适用于: SQL Server Analysis Services
SQL Server Analysis Services  Azure Analysis Services Fabric/Power BI Premium
Azure Analysis Services Fabric/Power BI Premium
本文总结了最新版本 SQL Server Analysis Services(SSAS)中的新功能、改进、已弃用及已停止使用的功能、行为变更,以及重大的更改。
SQL Server 2025 分析服务
性能改进
带有计算组和格式字符串的 Excel 模型
我们对具有计算组和格式字符串的模型的 MDX 查询进行了显著的性能改进,以减少内存使用率并提高响应能力。 最新变更提高了 Excel 中“分析”功能在包含以下一种或两种模型时的性能和可靠性:
度量值的动态格式字符串
带格式字符串的计算项
有关更多详细信息,请访问 动态格式字符串
DirectQuery 的并行查询执行
DirectQuery 模式下改进的并行度可加快复杂查询的响应时间。 基本思路是通过将多个查询并行化到单个 DAX 查询的数据源来最大程度地提高查询性能。 此查询并行化可减少数据源延迟和网络延迟对查询性能的影响。 有关更多详细信息,请访问此 博客。
水平融合
SQL Server Analysis Services 2025 包含最新版本的水平融合,这是一种查询性能优化,可减少 DAX 生成的 SQL 查询数,从而提高 DirectQuery 效率。 有关更多详细信息,请访问: 宣布水平融合。
DAX 函数和功能
视觉计算
引入视觉计算后,编写 DAX 的方式发生了变化。 可视化计算是直接在可视化上定义和执行的 DAX 计算。 视觉计算可以引用可视化中的任何数据,包括列、度量值或其他视觉计算。 此方法消除了语义模型的复杂性,并简化了编写 DAX 的过程。 可以使用视觉计算来完成常见的业务计算,例如累加总和或移动平均。 若要详细了解如何启用和使用视觉计算,请访问 视觉计算概述。
值筛选器行为
我们引入了一个新选项来控制值筛选器行为。 通过启用“独立值筛选器”设置,用户可以阻止将同一表中的多个筛选器自动合并为单个合并的筛选器。 此更改提供了更大的灵活性,允许更精确和独立的筛选来满足特定的建模需求,并提高数据查询的准确性和控制。 若要为 SSAS 设置此属性,可以使用基于 ValueFilterBehavior 属性的表格对象模型或 TMSL。 有关更多详细信息,请访问: 值筛选器行为。
运算组的选择式
选择表达式允许对满足某些条件时计算行为的方式进行微调控制。 选择表达式引入了其他逻辑,用于处理选择多个计算项或未对计算组进行特定选择的情况。 有关更多详细信息,请访问: 计算组。
DAX 函数改进
SQL Server Analysis Services 2025 包括支持多个新的 DAX 函数和改进,包括:
LINEST 和 LINESTX:这两个函数使用最小平方方法执行线性回归,以计算最适合给定数据的直线并返回描述该线的表。 当给定的已知值 (X) 时,这些函数在预测未知值 (Y) 时特别有用。 有关更多详细信息,请访问: LINEST DAX 函数 和 LINESTX DAX 函数。
INFO Functions:现有的 TMSCHEMA DMV 现在可用作 DAX 函数的新系列,它允许直接在 DAX 中查询有关语义模型的元数据,从而与其他 DAX 函数集成,以增强诊断和分析。 有关更多详细信息,请访问: 信息 DAX 函数。
APPROXIMATEDISTINCTCOUNT:此函数目前可用于 DirectQuery 模式,并通过调用数据源中的相应聚合作(针对查询性能进行优化)来返回列中唯一值的估计计数。 有关更多详细信息,请访问 Approximatedistinctcount DAX 函数,该函数列出了支持的数据源。
窗口函数:此函数使用绝对或相对定位检索结果切片。 通过 WINDOW 函数,可以更轻松地执行计算,例如添加运行总数、移动平均值或类似的计算,这些计算依赖于选择一系列值。 它还附带了两个名为 ORDERBY 和 PARTITIONBY 的帮助程序函数。 有关更多详细信息,请访问:Window DAX 函数。
MINX/MAXX: 我们向 MINX 和 MAXX DAX 函数添加了可选变体参数。 传统上,当存在变体或混合数据类型(如文本和数字)时,这些函数将忽略文本和布尔值。 现在,由于新的可选变量参数设置为 TRUE,函数会考虑文本值。 有关更多详细信息,请访问 MINX DAX 函数 和 MAXX DAX 函数。
小窍门
INFO 函数可能会在 Power BI 中演变,以支持新语义模型项目中的信息发现。 有关可能在 SQL Server Analysis Services 2025 中具有相应 INFO 函数的工件集,请参阅 [MS-SSAS-T]。
新开发人员版本
注释
