Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
VS Code için AI Toolkit (AI Toolkit), yapay zeka modellerini indirmenizi, test etmenizi, ince ayar yapmanızı ve uygulamalarınızla veya bulutta dağıtmanızı sağlayan VS Code bir uzantıdır. Daha fazla bilgi için bkz . AI Toolkit'e genel bakış.
Not
VS Code için AI Toolkit'in ek belgelerine ve öğreticilere, VS Code belgelerinde Visual Studio Code için AI Toolkit bölümünden ulaşabilirsiniz. Playground, yapay zeka modelleriyle çalışma, yerel ve bulut tabanlı modellerde ince ayarlama ve daha fazlası hakkında yönergeler bulacaksınız.
Bu makalede şunları nasıl yapacağınızı öğreneceksiniz:
- VS Code için AI Araç Seti'ni yükleme
- Katalogdan model indirme
- Oyun alanı kullanarak modeli yerel olarak çalıştırma
- REST veya ONNX Çalışma Zamanı'nı kullanarak yapay zeka modelini uygulamanızla tümleştirme
Önkoşullar
- VS Code yüklü olmalıdır. Daha fazla bilgi için bkz. İndirme VS Code ve kullanmaya VS Codebaşlama.
Yapay zeka özelliklerini kullanırken şunları gözden geçirmenizi öneririz: Windows'ta Sorumlu Üretken Yapay Zeka Uygulamaları ve Özellikleri Geliştirme.
Yüklemek
AI Toolkit, Visual Studio Market'te kullanılabilir ve diğer VS Code uzantılar gibi yüklenebilir. VS Code uzantılarını yükleme konusunda bilginiz yoksa şu adımları izleyin:
- Içindeki Etkinlik Çubuğu'nda VS Code seçin
- Uzantılar Arama çubuğuna "AI Toolkit" yazın
- "Visual Studio kodu için AI Araç Seti" öğesini seçin
- Yükle'yi seçin
Uzantı yüklendikten sonra Etkinlik Çubuğunuzda Yapay Zeka Araç Seti simgesini görürsünüz.
Katalogdan model indirme
Yapay Zeka Araç Seti'nin birincil kenar çubuğu Modellerim, Katalog, Araçlar ve Yardım ve Geri Bildirim şeklinde düzenlenmiştir. Oyun Alanı, Toplu Çalıştırma, Değerlendirme ve İnce ayar özellikleri Araçlar bölümünde bulunur. Başlamak için Katalogbölümünden Modeller'i seçerek Model Kataloğu penceresini açın:
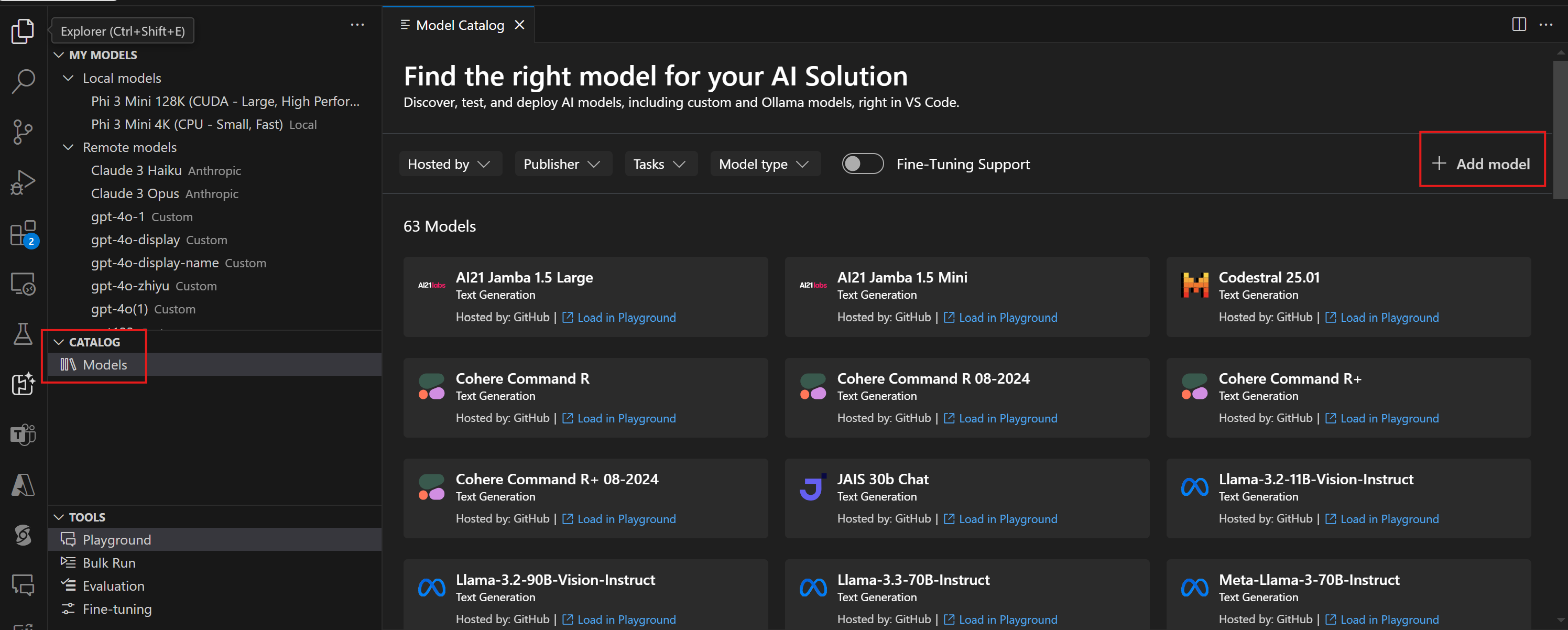
Barındırılan,Yayımcı, Görevler ve Model türüne göre filtrelemek için kataloğun üst kısmındaki filtreleri kullanabilirsiniz. Ayrıca, yalnızca ince ayarlı modelleri göstermek için açabileceğiniz bir Fine-Tuning Destek anahtarı da vardır.
