诊断和解决 SQL Server 上的旋转锁争用问题
本文提供有关如何识别和解决高并发系统上 SQL Server 应用程序中的旋转锁争用相关问题的深入信息。
注意
本文记载的建议和最佳做法基于实际 OLTP 系统开发和部署过程中的实际经验。 它最初由 Microsoft SQL Server 客户咨询团队 (SQLCAT) 发布。
背景
过去,商用 Windows Server 计算机仅使用一个或两个微处理器/CPU 芯片,且 CPU 设计为仅拥有一个处理器或“内核”。 计算机处理能力的提高已通过使用速度更快的 CPU 实现,这在很大程度上因晶体管密度的提升而成为可能。 根据“摩尔定律”,自 1971 年开发出第一个通用单芯片 CPU 以来,晶体管密度或可放置在集成电路上的晶体管数量保持每两年翻一番。 近年来,使用速度更快的 CPU 来提高计算机处理能力的传统方法通过构建具有多个 CPU 的计算机得到了增强。 撰写本文时,Intel Nehalem CPU 体系结构的每个 CPU 最多可容纳 8 个内核,在 8 插槽系统中使用时,其可通过使用多线程并行处理 (SMT) 技术倍增至 128 个逻辑处理器。 在 Intel CPU 上,SMT 称为超线程。 随着与 x86 兼容的计算机上的逻辑处理器数量的增加,与并发相关的问题也随着逻辑处理器争用资源而增加。 本指南介绍如何识别和解决在具有某些工作负荷的高并发系统上运行 SQL Server 应用程序时观察到的特定资源争用问题。
在本部分中,我们分析了 SQLCAT 团队从诊断和解决旋转锁争用问题中汲取的经验教训。 旋转锁争用是在大规模系统上的真实客户工作负荷中观察到的一类并发问题。
旋转锁争用的症状和原因
本部分介绍如何诊断与旋转锁争用相关的问题,这对 SQL Server 上的 OLTP 应用程序的性能具有负面影响。 旋转锁诊断和故障排除应被视为高级主题,需要具备调试工具和 Windows 内部机制知识。
旋转锁是轻量级同步基元,用于保护对数据结构的访问。 旋转锁不是 SQL Server 所独有的。 操作系统会在仅当短时间需要访问给定数据结构的情况下使用它们。 尝试获取旋转锁的线程无法获得访问权限时,它会在循环中执行,并定期检查以确定资源是否可用,而不是立即暂停。 一段时间过后,等待旋转锁的线程将在可以获取资源前暂停。 暂停使得在同一 CPU 上运行的其他线程可以执行。 此行为称为回退,稍后将在本文中进行深入讨论。
SQL Server 利用旋转锁来保护对其某些内部数据结构的访问。 旋转锁在引擎内部用于以类似闩锁的方式序列化对特定数据结构的访问。 闩锁和旋转锁之间的主要区别在于,旋转锁将旋转(执行循环)一段时间,以检查数据结构的可用性,而如果资源不可用,当线程尝试访问受闩锁保护的结构时,会立即暂停。 暂停要求从 CPU 切换线程上下文,以便另一个线程可以执行。 这是相对昂贵的操作,对于短时间持有的资源而言,整体上更高效的做法是允许线程在循环中执行并定期检查资源的可用性。
SQL Server 2022 (16.x) 中引入的数据库引擎的内部调整使旋转锁更高效。
症状
在任何繁忙的高并发系统上,通常都会看到受旋转锁保护的频繁访问的结构上存在活动争用现象。 仅当争用带来大量 CPU 开销时,才认为此用法有问题。 旋转锁统计信息由 SQL Server 中的 sys.dm_os_spinlock_stats 动态管理视图 (DMV) 公开。 例如,此查询生成以下输出:
注意
本文稍后将讨论有关如何解释此 DMV 返回的信息的更多详细信息。
SELECT * FROM sys.dm_os_spinlock_stats
