在多台计算机上为 SQL Server 大数据群集部署配置 Kubernetes
适用范围:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
重要
Microsoft SQL Server 2019 大数据群集附加产品将停用。 对 SQL Server 2019 大数据群集的支持将于 2025 年 2 月 28 日结束。 具有软件保障的 SQL Server 2019 的所有现有用户都将在平台上获得完全支持,在此之前,该软件将继续通过 SQL Server 累积更新进行维护。 有关详细信息,请参阅公告博客文章和 Microsoft SQL Server 平台上的大数据选项。
本文提供示例,说明如何使用 kubeadm 在多台计算机上为 SQL Server 大数据群集 部署配置 Kubernetes。 在此示例中,目标为多台 Ubuntu 16.04 或 18.04 LTS 计算机(物理或虚拟)。 如果要部署到其他 Linux 平台,则必须更改部分命令以匹配你的系统。
提示
有关用于配置 Kubernetes 的示例脚本,请参阅在 Ubuntu 20.04 LTS 上使用 Kubeadm 创建 Kubernetes 群集。
有关可自动在 VM 上完成单节点 kubeadm 部署,然后在其上部署大数据群集默认配置的示例脚本,请参阅部署单节点 kubeadm 群集。
先决条件
- 至少三个 Linux 物理计算机或虚拟机
- 每台计算机的建议配置:
- 8 个 CPU
- 64 GB 内存
- 100 GB 存储
重要
在启动大数据群集部署之前,请确保部署所针对的所有 Kubernetes 节点上的时钟同步。 大数据群集具有各种时间敏感型服务的内置运行状况属性,并且时钟偏差可能导致不正确的状态。
准备计算机
在每台计算机上,必须满足多个先决条件。 在 bash 终端中,在每台计算机上运行以下命令:
将当前计算机添加到
/etc/hosts文件:echo $(hostname -i) $(hostname) | sudo tee -a /etc/hosts禁用所有设备上的交换功能。
sudo sed -i "/ swap / s/^/#/" /etc/fstab sudo swapoff -a导入密钥并注册 Kubernetes 的存储库。
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo sudo tee /etc/apt/trusted.gpg.d/apt-key.asc echo 'deb http://apt.kubernetes.io/ kubernetes-xenial main' | sudo tee -a /etc/apt/sources.list.d/kubernetes.list在计算机上配置 docker 和 Kubernetes 必备组件。
KUBE_DPKG_VERSION=1.15.0-00 #or your other target K8s version, which should be at least 1.13. sudo apt-get update && \ sudo apt-get install -y ebtables ethtool && \ sudo apt-get install -y docker.io && \ sudo apt-get install -y apt-transport-https && \ sudo apt-get install -y kubelet=$KUBE_DPKG_VERSION kubeadm=$KUBE_DPKG_VERSION kubectl=$KUBE_DPKG_VERSION && \ curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get | bash设置
net.bridge.bridge-nf-call-iptables=1。 在 Ubuntu 18.04 上,以下命令首先启用br_netfilter。. /etc/os-release if [ "$VERSION_CODENAME" == "bionic" ]; then sudo modprobe br_netfilter; fi sudo sysctl net.bridge.bridge-nf-call-iptables=1
配置 Kubernetes 主计算机
在每台计算机上运行上述命令后,选择其中一台计算机作为 Kubernetes 主计算机。 然后在该计算机上运行以下命令。
首先,使用以下命令在当前目录中创建 rbac.yaml 文件。
cat <<EOF > rbac.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: default-rbac subjects: - kind: ServiceAccount name: default namespace: default roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io EOF在此计算机上初始化 Kubernetes 主计算机。 下面的示例脚本指定 Kubernetes 版本
1.15.0。 你使用的版本取决于 Kubernetes 群集。KUBE_VERSION=1.15.0 sudo kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=$KUBE_VERSION应看到 Kubernetes 主计算机已成功初始化的输出。
请注意
kubeadm join命令,在其他服务器上加入 Kubernetes 群集时需要用到它。 复制此命令以供将来使用。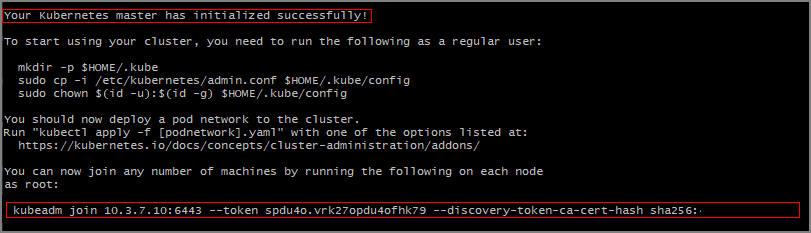
在主目录中设置 Kubernetes 配置文件。
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config配置群集和 Kubernetes 仪表板。
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml helm init kubectl apply -f rbac.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml kubectl create clusterrolebinding kubernetes-dashboard --clusterrole=cluster-admin --serviceaccount=kube-system:kubernetes-dashboard
配置 Kubernetes 代理
其他计算机将在群集中充当 Kubernetes 代理。
在其他每台计算机上,运行在上一部分中复制的 kubeadm join 命令。

查看群集状态
若要验证到群集的连接,请使用 kubectl get 命令返回群集节点列表。
kubectl get nodes
后续步骤
本文中的步骤在多台 Ubuntu 计算机上配置了 Kubernetes 群集。 下一步是部署 SQL Server 2019 大数据群集。 有关说明,请参阅以下文章: