Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Not
Bu makalede açıklanan el ile analizi otomatikleştirmek için bkz . Kullanılabilirlik grubu sistem durumu olaylarını tanılamak için AGDiag kullanma.
Bu makalede, kullanılabilirlik grubunuzun neden yük devreddiğini belirlemenize yardımcı olacak sorun giderme adımları sağlanır.
Always On sistem durumu sorunlarının veya yük devretmenin etkileri
Always On, birincil çoğaltmayı, temel alınan kümeyi ve sistem durumunu barındıran Microsoft SQL Server örneğinin sistem durumunu güvence altına almak için farklı mekanizmalar aracılığıyla sağlam sistem durumu izleme uygular. Bir Windows kümesi veya Always On sistem durumu sorunu belirlendiğinde üretim iş yükü kısa bir süre kesintiye uğrar.
Bir sistem durumu algılandığında, genellikle aşağıdaki olay dizisi gerçekleşir. Bu sorun gidericinin tamamında, aşağıdaki olaylara başvuruda sistem durumu olayları belirtilir:
Kullanılabilirlik grubu çoğaltmaları ve veritabanları birincil rolden çözüm rolüne geçiş gerçekleştirir.
Kullanılabilirlik grubu veritabanları çevrimdışına geçirilir ve artık erişilebilir değildir.
Windows Kümesi, kümelenmiş kullanılabilirlik grubu kaynağını başarısız olarak işaretler.
Windows Kümesi, kullanılabilirlik grubu rolünü yeniden çevrimiçi duruma getirmeye çalışır (özgün veya otomatik yük devretme iş ortağı çoğaltması üzerinde).
Always On ve Windows Kümesi sistem durumu izlemesi tarafından iyi durumda olduğu algılanırsa kullanılabilirlik grubu rolü başarıyla çevrimiçi olur.
Başarılı olursa, kullanılabilirlik grubu çoğaltmaları ve veritabanları birincil role geçirilir ve kullanılabilirlik grubu veritabanları çevrimiçi olur ve uygulamanız tarafından erişilebilir.
Uygulamalar kullanılabilirlik grubu veritabanlarına erişemiyor
Bir sistem durumu durumu algılandığında, kullanılabilirlik grubu çoğaltması ve veritabanları Çözümlenme rolüne geçirilir ve kullanılabilirlik grubu veritabanları çevrimdışına alınır. Çoğaltma birincil rolde (özgün çoğaltma sunucusunda veya yük devretme ortağı çoğaltma sunucusunda) çevrimiçi olduktan sonra, çoğaltma ve veritabanları yeniden çevrimiçine geçiş gerçekleştirir. Çoğaltma ve veritabanları çözümlenirken ve çevrimdışıyken, bu kullanılabilirlik grubu veritabanlarına erişmeye çalışan uygulamalar başarısız olur ve "Hata 983" iletisi oluşturur: Unable to access availability database.... Sql Server başarısız oturum açma girişimlerini kaydedecek şekilde yapılandırılmışsa bu hata Microsoft SQL Server hata günlüğüne de kaydedilir:
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
Kullanılabilirlik grubunun, birincil rolde yeniden çevrimiçi duruma gelmeden önce Çözümlenme rolünde olduğu süre genellikle yalnızca birkaç saniye, hatta bir saniyeden kısa sürer.
Always On kullanılabilirlik grubu sistem durumu olaylarını veya yük devretmeyi tanımlama ve tanılama
1. AlwaysOn sistem durumu eğilimlerini belirleme
Tek bir Always On sistem durumu olayını araştırabilirsiniz veya üretim kesintisine uğrayan son veya devam eden sistem durumu sorunları eğilimi olabilir. Aşağıdaki sorular, üretim ortamınızda bu sistem durumu sorunlarıyla ilgili olabilecek son değişiklikleri daraltmanıza ve ilişkilendirmenize yardımcı olabilir:
- Always On veya küme durumu olayları eğilimi ne zaman başladı?
- Sistem durumu olayları belirli bir günde mi gerçekleşir?
- Sistem durumu olayları günün belirli bir saatinde meydana geliyor mu?
- Sağlık olayları ayın belirli bir günü veya haftası içinde mi gerçekleşir?
