Пояснення процесу фабрики даних
Робочі цикли на основі даних
Конвеєри (робочі процеси, засновані на даних) у Azure Data Factory зазвичай виконують наступні чотири кроки:
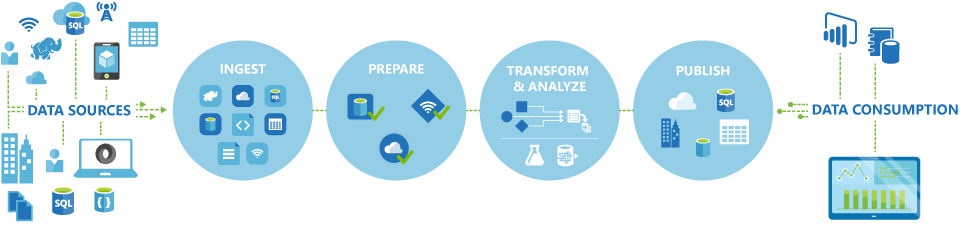
Підключення та збирання
Перший крок у створенні системи orchestration – визначити та з'єднати всі необхідні джерела даних, наприклад бази даних, спільний доступ до файлів і веб-служби FTP. Наступний крок полягає в тому, щоб за потреби додати дані до централізованого розташування для подальшої обробки.
Перетворення та збагачення
Обчислювальні сервіси, такі як Databricks і Machine Learning, можуть використовуватися для підготовки або створення трансформованих даних за підтримуваним і контрольованим графіком, щоб подавати виробничі середовища очищеними та трансформованими даними. У деяких випадках ви навіть можете доповнити вихідні дані додатковими даними для полегшення аналізу або консолідувати їх через процес нормалізації для використання в експерименті з Machine Learning як приклад.
Опублікувати
Після того, як сирі дані будуть оброблені до готового до бізнесу форму з фази трансформації та збагачення, ви можете завантажити їх у Microsoft Fabric, Azure SQL Database, Azure Cosmos DB або будь-який аналітичний рушій, на який можуть вказати ваші бізнес-користувачі зі своїх інструментів бізнес-аналітики
Монітор
Azure Data Factory має вбудовану підтримку моніторингу конвеєрів через Azure Monitor, API, PowerShell, журнали Azure Monitor та панелі здоров'я на порталі Azure для моніторингу запланованих дій і конвеєрів на рівні успіху та відмов.