在正式发布产品之前,不会完全记录对 SQL Server Analysis Services 2025 的完整版本和功能支持。 本文中所述的功能和版本在正式发布之前可能会更改。
以下免费版本旨在提供其相应付费版本的所有功能。 它们可用于开发 SQL Server 应用程序,而无需付费许可证。
对于按版本排序的功能,请查看 SQL Server 版本支持的功能
SQL Server 2025 (17.x) 预览版的版本和支持的功能可能会更改,直到产品正式发布。
标准开发人员版
SQL Server 2025 标准开发人员版是一个获得开发许可的免费版本。 它包括 SQL Server Standard 版本的所有功能。
- 开发标准版的新应用程序。
- 设置过渡环境,以在生产环境中部署现有应用程序之前,先从标准版升级到 SQL Server 2025 标准版。
企业开发人员版
SQL Server 2025 Enterprise Developer Edition 包括 SQL Server Enterprise Edition 功能。
- 开发企业版的新应用程序。
- 在功能上与早期版本中的 Developer Edition 等效。
其他功能
客户端库更新
建议客户升级到最新的 Analysis Services 库,以受益于性能、可靠性和功能改进,例如二进制 XML 支持、TMDL 序列化等。 具体而言,我们已将基于 XMLA 的通信从纯文本 XML 切换到二进制 XML,并为 .NET 客户端库启用压缩。 有关更多详细信息,请访问关于改进基于 xmla 工具通信性能的博客。 还可以始终在 Analysis Services 客户端库下载页上找到最新的客户端库版本。
Unicode 字符处理增强功能
SQL Server Analysis Services 2025 现在通过在 DAX 中为中国政府标准 GB18030 等字符集标准提供 Unicode 代理对支持,从而支持更新的 Unicode 标准。
诊断的执行指标
执行指标现在通过 XEvents 和 Profiler 跟踪公开,使客户能够更有效地分析查询性能。 有关更多详细信息,请访问此 博客。
故障转移群集支持
有关更多详细信息,请参阅有关 升级的加密架构的文章。
SQL Server Analysis Services 2025 中弃用的功能和重大变更
Excel PowerPivot for SharePoint 已停用
我们已从安装程序中删除 Excel PowerPivot for SharePoint 模式。 此功能在以前的版本中已弃用,SQL Server Analysis Services 2025 中不再受支持。
SQL 客户端程序集更新
SQL Server Analysis Services 2025 现在使用较新的 SQL 客户端库。 客户可能需要更新模型定义以反映新的提供程序名称(Microsoft.Data.SqlClient)。
HTTP 访问权限变更
从 SQL Server Analysis Services 2025 开始,默认情况下将禁用通过 msmdpump.dll 的 HTTP 连接。 所有通过 msmdpump.dll 的连接都必须通过 HTTPS 等安全通道进行。 有关详细信息,请参阅 配置 HTTP 访问。
已知问题
不支持 Windows Arm64
Windows Arm64 不支持 SQL Server Analysis Services 2025。 目前仅支持 每个 NUMA 节点最多具有 64 个核心 的 Intel 和 AMD x86-64 CPU。
SQL Server 2022 Analysis Services
累积更新 1 (CU1)
加密升级
此更新包括对模式写入操作的加密算法的增强。 此增强功能可能需要升级表格和多维模型数据库,以确保进行适当的加密。 若要了解详细信息,请参阅 升级加密。
正式发布 (GA)
水平融合
此版本引入了 Horizontal Fusion,这是一项查询执行计划优化,旨在减少生成和返回结果所需的数据源查询数。 多个较小的数据源查询合并到更大的数据源查询中。 数据源查询的减少意味着往返次数的减少,以及对大型数据源扫描成本的降低,这会导致 DAX 性能显著提升,并减少数据源的处理需求。 DAX 查询通过水平融合技术运行速度更快,尤其是在 DirectQuery 模式下。 此外,可伸缩性也会增加。
DirectQuery 的并行执行计划
这种改进使 Analysis Services 引擎能够分析针对 DirectQuery 数据源的 DAX 查询,并确定独立的存储引擎操作。 然后,引擎可以并行对数据源执行这些操作。 通过并行执行操作,Analysis Services 引擎可以通过利用大型数据源的可伸缩性来改善查询性能。 为了确保查询处理不会过度负担数据源,请使用 MaxParallelism 属性设置指定可用于并行作的固定线程数。
支持 Power BI DirectQuery 语义模型