ORDER BY spins DESC;
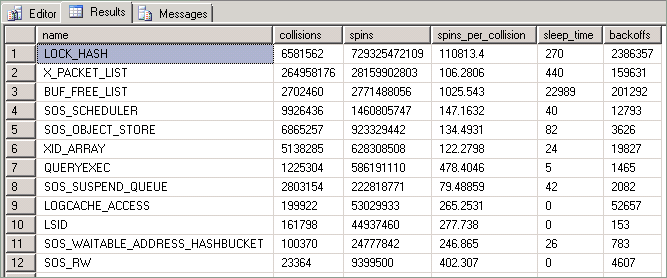
此查询公开的统计信息如下:
| 列 | 说明 |
|---|---|
| Collisions | 每次阻止线程访问受旋转锁保护的某个资源时,此值会递增。 |
| Spins | 每次线程在等待旋转锁变得可用期间执行循环时,此值会递增。 这是对线程在尝试获取资源时所完成的工作量的度量。 |
| Spins_per_collision | 每次冲突的旋转比率。 |
| Sleep time | 与回避事件相关;但与本文中所述的方法无关。 |
| Backoffs | 在尝试访问持有资源的“旋转”线程确定需要允许同一 CPU 上的其他线程执行时发生。 |
出于本讨论的目的,需要注意的统计信息包括系统处于高负载状态时在特定时段内发生的冲突、旋转和退避事件的数量。 当线程尝试访问受旋转锁保护的资源时,即会发生冲突。 发生冲突时,冲突计数会递增,且线程将开始在循环中旋转,并定期检查资源是否可用。 每次线程旋转(循环)时,旋转计数会递增。
每次冲突的旋转次数是对线程持有旋转锁期间发生的旋转次数的度量,将告知线程持有旋转锁期间发生的旋转次数。 例如,每次冲突的较少旋转次数和高冲突计数意味着在旋转锁下发生少量旋转并且有许多线程在争用。 大量旋转意味着在旋转锁代码中花费的旋转时间相对较长(即代码在哈希桶中遍历大量条目)。 随着争用增加(冲突计数因此增加),旋转次数也会增加。
可以使用类似旋转的方式来看待退避。 根据设计,为了避免过多的 CPU 浪费,旋转锁在可以访问持有的资源之前不会无限期地继续旋转。 为了确保旋转锁不会过度使用 CPU 资源,旋转锁会回退,或停止旋转并“休眠”。 旋转锁会退避,而无论它们是否曾获得目标资源的所有权。 这样做是为了允许在 CPU 上安排执行其他线程,以期可以提高工作效率。 引擎的默认行为是在执行退避之前先旋转固定的时间间隔。 尝试获取旋转锁时需要保持高速缓存并发状态,这相对于旋转的 CPU 开销而言是 CPU 密集型操作。 因此,通常会谨慎执行尝试获取旋转锁的操作,并且不会在线程每次旋转时都执行。 在 SQL Server 中,某些旋转锁类型(例如 LOCK_HASH)通过利用获取旋转锁的尝试之间的指数级间隔增加(需要满足一定限制要求)进行改进,这通常会减少对 CPU 性能的影响。
下图提供旋转锁算法的概念视图:

典型方案
旋转锁争用可能因多种原因发生,这些原因可能与数据库设计决策无关。 因为旋转锁控制对内部数据结构的访问,所以旋转锁争用的表现方式与缓冲区闩锁争用的表现方式不同,后者直接受架构设计选择和数据访问模式的影响。
主要与旋转锁争用相关的症状为大量旋转和许多尝试获取同一旋转锁的线程导致的高 CPU 使用率。 通常情况下,在 CPU 内核数 > = 24 的系统上(尤其是在 CPU 内核数 > = 32 的系统上)观察到了这一现象。 如前所述,对于具有大量负载的高并发 OLTP 系统,旋转锁上某些级别的争用是正常现象,并且 sys.dm_os_spinlock_stats DMV 经常报告在长时间运行的系统上有大量旋转(数十亿次/数万亿次)。 同样,观察到任何给定旋转锁类型具有大量旋转并不足以确定对工作负载性能有负面影响。
以下多种症状的组合可能指示存在旋转锁争用:
对于特定旋转锁类型,观察到大量旋转和退避。
系统正在经历高 CPU 使用率或 CPU 使用率高峰。 在高 CPU 使用率场景中,会在 SOS_SCHEDULER_YIELD 上看到大量信号等待(由 DMV
sys.dm_os_wait_stats报告)。系统正在经历高并发性。