Bir eğilim algılarsanız sistemdeki zamanlanmış bakımı (sanal ortamdaki konak sistemi), ETL toplu işlemlerini ve bu sistem durumu olaylarıyla bağıntılı olabilecek diğer işleri denetleyin. Sistem bir sanal makineyse, kesintiler sırasında ortaya çıkmış olabilecek değişiklikler için konak sistemini araştırın.
Sistem durumu sorunlarının zamanıyla (örneğin, kullanıcıların sistemde ilk kez oturum açtığında veya kullanıcılar öğle yemeğinden döndükten sonra) bağıntılı olabilecek meşgul geçici üretim iş yüklerini göz önünde bulundurun.
Not
Bu, hafta ve ay boyunca performans verilerini toplama planını göz önünde bulundurmak için iyi bir zamandır. Sistemin en yoğun olduğu zamanları daha iyi anlamak için , Memory::Available MBytesve MSSQLServer:SQL Statistics::Batch Requests/secgibi Processor Information::% Processor TimeWindows performans izleyici sayaçlarını ölçebilirsiniz.
2. Küme günlüğünü gözden geçirin
Windows Küme günlüğü, Always On veya küme durumu olayının türünü ve ayrıca olaya neden olan algılanan sistem durumu durumunu tanımlamak için kullanılacak en kapsamlı günlükdür. Küme günlüğünü oluşturmak ve açmak için şu adımları izleyin:
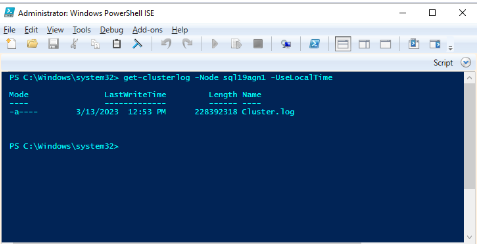
Sistem durumu olayı sırasında birincil çoğaltmayı barındıran küme düğümünde Windows Küme günlüğünü oluşturmak için Windows PowerShell'i kullanın. Örneğin, SQL Server tabanlı sunucu adı olarak 'sql19agn1' kullanarak yükseltilmiş bir PowerShell penceresinde aşağıdaki cmdlet'i çalıştırın:
get-clusterlog -Node sql19agn1 -UseLocalTime
Not
Varsayılan olarak, günlük dosyası %WINDIR%\cluster\reports içinde oluşturulur.
3. Küme günlüğünde sistem durumu olayını bulun
Always On, kullanılabilirlik grubu durumunu izlemek için çeşitli sistem durumu izleme mekanizmaları kullanır. Windows Kümesi sistem durumu olayına ek olarak (Windows Kümesi küme düğümleri arasında bir sistem durumu sorunu algılar), Always On'un dört farklı sistem durumu denetimi türü vardır:
- SQL Server hizmeti çalışmıyor
- SQL Server kiralama zaman aşımı
- SQL Server sistem durumu denetimi zaman aşımı
- SQL Server iç sistem durumu sorunu
Küme günlüğünde dizesini [hadrag] Resource Alive result 0arayarak bu Always On özel durum olaylarından herhangi birini bulabilirsiniz. Bu olaylardan herhangi biri algılandığında bu dize küme günlüğüne kaydedilir. Örneğin:
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
Her Zaman Açık sistem durumu sorunlarının özet raporunu oluşturabilmek için küme günlüğündeki tüm sistem durumu olaylarını bulmak için bir araç kullanabilirsiniz. Bu, kronolojik eğilimleri belirlemek ve belirli bir Always On sistem durumunun yinelenen olup olmadığını belirlemek için yararlı olabilir. Aşağıdaki ekran görüntüsünde, küme günlüğünde dizeyi içeren tüm satırları bulmak için bir metin düzenleyicisinin (bu örnekte Not Defteri++) nasıl kullanılacağı gösterilmektedir [hadrag] Resource Alive result 0 :

Yük devretmeyi tetikleyen sistem durumu sorununu belirleme ve çözme
Birincil çoğaltmanın küme günlüğündeki sistem durumu sorunlarını belirlemek için, bunları aşağıdaki bölümlerde açıklanan sorunlarla karşılaştırın. AG yük devretmenin yaygın nedenleri şunlardır:
- Küme durumu olayı
- SQL Server hizmeti çalışmıyor (Always On sistem durumu olayı)
- Kira zaman aşımı (Always On sistem durumu olayı)
- Sistem durumu denetimi zaman aşımı (Always On sistem durumu olayı)
- SQL Server sistem durumu (Always On sistem durumu olayı)
Küme durumu olayları
Microsoft Windows Kümesi, kümedeki üye sunucuların durumunu izler. Sistem durumu sorunu algılanırsa, küme üyesi sunucu kümeden kaldırılabilir. Ayrıca, küme kaynakları (kaldırılan küme üyesi sunucusunda barındırılan kullanılabilirlik grubu rolü dahil) otomatik yük devretme için yapılandırılmışsa kullanılabilirlik grubu yük devretme ortağı çoğaltmasına taşınır.