此版本引入了对将 DirectQuery 连接到 SQL Server 2022 Analysis Services 模型的 Power BI 模型的支持。 使用 2022 年 5 月及更高版本的 Power BI Desktop 的数据建模者和报表作者现在可以合并 Power BI 模型、Azure Analysis Services 和 SSAS 2022 中的其他导入和 DirectQuery 数据。
若要了解详细信息,请参阅 将 DirectQuery 用于语义模型和 Analysis Services |Power BI 文档。
MDX 查询性能
首先在 Power BI 中引入,现在在 SSAS 2022 中, MDX Fusion 包括公式引擎(FE)优化,减少了每个 MDX 查询的存储引擎(SE)查询数。 使用多维表达式(MDX)查询模型/数据集数据的客户端应用程序(如 Microsoft Excel)将看到改进的查询性能。 常见的 MDX 查询模式现在需要更少的 SE 查询,因为以前需要大量 SE 查询来支持不同的粒度。 SE 查询越少意味着对大型模型进行成本较低的扫描,这会产生显著的性能提升,尤其是在直接查询模式下连接到表格模型时。
若要了解详细信息,请参阅 宣布改进 Power BI 中的 MDX 查询性能 |Microsoft Power BI 博客。
资源治理
此版本包括改进了 QueryMemoryLimit 服务器内存属性和 DbpropMsmdRequestMemoryLimit 连接字符串属性的准确性。
首先在 SSAS 2019 中引入的 QueryMemoryLimit 服务器内存属性仅适用于在查询处理期间创建中间 DAX 查询结果的内存缓存。 现在,在 SSAS 2022 中,它还适用于 MDX 查询,有效地涵盖所有查询。 可以更好地控制导致大量具体化的昂贵查询过程。 如果查询达到指定的限制,引擎将取消查询并向调用方返回错误,从而减少对其他并发用户的影响。
客户端应用程序可以通过指定 DbpropMsmdRequestMemoryLimit 连接字符串属性进一步减少每个查询允许的内存。 以千字节为单位指定,此属性覆盖特定连接的服务器内存属性值 QueryMemoryLimit。
查询交错 - 快速取消的短查询偏差
此版本引入了一个新值,该值指定用于 Threadpool\SchedulingBehavior 属性设置的 短查询偏差以及快速取消。 此属性设置改进了高并发方案中的用户查询响应时间。 若要了解详细信息,请参阅 查询交错 - 配置。
表格模型 1600 兼容级别
此版本引入了表格模型的 1600 兼容级别 。 1600 兼容级别与 Power BI 和 Azure Analysis Services 中的最新功能相吻合。
SSAS 2022 中弃用的功能
此版本未宣布 已弃用 的功能。
SSAS 2022 中已停用的功能
此版本中 已停用 以下功能:
| 模式/类别 | 功能 / 特点 |
|---|---|
| 表格 | 1100 和 1103 兼容性级别 |
| 多维 | 数据挖掘 |
| Power Pivot 模式 | Power Pivot for SharePoint |
SSAS 2022 中的重大更改
此版本停止使用表格模型 1100 和 1103 兼容级别。 为了防止 中断性变更,在将早期 SSAS 版本升级到 SSAS 2022 之前,将模型升级到 1200 兼容级别。
SSAS 2022 中的行为更改
此版本中没有 行为更改 。
SQL Server 2019 Analysis Services
SQL Server 2019 Analysis Services CU 5
SQL Server Analysis Services 累积更新包含在 SQL Server 累积更新中。 若要详细了解和下载最新的累积更新,请参阅 SQL Server 2019 最新累积更新。 累积更新 KB 页汇总了所有 SQL Server 功能的已知问题、改进和修复,包括 SSAS。 此处介绍了 SSAS 的主要功能更新的其他详细信息。
多维模型的 SuperDAX (SuperDAXMD)
借助 CU5,基于 DAX 的客户端现在可以对多维模型使用 SuperDAX 函数和查询模式,从而在查询模型数据时提供更好的性能。 SuperDAX 首先使用 Power BI 和 SQL Server Analysis Services 2016 为表格模型引入了 DAX 查询优化。 SuperDAXMD 现在为多维模型带来了这些改进。
Power BI 博客上的单独公告重点介绍了 Power BI 用户如何通过下载最新版本的 Power BI Desktop 来受益于此多维模型性能改进。 Power BI 服务中的现有交互式报表无需执行任何其他步骤即可受益,因为 Power BI 会自动生成优化的 SuperDAX 查询。 Power BI 自动检测与具有 SuperDAX 支持的多维模型的连接,并使用它已针对表格模型使用的相同优化的 DAX 函数和查询模式。 虽然 Power BI 可以自动切换到 SuperDAXMD,但在自己的商业智能解决方案中,可能需要手动优化 DAX 查询模式。
