Моделі семантичної мови
Порада
Перегляньте вкладку Текст і зображення для отримання більш детальної інформації!
Оскільки стан мистецтва для НЛП просунувся, здатність навчати моделі, які інкапсулюють семантичний зв'язок між маркерами, призвела до появи потужних глибоких мовних моделей навчання. В основі цих моделей лежить кодування мовних маркерів як векторів (багатозначних масивів чисел), відомих як вбудовування.
Цей векторний підхід до моделювання тексту став поширеним у таких техніках, як Word2Vec і GloVe, де текстові токени представлені як щільні вектори з кількома вимірами. Під час навчання моделі значення розмірності призначаються відповідно до семантичних характеристик кожного токена на основі їх використання в навчальному тексті. Математичні взаємозв'язки між векторами можна використати для більш ефективного виконання типових текстових завдань, ніж старі чисто статистичні методи. Більш сучасним досягненням цього підходу є використання техніки « увага » для розгляду кожного токена в контексті та розрахунку впливу токен навколо нього. Отримані контекстуалізовані вкладення, такі як ті, що містяться в сімействі моделей GPT, становлять основу сучасного генеративного ШІ.
Представлення тексту як векторів
Вектори представляють точки в багатовимірному просторі, визначені координатами вздовж кількох осей. Кожен вектор описує напрямок і відстань від початку координат. Семантично схожі токени мають давати вектори з подібною орієнтацією — іншими словами, вони вказують у схожі напрямки.
Наприклад, розглянемо такі тривимірні вкладення для деяких поширених слів:
| Word | Вектор |
|---|---|
dog |
[0.8, 0.6, 0.1] |
puppy |
[0.9, 0.7, 0.4] |
cat |
[0.7, 0.5, 0.2] |
kitten |
[0.8, 0.6, 0.5] |
young |
[0.1, 0.1, 0.3] |
ball |
[0.3, 0.9, 0.1] |
tree |
[0.2, 0.1, 0.9] |
Ми можемо візуалізувати ці вектори у тривимірному просторі, як показано тут:

Вектори для "dog" і "cat" схожі (обидва домашні тварини), як і "puppy""kitten" (обидві молоді тварини). Слова "tree", "young", і ball" мають чітко різні векторні орієнтації, що відображає їхні різні семантичні значення.
Семантична характеристика, закодована у векторах, дозволяє використовувати векторні операції для порівняння слів і аналітичних порівнянь.
Пошук пов'язаних термінів
Оскільки орієнтація векторів визначається їхніми розмірними значеннями, слова з подібним семантичним значенням, як правило, мають схожі орієнтації. Це означає, що ви можете використовувати розрахунки, такі як косинусна схожість між векторами, для змістовних порівнянь.
Наприклад, щоб визначити «непарний» між "dog", "cat", і "tree", можна обчислити косинусну схожість між парами векторів. Косинусна схожість обчислюється так:
cosine_similarity(A, B) = (A · B) / (||A|| * ||B||)
Де A · B — крапковий добуток, а ||A|| — величина вектора A.