Belirtiler
Aşağıda, küme günlüğündeki bir küme durumu olayı örneği verilmiştır. Bunu bulmak için, kullanılabilirlik grubu rol değişikliği veya Cluster service has terminated yük devretme sırasında mevcut olabileceği için Lost quorum veya araması yapabilirsiniz.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
Bu olayı tanımlamanın bir diğer yolu da Windows sistem olay günlüğünde arama yapmaktır:
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Küme durumu olayını tanılama
Windows olay günlüğündeki hatalar (Olaylar 1135 ve 1177) ağ bağlantısının olayın bir nedeni olduğunu gösterir. Bu, küme durumu sorununun algı olmasının en yaygın nedenidir. Aşağıdaki örnekte, diğer küme üyesi sunucuların kullanılabilirlik grubu birincil çoğaltmasını barındıran bu sunucuyla iletişim kuramadığı ve bu sorunun kümeden küme düğümünün kaldırılmasını tetiklediği gösterilmektedir:
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
Düğüme bağlantı hatasının kanıtı için küme günlüğünde arama yapabilirsiniz. küme günlüğünde bulduğunuz Lost quorumkonumdan, , unreachableve is brokengibi Failed to connect to remote endpointdizeleri geriye doğru arayın.
Çözüm
Küme durumu izlemenin konak ortamı için uygun olduğundan emin olun. Microsoft Azure'da barındırılan SQL Server Always On kullanılabilirlik grupları hakkında daha fazla bilgi için bkz . Windows Server Yük Devretme Kümesine genel bakış - Azure VM'lerinde SQL Server.
Gerekirse, bir destek olayı açmak için Microsoft Windows Yüksek Kullanılabilirlik desteğine başvurmayı göz önünde bulundurun.
SQL Server hizmeti çalışmıyor: Always On sistem durumu olayı
Always On sistem durumu izleme, kullanılabilirlik grubu birincil çoğaltmasını barındıran SQL Server hizmetinin artık çalışıp çalışmadığını algılayabilir.
Belirtiler
'ag' kullanılabilirlik grubu rolü için bir işlem kimliği 0döndürdüklerinden QueryServiceStatusEx bir hata olduğunu gösteren küme günlüğü raporunun bir örneği aşağıda verilmiştir:
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
SQL Hizmeti kapatma olaylarını tanılama
Beklenmeyen sql server kapatması için Windows sistem olay günlüğünü ve SQL Server hata günlüğünü denetleyin.
SQL Server bir sistem kapatma veya yönetici kapatması tarafından kapatıldıysa, SQL Server hata günlüğünde aşağıdaki girdiyi görürsünüz:
2023-03-10 09:38:46.73 spid9s SQL Server is terminating in response to a 'stop' request from Service Control Manager. This is an informational message only. No user action is required.
Windows sistem olay günlüğü aşağıdaki hata girdisini gösterir:
Information 3/10/2023 9:41:06 AM Service Control Manager 7036 None The SQL Server (MSSQLSERVER) service entered the stopped state.
SQL Server beklenmedik bir şekilde kapanırsa Windows sistem olay günlüğü aşağıdaki hata girdisini gösterir:
Error 3/10/2023 8:37:46 AM Service Control Manager 7034 None The SQL Server (MSSQLSERVER) service terminated unexpectedly. It has done this 1 time(s).