Bahşiş
Model türü filtresi yalnızca CPU, GPU veya NPU üzerinde yerel olarak çalışacak modelleri veya yalnızca Uzaktan erişimi destekleyen modelleri göstermenizi sağlar. En az bir GPU'ya sahip cihazlarda iyileştirilmiş performans için Yerel çalıştırma w/ GPU model türünü seçin. Bu, DirectML hızlandırıcısı için iyileştirilmiş bir model bulmaya yardımcı olur.
Windows cihazınızda GPU olup olmadığını denetlemek için görev yöneticisi
Not
NPU Sinir İşlem Birimi (NPU) olan Copilot+ bilgisayarlar için NPU hızlandırıcısı için iyileştirilmiş modelleri seçebilirsiniz. Deepseek R1 Distilled modeli NPU için optimize edilmiştir ve Windows 11 çalıştıran Snapdragon destekli Copilot+ bilgisayarlarda indirilebilir. Daha fazla bilgi için bkz . Windows AI Foundry tarafından desteklenen Copilot+ bilgisayarlarda Distilled DeepSeek R1 modellerini yerel olarak çalıştırma.
Şu anda bir veya daha fazla GPU'ya sahip Windows cihazlarında aşağıdaki modeller kullanılabilir:
- Mistral 7B (DirectML - Küçük, Hızlı)
- Phi 3 Mini 4K (DirectML - Küçük, Hızlı)
- Phi 3 Mini 128K (DirectML - Küçük, Hızlı)
Phi 3 Mini 4K modelini seçin ve İndir'e tıklayın:
Not
Phi 3 Mini 4K modeli yaklaşık 2 GB-3 GB boyutundadır. Ağ hızınıza bağlı olarak indirme işlemi birkaç dakika sürebilir.
Modeli oyun alanında çalıştırma
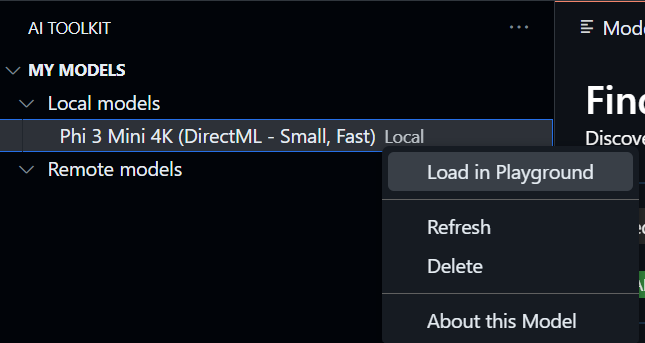
Modeliniz indirildikten sonra, Yerel modeller altındaki Modellerim bölümünde görünür. Modele sağ tıklayın ve bağlam menüsünden Oyun Alanında Yükle'yi seçin:
Oyun alanının sohbet arabirimine aşağıdaki iletiyi ve ardından Enter tuşunu girin :

Model yanıtının size geri akışla aktarılmış olduğunu görmeniz gerekir:
Uyarı
Cihazınızda
Şunları değiştirmek de mümkündür:
- Bağlam Yönergeleri: Modelin isteğinizin büyük resmini anlamasına yardımcı olun. Bu, arka plan bilgileri, istediğiniz şeyin örnekleri/tanıtımları veya görevinizin amacını açıklamak olabilir.
