Про етапи виконання програми на полотні, потік викликів і моніторинг продуктивності
Коли користувач відкриває компоновану програму, перш ніж відобразиться будь-який інтерфейс користувача, програма проходить кілька етапів виконання. Під час завантаження програма підключається до різних джерел даних, наприклад,, SharePoint, Microsoft Dataverse, SQL Server (локально), бази даних Azure SQL (онлайн), Excel і Oracle.
У цій статті ви дізнаєтеся про ці різні етапи виконання, про те, як програма підключається до джерел даних, а також про інструменти, які можна використовувати для моніторингу продуктивності.
Етапи виконання у компонованих програмах
Перед відображенням інтерфейсу користувачу компонована програма проходить наведені далі фази виконання.
Автентифікація користувача: пропонує користувачу, який вперше використовує програму, виконати вхід за допомогою облікових даних для будь-яких підключень, потрібних програмі. Якщо цей користувач знову відкриє програму, йому знову може відобразитися підказка, й це буде залежати від політики безпеки організації.
Отримати метадані: витягає метадані, такі як версія платформи Power Apps, на якій запущено програму, та джерела, з яких вона має отримувати дані.
Ініціалізація програми: виконує будь-які завдання, зазначені у властивості OnStart.
Візуалізація екранів: візуалізація першого екрана з елементами керування, які програма заповнює даними. Якщо користувач відкриє інші екрани, програма відобразить їх тим самим процесом.
Потік виклику даних у компонованих програмах
Виклики даних із програм canvas надсилають дані до табличних джерел даних за допомогою з’єднувачів через протокол OData. Запити OData надходять на внутрішні рівні, щоб зв’язатися з цільовим джерело даних і отримати дані для клієнта або зафіксувати дані в джерело даних. Конектори, засновані на діях, які забезпечують API, працюють так само.
Розуміння того, як надсилаються запити OData та API в програмах на полотні, може допомогти вам оптимізувати продуктивність програми на полотні та внутрішні джерела даних.
У цьому розділі ви дізнаєтеся про те, як виклики даних рухаються у компонованих програмах при використанні різних типів джерел даних.
Потік виклику даних для онлайн-джерел даних
На схемі нижче показано рух типового запиту даних у компонованій програмі (з лівої сторони) між шарами на стороні сервера та його надходження до цільового джерела даних (із правої сторони), а потім повернення даних клієнту.

Кожен шар на попередній схемі може виконуватися швидко або стикатися з перевантаженням під час обробки запиту. У багатьох програмах помітні затримки, як правило, представляють собою значне перевантаження:
Серверне джерело даних – поки обробляється запит.
Клієнт – під час надсилання запиту, або при виконанні операцій із отриманими даними в динамічній пам'яті й роботі пов'язаних функцій JavaScript, що обробляють дані перед відображенням на екранах.
Потік виклику даних із локальним шлюзом даних
Якщо компонована програма підключається до локального джерела даних, наприклад до Сервера SQL, вам знадобиться додатковий шар, який називається локальним шлюзом даних. Цей шлюз обов'язковий для доступу до локальних джерел даних. Він відповідає за роботу трансляції протоколу із запитів OData у декларації на мові маніпулювання даними (DML) SQL.
На схемі нижче показано, де і як буде доцільно розташувати локальний шлюз даних для обробки запитів даних.

Якщо програма використовує джерело даних локально, розташування та технічні характеристики шлюзу даних також впливатимуть на швидкість викликів даних.
Потік викликів даних за допомогою Microsoft Dataverse
Коли ви використовуєте Microsoft Dataverse як джерело даних, запити даних спрямовуються безпосередньо до інсталяції середовища, без проходження через Azure API Management. Через це продуктивність викликів даних є вищою порівняно з іншими джерелами даних. Програма за замовчуванням підключається до Microsoft Dataverse під час створення нової компонованої програми.

Розуміючі ці загальні принципи руху викликів даних, ви можете переходити до детального оцінювання швидкодії своєї програми. У підсумку зниження продуктивності може відбуватися на будь-якому з шарів – на шарі клієнта, керування API, з’єднувача, локального шлюзу даних або серверних джерел даних.
Вимірювання продуктивності
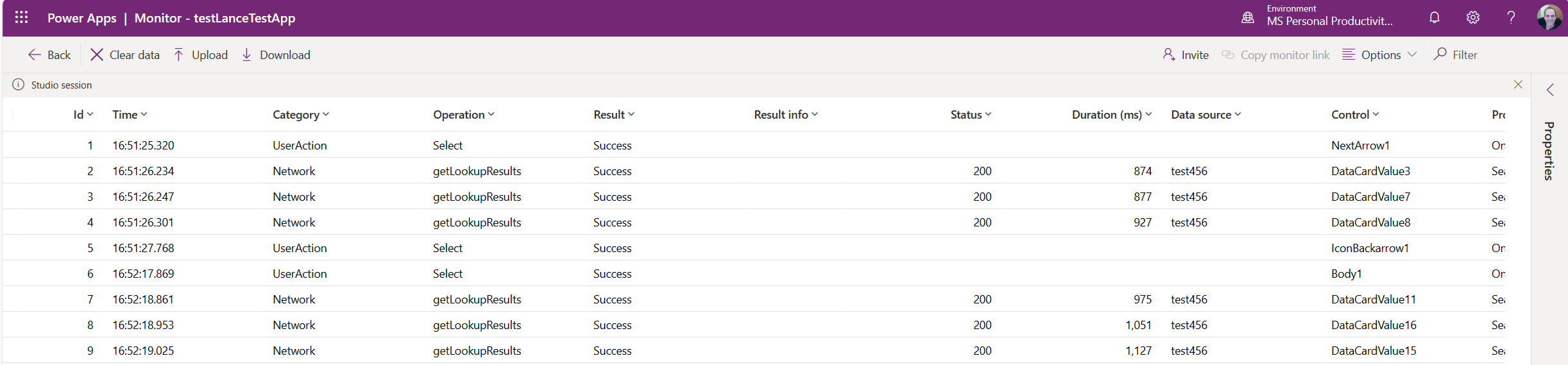
Power Apps Інструмент моніторингу
Хоча ви можете використовувати інструменти розробника браузера, щоб побачити продуктивність, набір викликів в інструменті моніторингу підставляється лише до тих, Power Apps які є Power Apps.
Інструмент Power Apps моніторингу може допомогти вам відстежити, що насправді надсилається на джерело даних, а також позначки часу, коли надсилаються запити та надходять відповіді з сервера.
Ви можете дізнатися більше про інструмент моніторингу в цій статті: Налагодження програм на полотні за допомогою Monitor .
Вимірювання тиску пам’яті на клієнта
Щоб переглянути споживання пам’яті в графічному вигляді, ви можете скористатися інструментами розробника вашого браузера для профілювання пам’яті. Це допомагає візуально відобразити розмір динамічної пам’яті, документів, вузлів і слухачів. Профілюйте продуктивність програми за допомогою браузера, як описано в Microsoft Edge огляді інструментів розробника (Chromium). Перевірте сценарії, які перевищують граничне значення обсягу динамічної пам’яті JS. Докладніше див. у розділі Виправляйте проблеми пам’яті

Наступні кроки
Див. також
Виправлення неполадок для Power Apps
Примітка
Розкажіть нам про свої уподобання щодо мови документації? Візьміть участь в короткому опитуванні. (зверніть увагу, що це опитування англійською мовою)
Проходження опитування займе близько семи хвилин. Персональні дані не збиратимуться (декларація про конфіденційність).