İpuçları için SQL Server hata günlüğünün sonunu denetleyin. Hata günlüğü aniden biterse, bu, zorla kapatıldığı anlamına gelir. Örneğin, SQL Server Görev Yöneticisi kullanılarak sonlandırıldıysa, SQL Server hata raporu işlemin kapanmasına neden olmuş olabilecek iç sorunlar hakkında herhangi bir bilgi ortaya çıkarmaz.
Çözüm
SQL Server hizmetinin beklenmeyen sonlandırmalarını en aza indirmek için yetkili veritabanı ve sistem yöneticilerinin sisteme erişimi olduğundan emin olun. Olay günlüklerini inceledikten sonra, bir hizmetin neden beklenmedik şekilde sonlandırılması gerektiğini araştırın.
SQL Server iç sistem durumu sorunu SQL Server'ın beklenmedik bir şekilde sonlandırılmasına neden olursa, SQL hata günlüğünün sonunda olası bir önemli özel durumun (bellek dökümü tanılama dosyasının oluşturulması dahil) ipuçları olabilir. İpuçlarını gözden geçirin ve gerekli eylemi gerçekleştirin. Döküm dosyası bulursanız Microsoft SQL Server desteğine başvurun ve daha fazla araştırma için SQL Server hata günlüğü ve döküm dosyası içeriğini sağlayın.
Kira zaman aşımı: Her Zaman Açık sistem durumu olayı
Always On, SQL Server'ın yüklü olduğu bilgisayarın durumunu izlemek için bir "kiralama" mekanizması kullanır. Varsayılan kira zaman aşımı 20 saniyedir.
Belirtiler
Burada, küme günlüğünden AlwaysOn kiralama zaman aşımının örnek bir çıktısı verilmişti. Küme günlüğünde kiralama zaman aşımını bulmak için bu dizelerde arama yapabilirsiniz.
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
Kira zaman aşımı hakkında daha fazla bilgi için, Her Zaman Açık kullanılabilirlik grupları için Kiralama, küme ve sistem durumu denetim zaman aşımları yönergeleri ve Mekanik bölümündeki Kira Mekanizması bölümüne bakın.
Always On kira zaman aşımı olaylarını tanılama ve çözme
Kiralama zaman aşımını tetikleyebilecek iki ana sorun vardır:
SQL Server bellek dökümü: SQL Server erişim ihlali, onay veya zamanlayıcı kilitlenmesi gibi bazı iç sistem durumu olayları algıladığında, SQL Server \LOG klasöründe bir tanılama döküm dosyası (.mdmp) oluşturur. Bellek dökümü oluşturma işlemi SQL Server yürütmesini kısa bir süre askıya alır. Bu dönemde kiralama mekanizması hizmet yanıtı ve tetikleyici eylemi eksikliğini algılayabilir. Daha fazla bilgi için bkz . Döküm oluşturmanın etkisi.
Sistem genelinde performans sorunu: Kiralama zaman aşımı sql Server sistem durumu sorununu belirtmez. Bunun yerine, SQL Server tabanlı sunucunun durumunu da etkileyen sistem genelinde bir sistem durumu sorununu gösterebilir.
- Sistemde yüksek CPU kullanımı (%100'e yakın).
- Yetersiz bellek koşulları - düşük sanal bellek ve/veya işlemlerden biri disk belleğine alınıyor.
- Çekirdek kaybı nedeniyle WSFC çevrimdışı oluyor
- Performansı etkileyen ve kira süresinin dolmasına neden olan VM azaltma.
Çözüm
Ayrıntılı sorun giderme adımları için bkz . MSSQLSERVER_19407. En yaygın iki sorun şunlardır:
1. SQL Sunucusu döküm dosyası tanılama
SQL Server erişim ihlali, onaylama veya kilitlenme zamanlayıcıları gibi bir iç sistem durumu sorunu algılayabilir. Bu durumda, program tanılama için SQL Server işleminin SQL Server \LOG klasöründe bir mini döküm dosyası (.mdmp) oluşturur. Mini döküm dosyası diske yazılırken SQL Server işlemi birkaç saniye boyunca dondurulur. Bu süre boyunca, SQL Server işlemi içindeki tüm iş parçacıkları, Always On sistem durumu izlemesi tarafından izlenen kira iş parçacığını içeren donmuş durumdadır. Bu nedenle Always On kiralama zaman aşımı algılayabilir.
