Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
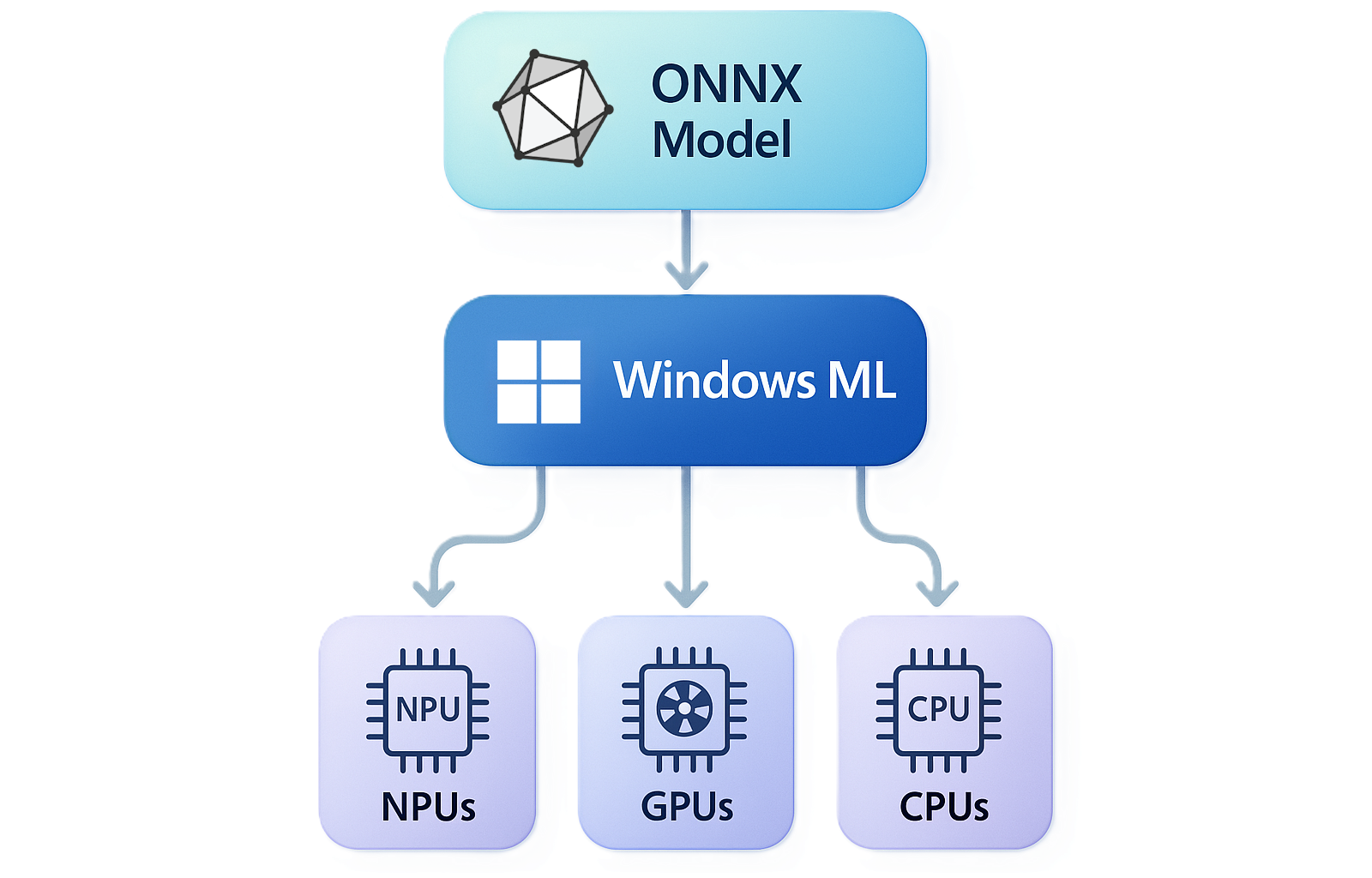
Windows ML, ONNX Çalışma Zamanı tarafından desteklenen Windows için birleşik ve yüksek performanslı yerel yapay zeka çıkarım çerçevesidir. Windows ML ile yapay zeka modellerini yerel olarak çalıştırabilir ve Windows'un yönettiği ve güncel tuttuğu isteğe bağlı yürütme sağlayıcıları aracılığıyla NPU'lar, GPU'lar ve CPU'larda çıkarımı hızlandırabilirsiniz. Windows ML ile PyTorch, TensorFlow/Keras, TFLite, scikit-learn ve diğer çerçevelerden modelleri kullanabilirsiniz.