优化的查询模式应使用 SUMMARIZECOLUMNS 函数替换效率较低的标准 SUMMARIZE 函数。 使用 DAX 变量 VAR 仅在定义位置计算表达式一次,然后在任何其他 DAX 表达式中重复使用结果,而无需再次执行计算。 其他(也许不太常见的 SuperDAX 函数)是 SUBSTITUTEWITHINDEX、 ADDMISSINGITEMS 以及 NATURALLEFTOUTERJOIN 和 NATURALINNERJOIN、 ISONORAFTER 和 GROUPBY。 SELECTCOLUMNS 和 UNION 也是 SuperDAX 函数。
若要详细了解 DAX 如何与多维模型配合使用,以及要注意的重要模式和约束,请务必查看 多维模型的 DAX。
SQL Server 2019 Analysis Services GA (正式发布)
表格模型兼容性级别
此版本引入了表格模型的 1500 兼容级别 。
查询交替
查询交错是一种表格模式系统配置,可在高并发情况下提高用户查询响应时间。 查询交错配合短查询偏差,使得并发查询可以共享 CPU 资源。 要了解详细信息,请参阅查询交叉。
表格模型中的计算组
通过将常见度量值表达式分组为“计算项”,计算组可显著减少冗余度量值的数量 。 计算组在报告客户端中显示为具有单个列的表。 列中的每一个值都表示可应用于任何度量值的可重用计算或计算项。 计算组可以包含任意数量的计算项。 每个计算项都由 DAX 表达式定义。 若要了解详细信息,请参阅 计算组。
Power BI 缓存刷新的调控设置
SSAS 2019 及更高版本中现在支持 ClientCacheRefreshPolicy 属性设置。 此属性设置已可用于 Azure Analysis Services。 Power BI 服务缓存仪表板磁贴数据和报表数据,以便初始加载 Live Connect 报表,导致向引擎提交缓存查询过多,在极端情况下,服务器过载。 ClientCacheRefreshPolicy 属性允许您在服务器级别更改此默认行为。 有关详细信息,请参阅常规属性。
联机附加
此功能提供将表格模型作为联机操作附加的能力。 联机附加可用于本地查询横向扩展环境中只读副本的同步。 若要执行联机附加操作,请使用 Attach XMLA 命令的 AllowOverwrite 选项。

此作可能需要 将模型内存加倍 ,才能在加载新版本时使旧版本保持联机状态。
典型的使用模式可能如下所示:
DB1 (版本 1)已在只读服务器 B 上附加。
DB1 (版本 2)在写入服务器 A 上进行处理。
DB1(版本 2)被分离并放置在服务器 B 可访问的位置(通过共享位置或使用文件复制工具如 robocopy 等)。
使用 AllowOverwrite=True 的 Attach 命令在数据库 1(版本 2)的新位置的服务器 B 上执行。
如果没有此功能,管理员首先需要分离数据库,然后附加新版本的数据库。 这会导致在数据库对用户不可用时出现停滞状态,对数据库的查询将失败。
指定此新标志后,在同一事务中以原子方式删除数据库版本 1,且不会停机。 但是,这需要同时将两个数据库加载到内存中。
表格模型中的多对多关系
此改善允许表之间建立多对多关系,其中两个列均为非唯一。 可以在维度表和事实表之间定义一种关系,这种关系的粒度高于维度表的键列。 这样就避免了必须规范化维度表,并可以提高用户体验,因为生成的模型具有较少的具有逻辑分组列的表。
多对多关系要求模型处于 1500 和更高的兼容级别。 可以通过将 Visual Studio 2019 与 Analysis Services 项目 VSIX update 2.9.2 及更高版本、表格对象模型 (TOM) API、表格模型脚本语言(TMSL)和开源表格编辑器工具结合使用来创建多对多关系。
资源治理的内存设置
以下属性设置提供了改进的资源治理:
- Memory\QueryMemoryLimit - 此内存属性可用于限制由提交到模型的 DAX 查询生成的内存缓存。
- DbpropMsmdRequestMemoryLimit - 此 XMLA 属性可用于替代连接的 Memory\QueryMemoryLimit 服务器属性值。
- OLAP\Query\RowsetSerializationLimit - 此服务器属性限制行集中返回的行数,从而保护服务器资源免受广泛的数据导出使用情况。 此属性同时适用于 DAX 和 MDX 查询。
可以使用最新版本的 SQL Server Management Studio(SSMS)设置这些属性。 这些设置已可用于 Azure Analysis Services。
