Примітка
Доступ до цієї сторінки потребує авторизації. Можна спробувати ввійти або змінити каталоги.
Доступ до цієї сторінки потребує авторизації. Можна спробувати змінити каталоги.
Оптичне розпізнавання символів (OCR) дає змогу знаходити та витягувати текст із зображень або екрана.
Хоча більшість сценаріїв вимагають обробки тексту певною мовою, бувають випадки, коли джерела є багатомовними.
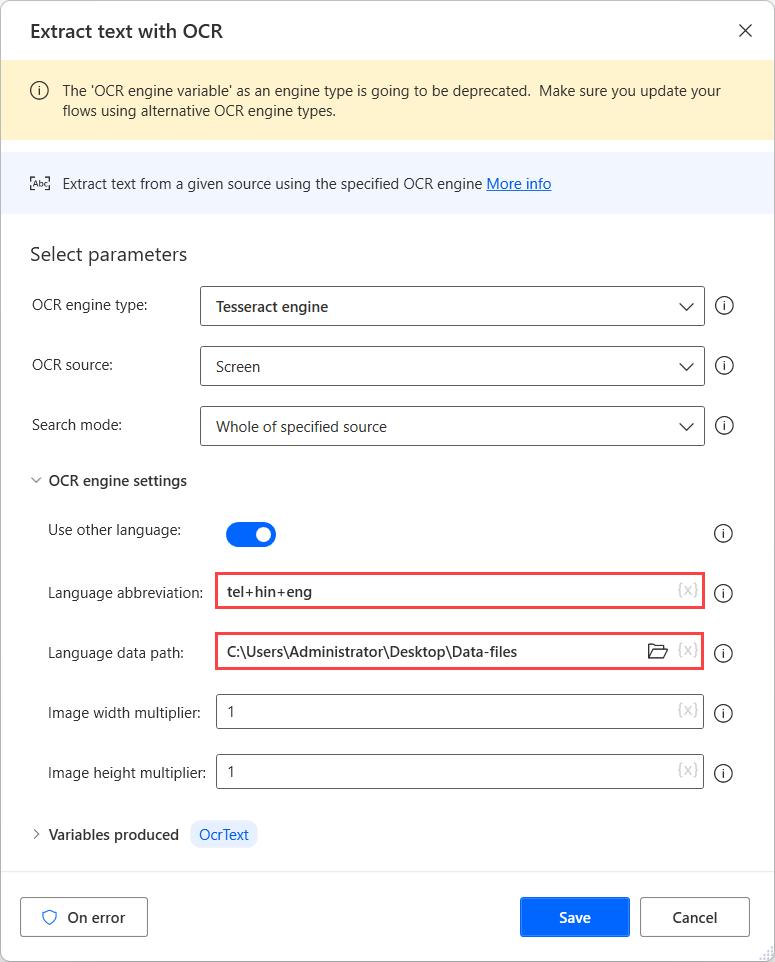
Щоб виконати OCR на цих джерелах, використовуйте рушій Tesseract у відповідній дії OCR і ввімкніть опцію Використовувати інші мови в налаштуваннях рушія.
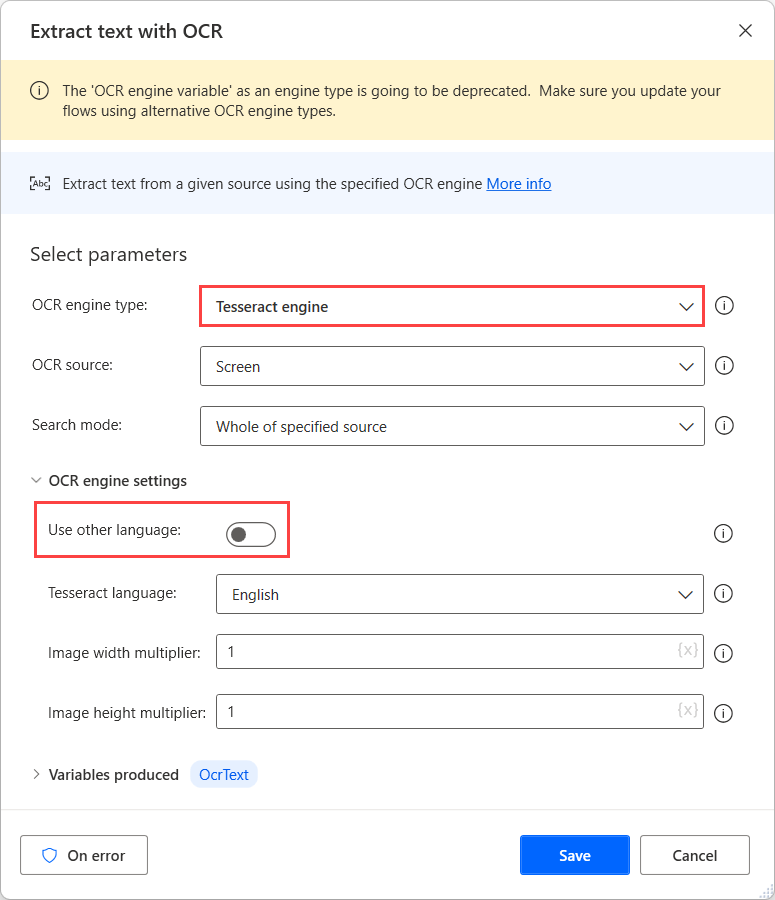
Якщо ввімкнено параметр «Використовувати інші мови», у дії відображаються два додаткові параметри: поля «Абревіатура мови » та «Шлях до мовних даних ».