Ana faydalar
Windows ML, yapay zeka çıkarımının herhangi bir Windows uygulamasına getirilmesini kolaylaştırır:
- Yapay zekayı cihazda çalıştırma — modeller kullanıcının donanımında yerel olarak çalışır, verileri özel tutar, bulut maliyetlerini ortadan kaldırır ve İnternet bağlantısı olmadan çalışır.
- Zaten sahip olduğunuz modelleri kullanın ; PyTorch, TensorFlow, scikit-learn, Hugging Face ve daha birçok model getirin.
- Windows tarafından kolaylaştırılan donanım hızlandırma — Windows ML, Windows'un Windows Update aracılığıyla yükleyip güncel tuttuğu yürütme sağlayıcıları aracılığıyla IHV'ye özgü NPU'lara, GPU'lara ve CPU'lara erişmenizi sağlar; uygulamanızdaki yürütme sağlayıcılarını paketlemenize gerek yoktur.
- Bir çalışma zamanı, birçok uygulama — Windows ML'yi isteğe bağlı olarak paylaşılan bir sistem bileşeni olarak kullanabilirsiniz, böylece uygulamanız küçük kalır ve cihazdaki tüm uygulamalar, her uygulamanın kendi sürümünü paketlemesi yerine aynı güncel çalışma zamanını paylaşır.
- Sınıfının en iyi performansı : Windows ML, RTX için TensorRT veya Qualcomm'un Yapay Zeka Altyapısı Doğrudan gibi ayrılmış SDK'larla eşit olarak NPU'larda ve GPU'larda en iyi performansı sunar. Performans sonuçları donanım yapılandırmasına ve modeline göre farklılık gösterir. Donanıma özgü yönergeler için bkz. Yapay zeka modellerini hızlandırma .
Neden Microsoft ORT yerine Windows ML kullanmalısınız?
Windows ML, sistem genelinde kopya veya bağımsız olarak kullanılabilen, Windows tarafından desteklenen ve bakımı yapılan ONNX Çalışma Zamanı (ORT) kopyasıdır:
- Aynı ONNX API'leri — mevcut ONNX Çalışma Zamanı kodunuzda değişiklik yok
- Windows tarafından desteklenen — Windows ekibi tarafından desteklenen ve bakımı yapılan
- Geniş donanım desteği — Herhangi bir donanım yapılandırmasına sahip Windows bilgisayarlarda (x64 ve ARM64) ve Windows Server'da çalışır
- İsteğe bağlı daha küçük uygulama boyutu : Kendi kopyanızı paketlemek yerine çerçeveye bağımlı dağıtımı seçin ve çalışma zamanını uygulamalar arasında paylaşın
- İsteğe bağlı sürekli güncelleştirmeler — çerçeveye bağımlı dağıtımı seçin ve kullanıcılarınız her zaman Windows Update aracılığıyla en son çalışma zamanını alır
Buna ek olarak, Windows ML uygulamanızın uygulamanızda IP'leri taşımadan ve farklı donanımlar için ayrı derlemeler oluşturmadan yapay zeka modellerinizi hızlandırmak için en son yürütme sağlayıcılarını dinamik olarak edinmesini sağlar.
Kendiniz denemek için bkz. Windows ML'yi kullanmaya başlama !
NPU, GPU ve CPU'da donanım hızlandırma
Windows ML, modern Windows bilgisayarlarında bulunan üç silikon sınıfı arasında çıkarımı hızlandırabilen yürütme sağlayıcılarına erişmenizi sağlar:
- NPU — Copilot+ bilgisayarlarda kullanılabilen en güçlü NPU'larla pil dostu, cihaz üzerinde sürekli çıkarım.