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
Bu sorunu çözmek için, kök neden için bellek dökümü dosyası tanılamasının incelenmesi gerekir. Daha fazla araştırma için SQL Server hata günlüğünü ve döküm dosyası içeriğini sağlamak için Microsoft SQL Server desteğine başvurmayı göz önünde bulundurun.
2. Yüksek CPU kullanımı veya diğer sistem performansı sorunu
Kira zaman aşımı, SQL Server da dahil olmak üzere tüm sistemi etkileyen bir performans sorununu gösterir. Sistem sorununu tanılamak için Always On sistem durumu tanılama, küme günlüğündeki performans izleme verilerini raporlar ve kira zaman aşımı olayını içerir. Performans verileri yaklaşık 50 saniyelik bir süreyle kira zaman aşımı olayına kadar devam eder ve CPU kullanımı, boş bellek ve disk gecikme süresini bildirir.
Aşağıda, küme günlüğünde kira zaman aşımını gösteren bildirilen performans verilerine bir örnek verilmiştır. Bu örnek çıktıda, kira zaman aşımıyla ilgili olabilecek yüksek genel CPU kullanımı.
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
Performans verileri kiralama zaman aşımı sırasında yüksek CPU kullanımı, düşük bellek koşulu veya yüksek disk gecikme süresi gösteriyorsa, bu belirtileri araştırmak için birincil çoğaltmada tam gün için Performans İzleyicisi verileri toplamaya başlayın. Performans izleyicisi verilerini daha uzun bir süre boyunca yakalayarak, bu kaynaklar için temel ve en yüksek değerleri daha iyi tanımlayabilir ve kiralama zaman aşımı oluştuğunda bu kaynaklardaki değişiklikleri izleyebilirsiniz. Bu verileri toplarken, SQL Server'da bu kaynak sorunlarının ve sistem durumu olaylarının zamanıyla ilişkili belirli zamanlanmış veya geçici iş yükleri olup olmadığını göz önünde bulundurun.
Aşağıdakiler de dahil olmak üzere aynı sistem kaynağı kullanımını bildiren sayaçları da yakalamanız gerekir:
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
Sistem durumu denetimi zaman aşımı: Her Zaman Açık sistem durumu olayı
Always On, SQL Server'ın durumunu ve istemci uygulamalarının bağlanabilmesini izlemek için bir sistem durumu denetimi mekanizması kullanır.
Belirtiler
Bir kullanılabilirlik grubu çoğaltması birincil role geçtiğinde, Always On sistem durumu izleme SQL Server örneğine yerel bir ODBC bağlantısı kurar. Always On bağlı ve izlemedeyken, KULLANıLABILIRlik grubunun sistem durumu denetim zaman aşımı için ayarlanan süre içinde SQL Server ODBC bağlantısı üzerinden yanıt vermezse (varsayılan değer 30 saniyedir), sistem durumu denetimi zaman aşımı olayı tetiklenir. Bu durumda, kullanılabilirlik grubu birincil rolden Çözümleme rolüne geçiş yapar ve bunu yapacak şekilde yapılandırılmışsa yük devretmeyi başlatır.
Sistem durumu denetimi zaman aşımları hakkında daha fazla bilgi için, Mekanikler ve Always On kullanılabilirlik grupları için kira, küme ve sistem durumu denetim zaman aşımları yönergeleri bölümündeki "Sistem durumu denetim zaman aşımı işlemi" bölümüne bakın.
Aşağıda küme günlüğünde bildirildiği gibi AlwaysOn sistem durumu denetimi zaman aşımı vardır:
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
Always On sistem durumu denetimi zaman aşımı olayını tanılama ve çözme
Aşağıdaki bölüm, bulabileceğiniz ve algılanan ve bildirilen Always On sistem durumu denetim zaman aşımlarıyla ilişkili "ekmek kırıntısı" olayları için SQL Server günlüklerini gözden geçirmenize yardımcı olur. Burada incelenen günlükler küme günlüğünü (sistem durumu denetimi zaman aşımının onaylandığı yer), system_health genişletilmiş olay günlüklerini ve SQL Server hata günlüklerini (her ikisi de SQL Server \LOG klasöründe bulunur) ve Windows sistem olay günlüğünü içerir. Sistem durumu denetimi zaman aşımının nedenini kapsamanıza yardımcı olabilecek bağıntılı olayları aramak için bunları ve diğer günlükleri kullanın.
