir çubuk grafik çizer.
Kod tarafından üretilen grafik aşağıdaki görüntüye benzer olacaktır:
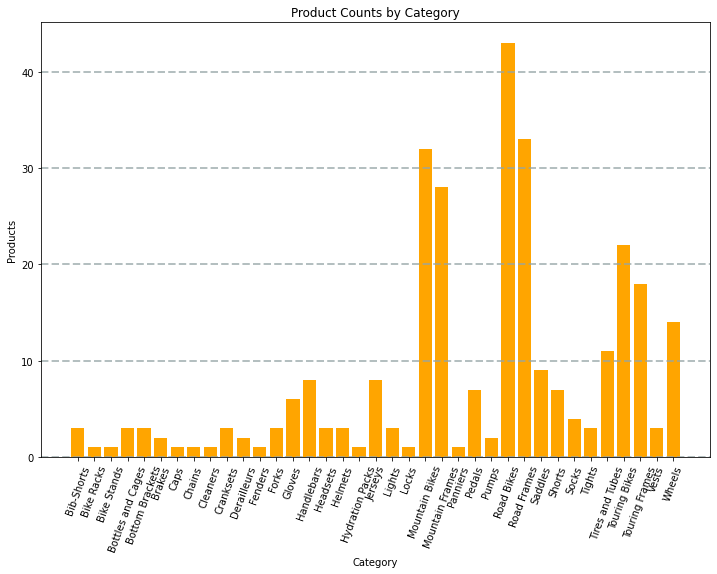
Matplotlib kitaplığını kullanarak birçok grafik türü oluşturabilirsiniz; veya tercih ederseniz, seaborn gibi diğer kitaplıkları kullanarak yüksek oranda özelleştirilmiş grafikler oluşturabilirsiniz.
Not
Matplotlib ve Seaborn kitaplıkları, küme için Databricks Runtime'a bağlı olarak Databricks kümelerine zaten yüklenmiş olabilir. Yoksa veya henüz yüklü olmayan farklı bir kitaplık kullanmak istiyorsanız, bunu kümeye ekleyebilirsiniz. Ayrıntılar için Azure Databricks belgelerindeki Küme Kitaplıkları'na bakın.