SSAS 2019 中弃用的功能
此版本未宣布任何不推荐使用的功能。
SSAS 2019 中已停用的功能
此版本未公布 任何已停用 的功能。
SSAS 2019 中的重大变更
此版本中没有 重大更改 。
SSAS 2019 中的行为更改
此版本中没有 行为更改 。
SQL Server 2017 Analysis Services
SQL Server 2017 Analysis Services 经历了自 SQL Server 2012 以来最重要的增强功能。 基于表格模式的成功(首次在 SQL Server 2012 Analysis Services 中引入),此版本使表格模型比以往更加强大。
多维模式和 SharePoint 的 Power Pivot 模式是许多分析服务部署的重要组成部分。 在 Analysis Services 产品生命周期中,这些模式已成熟。 此版本中这两种模式都没有新功能。 不过,其中包括漏洞修复和性能改进。
此处介绍的功能包含在 SQL Server 2017 Analysis Services 中。 但为了利用它们,还必须将最新版本的 Visual Studio 与 Analysis Services 项目和 SQL Server Management Studio(SSMS)配合使用。 Analysis Services 项目和 SSMS 每月更新一次,新增和改进的功能通常与 SQL Server 中的新功能相吻合。
虽然了解所有新功能非常重要,但了解此版本和将来版本中即将弃用和停用的内容也很重要。 若要了解详细信息,请参阅 SSAS 2017 中弃用的功能。
让我们看看此版本中的一些关键新功能。
表格模型的 1400 兼容性级别
若要利用此处所述的许多新功能和功能,必须将新的或现有的表格模型设置为或升级到 1400 兼容级别。 1400 兼容级别的模型不能部署到 SQL Server 2016 SP1 或更早版本,或者降级到较低的兼容性级别。 若要了解详细信息,请参阅 Analysis Services 表格模型的兼容性级别。
在 Visual Studio 中,创建新的表格模型项目时,可以选择新的 1400 兼容级别。
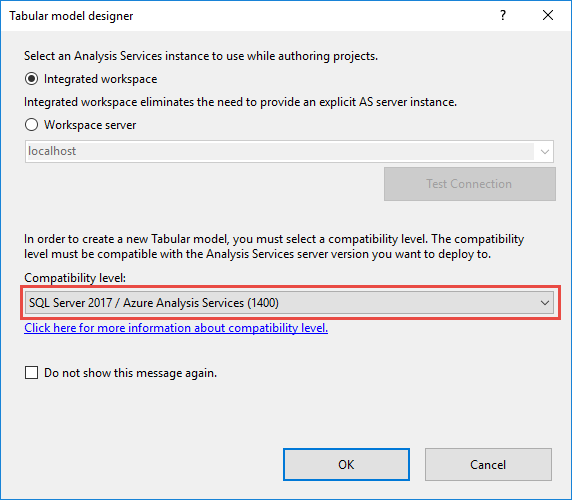
若要升级 Visual Studio 中的现有表格模型,请在解决方案资源管理器中右键单击 Model.bim,然后在“属性”中将兼容性级别属性设置为 SQL Server 2017 (1400)。
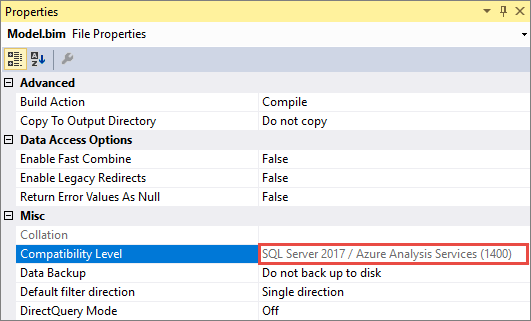
请务必记住,将现有模型升级到 1400 后,便无法降级。 请务必保留 1200 模型数据库的备份。
新式的数据获取体验
当涉及到将数据从数据源导入表格模型时,SSDT 会在 1400 兼容级别为模型引入新式 获取数据 体验。 此新功能基于 Power BI Desktop 和 Microsoft Excel 2016 中的类似功能。 新式 Get Data 体验通过使用 Get Data 查询生成器和 M 表达式提供巨大的数据转换和数据混合功能。
新式 Get Data 体验为各种数据源提供支持。 今后,更新将包括对更多内容的支持。
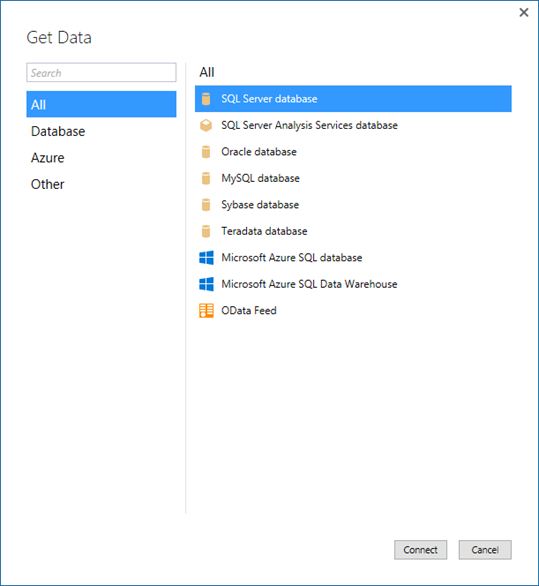
功能强大的直观用户界面使选择数据和数据转换/混合功能比以往更容易。
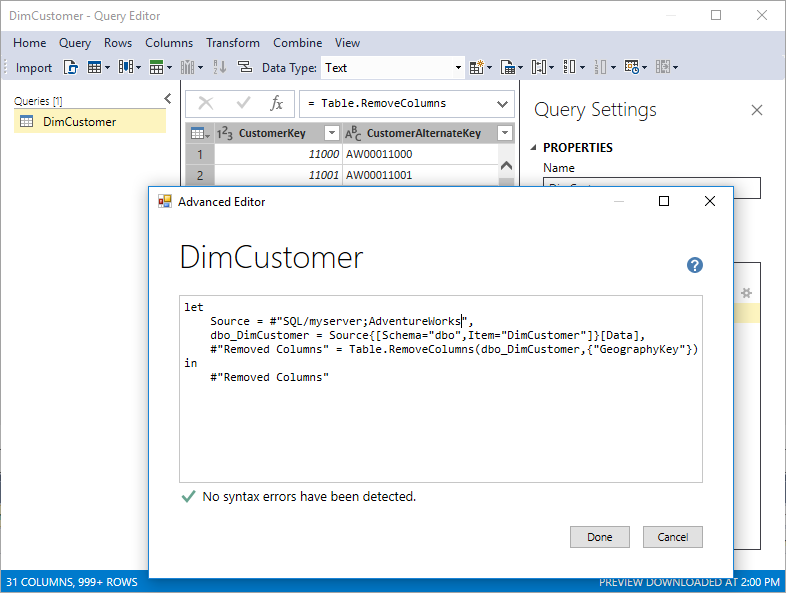
新式“Get Data”体验和 Mashup 能力不适用于从 1200 兼容级别升级到 1400 的现有表格模型。 新体验仅适用于在 1400 兼容级别创建的新模型。
编码提示
此版本引入了编码提示,这是用于优化大型内存中表格模型的处理(数据刷新)的高级功能。 若要更好地了解编码,请参阅 SQL Server 2012 Analysis Services 白皮书中表格模型的性能优化 ,以便更好地了解编码。
值编码为通常用于聚合的列提供更好的查询性能。
哈希编码是用于分组依据列(通常为维度表值)和外键的首选。 字符串列始终经过哈希编码。
数值列可以使用以下任一编码方法。 当 Analysis Services 开始处理表时,如果表为空(带或不带分区)或执行全表处理作,则会为每个数值列获取样本值,以确定是应用值还是哈希编码。 默认情况下,当列中非重复值样本足够大时,选择值编码 - 否则哈希编码通常提供更好的压缩。 Analysis Services 可以根据有关数据分布的详细信息在部分处理列后更改编码方法,并重启编码过程;但是,这会增加处理时间,并且效率低下。 性能优化白皮书更详细地讨论了重新编码,并介绍了如何使用 SQL Server Profiler 检测它。