1. Verimsiz zamanlayıcı olaylarını denetleyin
Always On sistem durumu denetimi zaman aşımı genellikle SQL Server'daki "verimsiz" olaylardan kaynaklanır. SQL Server bir iş parçacığının bir zamanlayıcıda verim almadığını algıladığında, verim vermeyen bir zamanlayıcı olayının gerçekleştiğini bildirir. Aynı zamanlayıcıda CPU süresi almayan başka görevler görürseniz, bu verimsiz bir zamanlayıcının birincil işaretidir. Bu davranış, bu görevlerin gecikmeli yürütülmesine ve belirli bir CPU zamanlayıcısına atanan iş yüklerinin "açlıktan ölmesine" neden olabilir.
Verimsiz zamanlayıcı olaylarını denetlemek için şu adımları izleyin:
Sql Server
system_healthgenişletilmiş olay günlüklerini denetleerek Always On sistem durumu denetimi zaman aşımı olayının etrafında bir tür verim vermeyen zamanlayıcı olayının bildirilip bildirmediğini belirleyin. Bulabileceğiniz verimsiz olaylar şunlardır:scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
Birincil çoğaltmadaki SQL Server sistem durumu genişletilmiş olay günlüklerini şüpheli sistem durumu denetimi zaman aşımı süresine kadar açın.
SQL Server Management Studio'da (SSMS), Dosya > Aç'a gidin ve Genişletilmiş Olay Dosyalarını Birleştir'i seçin.
Ekle düğmesini seçin.
Dosya Aç iletişim kutusunda, SQL Server \LOG dizinindeki dosyalara gidin.
Control tuşunu basılı tutun ve adları ile
system_health_xxx.xelbaşlayan dosyaları seçin.Tamam'ı aç'ı> seçin.
Sonuçları filtreleyin. Ad sütununun altında bir olaya sağ tıklayın ve Bu Değere Göre Filtrele'yi seçin.
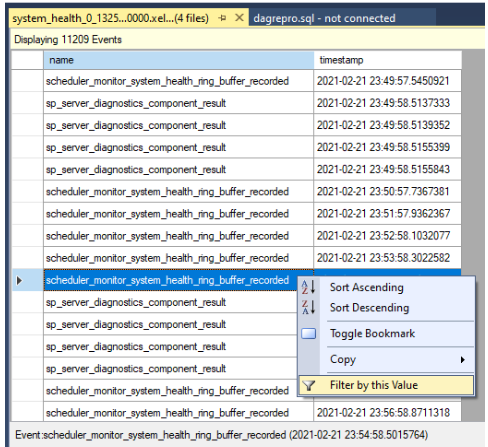
Aşağıdaki ekran görüntüsünde gösterildiği gibi ad sütunundaki değerlerin içerdiği
yieldsatırları sıralamak için bir filtre tanımlayın. Bu, günlüklere kaydedilmişsystem_healtholabilecek her türlü verimsiz olayı döndürür.
Sistem durumu denetimi zaman aşımı sırasında verimsiz olaylar olup olmadığını görmek için zaman damgalarını karşılaştırın. Küme günlüğünde bildirildiği gibi sistem durumu denetimi zaman aşımı aşağıdadır:
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.Sistem durumu denetimi zaman aşımı sırasında oluşan verimsiz olaylar olduğunu görebilirsiniz.
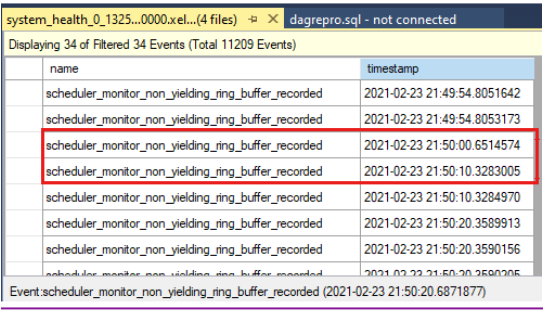
Verimsiz olaylar algılanırsa, verimsiz olayın nedenini denetleyin. Verimsiz olayları araştırmak için SQL Server destek ekibine başvurmayı göz önünde bulundurun.