Обчислення подібностей між трьома словами:
dog[0,8, 0,6, 0,1] таcat[0,7, 0,5, 0,2]:- Крапковий добуток: (0,8 × 0,7) + (0,6 × 0,5) + (0,1 × 0,2) = 0,56 + 0,30 + 0,02 = 0,88
- Зоряна величина
dog: √(0,8² + 0,6² + 0,1²) = √(0,64 + 0,36 + 0,01) = √1,01 ≈ 1,005 - Зоряна величина
cat: √(0,7² + 0,5² + 0,2²) = √(0,49 + 0,25 + 0,04) = √0,78 ≈ 0,883 - Косинусна схожість: 0,88 / (1,005 × 0,883) ≈ 0,992 (висока схожість)
dog[0,8, 0,6, 0,1] таtree[0,2, 0,1, 0,9]:- Крапковий добуток: (0,8 × 0,2) + (0,6 × 0,1) + (0,1 × 0,9) = 0,16 + 0,06 + 0,09 = 0,31
- Величина:
tree√(0,2² + 0,1² + 0,9²) = √(0,04 + 0,01 + 0,81) = √0,86 ≈ 0,927 - Косинусна схожість: 0,31 / (1,005 × 0,927) ≈ 0,333 (низька схожість)
cat[0,7, 0,5, 0,2] таtree[0,2, 0,1, 0,9]:- Крапковий добуток: (0,7 × 0,2) + (0,5 × 0,1) + (0,2 × 0,9) = 0,14 + 0,05 + 0,18 = 0,37
- Косинусна схожість: 0,37 / (0,883 × 0,927) ≈ 0,452 (низька схожість)
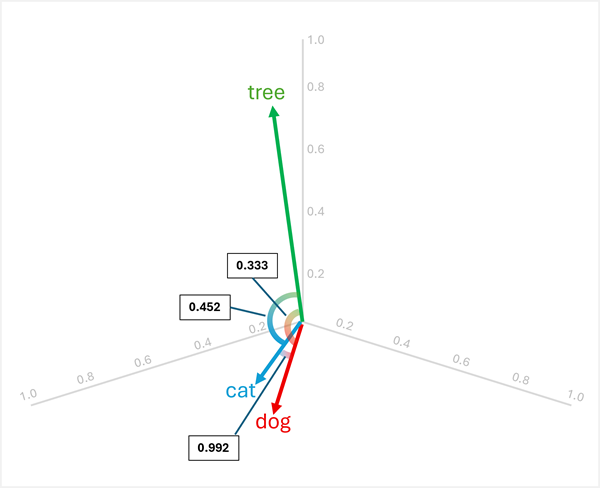
Результати показують, що "dog" та "cat" є дуже схожими (0,992), тоді "tree" як мають меншу схожість з обома "dog" (0,333) та "cat" (0,452). Отже, tree це явно виняток.
Векторне переміщення шляхом додавання та віднімання
Ви можете додавати або віднімати вектори, щоб отримати нові результати на основі векторів; які потім можна використовувати для пошуку токен із відповідними векторами. Ця техніка дозволяє інтуїтивно арифметичній логіці визначати відповідні терміни на основі лінгвістичних відносин.
Наприклад, використовуючи вектори з попередніх часів:
-
dog+young= [0.8, 0.6, 0.1] + [0.1, 0.1, 0.3] = [0.9, 0.7, 0.4] =puppy -
cat+young= [0.7, 0.5, 0.2] + [0.1, 0.1, 0.3] = [0.8, 0.6, 0.5] =kitten
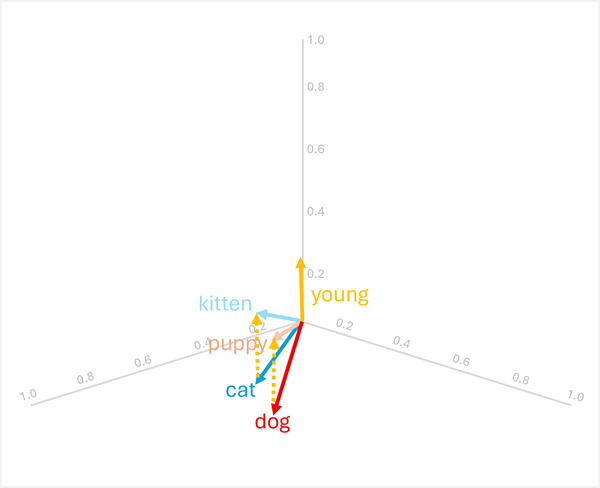
Ці операції працюють, оскільки вектор для "young" кодує семантичну трансформацію від дорослої тварини до її молодого аналога.