- GPU — Görüntü, video ve üretken yapay zeka gibi yüksek aktarım hızına sahip iş yükleri, genellikle ayrı GPU'larda en yüksek performansı sağlar
- CPU — evrensel geri dönüş ve IHV için iyileştirilmiş CPU hızlandırmaları
Tam silikon-EP eşleme, sürücü gereksinimleri ve EP kaynak oluşturma seçenekleri için bakınız Yapay zeka modellerini hızlandırma.
Sistem gereksinimleri
- OS: Windows Uygulama SDK'sı tarafından desteklenen Windows sürümü
- Mimari: x64 veya ARM64
- Donanım: Herhangi bir bilgisayar yapılandırması (CPU'lar, tümleşik/ayrık GPU'lar, NPU'lar)
Uyarı
CPU ve GPU desteği (DirectML aracılığıyla) desteklenen tüm Windows sürümlerinde kullanılabilir. NPU'lar ve belirli GPU'lar için optimize edilmiş yürütme sağlayıcıları, Windows 11 sürüm 24H2 (derleme 26100) veya daha üzerini gerektirir. Ayrıntılı bilgi için bkz. Windows ML yürütme sağlayıcıları.
Performans iyileştirme
Windows ML'nin en son sürümü GPU'lar ve NPU'lar için ayrılmış yürütme sağlayıcılarıyla doğrudan çalışır ve RTX için TensorRT, AI Engine Direct ve PyTorch için Intel Uzantısı gibi geçmişe ait ayrılmış SDK'larla aynı performans sunar. Windows ML'yi, uygulamanızın IHV'ye özgü SDK'ları dağıtmasına gerek kalmadan sınıfının en iyisi GPU ve NPU performansına sahip olacak şekilde geliştirdik. Performans sonuçları donanım yapılandırmasına ve modeline göre farklılık gösterir. Donanıma özgü yönergeler için bkz. Yapay zeka modellerini hızlandırma .
Modelleri ONNX'e dönüştürme
Modelleri Windows ML ile kullanabilmek için diğer biçimlerden ONNX'e dönüştürebilirsiniz. Daha fazla bilgi edinmek için Visual Studio Code için Foundry Toolkit belgelerinde \modelleri ONNX biçimine dönüştürme\ konusuna bakın. PyTorch, TensorFlow ve Hugging Face modellerini ONNX'e dönüştürme hakkında daha fazla bilgi için ONNX Çalışma Zamanı Kılavuzları'na bakınız.
Model dağıtımı
Windows ML, yapay zeka modellerini dağıtmak için esnek seçenekler sağlar:
- Modelleri uygulamalar arasında paylaşma - Büyük dosyaları paketlemeden herhangi bir CDN'den farklı uygulamalarda modelleri dinamik olarak indirme ve paylaşma
- Yerel modeller - Model dosyalarını doğrudan uygulama paketinize ekleme
Windows yapay zeka ekosistemiyle tümleştirme
Windows ML, daha geniş Windows yapay zeka platformunun temelini oluşturur:
- Windows AI API'leri - Yaygın görevler için yerleşik modeller
- Foundry Local - Kullanıma hazır yapay zeka modelleri
- Özel modeller - Gelişmiş senaryolar için doğrudan Windows ML API erişimi
Geri bildirim sağlama
Bir sorun mu buldunuz yoksa önerileriniz mi var? Windows Uygulama SDK'sı GitHub üzerinde arama yapın veya sorun oluşturun.
Sonraki Adımlar
- Yapay zeka modellerini çalıştırma - Windows ML'yi yükleme ve ilk ONNX modelinizi çalıştırma
- Yapay zeka modellerini hızlandırma - Daha hızlı çıkarım için NPU, GPU veya CPU yürütme sağlayıcıları ekleme
- Modelleri bulma veya eğitma - Windows ML ile uyumlu modelleri bulma
- API başvurusu - Microsoft.WindowsAppSDK.ML paketindeki WinRT ve ONNX Çalışma Zamanı API'leri