2. SQL Server hata günlüğünü denetleyin
Sistem durumu denetimi zaman aşımı sırasındaki olayları ilişkilendirmek için SQL Server hata günlüğünü denetleyin. Bu olaylar, sistem durumu denetimi zaman aşımlarının kök nedenini kapsamak için başka adımlar öneren "ekmek kırıntıları" sağlayabilir.
Örneğin, aşağıdaki günlük girdisi küme günlüğünde bir sistem durumu denetimi zaman aşımı oluştuğunu gösterir:
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
SQL Server hata günlüğünde, sistem durumu denetimi zaman aşımından sonra saniyeler içinde SQL Server ciddi G/Ç gecikmesi algıladığını bildirir:
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
Sistem durumu denetimi zaman aşımı olayıyla ilgili olabilecek olası sistem ipuçları için sistem olay günlüğünü gözden geçirin. Windows sistem olay günlüğünü gözden geçirirken, aynı sistem durumu denetimi zaman aşımı için aynı anda bildirilen bir G/Ç sorunuyla karşılaşabilirsiniz:
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
SQL Server sistem durumu: Her Zaman Açık sistem durumu olayı
Always On, farklı türde SQL Server sistem durumu olaylarını izler. Sql Server, bir kullanılabilirlik grubu birincil çoğaltmasını barındırırken, sql server sistem durumunu farklı bileşenler kullanarak raporlayan sp_server_diagnostics sürekli olarak çalıştırır. Herhangi bir sistem durumu sorunu algılandığında, sp_server_diagnostics söz konusu bileşen için bir hata bildirir ve sonuçları Always On sistem durumu algılama işlemine geri gönderir. Bir hata bildirildiğinde, kullanılabilirlik grubu bunu yapacak şekilde yapılandırılmışsa Kullanılabilirlik Grubu rolü başarısız durumu ve olası yük devretmeyi gösterir.
Belirtiler
Aşağıda, küme günlüğünde bildirildiği sp_server_diagnostics gibi bir SQL Server sistem durumu sorunu örneği verilmiştır. SQL Server, sistem bileşenindeki "hata" durumunu Always On sistem durumu izlemesine bildirir ve "contoso-ag" kullanılabilirlik grubu başarısız duruma geçirilir.
Not
SQL Server sistem durumu sorunu, sistem durumu denetimi zaman aşımına benzer bir rapor oluşturur. Her iki sistem durumu olayı da raporu Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel. SQL Server sistem durumu olayının farkı, SQL Server bileşeninin "uyarı" olan "hata" olarak değiştiğini bildirmesidir.
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
SQL Server sistem durumu olaylarını tanılama
SQL Server sistem durumu tarafından bildirilen sistem durumu sorunu türü, kök neden analizinin yönünü belirlemelidir.
Varsayılan olarak, bir kullanılabilirlik grubu dağıttığınızda üç FAILURE_CONDITION_LEVEL olarak ayarlanır. Bu, bazı SQL Server sistem durumu profillerinin izlenmesini etkinleştirir, ancak tüm SQL Server sistem durumu profillerini etkinleştirmez. Varsayılan düzeyde, SQL Server çok fazla döküm dosyası, yazma erişim ihlali veya yalnız bırakılmış bir spinlock ürettiğinde Always On bir sistem durumu olayını tetikler. Kullanılabilirlik grubunun dört veya beş düzeyine kadar ayarlanması, izlenen SQL Server sistem durumu sorunlarının türlerini genişletir. SQL Server sistem durumu Always On izleyicileri hakkında daha fazla bilgi için bkz . Kullanılabilirlik grubu için esnek otomatik yük devretme ilkesi yapılandırma - SQL Server AlwaysOn.
Always On'a özgü sistem durumu sorununu belirlemek için şu adımları izleyin:
Birincil çoğaltmadaki SQL Server kümesi tanılama genişletilmiş olay günlüklerini, şüpheli SQL Server sistem durumu olayının oluştuğu zamana kadar açın.