-
Çıkarım parametreleri:
- Maksimum yanıt uzunluğu: Modelin döndüreceği en fazla belirteç sayısı.
- Sıcaklık: Model sıcaklığı, bir dil modelinin çıkışının ne kadar rastgele olduğunu denetleen bir parametredir. Daha yüksek bir sıcaklık, modelin daha fazla risk alması ve size daha çeşitli sözcükler sunması anlamına gelir. Öte yandan düşük bir sıcaklık, modelin daha odaklanmış ve öngörülebilir yanıtlara bağlı kalarak güvenli bir şekilde oynamasını sağlar.
- Üst P: Çekirdek örnekleme olarak da bilinen ayar, dil modelinin bir sonraki sözcüğü tahmin ederken dikkate alınacak olası sözcük veya tümcecik sayısını denetleen bir ayardır
- Sıklık cezası: Bu parametre, modelin çıktısında sözcükleri veya tümcecikleri ne sıklıkta yineleyeceğini etkiler. Değer ne kadar yüksek olursa (1.0'a yakın), modeli yinelenen sözcüklerden veya tümceciklerden kaçınmaya teşvik eder.
- Varlık cezası: Bu parametre, üretilen metinde çeşitliliği ve özgüllüğü teşvik etmek için üretken yapay zeka modellerinde kullanılır. Daha yüksek bir değer (1,0'a yakın), modeli daha yeni ve çeşitli belirteçler eklemeye teşvik eder. Daha düşük bir değer, modelin ortak veya klişe tümceleri oluşturma olasılığını artırır.
Yapay zeka modelini uygulamanıza tümleştirme
Modeli uygulamanızla tümleştirmek için iki seçenek vardır:
- AI Toolkit,
OpenAI sohbet tamamlamaları biçimini kullanan yerel ile birlikte gelir. Bu, bulut yapay zeka modeli hizmetine güvenmek zorunda kalmadan uç noktaAPI web sunucusu http://127.0.0.1:5272/v1/chat/completionskullanarak uygulamanızı yerel olarak test etmenizi sağlar. Üretimde bir bulut uç noktasına geçmek istiyorsanız bu seçeneği kullanın. Web sunucusuna bağlanmak için OpenAI istemci kitaplıklarını kullanabilirsiniz. - ONNX Çalışma Zamanının kullanımı . Modeli, cihazda çıkarım yapacak şekilde uygulamanızla birlikte göndermeyi planlıyorsanız bu seçeneği kullanın.
Yerel REST API web sunucusu
Yerel REST API web sunucusu, bulut yapay zeka modeli hizmetine güvenmek zorunda kalmadan uygulamanızı yerel olarak derlemenize ve test etmenizi sağlar. RESTkullanarak veya openAI istemci kitaplığıyla web sunucusuyla etkileşim kurabilirsiniz:
REST isteğiniz için örnek bir metin aşağıdadır:
{
"model": "Phi-3-mini-4k-directml-int4-awq-block-128-onnx",
"messages": [
{
"role": "user",
"content": "what is the golden ratio?"
}
],
"temperature": 0.7,
"top_p": 1,
"top_k": 10,
"max_tokens": 100,
"stream": true
}'
Not
Model alanını indirdiğiniz modelin adıyla güncelleştirmeniz gerekebilir.
REST veya CURL yardımcı programı gibi bir API aracı kullanarak uç noktasını test edebilirsiniz:
curl -vX POST http://127.0.0.1:5272/v1/chat/completions -H 'Content-Type: application/json' -d @body.json
ONNX Çalışma Zamanı
ONNX Çalışma Zamanı Oluşturma API'si ONNX Çalışma Zamanı ile çıkarım, logits işleme, arama ve örnekleme ve KV önbellek yönetimi dahil olmak üzere ONNX modelleri için üretken yapay zeka döngüsü sağlar. Üst düzey bir generate() yöntemi çağırabilir veya modelin her yinelemesini döngüde çalıştırabilir, bir kerede bir belirteç oluşturabilir ve isteğe bağlı olarak döngü içindeki oluşturma parametrelerini güncelleştirebilirsiniz.
Doyumsuz/kirişli arama ve TopP, belirteç dizileri oluşturmak için TopK örnekleme ve yineleme cezaları gibi yerleşik logit işleme desteğine sahiptir. Aşağıdaki kod, uygulamalarınızda ONNX çalışma zamanından nasıl yararlanabileceğinize ilişkin bir örnektir.
Lütfen Yerel REST API web sunucusunda gösterilen örne bakın. AI Toolkit REST web sunucusu ONNX Çalışma Zamanı kullanılarak oluşturulur.