CPU 使用率和旋转次数的增加与吞吐量不成比例。
重要
即使上述每个条件都成立,CPU 使用率高的根本原因仍有可能在其他地方。 实际上,在大多数情况下,CPU 使用率增加是由于旋转锁争用以外的原因。 CPU 使用率增加的一些较常见的原因包括:
由于基础数据增长,查询随时间推移而变得更加昂贵,从而导致需要对内存常驻数据执行额外的逻辑读取。
查询计划的更改导致非最优执行。
如果所有这些条件都成立,请对可能的旋转锁争用问题执行进一步调查。
可轻松诊断的一种常见现象是吞吐量和 CPU 使用率之间的重大分歧。 许多 OLTP 工作负荷在(吞吐量/系统上的用户数量)与 CPU 使用率之间建立了关系。 观察到的较高旋转次数以及 CPU 使用率和吞吐量的重大分歧可能指示引入 CPU 开销的旋转锁争用问题。 此处需要重点注意的是,当某些查询随时间推移变得越来越昂贵时,通常会在系统上看到此类分歧。 例如,针对随时间推移而执行更多逻辑读取的数据集发出的查询可能会导致类似的症状。
排查这些类型的问题时,至关重要的是排除造成高 CPU 使用率的其他更常见的原因。
示例
在以下示例中,CPU 使用率和吞吐量之间存在几乎线性的关系,并以每秒事务数度量。 在此处看到一些分歧是正常现象,因为开销随任何工作负载的增加而产生。 如图所示,分歧变得明显。 一旦 CPU 使用率达到 100%,吞吐量也会急剧下降。

以 3 分钟为间隔测量旋转次数时,我们看到旋转的增长更多表现为指数性,而不是线性,这指示旋转锁争用可能有问题。

如前所述,旋转锁在处于高负载状态的高并发系统上最常见。
容易出现此问题的一些场景包括:
由于无法完全限定对象名称而导致的名称解析问题。 有关详细信息,请参阅编译锁导致的 SQL Server 阻塞的说明。 本文详细介绍了此特定问题。
锁管理器中针对频繁访问同一锁(例如,位于频繁读取的行上的共享锁)的工作负荷的锁哈希桶争用。 此类争用表现为 LOCK_HASH 类型的旋转锁。 在某种特定情况下,我们发现此问题是由于在测试环境中对访问模式进行错误建模而导致的。 在此环境中,由于测试参数配置不正确,持续访问完全相同的行的线程数量超出了预期。
MSDTC 事务协调器之间的延迟程度较高时,DTC 事务速率会很高。 SQLCAT 博客条目 Resolving DTC Related Waits and Tuning Scalability of DTC(解决与 DTC 相关的等待问题并优化 DTC 的可伸缩性)中详细记录了此特定问题。
诊断旋转锁争用
本部分提供用于诊断 SQL Server 旋转锁争用的信息。 用于诊断旋转锁争用的主要工具包括:
| 工具 | 使用 |
|---|---|
| 性能监视器 | 寻找高 CPU 使用率条件或吞吐量与 CPU 使用率之间的分歧。 |
sys.dm_os_spinlock 统计信息 DMV** |
寻找一段时间内的大量旋转和退避事件。 |
| SQL Server 扩展事件 | 用于跟踪发生大量旋转的旋转锁的调用堆栈。 |
| 内存转储 | 在某些情况下,必须使用 Windows 调试工具分析 SQL Server 进程的内存转储。 通常情况下,在 Microsoft SQL Server 支持团队参与的情况下进行此级别的分析。 |
诊断 SQL Server 旋转锁争用的常规技术过程如下:
步骤 1:确定是否存在可能与旋转锁有关的争用。
步骤 2:从