编码提示允许模型设计者指定编码方法的首选项,该首选项基于先前的数据分析知识和/或针对重新编码追踪事件的响应。 由于对哈希编码列进行聚合比对值编码列进行聚合更慢,因此可以将值编码指定为此类列的提示。 无法保证会应用偏好设置。 这是一个提示,而不是设置。 若要指定编码提示,请在列上设置 EncodingHint 属性。 可能的值为“Default”、“Value”和“Hash”。 Model.bim 文件中的以下基于 JSON 的元数据片段指定了 Sales Amount 列的值编码。
{
"name": "Sales Amount",
"dataType": "decimal",
"sourceColumn": "SalesAmount",
"formatString": "\\$#,0.00;(\\$#,0.00);\\$#,0.00",
"sourceProviderType": "Currency",
"encodingHint": "Value"
}
不规则层次结构
在表格模型中,可以为父子层次结构建模。 具有不同级别的层次结构通常称为不规则层次结构。 默认情况下,不规则层次结构会在最低子级以下的级别显示为空白。 下面是组织结构图中不规则层次结构的示例:
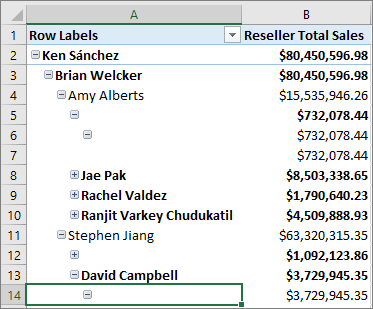
此版本引入了 Hide Members 属性。 可以将层次结构的 “隐藏成员 ”属性设置为 “隐藏空白成员”。
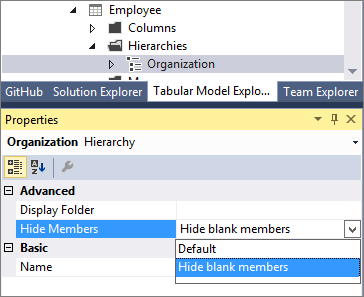
注释
模型中的空白成员由 DAX 空白值表示,而不是空字符串。
当设置为 “隐藏空白成员”和部署的模型时,报表客户端(如 Excel)中会显示层次结构的更易于阅读的版本。
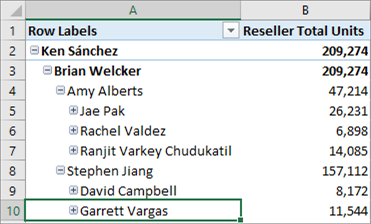
详细信息行
现在可以定义贡献度量值的自定义行集。 详细信息行类似于多维模型中的默认钻取操作。 这样,最终用户就可以比聚合级别更详细地查看信息。
以下数据透视表按年份显示 Adventure Works 示例表格模型中的 Internet 总销售额。 可以右键单击度量值中具有聚合值的单元格,然后单击“ 显示详细信息 ”以查看详细信息行。
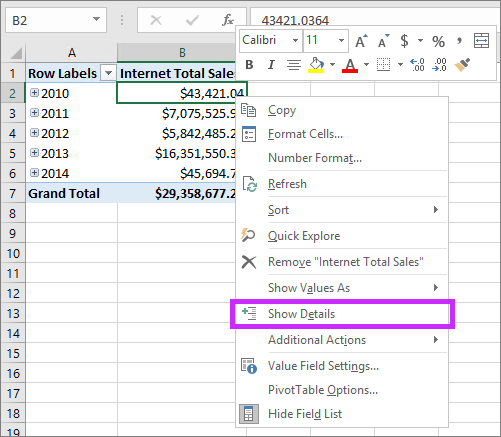
默认情况下,将显示 Internet Sales 表中的关联数据。 此有限行为通常对用户没有意义,因为表可能没有必要的列来显示有用的信息,如客户名称和订单信息。 使用详细信息行,可以为度量值指定 详细信息行表达式 属性。
度量值的详细信息行表达式属性
度量值的 详细信息行表达式 属性允许模型作者自定义返回给终端用户的列和行。
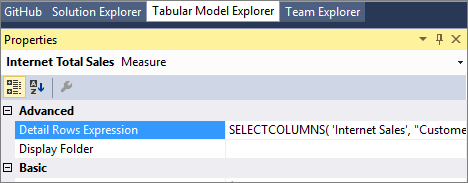
SELECTCOLUMNS DAX 函数通常用于明细行表达式。 以下示例定义了要从示例 Adventure Works 多维数据模型中的 Internet Sales 表的行返回的列。
SELECTCOLUMNS(
'Internet Sales',
"Customer First Name", RELATED( Customer[Last Name]),
"Customer Last Name", RELATED( Customer[First Name]),
"Order Date", 'Internet Sales'[Order Date],
"Internet Total Sales", [Internet Total Sales]
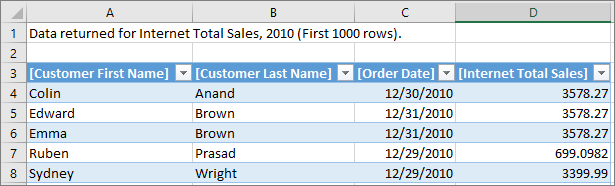
)
定义属性并部署模型后,当用户选择“ 显示详细信息”时,将返回自定义行集。 它会自动地遵循所选单元格的过滤器上下文。 在此示例中,仅显示与2010年值相关的行:
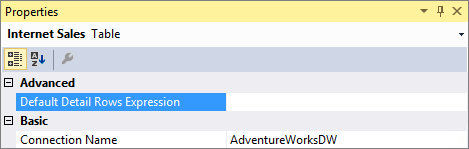
表格的默认详细信息行表达式属性
除了度量值,表还具有用于定义详细信息行表达式的属性。 默认详细信息行表达式属性充当表内所有度量值的默认属性。 未定义自身表达式的度量值会继承表的表达式,并显示表定义的行集合。 这样就可以重复使用表达式,以后添加到表的新度量值会自动继承表达式。
DETAILROWS DAX 函数
此版本中包括一个新的 DETAILROWS DAX 函数,它返回详细信息行表达式定义的行集。 它的工作方式类似于 DRILLTHROUGH MDX 中的语句,该语句也与表格模型中定义的详细信息行表达式兼容。
以下 DAX 查询返回由度量值或其表的明细行表达式定义的行集。 如果未定义表达式,则返回 Internet Sales 表的数据,因为它是包含度量值的表。
EVALUATE DETAILROWS([Internet Total Sales])
对象级安全性
此版本为表和列引入了 对象级安全性 。 除了限制对表和列数据的访问外,还可以保护敏感的表和列名。 这有助于防止恶意用户发现此类表存在。
必须使用基于 JSON 的元数据、表格模型脚本语言(TMSL)或表格对象模型(TOM)设置对象级别安全性。
