Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Uyarı
Daha fazla işlevsellik için PyTorch, Windows üzerinde DirectML ile de kullanılabilir.
Bu öğreticinin önceki aşamasında, PyTorch ile görüntü sınıflandırıcımızı eğitmek için kullanacağımız veri kümesini aldık. Şimdi bu verileri kullanmaya koymanın zamanı geldi.
Görüntü sınıflandırıcısını PyTorch ile eğitmek için aşağıdaki adımları tamamlamanız gerekir:
- Verileri yükleyin. Bu öğreticinin önceki adımını yaptıysanız, bunu zaten hallettiniz.
- Bir Convolution Sinir Ağı tanımlayın.
- Bir kayıp işlevi tanımlayın.
- Modeli eğitim verileri üzerinde eğitin.
- Ağı test verilerinde test edin.
Bir Convolution Sinir Ağı tanımlayın.
PyTorch ile bir sinir ağı oluşturmak için torch.nn paketini kullanacaksınız. Bu paket modüller, genişletilebilir sınıflar ve sinir ağları oluşturmak için gerekli tüm bileşenleri içerir.
Burada, CIFAR10 veri kümesindeki görüntüleri sınıflandırmak için temel bir kıvrımlı sinir ağı (CNN) oluşturacaksınız.
CNN, verilerdeki karmaşık özellikleri algılamak için tasarlanmış çok katmanlı sinir ağları olarak tanımlanan bir sinir ağları sınıfıdır. Bunlar en yaygın olarak görüntü işleme uygulamalarında kullanılır.
Ağımız aşağıdaki 14 katmanla yapılandırılacak:
Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> MaxPool -> Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> Linear.
Kıvrım katmanı
Kıvrım katmanı, görüntülerdeki özellikleri algılamamıza yardımcı olan bir CNN ana katmanıdır. Katmanların her birinde görüntülerdeki belirli özellikleri algılamaya yönelik kanal sayısı ve algılanan özelliğin boyutunu tanımlamak için bir dizi çekirdek bulunur. Bu nedenle, 64 kanallı ve çekirdek boyutu 3 x 3 olan bir kıvrım katmanı, her biri 3 x 3 boyutunda 64 ayrı özellik algılar. Bir kıvrım katmanı tanımlarken, kanal sayısını, kanal dışı sayısını ve çekirdek boyutunu sağlarsınız. Katmandaki dış kanal sayısı, bir sonraki katmana giden kanal sayısı olarak görev görür.
Örneğin: In-channels=3, out-channels=10 ve kernel-size=6 içeren bir Convolution katmanı, giriş olarak RGB görüntüsünü (3 kanal) alır ve çekirdek boyutu 6x6 olan görüntülere 10 özellik algılayıcısı uygular. Daha küçük çekirdek boyutları işlem süresini ve ağırlık paylaşımını azaltır.
Diğer katmanlar
Ağımızda aşağıdaki diğer katmanlar yer almaktadır:
-
ReLUkatmanı, tüm gelen özellikleri 0 veya daha büyük olacak şekilde tanımlamak için bir etkinleştirme işlevi kullanır. Bu katmanı uyguladığınızda, 0'dan küçük herhangi bir sayı sıfır olarak değiştirilirken, diğerleri aynı tutulur. - katman,
BatchNorm2dsıfır ortalama ve birim varyansına sahip olmak ve ağ doğruluğunu artırmak için girişlere normalleştirme uygular. - Katman,
MaxPoolbir nesnenin görüntüdeki konumunun sinir ağının belirli özelliklerini algılama becerisini etkilemediğinden emin olmamıza yardımcı olur. - Katman
Linear, ağımızda sınıfların her birinin puanlarını hesaplayan son katmanlardır. CIFAR10 veri kümesinde on etiket sınıfı vardır. En yüksek puana sahip etiket, model tarafından tahmin edilen etiket olacaktır. Doğrusal katmanda, giriş özelliklerinin sayısını ve sınıf sayısına karşılık gelen çıkış özelliklerinin sayısını belirtmeniz gerekir.
Sinir Ağı nasıl çalışır?
