教學課程:在 Azure Machine Learning 中上傳、存取及探索資料
適用於: Python SDK azure-ai-ml v2 (目前)
Python SDK azure-ai-ml v2 (目前)
在本教學課程中,您將了解如何:
- 將資料上傳至雲端儲存體
- 建立 Azure Machine Learning 資料資產
- 在筆記本中存取資料,以進行互動式開發
- 建立新版本的資料資產
機器學習專案的開始通常涉及探勘資料分析 (EDA)、資料前置處理 (清理、特徵工程),以及建立機器學習模型原型來驗證假設。 此原型專案階段有高度互動性。 適合使用 Python 互動式控制台在 IDE 或 Jupyter 筆記本中開發。 本教學課程說明這些想法。
這段影片會示範如何開始使用 Azure Machine Learning 工作室,以便遵循教學課程中的步驟。 影片示範如何建立筆記本、複製筆記本、建立計算執行個體,以及下載教學課程所需的資料。 這些步驟也會於下列各節中說明。
必要條件
-
若要使用 Azure Machine Learning,您必須先有工作區。 如果您沒有工作區,請完成建立要開始使用所需要的資源以建立工作區,並深入了解其使用方式。
-
登入 Studio,如果工作區尚未開啟,請選取您的工作區。
-
在工作區開啟或建立筆記本:
- 如果您想要將程式碼複製/貼到資料格中,請建立新筆記本。
- 或者,從工作室的 [範例] 區段開啟 tutorials/get-started-notebooks/explore-data.ipynb。 然後選取 [複製] 以將筆記本新增至 [檔案]。 (查看可在哪裡找到範例。)
設定核心
在開啟的筆記本上方的頂端列上,如果您還沒有計算執行個體,請建立計算執行個體。

如果計算執行個體已停止,請選取 [啟動計算],並等到其執行為止。

確定位於右上方的核心是
Python 3.10 - SDK v2。 如果不是,則使用下拉式清單選取此核心。
如果您看到橫幅指出您需要進行驗證,請選取 [驗證]。



重要
本教學課程的其餘部分包含教學課程筆記本的儲存格。 將其複製/貼入您的新筆記本中,或立即切換至您複製的筆記本。
下載本教學課程中使用的資料
就資料擷取而言,Azure 資料總管會處理這些格式的未經處理資料。 本教學課程會使用此 CSV 格式的信用卡用戶端資料範例。 我們可以看到步驟在 Azure Machine Learning 資源中進行。 在該資源中,我們將直接在此筆記本所在的資料夾下,建立有建議資料名稱的本機資料夾。
注意
本教學課程取決於 Azure Machine Learning 資源資料夾位置中放置的資料。 在本教學課程中,'local' 指的是該 Azure Machine Learning 資源中的資料夾位置。
選取三個點下方的 [開啟終端機],如下圖所示:

終端機視窗會在新的索引標籤開啟。
請確定您
cd至此筆記本所在的相同資料夾。 例如,如果筆記本位於名為 get-started-notebooks 的資料夾:cd get-started-notebooks # modify this to the path where your notebook is located在終端機視窗中輸入下列命令,將資料複製到計算執行個體:
mkdir data cd data # the sub-folder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv您現在可以關閉終端機視窗。
深入了解 UCI Machine Learning 存放庫上的此項資料。
建立工作區的控制代碼
在深入探討程式碼之前,您需要可參考工作區的方法。 您會建立 ml_client 以獲得工作區的控制代碼。 接著,您會使用 ml_client 來管理資源和作業。
在下一個資料格中,輸入您的訂用帳戶識別碼、資源群組名稱和工作區名稱。 若要尋找這些值:
- 在右上方的 Azure Machine Learning 工作室工具列中,選取您的工作區名稱。
- 將工作區、資源群組和訂閱識別碼的值複製到程式碼。
- 您必須複製一個值、關閉區域並貼上,然後返回處理下一個值。
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
注意
建立 MLClient 時不會連線至工作區。 用戶端初始化有延遲性,會等到第一次需要進行呼叫時才開始 (這會在下一個程式碼資料格發生)。
將資料上傳至雲端儲存體
Azure Machine Learning 會使用統一資源識別項 (URI),其指向雲端中的儲存體位置。 URI 可讓您輕鬆地存取筆記本和作業中的資料。 資料 URI 格式看起來類似於您在網頁瀏覽器中用來存取網頁的 Web URL。 例如:
- 從公用 https 伺服器存取資料:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - 從 Azure Data Lake Gen 2 存取資料:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Azure Machine Learning 資料資產類似於網頁瀏覽器書籤 (我的最愛)。 您不必記住指向最常用資料的冗長儲存體路徑 (URI),只要建立資料資產,就能以自訂名稱存取該資產。
建立資料資產也會建立資料來源位置的參考,以及其中繼資料的複本。 因為資料留在現有位置,所以不會產生額外儲存成本,也不損及資料來源的完整性。 您可以從 Azure Machine Learning 資料存放區、Azure 儲存體、公用 URL 或本機檔案建立資料資產。
提示
對於較小的資料上傳,Azure Machine Learning 資料資產建立適用於將資料從本機電腦資源上傳至雲端儲存體。 此方法可避免需要額外的工具或公用程式。 不過,較龐大的資料上傳可能需要專用的工具或公用程式,例如 azcopy。 azcopy 命令行工具會將資料移入 Azure 儲存體,以及從 Azure 儲存體中移出資料。 在這裡深入了解 azcopy。
下一個筆記本資料格會建立資料資產。 程式碼範例會將未經處理資料檔案上傳至指定的雲端儲存空間資源。
每次建立資料資產時,都需要為其製作唯一版本。 如果版本已經存在,您會收到錯誤。 在此程式碼中,我們會使用 "initial" 來進行對資料的第一次讀取。 如果該版本已存在,我們會略過再次建立版本的步驟。
您也可以省略版本參數,並從 1 開始產生版本號碼,然後從該處遞增。
在本教學課程中,我們會使用名稱 "initial" 作為第一個版本。 建立生產機器學習管線教學課程也會使用此版本的資料,因此在這裡我們使用了將在該教學課程中再次看到的值。
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
選取左側的 [資料],即可查看上傳的資料。 您會看到資料已上傳,並會建立資料資產:

此資料命名為信用卡並位於 [資料資產] 索引標籤中,系統會在 [名稱] 資料行中顯示。 此資料上傳至工作區名為 workspaceblobstore 的預設資料存放區,可以在 [資料來源] 資料行中看到。
Azure Machine Learning 資料存放區是 Azure 上現有儲存體帳戶的參考。 資料存放區提供下列優點:
- 常見且易於使用的 API,可與不同的儲存體類型 (Blob/檔案/Azure Data Lake Storage) 和驗證方法互動。
- 以小組模式合作時,可更輕鬆探索實用的資料存放區。
- 在指令碼中,提供隱藏認證型資料存取連線資訊的方法 (服務主體/SAS/金鑰)。
存取筆記本中的資料
Pandas 直接支援 URI;此範例示範如何從 Azure Machine Learning 資料存放區讀取 CSV 檔案:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
不過,如先前所述,要記住這些 URI 可能有些困難。 此外,您必須以資源的實際值,手動取代 pd.read_csv 命令中的所有 <substring> 值。
您想要為經常存取的資料建立資料資產。 以下是在 Pandas 中存取 CSV 檔案較簡單的方式:
重要
在 Notebook 資料格中,執行此程式碼以在 Jupyter 核心中安裝 azureml-fsspec Python 程式庫:
%pip install -U azureml-fsspec
import pandas as pd
# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
若要深入了解筆記本中的資料存取,請參閱在互動部署期間存取 Azure 雲端儲存體的資料。
建立新版本的資料資產
您可能已經注意到資料需要一些清理動作,以使其適合用來定型機器學習模型。 其中包含:
- 兩個標頭
- 用戶端識別碼資料行;我們不會在機器學習中使用這項功能
- 回應變數名稱中的空格
此外,相較於 CSV 格式,Parquet 檔案格式會是儲存此資料的較佳方式。 Parquet 提供壓縮,並會維護結構描述。 因此,若要清理資料並將其儲存在 Parquet 中,請使用:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
下表顯示在先前的步驟中,所下載的原始 default_of_credit_card_clients.csv .CSV 檔案中的資料結構。 上傳的資料包含 23 個解釋變數和 1 個回應變數,如下所示:
| 資料行名稱 | 變數類型 | 描述 |
|---|---|---|
| X1 | 解釋 | 指定的信用額度金額 (新臺幣):包括個人消費者的信用額度及其家庭 (附屬) 信用額度。 |
| X2 | 解釋 | 性別 (1 = 男性;2 = 女性)。 |
| X3 | 解釋 | 教育 (1 = 研究生;2 = 大學;3 = 高中;4 = 其他)。 |
| X4 | 解釋 | 婚姻狀況 (1 = 已婚;2 = 單身;3 = 其他)。 |
| X5 | 解釋 | 年齡 (歲)。 |
| X6-X11 | 解釋 | 過去付款的歷程記錄。 我們追蹤了過去每月的付款記錄 (從 2005 年 4 月至 9 月)。 -1 = 準時付款;1 = 付款延遲一個月;2 = 付款延遲兩個月; . ;8 = 付款延遲八個月;9 = 付款延遲九個月以上。 |
| X12-17 | 解釋 | 2005 年 4 月至 9 月的對帳單金額 (新臺幣)。 |
| X18-23 | 解釋 | 2005 年 4 月至 9 月的先前付款金額 (新臺幣)。 |
| Y | 回應 | 預設付款 (是 = 1,否 = 0) |
接下來,建立資料資產的新版本 (資料會自動上傳至雲端儲存體)。 在此版本中,我們將新增時間值,以便每次執行此程式碼時,都會建立不同的版本號碼。
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
清理過的 parquet 檔案是最新版本的資料來源。 此程式碼會先顯示 CSV 版本結果集,然後顯示 Parquet 版本:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
清除資源
如果您打算立即繼續進行其他教學課程,請跳至後續步驟。
停止計算執行個體
如果現在不打算使用,請停止計算執行個體:
- 在工作室的左側導覽區域中,選取 [計算]。
- 在頂端索引標籤中,選取 [計算執行個體]
- 選取清單中的計算執行個體。
- 在頂端工具列中,選取 [停止]。
刪除所有資源
重要
您所建立的資源可用來作為其他 Azure Machine Learning 教學課程和操作說明文章的先決條件。
如果不打算使用您建立的任何資源,請刪除以免產生任何費用:
在 Azure 入口網站中,選取最左邊的 [資源群組]。
從清單中,選取您所建立的資源群組。
選取 [刪除資源群組]。
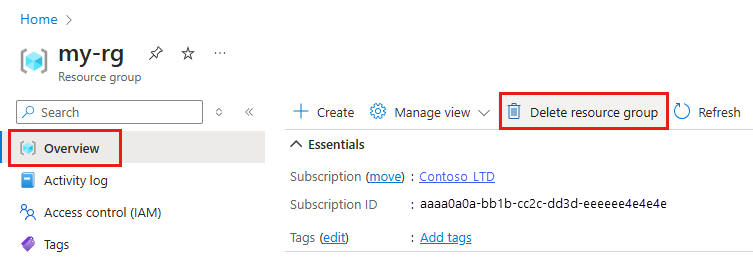
輸入資源群組名稱。 接著選取刪除。
下一步
如需資料資產的詳細資訊,請參閱建立資料資產。
若要深入了解資料存放區,請參閱建立資料存放區。
繼續進行教學課程,以了解如何開發定型指令碼。