Поле «Абревіатура мови» вказує рушію, яку мову слід шукати під час оптичного розпізнавання символів. Поле «Шлях до даних мови» містить файли мовних даних (.traineddata), які використовуються для навчання механізму оптичного розпізнавання символів.
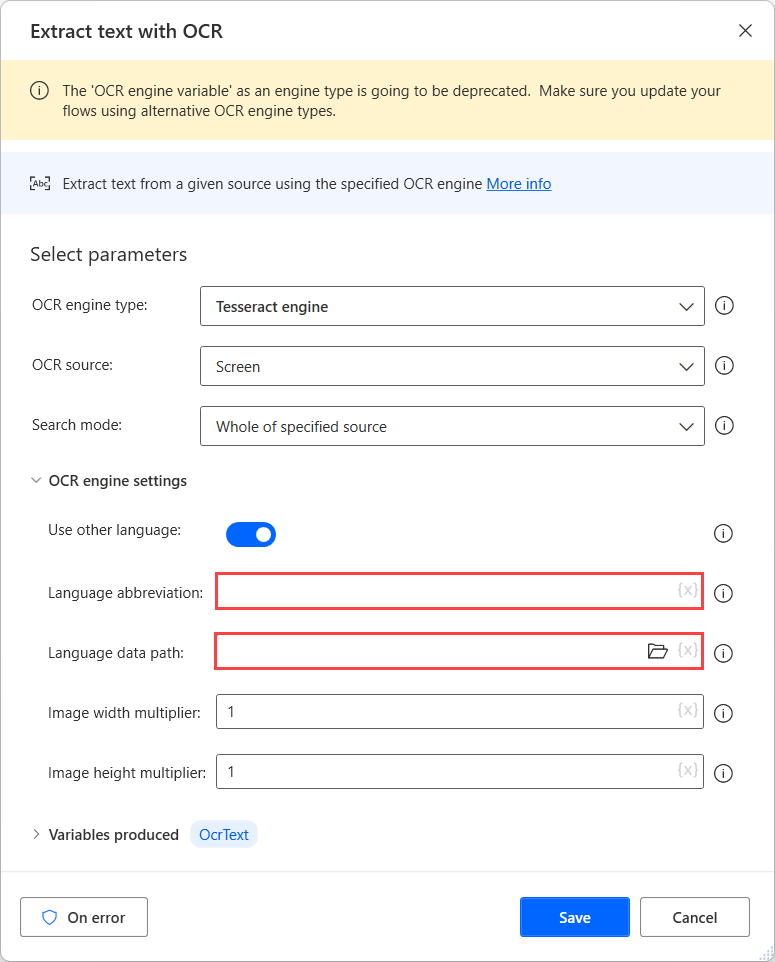
Завантаживши файли даних для потрібних мов, перемістіть їх у загальну папку, щоб зробити їх доступними за тим самим шляхом.
Далі вибираємо створену папку в полі Шлях до даних мови, а в поле Абревіатура мови заповнюємо відповідні коди мов. Щоб розділити коди мов, використовуйте символ плюс (+).
Нотатка
Ви можете знайти всі доступні коди мов у вихідних файлах мовних даних. У наведеному нижче прикладі використані коди представляють телугу, гінді та англійську мову.