Загальні відомості про нормалізацію
Нормалізація – це термін, який використовується фахівцями бази даних для процесу розробки схеми, що зменшує дублювання даних і забезпечує цілісність даних.
Хоча існує багато складних правил, які визначають процес рефактоторування даних на різні рівні (або форми) нормалізації, просте визначення для практичних цілей:
- Розділяйте кожну сутність на власну таблицю.
- Розділяйте кожен окремий атрибут на власний стовпець.
- Унікальний ідентифікатор кожного екземпляра сутності (рядка) за допомогою первинного ключа.
- Зв'язування пов'язаних сутностей за допомогою стовпців зовнішнього ключа .
Щоб зрозуміти основні принципи нормалізації, припустімо, що наведена нижче таблиця представляє електронну таблицю, яку компанія використовує для відстеження збуту.
| Номер замовлення | Ім'я клієнта | CustomerAddress | Назва товару | Ціна за одиницю | Кість |
|---|---|---|---|---|---|
| 1 | Джейн Сміт | 42 Oak St. Сіетл | Віджет А | 9.99 | 2 |
| 1 | Джейн Сміт | 42 Oak St. Сіетл | Віджет Б | 4.49 | 1 |
| 2 | Боб Джонс | 18 Пайн Авеню, Портленд | Віджет А | 9.99 | 5 |
| 2 | Боб Джонс | 18 Пайн Авеню, Портленд | Гаджет Ікс | 24.99 | 1 |
| 3 | Джейн Сміт | 42 Oak St. Сіетл | Гаджет Ікс | 24.99 | 3 |
| 3 | Джейн Сміт | 42 Oak St. Сіетл | Віджет Б | 4.49 | 2 |
Зверніть увагу, що відомості про клієнта та продукт дублюються для кожного проданого окремого товару; і що ім'я та поштова адреса клієнта, а також назва товару та ціна об'єднуються в ті самі клітинки електронної таблиці.
Тепер давайте розглянемо, як нормалізація змінює спосіб зберігання даних.
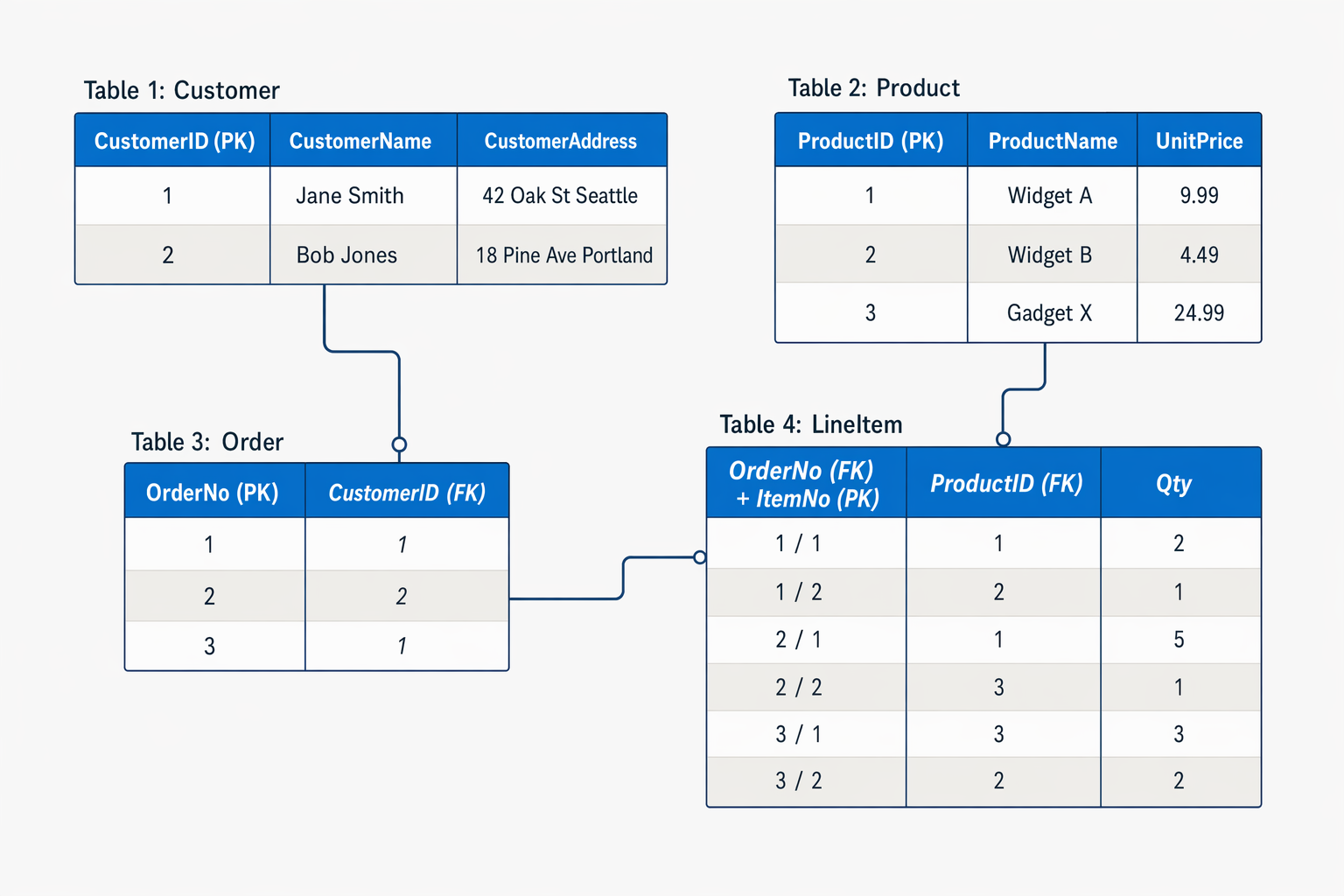