sys.dm_ os_spinlock_stats 中捕获统计信息,以找到发生最多争用的旋转锁类型。步骤 3:获取 sqlservr.exe 的调试符号 (sqlservr.pdb),并将这些符号放在与 SQL Server 实例的 SQL Server 服务 .exe 文件 (sqlservr.exe) 相同的目录中。\要查看回退事件的调用堆栈,必须具有针对所运行的特定 SQL Server 版本的符号。 Microsoft 符号服务器上提供 SQL Server 符号。 有关如何从 Microsoft 符号服务器下载符号的详细信息,请参阅使用符号调试。
步骤 4:使用 SQL Server 扩展事件跟踪需要注意的旋转锁类型的退避事件。
扩展事件提供跟踪“退避”事件并捕获最常尝试获取旋转锁的操作的调用堆栈的功能。 通过分析调用堆栈,可以确定导致任何特定旋转锁争用的操作类型。
诊断演练
以下演练演示如何在实际场景中使用工具和方法来诊断旋转锁争用问题。 本演练基于运行基准测试的客户参与场景,其中在具有 64 个物理内核并具有 1 TB 内存的 8 插槽服务器中模拟约 6,500 个并发用户。
症状
观察到 CPU 的周期性高峰,这使 CPU 使用率接近 100%。 观察到吞吐量和 CPU 使用率之间的分歧导致问题。 在出现大型 CPU 高峰时,已建立在特定时间间隔内的高 CPU 使用率期间发生大量旋转的模式。
在这种极端情况下,争用导致旋转锁护航条件。 当线程不再能够为工作负荷提供服务,而是花费所有处理资源尝试获得对锁的访问权限时,就会发生护航效应。 性能监视器日志说明事务日志吞吐量和 CPU 使用率之间的这种分歧,并最终说明 CPU 使用率的大型高峰。

在查询 sys.dm_os_spinlock_stats 以确定 SOS_CACHESTORE 上是否存在显著争用后,使用扩展事件脚本来度量需要关注的旋转锁类型的回退事件数量。
| 名称 | 冲突次数 | 旋转次数 | 每次冲突的旋转次数 | 退避次数 |
|---|---|---|---|---|
SOS_CACHESTORE |
14,752,117 | 942,869,471,526 | 63,914 | 67,900,620 |
SOS_SUSPEND_QUEUE |
69,267,367 | 473,760,338,765 | 6,840 | 2,167,281 |
LOCK_HASH |
5,765,761 | 260,885,816,584 | 45,247 | 3,739,208 |
MUTEX |
2,802,773 | 9,767,503,682 | 3,485 | 350,997 |
SOS_SCHEDULER |
1,207,007 | 3,692,845,572 | 3,060 | 109,746 |
量化旋转影响的最直接方法是查看具有最高旋转次数的旋转锁类型在同样的 1 分钟间隔内由 sys.dm_os_spinlock_stats 公开的回退事件的数量。 此方法用于检测显著争用时效果最佳,因为它指示线程在等待获取旋转锁期间何时耗尽旋转限制次数。 以下脚本说明一种高级方法,该方法利用扩展事件来测量相关退避事件并识别争用所在的特定代码路径。
有关 SQL Server 中扩展事件的详细信息,请参阅 SQL Server 扩展事件简介。
脚本
/*
This script is provided "AS IS" with no warranties, and confers no rights.
This script will monitor for backoff events over a given period of time and
capture the code paths (callstacks) for those.
