适用于:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() 分析平台系统(PDW)
分析平台系统(PDW)![]() Microsoft Fabric中的SQL数据库
Microsoft Fabric中的SQL数据库
SQL Server 使用联接基于它们之间的逻辑关系从多个表中检索数据。 联接是关系数据库作的基础,使你能够将数据从两个或多个表合并到单个结果集中。
SQL Server 实现逻辑联接作(由 Transact-SQL 语法定义)和物理联接作(用于执行联接的实际算法)。 了解这两个方面有助于编写高效的查询并优化数据库性能。
逻辑联接作包括:
- 内部联接
- 左、右和完整外部联接
- 交叉联接
物理联接作包括:
- 嵌套循环联接
- 合并联接
- 哈希联接
- 自适应联接(适用于: SQL Server 2017 (14.x) 及更高版本)
本文介绍联接的工作原理、何时使用不同的联接类型,以及查询优化器如何根据表大小、可用索引和数据分布等因素选择最有效的联接算法。
Note
有关联接语法的详细信息,请参阅 FROM 子句和 JOIN、APPLY、PIVOT。
联接基础知识
通过联接,可以从两个或多个表中根据各个表之间的逻辑关系来检索数据。 联接指明了 SQL Server 应如何使用一个表中的数据来选择另一个表中的行。
联接条件可通过以下方式定义两个表在查询中的关联方式:
- 指定每个表中要用于联接的列。 典型的联接条件在一个表中指定一个外键,而在另一个表中指定与其关联的键。
- 指定用于比较各列的值的逻辑运算符(例如 = 或 <>)。
联接使用以下 Transact-SQL 语法以逻辑方式表示:
[ INNER ] JOINLEFT [ OUTER ] JOINRIGHT [ OUTER ] JOINFULL [ OUTER ] JOINCROSS JOIN
可以在 或 FROM 子句中指定内部联接WHERE。 只能在 子句中指定外部联接和交叉联接FROM。 联接条件与 WHERE 和 HAVING 搜索条件相结合,用于控制从 FROM 子句所引用的基表中选定的行。
在 FROM 子句中指定联接条件有助于将这些联接条件与 WHERE 子句中可能指定的其他任何搜索条件分开,建议用这种方法来指定联接。 简化的 ISO FROM 子句联接语法如下:
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
- join_type 指定执行的联接类型:内部、外部或交叉联接。 有关不同类型联接的相关说明,请参阅 From 子句。
- join_condition 定义用于对每一对联接行进行求值的谓词。
下面 Code 是 FROM 子句联接规范示例:
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
下面 Code 是使用此联接的一个简单 SELECT 语句:
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
SELECT 语句会返回某个公司所提供的一组产品以及供应商信息,该公司名以字母 F 开头,并且产品价格在 10 美元以上。
当在单个查询中引用多个表时,所有列引用都必须是明确的。 在上例中,ProductVendor 和 Vendor 表都含有名为 BusinessEntityID 的列。 在查询所引用的两个或多个表中,任何重复的列名都必须用表名加以限定。 此示例中对 Vendor 列的所有引用均已限定。
如果查询中使用的两个或多个表中没有重复列名,则对列名的引用不必使用表名进行限定。 如上例所示。
SELECT此类子句有时难以理解,因为没有指示提供每列的表。 如果所有的列都用它们的表名加以限定,将会提高查询的可读性。 如果使用了表的别名,将会进一步提高可读性,尤其是当表名自身必须用数据库名和所有者名加以限定时。 下例 Code 与上例相同,只不过分配了表的别名并且用表的别名对列加以限定,从而提高了可读性:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
上例是在 FROM 子句中指定联接条件的,这是首选的方法。 下列查询包含相同的联接条件,该联接条件在 WHERE 子句中指定:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
联接的 SELECT 列表可以引用联接表中的所有列或任意一部分列。 该 SELECT 列表不需要包含联接中每个表的列。 例如,在三表联接中,只能用一个表作为中间表来联接另外两个表,而选择列表不必引用该中间表的任何列。 这也称为“反半联接”。
虽然联接条件通常使用相等比较 (=),但也可以像指定其他谓词一样指定其他比较运算符或关系运算符。 有关详细信息,请参阅 比较运算符 和 WHERE。
当 SQL Server 处理联接时,查询优化器从多种可行方法中选择最高效的方法来处理联接。 这包括选择最有效的物理联接类型、表将联接的顺序,甚至使用无法直接用 Transact-SQL 语法表示的逻辑联接作类型,例如 半联接 和 反半联接。 各种联接的物理执行可以使用许多不同的优化,因此无法可靠地预测。 有关半联接和反半联接的详细信息,请参阅 逻辑和物理 showplan 运算符参考。
联接条件中使用的列不需要具有相同的名称或相同数据类型。 但是,如果数据类型不相同,则它们必须兼容,或者是 SQL Server 可以隐式转换的类型。 如果无法隐式转换数据类型,则联接条件必须使用函数显式转换数据类型 CAST 。 有关隐式转换和显式转换的详细信息,请参阅数据类型转换(数据库引擎)。
大多数使用联接的查询可以用子查询(嵌套在其他查询中的查询)重写,并且大多数子查询可以重写为联接。 有关子查询的详细信息,请参阅子查询(SQL Server)。
Note
不能直接在 ntext、文本或图像列上联接表。 但可以使用 SUBSTRING 在 ntext、text 或 image 列上间接联接表。
例如,SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) 可对表 t1 和 t2 中每个文本列的前 20 个字符进行两表内联。
此外,另一种可以采用的比较两个表中 ntext 或 text 列的方法是用 WHERE 子句比较这些列的长度,例如:WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info)
了解嵌套循环联接
如果一个联接输入很小(不到 10 行),而另一个联接输入很大而且已在其联接列上创建了索引,则索引 Nested Loops 连接是最快的联接操作,因为它们需要的 I/O 和比较都最少。
嵌套循环联接也称为嵌套迭代,它将一个联接输入用作外部输入表(显示为图形执行计划中的顶端输入),将另一个联接输入用作内部(底端)输入表。 外部循环逐行处理外部输入表。 内部循环会针对每个外部行执行,在内部输入表中搜索匹配行。
最简单的情况是,搜索时扫描整个表或索引;这称为单纯嵌套循环联接。 如果搜索利用索引,则它称为 索引嵌套循环联接。 如果索引作为查询计划的一部分生成(并在查询完成后销毁),则它称为 临时索引嵌套循环联接。 查询优化器考虑了所有这些不同情况。
如果外部输入较小而内部输入较大且预先创建了索引,则嵌套循环联接尤其有效。 在许多小事务中(如那些只影响较小的一组行的事务),索引嵌套循环联接优于合并联接和哈希联接。 但在大型查询中,嵌套循环联接通常不是最佳选择。
嵌套循环联接运算符的 OPTIMIZED 属性设置为 True 时,这意味着当内侧表很大时,使用优化的嵌套循环(或批处理排序)来最大程度地减少 I/O,而不管是否对其进行并行化。 鉴于排序本身是隐藏操作,在分析执行计划时,给定计划中的这种优化可能不是非常明显。 但是可以在计划 XML 中查找属性 OPTIMIZED,它表明嵌套循环联接可能会尝试重新排序输入行以提高 I/O 性能。
合并联接
如果两个联接输入不小,但在联接列上排序(例如,如果通过扫描排序索引获得联接输入),则合并联接是最快的联接作。 如果两个联接输入都很大,而且这两个输入的大小差不多,则预先排序的合并联接提供的性能与哈希联接相近。 但是,如果这两个输入的大小相差很大,则哈希联接操作通常快得多。
合并联接要求对合并列进行排序,这些输入由联接谓词的相等性 (ON) 子句定义。 通常,查询优化器扫描索引(如果在适当的一组列上存在索引),或在合并联接的下面放一个排序运算符。 在极少数情况下,虽然会有多个等效子句,但只用其中一些可用的等效子句获得合并列。
由于每个输入都已排序,因此 Merge Join 运算符将从每个输入获取一行并将其进行比较。 例如,对于内联接操作,如果行相等则返回。 如果它们不相等,则会丢弃低值行,并从该输入获取另一行。 这一过程将重复进行,直到处理完所有的行为止。
合并联接操作可以是常规操作,也可以是多对多操作。 多对多合并联接使用临时表存储行。 如果每个输入中有重复值,则在处理其中一个输入中的每个重复项时,另一个输入必须重绕到重复项的开始位置。
如果存在驻留谓词,则所有满足合并谓词的行都将对该驻留谓词取值,而只返回那些满足该驻留谓词的行。
合并联接本身的速度很快,但如果需要排序操作,选择合并联接就会非常费时。 然而,如果数据量很大且能够从现有 B 树索引中获得预排序的所需数据,则合并联接通常是最快的可用联接算法。
哈希联接
哈希联接可以有效处理未排序的大型非索引输入。 它们对复杂查询的中间结果很有用,因为:
- 中间结果不会编制索引(除非显式保存到磁盘,然后编制索引),并且通常不会对查询计划中下一个作进行适当排序。
- 查询优化器只估计中间结果的大小。 由于对于复杂查询,估计可能有很大的误差,因此如果中间结果比预期的大得多,则处理中间结果的算法不仅必须有效而且必须适度弱化。
哈希联接可以减少使用非规范化。 非规范化一般通过减少联接操作获得更好的性能,尽管这样做有冗余之险(如不一致的更新)。 哈希联接则减少使用非规范化的需要。 哈希联接使垂直分区(用单独的文件或索引代表单个表中的几组列)得以成为物理数据库设计的可行选项。
哈希联接有两种输入:生成输入和探测输入。 查询优化器指派这些角色,使两个输入中较小的那个作为生成输入。
哈希联接用于多种设置匹配操作:内部联接;左外部联接、右外部联接和完全外部联接;左半联接和右半联接;交集;并集和差异。 此外,哈希联接的某种变形可以进行重复删除和分组,例如 SUM(salary) GROUP BY department。 这些修改对生成和探测角色只使用一个输入。
以下几节介绍了不同类型的哈希联接:内存中的哈希联接、Grace 哈希联接和递归哈希联接。
内存中的哈希联接
哈希联接先扫描或计算整个生成输入,然后在内存中生成哈希表。 根据计算得出的哈希键的哈希值,将每行插入哈希存储桶。 如果整个生成输入小于可用内存,则可以将所有行都插入哈希表中。 生成阶段之后是探测阶段。 一次一行地对整个探测输入进行扫描或计算,并为每个探测行计算哈希键的值,扫描相应的哈希存储桶并生成匹配项。
Grace 哈希联接
如果生成输入不适合内存,哈希联接将分几个步骤进行。 这称为“Grace 哈希联接”。 每一步都分为生成阶段和探测阶段。 首先,消耗整个生成和探测输入并将其分区(使用哈希键上的哈希函数)为多个文件。 对哈希键使用哈希函数可以保证任意两个联接记录一定位于相同的文件对中。 因此,联接两个大输入的任务简化为相同任务的多个较小的实例。 然后将哈希联接应用于每对分区文件。
递归哈希联接
如果生成输入非常大,以至于标准外部合并的输入需要多个合并级别,则需要多个分区步骤和多个分区级别。 如果只有某些分区较大,则只需对那些分区使用附加的分区步骤。 为了使所有分区步骤尽可能快,将使用大的异步 I/O 操作以便单个线程就能使多个磁盘驱动器繁忙工作。
Note
如果生成输入仅稍大于可用内存,则内存中的哈希联接和 Grace 哈希联接的元素将结合在一个步骤中,生成混合哈希联接。
在优化期间,并不总是能够确定使用哪个哈希联接。 因此,SQL Server 开始时使用内存中的哈希联接,然后根据生成输入的大小逐渐转换到 Grace 哈希联接和递归哈希联接。
如果查询优化器错误地预计两个输入中哪个较小并由此确定哪个作为生成输入,生成角色和探测角色将动态反转。 哈希联接确保使用较小的溢出文件作为生成输入。 这一技术称为角色反转。 至少一个文件溢出到磁盘后,哈希联接中才会发生角色反转。
Note
角色反转的发生独立于任何查询提示或结构。 角色逆转不会显示在查询计划中;发生时,对用户是透明的。
哈希救助
术语“哈希援助”有时用于描述 Grace 哈希联接或递归哈希联接。
Note
递归哈希联接或哈希援助会导致服务器性能降低。 如果跟踪中显示许多哈希警告事件,请更新正在联接的列上的统计信息。
有关哈希援助的详细信息,请参阅 Hash Warning 事件类。
自适应联接
借助批处理模式自适应联接功能,可延迟选择哈希联接或嵌套循环联接方法,将其延迟到扫描第一个输入之后。 自适应联接运算符可定义用于决定何时切换到嵌套循环计划的阈值。 因此,查询计划可在执行期间动态切换到较好的联接策略,而无需进行重新编译。
Tip
小型和大型联接输入扫描之间频繁振荡的工作负荷将从此功能获益最大。
运行时决策基于以下步骤:
- 如果生成联接输入的行计数足够小,以致于嵌套循环联接优于哈希联接,则计划将切换到嵌套循环算法。
- 如果生成联接输入超过特定行计数阈值,则不会进行切换并且计划将通过哈希联接继续。
以下查询用于说明自适应联接示例:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
查询将返回 336 行。 启用实时查询统计信息会显示以下计划:

在计划中,请注意以下事项:
- 用于为哈希联接生成阶段提供行的列存储索引扫描。
- 新的自适应联接运算符。 此运算符可定义用于决定何时切换到嵌套循环计划的阈值。 对于此示例,阈值为 78 行。 包含 >= 78 行的任何示例均将使用哈希联接。 如果小于阈值,将使用嵌套循环联接。
- 由于查询返回 336 行,超过了阈值,因此,第二个分支表示标准哈希联接操作的探测阶段。 实时查询统计信息将显示流经运算符的行,在本示例中为“672 行,共 672 行”。
- 并且,最后一个分支是供未超出阈值的嵌套循环联接使用的聚集索引查找。 我们将看到显示“0 行,共 336 行”(未使用分支)。
现将计划与同一查询进行对比,但当表中的 Quantity 值只有一行时:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
查询将返回一行。 启用“实时查询统计信息”会显示以下计划:

在计划中,请注意以下事项:
- 返回一行后,聚集索引搜索现已有行流经它。
- 由于哈希联接生成阶段未继续,因此没有流经第二个分支的行。
自适应联接注解
自适应联接引入了比索引嵌套循环联接等效计划更高的内存要求。 它会请求额外的内存,就像嵌套循环属于哈希联接一样。 生成阶段还有一个开销,即即点即用作与嵌套循环流式处理等效联接。 这笔额外成本产生的同时也实现了行计数可在生成输入中波动的方案灵活性。
批处理模式自适应联接适用于语句的初始执行,编译后,根据编译的自适应联结阈值和流经外部输入生成阶段的运行时行,连续执行将保持自适应状态。
如果自适应联接切换到嵌套循环操作,它将使用哈希联接生成已经读取的行。 运算符不会再次重新读取外部引用行。
跟踪自适应联接活动
自适应联接运算符具有以下计划运算符属性:
| Plan 属性 | Description |
|---|---|
| AdaptiveThresholdRows | 显示用于从哈希联接切换到嵌套循环联接的阈值。 |
| EstimatedJoinType | 可能的联接类型。 |
| ActualJoinType | 在实际计划中,显示根据阈值最终选择的联接算法。 |
估计的计划显示自适应联接计划形状,以及定义的自适应联接阈值和估计的联接类型。
Tip
查询存储可捕获并强制执行批处理模式自适应联接计划。
符合自适应联接条件的语句
以下多个条件可使逻辑联接符合批处理模式自适应联接的条件:
- 数据库兼容性级别为 140 或更高级别。
- 查询是
SELECT语句(数据修改语句当前不符合条件)。 - 联接符合同时由索引嵌套循环联接或哈希联接物理算法执行的条件。
- 哈希联接使用批处理模式,通过整体查询中的列存储索引状态、联接直接引用的列存储索引表,或通过使用针对行存储功能批处理模式来启用。
- 嵌套循环联接和哈希联接生成的替代解决方案的第一个子级(外部引用)应相同。
自适应阈值行
下图显示了哈希联接的成本与嵌套循环联接替代的成本之间的示例交集。 在这个交点处,确定了阈值,该阈值将反过来确定将实际用于联接操作的算法。
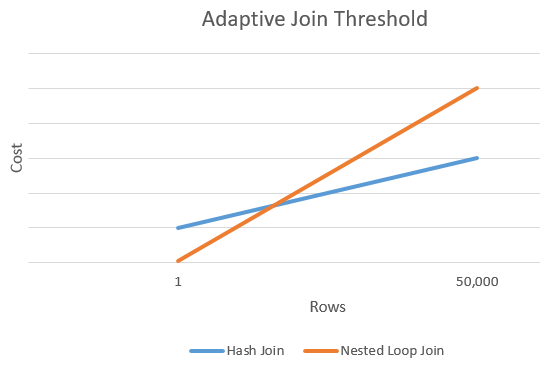
在不更改兼容性级别的情况下禁用自适应联接
可在数据库或语句范围内禁用自适应联接,同时将数据库兼容性级别维持在 140 或更高。
若要对源自数据库的所有查询执行禁用自适应联接,请在对应数据库的上下文中执行以下命令:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
启用后,此设置在 sys.database_scoped_configurations 中将显示为已启用。
若要对源自数据库的所有查询执行重新启用自适应联接,请在对应数据库的上下文中执行以下命令:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
此外,将 DISABLE_BATCH_MODE_ADAPTIVE_JOINS 指定为 USE HINT 查询提示也可为特定查询禁用自适应联接。 例如:
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Note
USE HINT查询提示优先于数据库范围的配置或跟踪标志设置。
NULL 值和联接
如果联接的表的列中存在 null 值,则 null 值不匹配。 如果其中一个联接表的列中出现空值,只能通过外部联接返回这些空值(除非 WHERE 子句不包括空值)。
下面的两个表中,每个表中要参与联接的列中均包含 NULL:
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
将列中的值与列ac的值进行比较的联接不会对具有以下NULL值的列进行匹配:
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
只返回列 4 和 a 中值为 c 的一行:
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
另外,从基表返回的空值与从外部联接返回的空值很难区分开。 例如,下面的 SELECT 语句对这两个表执行左向外部联接:
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
结果集如下。
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
结果不容易区分 NULL 数据 NULL 中表示联接失败的情况。 当 NULL 数据中存在值时,通常最好使用常规联接从结果中省略这些值。