例如,以下代码通过将 TablePermission 类的 MetadataPermission 属性设置为 None,帮助保护示例 Adventure Works 表格模型中的产品表。
//Find the Users role in Adventure Works and secure the Product table
ModelRole role = db.Model.Roles.Find("Users");
Table productTable = db.Model.Tables.Find("Product");
if (role != null && productTable != null)
{
TablePermission tablePermission;
if (role.TablePermissions.Contains(productTable.Name))
{
tablePermission = role.TablePermissions[productTable.Name];
}
else
{
tablePermission = new TablePermission();
role.TablePermissions.Add(tablePermission);
tablePermission.Table = productTable;
}
tablePermission.MetadataPermission = MetadataPermission.None;
}
db.Update(UpdateOptions.ExpandFull);
动态管理视图 (DMV)
DMVs 是 SQL Server Profiler 中的查询,用于返回关于本地服务器操作和服务器健康状况的信息。 此版本包括对 1200 和 1400 兼容级别的表格模型的 动态管理视图 (DMV)的改进。
DISCOVER_CALC_DEPENDENCY现在适用于表格 1200 和更高型号。 表格 1400 及更高版本的模型显示 M 分区、M 表达式和结构化数据源之间的依赖关系。 若要了解详细信息,请参阅 Analysis Services 博客。
此 DMV 包括 MDSCHEMA_MEASUREGROUP_DIMENSIONS 的改进,这是被各种客户端工具用来显示度量组维度的。 例如,Excel 数据透视表中的“浏览”功能允许用户交叉钻取与所选度量值相关的维度。 此版本修正了基数列,这些列先前显示的值不正确。
DAX 增强功能
新的 DAX 功能最重要的部分之一是 DAX 表达式的新 IN 运算符/CONTAINSROW 函数 。 这类似于 TSQL IN 运算符,常用于在 WHERE 子句中指定多个值。
以前,通常使用逻辑 OR 运算符指定多值筛选器,如以下度量值表达式所示:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
'Product'[Color] = "Red"
|| 'Product'[Color] = "Blue"
|| 'Product'[Color] = "Black"
)
这可以使用运算符IN来简化。
Filtered Sales:=CALCULATE (
[Internet Total Sales], 'Product'[Color] IN { "Red", "Blue", "Black" }
)
在这种情况下,IN 运算符指的是一个包含3行的单列表,每种指定颜色各占一行。 请注意,表构造函数语法使用大括号。
运算符 IN 在功能上等效于函数 CONTAINSROW :
Filtered Sales:=CALCULATE (
[Internet Total Sales], CONTAINSROW({ "Red", "Blue", "Black" }, 'Product'[Color])
)
IN运算符还可以有效地与表构造函数一起使用。 例如,以下度量值按产品颜色和类别的组合筛选:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
FILTER( ALL('Product'),
( 'Product'[Color] = "Red" && Product[Product Category Name] = "Accessories" )
|| ( 'Product'[Color] = "Blue" && Product[Product Category Name] = "Bikes" )
|| ( 'Product'[Color] = "Black" && Product[Product Category Name] = "Clothing" )
)
)
通过使用新 IN 运算符,上述度量值表达式现在等效于以下运算符:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
FILTER( ALL('Product'),
