使用 Azure Data Studio 连接到 SQL Server 大数据群集
适用范围:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
本文介绍如何从 Azure Data Studio 连接到 SQL Server 2019 大数据群集。
重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
先决条件
- 已部署的 SQL Server 2019 大数据群集。
- SQL Server 2019 大数据工具:
- Azure Data Studio
- SQL Server 2019 扩展
- kubectl
- azdata
连接到群集
若要使用 Azure Data Studio 连接到大数据群集,请与群集中的 SQL Server 主实例建立新的连接。 以下是操作方法。
查找 SQL Server 主实例终结点:
azdata bdc endpoint list -e sql-server-master提示
有关如何检索终结点的详细信息,请参阅检索终结点。
在 Azure Data Studio 中,按“F1”>“新建连接” 。
在“连接类型”中,选择“Microsoft SQL Server” 。
在“服务器名称”文本框中键入为 SQL Server 主实例找到的终结点名称(例如 <IP_Address>,31433)。
选择身份验证类型。 对于在大数据群集中运行的 SQL Server 主实例,仅支持 Windows 身份验证和 SQL 登录 。
如果使用的是 SQL 登录,请输入 SQL 登录的用户名和密码 。
提示
默认情况下,用户名 SA 在大数据群集部署过程中处于禁用状态 。 在部署期间预配一个新的 sysadmin 用户,其名称和密码分别对应于 AZDATA_USERNAME 和 AZDATA_PASSWORD 环境变量(这是在部署之前或部署期间设置) 。
将目标“数据库名称”更改为你的关系数据库之一 。
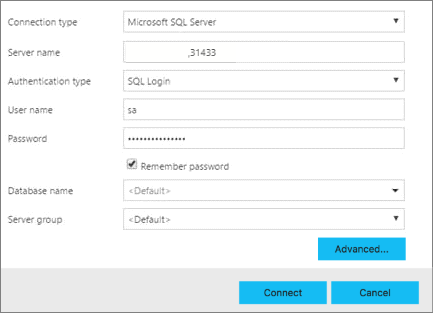
按“连接”,此时应显示“服务器仪表板” 。
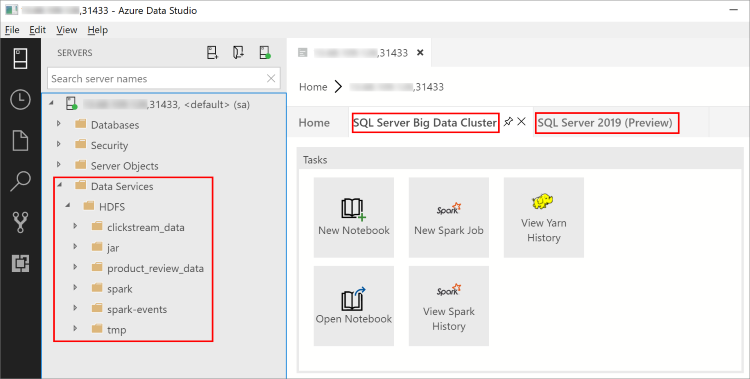
借助 Azure Data Studio 2019 年 2 月版,连接到 SQL Server 主实例还使你可以与 HDFS/Spark 网关交互。 这意味着无需为下一部分介绍的 HDFS 和 Spark 使用单独的连接。
对象资源管理器现在包含一个新的“数据服务”节点,其为大数据群集任务提供右键单击支持,例如新建笔记本或提交 spark 作业 。
“数据服务”节点还包含一个 HDFS 文件夹,通过该文件夹可浏览 HDFS 的内容并执行涉及 HDFS 的常见任务(例如,创建外部表或打开笔记本以分析 HDFS 内容) 。
安装扩展时,连接的“服务器仪表板”还包含“SQL Server 大数据群集”和“SQL Server 2019”选项卡 。
后续步骤
有关 SQL Server 2019 大数据群集 的详细信息,请参阅什么是 SQL Server 2019 大数据群集。