创建自定义模型服务终结点
本文介绍如何使用 Databricks 模型服务来创建为自定义模型提供服务的模型服务终结点。
该模型服务提供了下列用于为终结点创建提供服务的选项:
- 服务 UI
- REST API
- MLflow 部署 SDK
若要了解如何创建为生成式 AI 基础模型提供服务的终结点,请参阅创建为终结点提供服务的生成式 AI 模型。
要求
- 工作区必须位于受支持的区域。
- 如果将自定义库或来自专用镜像服务器的库与模型配合使用,请在创建模型终结点之前,参阅将自定义 Python 库与模型服务配合使用。
- 若要使用 MLflow 部署 SDK 创建这些终结点,必须安装 MLflow 部署客户端。 要安装它,请运行:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
访问控制
要了解模型服务终结点的访问控制选项以进行终结点管理,请参阅管理模型服务终结点的权限。
还可以添加环境变量来存储模型服务的凭据。 请参阅配置从模型服务终结点对资源的访问权限
创建终结点
Serving UI
可以使用服务 UI 为模型服务创建终结点。
单击边栏中的“服务”以显示服务 UI。
单击“创建服务终结点”。
对于在工作区模型注册表或 Unity 目录中注册的模型:
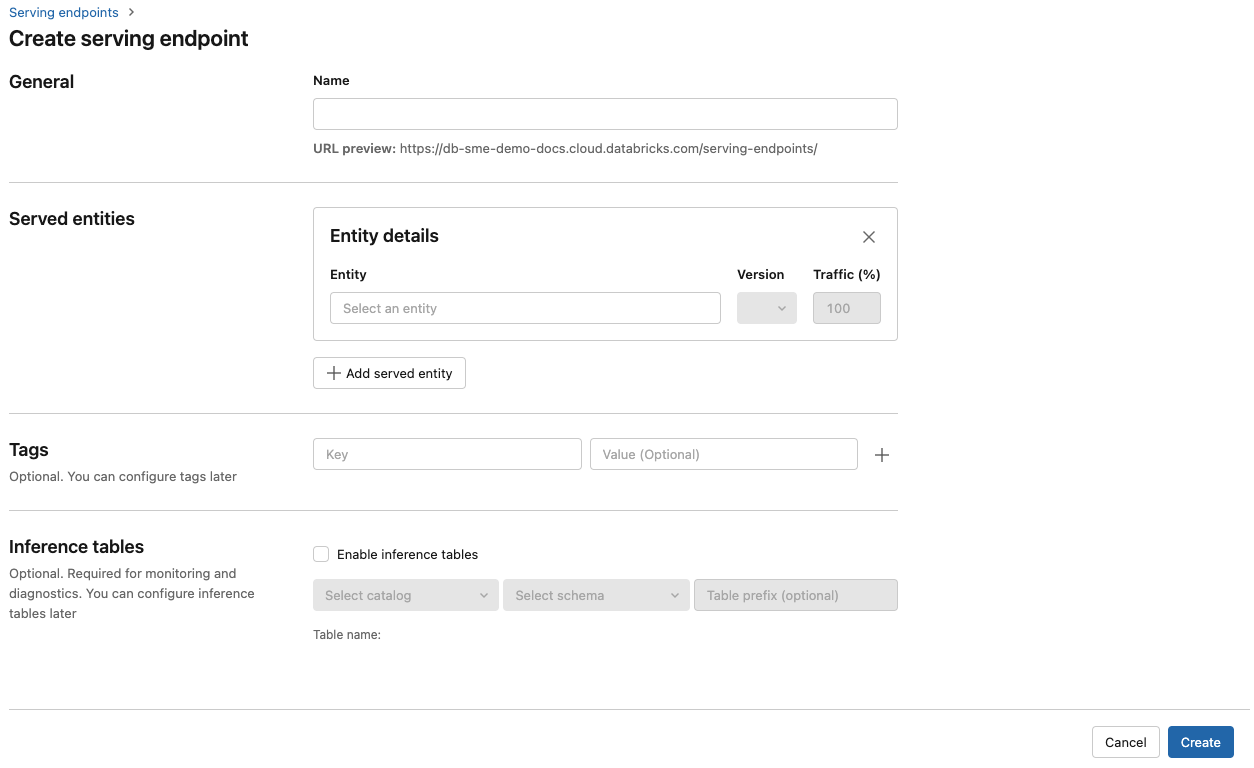
在“名称”字段中,提供终结点的名称。
在“服务的实体”部分中
- 单击“实体”字段以打开“选择服务的实体”窗体。
- 选择要服务的模型类型。 窗体会根据所选内容动态更新。
- 选择要服务的模型和模型版本。
- 选择要路由到服务的模型的流量百分比。
- 选择要使用的计算大小。 可以将 CPU 或 GPU 计算用于工作负荷。 有关可用 GPU 计算的详细信息,请参阅 GPU 工作负载类型。
- 在“计算横向扩展”下,选择计算横向扩展的大小,该大小对应于此服务的模型可以同时处理的请求数量。 此数字应大致等于 QPS x 模型运行时。
- 可用大小包括:小(适用于 0-4 个请求)、中(适用于 8-16 个请求)、大(适用于 16-64 个请求)。
- 指明终结点是否应在不使用时缩放为零。
单击 “创建” 。 此时将显示“服务终结点”页,其中“服务终结点状态”显示为“未就绪”。
REST API
可以使用 REST API 创建终结点。 有关终结点配置参数,请参阅 POST /api/2.0/serving-endpoints。
以下示例创建一个终结点,该终结点为模型注册表中注册的 ads1 模型的第一个版本提供服务。 若要从 Unity Catalog 指定模型,请提供完整的模型名称,包括父目录和架构,例如 catalog.schema.example-model。
POST /api/2.0/serving-endpoints
{
"name": "workspace-model-endpoint",
"config":{
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
},
{
"entity_name": "my-ads-model",
"entity_version": "4",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":{
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
},
{
"served_model_name": "my-ads-model-4",
"traffic_percentage": 20
}
]
}
},
"tags": [
{
"key": "team",
"value": "data science"
}
]
}
以下是示例响应。 终结点的 config_update 状态为 NOT_UPDATING ,服务模型处于 READY 状态。
{
"name": "workspace-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "my-ads-model-3",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
},
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
MLflow 部署 SDK
MLflow 部署提供用于创建、更新和删除任务的 API。 面向这些任务的 API 接受与服务终结点的 REST API 相同的参数。 有关终结点配置参数,请参阅 POST /api/2.0/serving-endpoints。