Нотатка
На практиці векторна арифметика рідко дає точні збіги; Замість цього ви шукаєте слово, вектор якого найближчий (найсхожий) до результату.
Арифметика працює і у зворотному напрямку:
-
puppy-young= [0,9, 0,7, 0,4] - [0,1, 0,1, 0,3] = [0,8, 0,6, 0,1] =dog -
kitten-young= [0.8, 0.6, 0.5] - [0.1, 0.1, 0.3] = [0.7, 0.5, 0.2] =cat
Аналогічне мислення
Векторна арифметика також може відповісти на аналогічні питання, наприклад, «puppyis to dog as kitten is to?»
Щоб розв'язати це, розрахуйте: kitten - puppy + dog
- [0.8, 0.6, 0.5] - [0.9, 0.7, 0.4] + [0.8, 0.6, 0.1]
- = [-0,1, -0,1, 0,1] + [0,8, 0,6, 0,1]
- = [0,7, 0,5, 0,2]
- =
cat
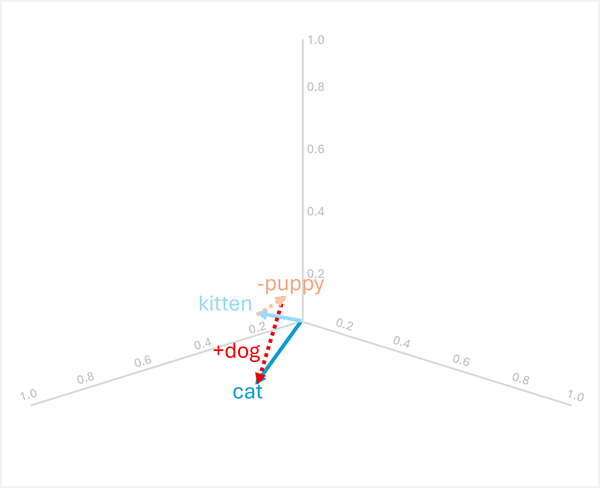
Ці приклади демонструють, як векторні операції можуть захоплювати лінгвістичні зв'язки та дозволяти міркувати про семантичні закономірності.
Використання семантичних моделей для текстового аналізу
Векторні семантичні моделі надають потужні можливості для багатьох поширених завдань аналізу тексту.
Узагальнення тексту
Семантичні вкладення дозволяють екстрактивне узагальнення, ідентифікуючи речення з векторами, які найкраще репрезентують загальний документ. Кодуючи кожне речення як вектор (часто усереднюючи або об'єднуючи вкладення його складових слів), можна розрахувати, які речення є найбільш центральними для значення документа. Ці центральні речення можна виділити для формування резюме, яке охоплює ключові теми.
Вилучення ключових слів
Векторна схожість дозволяє визначити найважливіші терміни в документі, порівнюючи вкладення кожного слова з загальним семантичним представленням документа. Слова, вектори яких найбільше схожі на вектор документа або є найбільш центральними при розгляді всіх векторів слів у документі, ймовірно, є ключовими термінами, що представляють основні теми.
Розпізнавання іменованих сутностей
Семантичні моделі можна тонко налаштувати для розпізнавання іменованих сутностей (людей, організацій, локацій тощо), вивчаючи векторні представлення, які кластеризують подібні типи сутностей разом. Під час висновку модель аналізує вкладення кожного токена та його контекст, щоб визначити, чи представляє він іменовану сутність і, якщо так, то який тип.
Класифікація тексту
Для завдань, таких як аналіз настроїв або категоризація тем, документи можна представляти як агреговані вектори (наприклад, середнє значення всіх вкладень слів у документі). Ці вектори документів потім можуть використовуватися як ознаки для класифікаторів машинного навчання або безпосередньо порівнюватися з векторами прототипів класів для призначення категорій. Оскільки семантично схожі документи мають подібні векторні орієнтації, цей підхід фактично групує пов'язаний контент і розрізняє різні категорії.