Caching in Fabric data warehousing
Applies to: ✅ SQL analytics endpoint and Warehouse in Microsoft Fabric
Retrieving data from the data lake is crucial input/output (IO) operation with substantial implications for query performance. Fabric Data Warehouse employs refined access patterns to enhance data reads from storage and elevate query execution speed. Additionally, it intelligently minimizes the need for remote storage reads by leveraging local caches.
Caching is a technique that improves the performance of data processing applications by reducing the IO operations. Caching stores frequently accessed data and metadata in a faster storage layer, such as local memory or local SSD disk, so that subsequent requests can be served more quickly, directly from the cache. If a particular set of data has been previously accessed by a query, any subsequent queries will retrieve that data directly from the in-memory cache. This approach significantly diminishes IO latency, as local memory operations are notably faster compared to fetching data from remote storage.
Caching is fully transparent to the user. Irrespective of the origin, whether it be a warehouse table, a OneLake shortcut, or even OneLake shortcut that references to non-Azure services, the query caches all the data it accesses.
There are two types of caches that are described later in this article:
- In-memory cache
- Disk cache
In-memory cache
As the query accesses and retrieves data from storage, it performs a transformation process that transcodes the data from its original file-based format into highly optimized structures in in-memory cache.

Data in cache is organized in a compressed columnar format optimized for analytical queries. Each column of data is stored together, separate from the others, allowing for better compression since similar data values are stored together, leading to reduced memory footprint. When queries need to perform operations on a specific column like aggregates or filtering, the engine can work more efficiently since it doesn't have to process unnecessary data from other columns.
Additionally, this columnar storage is also conducive to parallel processing, which can significantly speed up query execution for large datasets. The engine can perform operations on multiple columns simultaneously, taking advantage of modern multi-core processors.
This approach is especially beneficial for analytical workloads where queries involve scanning large amounts of data to perform aggregations, filtering, and other data manipulations.
Disk cache
Certain datasets are too large to be accommodated within an in-memory cache. To sustain rapid query performance for these datasets, Warehouse utilizes disk space as a complementary extension to the in-memory cache. Any information that is loaded into the in-memory cache is also serialized to the SSD cache.
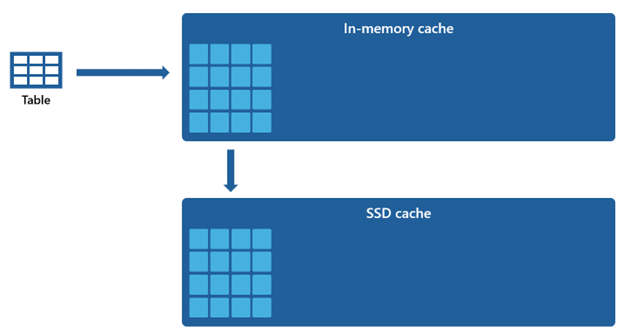
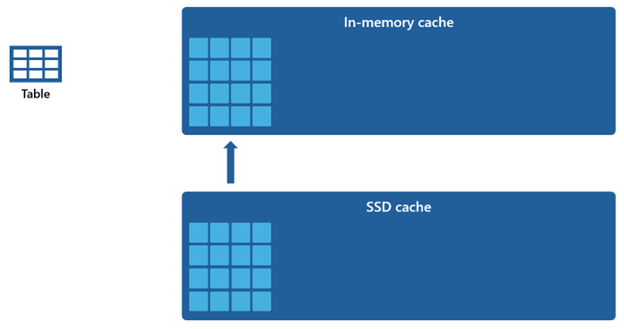
Given that the in-memory cache has a smaller capacity compared to the SSD cache, data that is removed from the in-memory cache remains within the SSD cache for an extended period. When subsequent query requests this data, it is retrieved from the SSD cache into the in-memory cache at a significantly quicker rate than if fetched from remote storage, ultimately providing you with more consistent query performance.
Cache management
Caching remains consistently active and operates seamlessly in the background, requiring no intervention on your part. Disabling caching is not needed, as doing so would inevitably lead to a noticeable deterioration in query performance.
The caching mechanism is orchestrated and upheld by the Microsoft Fabric itself, and it doesn't offer users the capability to manually clear the cache.
Full cache transactional consistency ensures that any modifications to the data in storage, such as through Data Manipulation Language (DML) operations, after it has been initially loaded into the in-memory cache, will result in consistent data.
When the cache reaches its capacity threshold and fresh data is being read for the first time, objects that have remained unused for the longest duration will be removed from the cache. This process is enacted to create space for the influx of new data and maintain an optimal cache utilization strategy.