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
Examples:
61LOCK_HASH
144 SOS_CACHESTORE
08MUTEX
*/
--create the even session that will capture the callstacks to a bucketizer
--more information is available in this reference: http://msdn.microsoft.com/en-us/library/bb630354.aspx
CREATE EVENT SESSION spin_lock_backoff ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
OR TYPE = 144 --SOS_CACHESTORE
OR TYPE = 8 --MUTEX
) ADD TARGET package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
);
--Ensure the session was created
SELECT * FROM sys.dm_xe_sessions
WHERE name = 'spin_lock_backoff';
--Run this section to measure the contention
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = START;
--wait to measure the number of backoffs over a 1 minute period
WAITFOR DELAY '00:01:00';
--To view the data
--1. Ensure the sqlservr.pdb is in the same directory as the sqlservr.exe
--2. Enable this trace flag to turn on symbol resolution
DBCC TRACEON (3656, -1);
--Get the callstacks from the bucketize target
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spin_lock_backoff';
--clean up the session
ALTER EVENT SESSION spin_lock_backoff ON SERVER STATE = STOP;
DROP EVENT SESSION spin_lock_backoff ON SERVER;
通过分析输出,我们可以看到 SOS_CACHESTORE 旋转的最常见代码路径的调用堆栈。 在 CPU 使用率很高的时间段内,该脚本在几个不同的时间运行,以检查返回的调用堆栈中的一致性。 两个输出(35,668 和 8,506)之间槽桶计数最高的调用堆栈相同。 这些调用堆栈的“插槽计数”比下一最高计数条目大两个数量级。 此条件指示需要关注的代码路径。
注意
看到之前脚本返回的调用堆栈并不少见。 在脚本运行了 1 分钟时,我们观察到槽计数 > 1000 的调用堆栈出现问题,但槽计数 > 10,000 的调用堆栈由于槽计数更高,因此更可能出现问题。
注意
为了便于阅读,已清除以下输出的格式设置。
输出 1
<BucketizerTarget truncated="0" buckets="256">
<Slot count="35668" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid
CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey
CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="752" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
输出 2
<BucketizerTarget truncated="0" buckets="256">
<Slot count="8506" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep+c7 [ @ 0+0x0 SpinlockBase::Backoff Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
NTGroupInfo::`vector deleting destructor'
</value>
</Slot>
<Slot count="190" trunc="0">
<value>
XeSosPkg::spinlock_backoff::Publish
SpinlockBase::Sleep
SpinlockBase::Backoff
Spinlock<144,1,0>::SpinToAcquireOptimistic
SOS_CacheStore::GetUserData
OpenSystemTableRowset
CMEDScanBase::Rowset
CMEDScan::StartSearch