Кожна сутність, представлена в даних (клієнт, продукт, замовлення на збут і елемент рядка), зберігається у власній таблиці, а кожен дискретний атрибут цих сутностей – у своєму стовпці.
Записування кожного екземпляра сутності як рядка в таблиці, пов'язаних із сутністю, видаляє дублювання даних. Наприклад, щоб змінити адресу клієнта, потрібно змінити значення лише в одному рядку.
Розклад атрибутів на окремі стовпці гарантує, що кожне значення обмежене відповідним типом даних — наприклад, ціни на товар muSt.be десяткові значення, а кількість рядкових елементів muSt.be цілими числами. Крім того, створення окремих стовпців забезпечує корисний рівень деталізованих даних для запитів , наприклад, ви можете легко фільтрувати клієнтів до тих, хто живе в певному місті.
Екземпляри кожної сутності однозначно ідентифікуються за ідентифікатором або іншим значенням ключа, відомим як первинний ключ; і коли одна сутність посилається на іншу (наприклад, замовлення має пов'язаного клієнта), первинний ключ пов'язаної сутності зберігається як зовнішній ключ. Ви можете знайти адресу клієнта (який зберігається лише один раз) для кожного запису в таблиці "Замовлення ", посилаючись на відповідний запис у таблиці "Клієнт ". Зазвичай реляційна система управління базами даних (RDBMS) може забезпечувати референтну цілісність, щоб переконатися, що значення, введене у поле зовнішнього ключа, має відповідний первинний ключ у відповідній таблиці — наприклад, запобігаючи замовленням для неіснуючих клієнтів.
У деяких випадках ключ (первинний або зовнішній) можна визначити як складений ключ на основі унікального поєднання кількох стовпців. Наприклад, таблиця LineItem у наведеному вище прикладі використовує унікальне поєднання OrderNo та ItemNo для визначення елемента рядка з окремого замовлення.