CNN bir ileri akış ağıdır. Eğitim süreci sırasında ağ, girdiyi tüm katmanlar boyunca işler, görüntünün tahmin edilen etiketinin doğru etiketten ne kadar saptığını anlamak için kaybı hesaplar ve katmanların ağırlıklarını güncellemek üzere gradyanları ağa geri yayar. Büyük bir giriş veri kümesi üzerinde yineleme yaparak ağ, en iyi sonuçları elde etmek için ağırlıklarını ayarlamayı "öğrenir".
İleriye doğru işlevi kayıp işlevinin değerini hesaplar ve geriye dönük işlev de öğrenilebilir parametrelerin gradyanlarını hesaplar. Sinir ağımızı PyTorch ile oluşturduğunuzda yalnızca forward işlevini tanımlamanız gerekir. Geriye dönük işlev otomatik olarak tanımlanır.
- CCN'yi tanımlamak için aşağıdaki kodu
PyTorchTraining.pyVisual Studio'daki dosyaya kopyalayın.
import torch
import torch.nn as nn
import torchvision
import torch.nn.functional as F
# Define a convolution neural network
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*10*10, 10)
def forward(self, input):
output = F.relu(self.bn1(self.conv1(input)))
output = F.relu(self.bn2(self.conv2(output)))
output = self.pool(output)
output = F.relu(self.bn4(self.conv4(output)))
output = F.relu(self.bn5(self.conv5(output)))
output = output.view(-1, 24*10*10)
output = self.fc1(output)
return output
# Instantiate a neural network model
model = Network()
Uyarı
PyTorch ile sinir ağı hakkında daha fazla bilgi edinmek istiyor musunuz? PyTorch belgelerine göz atın
Bir kayıp fonksiyonu tanımlayın
Kayıp işlevi, çıkışın hedeften ne kadar uzakta olduğunu tahmin eden bir değer hesaplar. Temel amaç, sinir ağlarında geri yayılım yoluyla ağırlık vektörü değerlerini değiştirerek kayıp fonksiyonunun değerini azaltmaktır.
Kayıp değeri model doğruluğundan farklıdır. Loss işlevi, eğitim kümesindeki her iyileştirme yinelemesinin ardından modelin ne kadar iyi davrandığını anlamamızı sağlar. Modelin doğruluğu test verilerinde hesaplanır ve doğru tahminin yüzdesini gösterir.
PyTorch'ta sinir ağı paketi, derin sinir ağlarının yapı taşları oluşturan çeşitli kayıp işlevleri içerir. Bu öğreticide, Çapraz Entropi kaybı ve Adam Optimizatörü ile kayıp işlevini tanımlayarak bir Sınıflandırma kaybı işlevi kullanacaksınız. Öğrenme hızı (lr), kayıp gradyanını dikkate alarak ağımızın ağırlıklarını ne kadar ayarlayacağınızı kontrol eder. Bunu 0,001 olarak ayarlayacaksınız. Ne kadar düşük olursa, eğitim o kadar yavaş olur.
- Kayıp işlevini ve iyileştiriciyi
PyTorchTraining.pytanımlamak için aşağıdaki kodu Visual Studio'daki dosyaya kopyalayın.
from torch.optim import Adam
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Modeli eğitim verileri üzerinde eğitin.
Modeli eğitmek için veri yineleyicimiz üzerinde döngü oluşturmanız, girişleri ağa beslemeniz ve iyileştirmeniz gerekir. PyTorch'un GPU kullanımı için ayrılmış bir kitaplığı yoktur, ancak yürütme cihazını el ile tanımlayabilirsiniz. Makinenizde varsa cihaz bir Nvidia GPU veya yoksa CPU'nuz olacaktır.
- Dosyaya aşağıdaki kodu
PyTorchTraining.pyekleyin
from torch.autograd import Variable
# Function to save the model
def saveModel():
path = "./myFirstModel.pth"
torch.save(model.state_dict(), path)
# Function to test the model with the test dataset and print the accuracy for the test images
def testAccuracy():
model.eval()
accuracy = 0.0
total = 0.0
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
with torch.no_grad():
for data in test_loader:
images, labels = data
# run the model on the test set to predict labels
outputs = model(images.to(device))
# the label with the highest energy will be our prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
accuracy += (predicted == labels.to(device)).sum().item()
# compute the accuracy over all test images
accuracy = (100 * accuracy / total)
return(accuracy)
