Знаходьте схожих клієнтів за допомогою штучного інтелекту (підготовча версія)
[Ця стаття стосується інструкції до попередньої версії, і її буде змінено.]
Знайдіть схожих клієнтів у своїй базі клієнтів за допомогою штучного інтелекту. Щоб використовувати цю функцію, потрібно створити принаймні один сегмент. Розширення критеріїв існуючої сегмент допомагає знайти клієнтів, схожих на сегмент.
Нотатка
Функція «Знайти схожих клієнтів » використовує автоматизовані засоби для оцінки даних і прогнозування на основі цих даних. Таким чином, його можна використовувати як метод профілювання, оскільки цей термін визначається різними законами та нормативними актами про конфіденційність. Використання цієї функції клієнтами для обробки даних може регулюватися цими законами або правилами. Ви несете відповідальність за те, щоб ваше використання Dynamics 365 Customer Insights - Data, включно з прогнозами, відповідало всім застосовним законам і правилам, включаючи закони, пов’язані з конфіденційністю, персональними даними, біометричними даними, захистом даних і конфіденційністю спілкування.
Пошук подібних клієнтів
Перейдіть у розділ Сегменти>статистики та виберіть сегмент, на основі якого потрібно створити новий сегмент. Це ваше джерело сегмент.
Виберіть Знайти схожих клієнтів.
Перегляньте запропоноване ім'я для нового сегмента і змініть його в разі потреби.
За бажанням додайте теги до нового сегмент.
Перегляньте поля, які визначатимуть ваш новий сегмент. Ці поля визначають основу, ґрунтуючись на якій система спробує знайти клієнтів, подібних до учасників вихідного сегмента. Система за замовчуванням вибирає рекомендовані поля. Якщо потрібно, додайте більше полів. Зазначені нижче поля, які можуть суттєво зменшити продуктивність моделі, буде автоматично виключено.
- Поля з такими типами даних: StringType, BooleanType, CharType, LongType, IntType, DoubleType, FloatType, ShortType
- Поля із кратністю (кількістю елементів у полі), що є меншою 2 або більшою 30