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="workspace-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "3",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "my-ads-model-3",
"traffic_percentage": 100
}
]
}
}
)
也可执行以下操作:
- 将终结点配置为服务多个模型。
- 配置终结点以优化路由。
- 将终结点配置为使用 Databricks 机密访问外部资源。
- 启用推理表,以自动捕获传入请求和对模型服务终结点的传出响应。
GPU 工作负载类型
GPU 部署与以下包版本兼容:
- Pytorch 1.13.0 - 2.0.1
- TensorFlow 2.5.0 - 2.13.0
- MLflow 2.4.0 及更高版本
若要使用 GPU 部署模型,请在创建终结点或使用 API 进行终结点配置更新时,在终结点配置中包括 workload_type 字段。 若要使用“服务”UI 为 GPU 工作负载配置终结点,请从“计算类型”下拉列表中选择所需的 GPU 类型。
{
"served_entities": [{
"name": "ads1",
"entity_version": "2",
"workload_type": "GPU_LARGE",
"workload_size": "Small",
"scale_to_zero_enabled": false,
}]
}
下表汇总了支持的可用 GPU 工作负载类型。
| GPU 工作负载类型 | GPU 实例 | GPU 内存 |
|---|---|---|
GPU_SMALL |
1xT4 | 16GB |
GPU_LARGE |
1xA100 | 80GB |
GPU_LARGE_2 |
2xA100 | 160GB |
修改自定义模型终结点
启用自定义模型终结点后,可根据需要更新计算配置。 如果需要模型的其他资源,此配置将尤其有用。 在为模型服务分配哪些资源方面,工作负载大小和计算配置起着关键作用。
在新配置准备就绪之前,旧配置会一直为预测流量提供服务。 正在进行更新时,无法进行其他更新。 但是,可以从“服务”UI 取消正在进行的更新。
Serving UI
在启用模型终结点后,选择“编辑终结点”以修改终结点的计算配置。
您可以执行下列操作:
- 有几个工作负载大小可供选择,并且自动缩放会在工作负载大小内自动配置。
- 指定终结点在不使用时是否应缩减到零。
- 修改要路由到所服务模型的流量百分比。
选择终结点详细信息页面右上方的“取消更新”可以取消正在进行的配置更新。 此功能仅在“服务”UI 中可用。
REST API
下面是使用 REST API 进行的终结点配置更新示例。 请参阅 PUT /api/2.0/service-endpoints/{name}/config。
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "workspace-model-endpoint",
"config":{
"served_entities": [
{
"name": "ads-entity"
"entity_name": "my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
MLflow 部署 SDK
MLflow 部署 SDK 使用与 REST API 相同的参数。有关请求和响应架构详细信息,请参阅 PUT /api/2.0/serving-endpoints/{name}/config。
以下代码示例使用 Unity Catalog 模型注册表中的模型:
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
为模型终结点评分
若要为模型评分,可以将请求发送到模型服务终结点。
- 请参阅查询自定义模型的服务终结点。
- 请参阅查询基础模型。
其他资源
- 管理模型服务终结点。
- 查询自定义模型的服务终结点。
- 查询基础模型。
- Mosaic AI Model Serving 中的外部模型。
- 用于监视和调试模型的推理表。
- 如果想要使用 Python,可以使用 Databricks 实时服务 Python SDK。
笔记本示例
以下笔记本包含可用于启动和运行模型服务终结点的不同 Databricks 注册模型。
可以按照导入笔记本中的说明将模型示例导入工作区。 从其中一个示例中选择并创建模型后,在 MLflow 模型注册表中注册它,然后按照 UI 工作流步骤实现模型服务。
为模型服务笔记本训练和注册 scikit-learn 模型
为模型服务笔记本训练和注册 HuggingFace 模型
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