# Training function. We simply have to loop over our data iterator and feed the inputs to the network and optimize.
def train(num_epochs):
best_accuracy = 0.0
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device")
# Convert model parameters and buffers to CPU or Cuda
model.to(device)
for epoch in range(num_epochs): # loop over the dataset multiple times
running_loss = 0.0
running_acc = 0.0
for i, (images, labels) in enumerate(train_loader, 0):
# get the inputs
images = Variable(images.to(device))
labels = Variable(labels.to(device))
# zero the parameter gradients
optimizer.zero_grad()
# predict classes using images from the training set
outputs = model(images)
# compute the loss based on model output and real labels
loss = loss_fn(outputs, labels)
# backpropagate the loss
loss.backward()
# adjust parameters based on the calculated gradients
optimizer.step()
# Let's print statistics for every 1,000 images
running_loss += loss.item() # extract the loss value
if i % 1000 == 999:
# print every 1000 (twice per epoch)
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
# zero the loss
running_loss = 0.0
# Compute and print the average accuracy fo this epoch when tested over all 10000 test images
accuracy = testAccuracy()
print('For epoch', epoch+1,'the test accuracy over the whole test set is %d %%' % (accuracy))
# we want to save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
Test verilerinde modeli test edin.
Şimdi, test kümemizden alınan toplu görüntülerle modeli test edebilirsiniz.
-
PyTorchTraining.pydosyasına aşağıdaki kodu ekleyin.
import matplotlib.pyplot as plt
import numpy as np
# Function to show the images
def imageshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# Function to test the model with a batch of images and show the labels predictions
def testBatch():
# get batch of images from the test DataLoader
images, labels = next(iter(test_loader))
# show all images as one image grid
imageshow(torchvision.utils.make_grid(images))
# Show the real labels on the screen
print('Real labels: ', ' '.join('%5s' % classes[labels[j]]
for j in range(batch_size)))
# Let's see what if the model identifiers the labels of those example
outputs = model(images)
# We got the probability for every 10 labels. The highest (max) probability should be correct label
_, predicted = torch.max(outputs, 1)
# Let's show the predicted labels on the screen to compare with the real ones
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(batch_size)))
Son olarak ana kodu ekleyelim. Bu işlem model eğitimini başlatır, modeli kaydeder ve sonuçları ekranda görüntüler. Eğitim kümesi üzerinde yalnızca iki yineleme [train(2)] çalıştıracağız, bu nedenle eğitim süreci çok uzun sürmez.
-
PyTorchTraining.pydosyasına aşağıdaki kodu ekleyin.
if __name__ == "__main__":
# Let's build our model
train(5)
print('Finished Training')
# Test which classes performed well
testAccuracy()
# Let's load the model we just created and test the accuracy per label
model = Network()
path = "myFirstModel.pth"
model.load_state_dict(torch.load(path))
# Test with batch of images
testBatch()
Testi yapalım! Üst araç çubuğundaki açılan menülerin Debug olarak ayarlandığından emin olun. Cihazınız 64 bitse projeyi yerel makinenizde çalıştırmak için Çözüm Platformu'nun x64, 32 bit ise x86 olarak değiştirin.
Eğitim veri kümesinden iki tam geçişi ifade eden dönem numarasını iki olarak seçmek ([train(2)]), 10.000 görüntüden oluşan test veri kümesinin tamamı üzerinde iki kez yinelemeye neden olur. 8. Nesil Intel CPU'da eğitimin tamamlanması yaklaşık 20 dakika sürer ve modelin on etiket sınıflandırmasında 65% başarı oranına daha fazla veya daha az ulaşması gerekir.
- Projeyi çalıştırmak için araç çubuğundaki Hata Ayıklamayı Başlat düğmesine tıklayın veya F5 tuşuna basın.
Konsol penceresi açılır ve eğitim sürecini görebilir.
Tanımladığınız gibi, kayıp değeri her 1.000 görüntü topluluğunda veya eğitim setine yapılan her yinelemede beş kez yazdırılacak. Her döngüde kayıp değerinin azalmasını beklersiniz.
Ayrıca her yinelemeden sonra modelin doğruluğunu da göreceksiniz. Model doğruluğu kayıp değerinden farklıdır. Loss işlevi, eğitim kümesindeki her iyileştirme yinelemesinin ardından modelin ne kadar iyi davrandığını anlamamızı sağlar. Modelin doğruluğu test verilerinde hesaplanır ve doğru tahminin yüzdesini gösterir. Bizim örneğimizde, modelimizin her eğitim yinelemesinden sonra doğru şekilde sınıflandırabildiği 10.000 resimlik test kümesinden kaç resim olduğunu bildirir.