Виберіть, чи потрібно включати всіх клієнтів , крім вихідного сегмент, або лише клієнтів в іншому сегмент у вашому новому сегмент.
За замовчуванням система пропонує обмежити вивід до 20% від розміру цільової аудиторій. За потреби змініть це граничне значення. Збільшення цього граничного значення призведе до зниження точності.
Щоб включити клієнтів у вихідний сегмент, установіть прапорець Включати учасників із вихідного сегмент на додаток до клієнтів зі схожими атрибутами .
Виберіть «Виконати » внизу сторінки, щоб запустити завдання двійкової класифікації (метод машинне навчання), яке аналізує набір даних.
Перегляд подібного сегмента
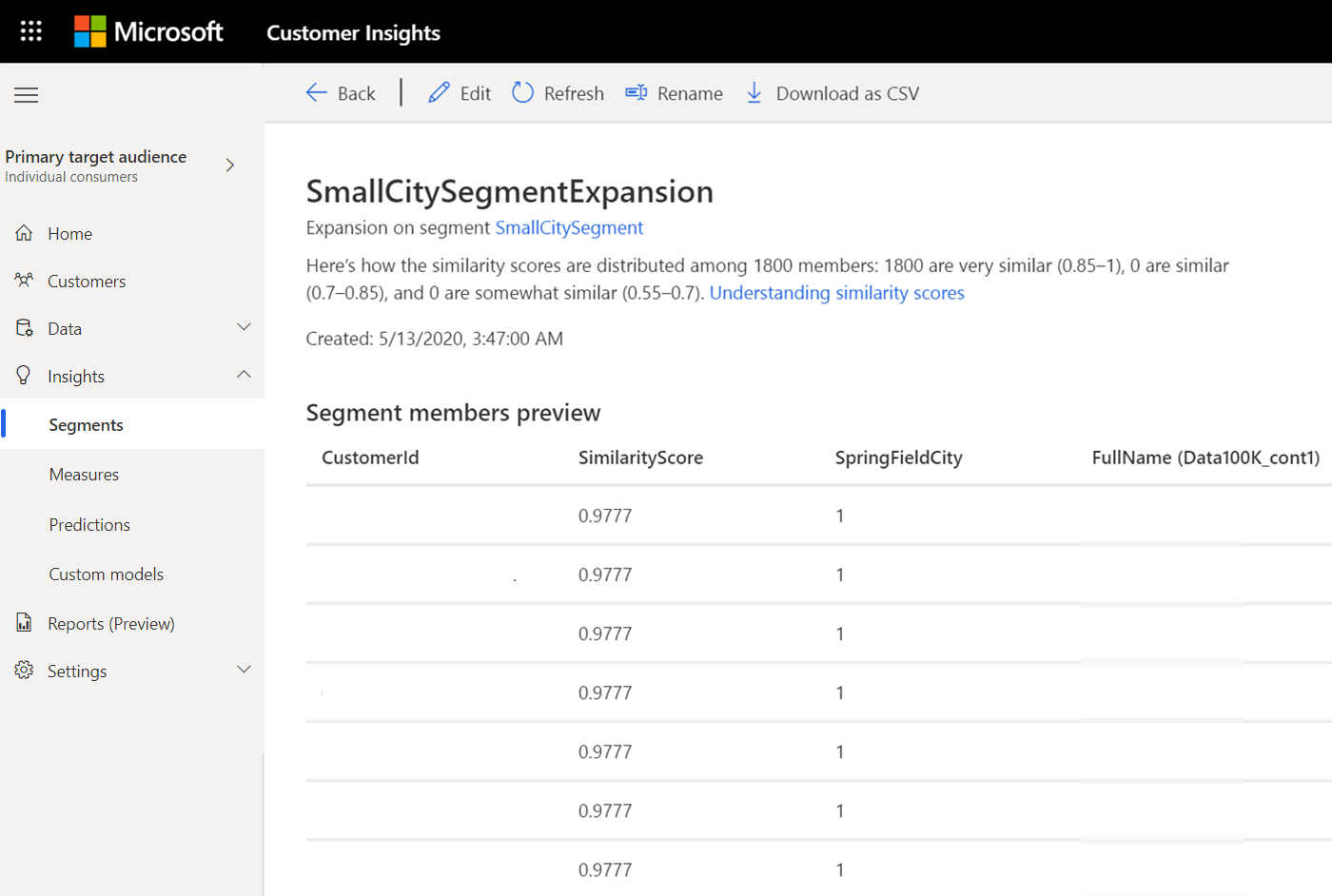
Обробивши схожі сегмент, ви побачите новий сегмент у списку на сторінці "Сегменти>статистики " з типом "Розширення".
Виберіть Перегляд, щоб переглянути розподіл результатів за показниками подібності та значеннями показників подібності в розділах сегмент учасники підготовча версія .
Керуйте аналогічним сегмент
Працюйте з подібними сегмент як і з іншими сегментами, і керуйте ними. Наприклад, експортуйте сегмент або створіть показник.
Редагуйте та оновлюйте, перейменовуйте, завантажуйте та видаляйте подібні сегмент. Редагування подібного сегмент повторно обробляє дані. Раніше створений сегмент буде доповнено новими даними.
Відомості щодо оцінок подібності
Модель машинного навчання із застосуванням двійкової класифікації призначає клієнтам у подібному сегменті оцінки. Оцінка залежить від схожості на клієнтів з вихідного сегмента.
- Показники подібності нижче 0,55 - це клієнти, яких система класифікує як таких, що не схожі на клієнтів у вихідному сегмент
- Показники подібності від 0,55 до 0,7 класифікуються як дещо схожі
- Показники подібності від 0,7 до 0,85 класифікуються як схожі
- Показники подібності від 0,85 до 1 – це клієнти, яких система класифікує як дуже схожих
Клієнти із оцінками подібності, що є нижчими за 0,4, не потрапляють до результатів роботи моделі. Система вважає їх недостатньо схожими на вихідний сегмент.