SSMS'de Dosya>Aç'a gidin ve Genişletilmiş Olay Dosyalarını Birleştir'i seçin.
Ekle'yi seçin.
Dosya Aç iletişim kutusunda, SQL Server \LOG dizinindeki dosyalara gidin.
Control tuşuna basın, adları ile eşleşen
<servername>_<instance>_SQLDIAG_xxx.xeldosyaları seçin ve ardından Tamam'ı Aç'ı> seçin.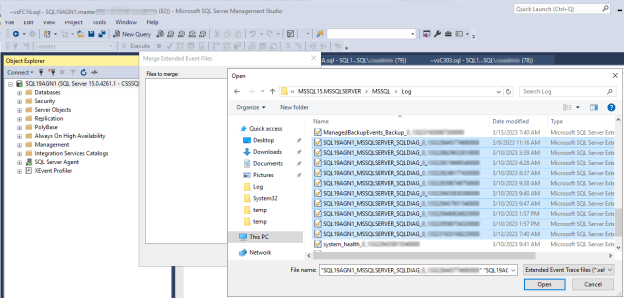
Aşağıdaki ekran görüntüsünde gösterildiği gibi, SSMS'de genişletilmiş olayları içeren yeni bir sekmeli pencere göreceksiniz.
SQL Server sistem durumu sorununu araştırmak için değerini
errorbuluncomponent_health_resultstate_desc. Aşağıda Always On sistem durumu izlemesine hata bildiren bir sistem bileşeni olayı örneği verilmişti: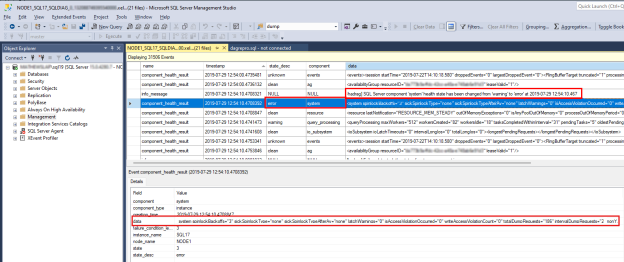
Alt bölmedeki veri sütununa çift tıklayın. Bu işlem, ayrıntılı bileşen verilerini gözden geçirmek üzere yeni bir SSMS pencere bölmesinde açar. Sistem bileşeni verileri şöyle görünür:

'totalDumprequests=186' verilerinin bu SQL Server'da çok fazla döküm dosyası tanılama olayı oluşturulduğunu gösterdiğine dikkat edin. Sistem bileşeninin hata durumu bildirmesinin nedeni budur. Always On sistem durumu izlemesi bu hata durumunu aldığında bir kullanılabilirlik grubu sistem durumu olayını tetikler. Ayrıca, sistem bileşeni verilerinde sağlanan verilerden hiçbir yazma erişim ihlali veya yalnız bırakılmış spinlock algılanmamış olduğunu doğrulayabilirsiniz.



Çözüm
Bulduğunuz sorunun türüne bağlı olarak, sorunu uygun şekilde çözmeniz gerekir. Kullanılabilirlik grubu için esnek otomatik yük devretme ilkesi yapılandırma - SQL Server Always On makalesinde açıklandığı gibi, buna yol açan çeşitli sorunlar olabilir. Örnekler şunları içerir:
- SQL Server hizmeti çalışmıyor.
- Kira zaman aşımı.
- Kullanılabilirlik çoğaltması başarısız durumda.
- Yalnız bırakılmış spinlock'lar, erişim ihlalleri veya kısa bir süre içinde oluşturulan çok fazla bellek dökümü tarafından oluşturulan bellek dökümleri.
- SQL Server iç kaynak havuzundaki kalıcı yetersiz bellek koşulu.
- Scheduler kilitlenmesinin algılanması.
- Çözülemeyen bir kilitlenme algılanması.
Gerekirse, bu iç SQL Server sistem durumu sorunlarının kök nedenini bulma konusunda daha fazla yardım almak üzere bir destek olayı açmak için SQL Server desteğine başvurun