Eğitim tamamlandıktan sonra aşağıdakine benzer bir çıktı görmeniz gerekir. Sayılarınız tam olarak aynı olmayacaktır- trianing birçok faktöre bağlıdır ve her zaman identifical sonuçlar döndürmez - ancak benzer görünmelidir.
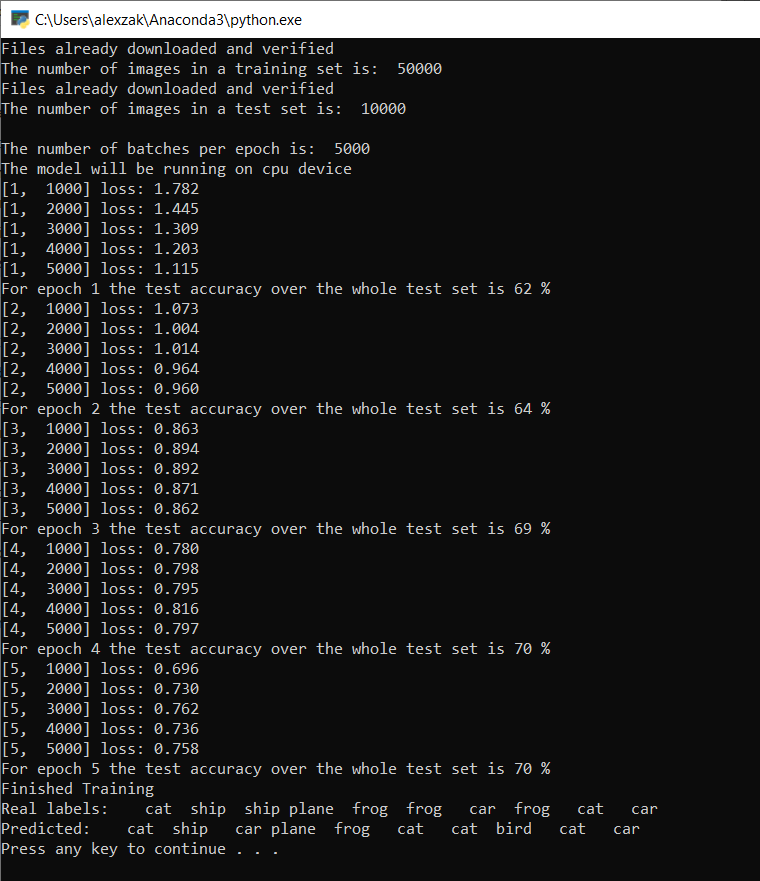
Yalnızca 5 dönem çalıştırıldıktan sonra model başarı oranı 70%olur. Bu, kısa bir süre için eğitilmiş temel bir model için iyi bir sonuç!
Görüntü toplu işlemiyle test eden model, 10'lu toplu işlemden doğru 7 görüntü elde etti. Hiç fena değil ve model başarı oranıyla tutarlı.

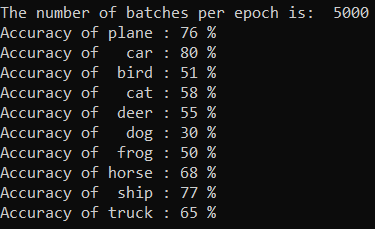
Modelimizin en iyi sınıfları tahmin edebildiğini kontrol edebilirsiniz. Sadece aşağıdaki kodu ekleyip çalıştırın.
-
İsteğe bağlı - aşağıdaki
testClassessişleviPyTorchTraining.pydosyasına ekleyin, bu işlevin çağrısını -testClassess()ana işlevin içine -__name__ == "__main__"ekleyin.
# Function to test what classes performed well
def testClassess():
class_correct = list(0. for i in range(number_of_labels))
class_total = list(0. for i in range(number_of_labels))
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(batch_size):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(number_of_labels):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
Çıktı aşağıdaki şekilde olacaktır:
Sonraki Adımlar
Artık bir sınıflandırma modelimiz olduğuna göre, sonraki adım modeli ONNX biçimine dönüştürmektir