CMEDCatalogOwner::GetOwnerAliasIdFromSid CMEDCatalogOwner::LookupPrimaryIdInCatalog CMEDCacheEntryFactory::GetProxiedCacheEntryByAltKey CMEDCatalogOwner::GetProxyOwnerBySID
CMEDProxyDatabase::GetOwnerBySID
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
ISECTmpEntryStore::Get
</value>
</Slot>
在上一示例中,最需要关注的堆栈具有最高的插槽计数(35,668 和 8,506),实际上,其插槽计数 > 1000。
现在的问题可能是,“我如何处理此信息”? 通常情况下,需要深入了解 SQL Server 引擎才能使用调用堆栈信息,因此,故障排除过程此时会进入灰色区域。 在此特定情况下,通过查看调用堆栈,我们可以看到发生问题的代码路径与安全性和元数据查找有关(如以下堆栈框所示:CMEDCatalogOwner::GetProxyOwnerBySID & CMEDProxyDatabase::GetOwnerBySID))。
单独来看,很难使用此信息解决问题,但确实为我们提供了一些思路,以便集中精力进行其他故障排除来进一步隔离问题。
因为此问题似乎与执行安全性相关检查的代码路径有关,所以我们决定运行测试,在测试中,连接到数据库的应用程序用户被授予 sysadmin 特权。 尽管不建议在生产环境中使用此方法,但在我们的测试环境中,它被证明是有用的故障排除步骤。 使用提升的权限 (sysadmin) 运行会话时,与争用相关的 CPU 高峰消失。
选项和解决方法
显然,排查旋转锁争用问题可能是一项非凡的任务。 没有“一种通用的最佳方法”。 排查和解决任何性能问题的第一步都是确定根本原因。 使用本文介绍的方法和工具是执行所需分析的第一步,以了解与旋转锁相关的争用点。
随着 SQL Server 新版本的开发,引擎通过实现针对高并发系统进行了更好优化的代码,继续提高可伸缩性。 SQL Server 为高并发系统引入了许多优化,其中之一是最常见争用点的指数退避。 从 SQL Server 2012 开始,提供一些特定增强功能,这些增强功能通过为引擎内的所有旋转锁使用指数退避算法来专门改进此特定领域。
在设计需要极高性能和极大规模的高端应用程序时,请考虑如何使 SQL Server 中所需的代码路径保持尽可能短。 越短的代码路径意味着数据库引擎执行的工作越少,并且可自然而然地避免争用点。 许多最佳做法的附带作用是减少引擎所需完成的工作量,因此可以优化工作负荷性能。
以本文前面部分的几个最佳做法为例:
完全限定名称:所有对象的完全限定名称将导致 SQL Server 无需执行解析名称所需的代码路径。 不在对存储过程的调用中使用完全限定的名称时,我们也在遇到的 SOS_CACHESTORE 旋转锁类型上观察到了争用点。 无法完全限定这些名称会导致 SQL Server 需要为用户查找默认架构,这会导致执行 SQL 所需的代码路径变长。
参数化查询:另一个示例是利用参数化查询和存储过程调用来减少生成执行计划所需完成的工作。 这也会导致执行的代码路径变短。
LOCK_HASH 争用:在某些情况下,某些锁结构或哈希桶冲突中的争用不可避免。 即使 SQL Server 引擎对大多数锁结构进行了分区,但有时获取锁结果仍会导致访问同一哈希桶。 例如,一个应用程序通过许多线程并发访问同一行(即引用数据)。 这些类型的问题可以通过以下方法解决:在数据库架构内横向扩展此引用数据,或在可能的情况下使用 NOLOCK 提示。
优化 SQL Server 工作负荷的第一道防线始终是标准优化方法(例如,编制索引、查询优化、I/O 优化等)。 但是,除可以执行的标准优化外,遵循减少执行操作所需的代码量的做法也是一种重要的方法。 即使遵循最佳做法,在繁忙的高并发系统上仍然有可能发生旋转锁争用。 使用本文中的工具和方法可以帮助隔离或排除这些类型的问题,并确定何时需要联系合适的 Microsoft 资源来提供帮助。
希望这些方法将为此类故障排除提供有用的方法,并为 SQL Server 提供的一些更高级的性能分析方法提供见解。
附录:自动执行内存转储捕获
事实证明,当旋转锁争用变得显著时,以下扩展事件脚本对于自动收集内存转储很有用。 在某些情况下,将需要内存转储来执行完整问题诊断,或者 Microsoft 支持团队将要求提供内存转储来执行深入分析。 在 SQL Server 2008 中,归类器捕获的调用堆栈存在 16 个帧的限制,该深度可能不足以准确确定调用堆栈在引擎中的确切输入位置。 SQL Server 2012 中引入了改进,将归类器捕获的调用堆栈中的帧数增加到 32。
以下 SQL 脚本可用于自动执行捕获内存转储的过程,以帮助分析旋转锁争用:
/*
This script is provided "AS IS" with no warranties, and confers no rights.
Use: This procedure will monitor for spinlocks with a high number of backoff events
over a defined time period which would indicate that there is likely significant
spin lock contention.
Modify the variables noted below before running.
Requires:
xp_cmdshell to be enabled
sp_configure 'xp_cmd', 1
go
reconfigure
go
*********************************************************************************************************/
USE tempdb;
GO
IF object_id('sp_xevent_dump_on_backoffs') IS NOT NULL
DROP PROCEDURE sp_xevent_dump_on_backoffs
GO
CREATE PROCEDURE sp_xevent_dump_on_backoffs (
@sqldumper_path NVARCHAR(max) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"',
@dump_threshold INT = 500, --capture mini dump when the slot count for the top bucket exceeds this
@total_delay_time_seconds INT = 60, --poll for 60 seconds
@PID INT = 0,
@output_path NVARCHAR(MAX) = 'c:\',
@dump_captured_flag INT = 0 OUTPUT
)
AS
/*
--Find the spinlock types
select map_value, map_key, name from sys.dm_xe_map_values
where name = 'spinlock_types'
order by map_value asc
--Example: Get the type value for any given spinlock type
select map_value, map_key, name from sys.dm_xe_map_values
where map_value IN ('SOS_CACHESTORE', 'LOCK_HASH', 'MUTEX')
*/
IF EXISTS (
SELECT *
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump'
)
DROP EVENT SESSION spinlock_backoff_with_dump
ON SERVER
CREATE EVENT SESSION spinlock_backoff_with_dump ON SERVER
ADD EVENT sqlos.spinlock_backoff (
ACTION(package0.callstack) WHERE type = 61 --LOCK_HASH
--or type = 144 --SOS_CACHESTORE
--or type = 8 --MUTEX
--or type = 53 --LOGCACHE_ACCESS
--or type = 41 --LOGFLUSHQ
--or type = 25 --SQL_MGR
--or type = 39 --XDESMGR
) ADD target package0.asynchronous_bucketizer (
SET filtering_event_name = 'sqlos.spinlock_backoff',
source_type = 1,
source = 'package0.callstack'
)
WITH (
MAX_MEMORY = 50 MB,
MEMORY_PARTITION_MODE = PER_NODE
)
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = START;
DECLARE @instance_name NVARCHAR(MAX) = @@SERVICENAME;
DECLARE @loop_count INT = 1;
DECLARE @xml_result XML;
DECLARE @slot_count BIGINT;
DECLARE @xp_cmdshell NVARCHAR(MAX) = NULL;
--start polling for the backoffs
PRINT 'Polling for: ' + convert(VARCHAR(32), @total_delay_time_seconds) + ' seconds';
WHILE (@loop_count < CAST(@total_delay_time_seconds / 1 AS INT))
BEGIN
WAITFOR DELAY '00:00:01'
--get the xml from the bucketizer for the session
SELECT @xml_result = CAST(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
--get the highest slot count from the bucketizer
SELECT @slot_count = @xml_result.value(N'(//Slot/@count)[1]', 'int');
--if the slot count is higher than the threshold in the one minute period
--dump the process and clean up session
IF (@slot_count > @dump_threshold)
BEGIN
PRINT 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 c:\ '''
SELECT @xp_cmdshell = 'exec xp_cmdshell ''' + @sqldumper_path + ' ' + convert(NVARCHAR(max), @PID) + ' 0 0x800 0 ' + @output_path + ' '''
EXEC sp_executesql @xp_cmdshell
PRINT 'loop count: ' + convert(VARCHAR(128), @loop_count)
PRINT 'slot count: ' + convert(VARCHAR(128), @slot_count)
SET @dump_captured_flag = 1
BREAK
END
--otherwise loop
SET @loop_count = @loop_count + 1
END;
--see what was collected then clean up
DBCC TRACEON (3656, -1);
SELECT event_session_address,
target_name,
execution_count,
cast(target_data AS XML)
FROM sys.dm_xe_session_targets xst
INNER JOIN sys.dm_xe_sessions xs
ON (xst.event_session_address = xs.address)
WHERE xs.name = 'spinlock_backoff_with_dump';
ALTER EVENT SESSION spinlock_backoff_with_dump ON SERVER STATE = STOP;
DROP EVENT SESSION spinlock_backoff_with_dump ON SERVER;
GO
/* CAPTURE THE DUMPS
******************************************************************/
--Example: This will run continuously until a dump is created.
DECLARE @sqldumper_path NVARCHAR(MAX) = '"c:\Program Files\Microsoft SQL Server\100\Shared\SqlDumper.exe"';
DECLARE @dump_threshold INT = 300; --capture mini dump when the slot count for the top bucket exceeds this
DECLARE @total_delay_time_seconds INT = 60; --poll for 60 seconds
DECLARE @PID INT = 0;
DECLARE @flag TINYINT = 0;
DECLARE @dump_count TINYINT = 0;
DECLARE @max_dumps TINYINT = 3; --stop after collecting this many dumps
DECLARE @output_path NVARCHAR(max) = 'c:\'; --no spaces in the path please :)
--Get the process id for sql server
DECLARE @error_log TABLE (
LogDate DATETIME,
ProcessInfo VARCHAR(255),
TEXT VARCHAR(max)
);
INSERT INTO @error_log
EXEC ('xp_readerrorlog 0, 1, ''Server Process ID''');
SELECT @PID = convert(INT, (REPLACE(REPLACE(TEXT, 'Server Process ID is ', ''), '.', '')))
FROM @error_log
WHERE TEXT LIKE ('Server Process ID is%');
PRINT 'SQL Server PID: ' + convert(VARCHAR(6), @PID);
--Loop to monitor the spinlocks and capture dumps. while (@dump_count < @max_dumps)
BEGIN
EXEC sp_xevent_dump_on_backoffs @sqldumper_path = @sqldumper_path,
@dump_threshold = @dump_threshold,
@total_delay_time_seconds = @total_delay_time_seconds,
@PID = @PID,
@output_path = @output_path,
@dump_captured_flag = @flag OUTPUT
IF (@flag > 0)
SET @dump_count = @dump_count + 1
PRINT 'Dump Count: ' + convert(VARCHAR(2), @dump_count)
WAITFOR DELAY '00:00:02'
END;
附录:随时间推移捕获旋转锁统计信息
以下脚本可用于查看特定时间段内的旋转锁统计信息。 每次运行时,它将返回当前值和收集的先前值之间的增量。
/* Snapshot the current spinlock stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
USE tempdb;
GO
DECLARE @current_snap_time DATETIME;
DECLARE @previous_snap_time DATETIME;
SET @current_snap_time = GETDATE();
IF NOT EXISTS (
SELECT name
FROM tempdb.sys.sysobjects
WHERE name LIKE '#_spin_waits%'
)
CREATE TABLE #_spin_waits (
lock_name VARCHAR(128),
collisions BIGINT,
spins BIGINT,
sleep_time BIGINT,
backoffs BIGINT,
snap_time DATETIME
);
--capture the current stats
INSERT INTO #_spin_waits (
lock_name,
collisions,
spins,
sleep_time,
backoffs,
snap_time
)
SELECT name,
collisions,
spins,
sleep_time,
backoffs,
@current_snap_time
FROM sys.dm_os_spinlock_stats;
SELECT TOP 1 @previous_snap_time = snap_time
FROM #_spin_waits
WHERE snap_time < (
SELECT max(snap_time)
FROM #_spin_waits
)
ORDER BY snap_time DESC;
--get delta in the spin locks stats
SELECT TOP 10 spins_current.lock_name,
(spins_current.collisions - spins_previous.collisions) AS collisions,
(spins_current.spins - spins_previous.spins) AS spins,
(spins_current.sleep_time - spins_previous.sleep_time) AS sleep_time,
(spins_current.backoffs - spins_previous.backoffs) AS backoffs,
spins_previous.snap_time AS [start_time],
spins_current.snap_time AS [end_time],
DATEDIFF(ss, @previous_snap_time, @current_snap_time) AS [seconds_in_sample]
FROM #_spin_waits spins_current
INNER JOIN (
SELECT *
FROM #_spin_waits
WHERE snap_time = @previous_snap_time
) spins_previous
ON (spins_previous.lock_name = spins_current.lock_name)
WHERE spins_current.snap_time = @current_snap_time
AND spins_previous.snap_time = @previous_snap_time
AND spins_current.spins > 0
ORDER BY (spins_current.spins - spins_previous.spins) DESC;
--clean up table
DELETE
FROM #_spin_waits
WHERE snap_time = @previous_snap_time;