('Product'[Color], Product[Product Category Name]) IN
{ ( "Red", "Accessories" ), ( "Blue", "Bikes" ), ( "Black", "Clothing" ) }
)
)
其他改进
除所有新功能外,Analysis Services、SSDT 和 SSMS 还包括以下改进:
- Power BI 字段列表中的层次结构和列重用在更有效的位置得到了展示。
- 根据日期字段轻松创建与日期维度相关的日期关系。
- Analysis Services 的默认安装选项现在适用于表格模式。
- 新的 Get Data(Power Query)数据源。
- 用于 SSDT 的 DAX 编辑器。
- 现有 DirectQuery 数据源支持 M 查询。
- SSMS 的改进包括支持查看、编辑和对结构化数据源进行脚本操作。
SSAS 2017 中弃用的功能
此版本中 弃用 了以下功能:
| 模式/类别 | 功能 / 特点 |
|---|---|
| 多维度 | 数据挖掘 |
| 多维 | 远程链接度量值组 |
| 表格 | 处于兼容级别 1100 和 1103 的模型 |
| 表格 | 表格对象模型属性 - Column.TableDetailPosition、Column.IsDefaultLabel、Column.IsDefaultImage |
| 工具 | 用于跟踪捕获的 SQL Server Profiler 替换项是使用 SQL Server Management Studio 中嵌入的扩展事件探查器。 请参阅 使用 SQL Server 扩展事件监视 Analysis Services。 |
| 工具 | 用于追踪重播的服务器分析器 更换。 没有替代项。 |
| 跟踪管理对象和跟踪 API | Microsoft.AnalysisServices.Trace 对象(包含 Analysis Services 跟踪和重播对象的 API)。 替换过程包括多个部分: - 跟踪配置:Microsoft.SqlServer.Management.XEvent - 跟踪读取:Microsoft.SqlServer.XEvent.Linq - 跟踪回放:无 |
SSAS 2017 中已停用的功能
此版本中 已停用 以下功能:
| 模式/类别 | 功能 / 特点 |
|---|---|
| 表格 | VertiPaqPagingPolicy 的内存属性值为 (2),启用通过内存映射文件进行的磁盘分页。 |
| 多维 | 远程分区 |
| 多维 | 远程链接度量值组 |
| 多维 | 维度写回 |
| 多维 | 链接维度 |
SSAS 2017 中的重大变更
此版本中没有 重大更改 。
SSAS 2017 中的行为更改
对MDSCHEMA_MEASUREGROUP_DIMENSIONS和DISCOVER_CALC_DEPENDENCY的更改,详细记录在《SQL Server 2017 CTP 2.1 for Analysis Services 的新增特性》公告中。
SQL Server 2016 Analysis Services
SQL Server 2016 Analysis Services 包括许多新的增强功能,可改进性能、简化解决方案创作、自动化数据库管理、与双向交叉筛选、并行分区处理等增强关系。 此版本的大多数增强功能的核心是表格模型数据库的新 1200 兼容级别。
SQL Server 2016 Service Pack 1 (SP1) Analysis Services
SQL Server 2016 Service Pack 1 的分析服务通过基于 Intel 线程建筑模块(Intel TBB)的非一致性内存访问(NUMA)感知机制和优化内存分配,提高了性能和可扩展性。 此新功能通过支持更少的、更强大的企业服务器上的更多用户,帮助降低总拥有成本(TCO)。
具体而言,SQL Server 2016 SP1 Analysis Services 在这些关键领域进行了改进:
- NUMA 感知 - 为了更好地支持 NUMA,Analysis Services 中的内存内(VertiPaq)引擎现在在每个 NUMA 节点上维护一个独立的作业队列。 这可以保证段扫描作业在为段数据分配内存的同一节点上运行。 请注意,NUMA 感知功能默认仅在至少具有四个 NUMA 节点的系统上启用。 在双节点系统上,访问远程分配内存的成本通常不足以值得处理 NUMA 细节的开销。
- 内存分配 - Analysis Services 已通过 Intel Threading Building Blocks 加速优化,该工具是一个可扩展的分配器,为每个核心提供独立的内存池。 随着核心数的增加,系统几乎可以线性缩放。
- 堆碎片 - 基于 Intel TBB 的可扩展分配器还有助于减轻由堆碎片导致的性能问题,研究表明这些碎片会在 Windows 堆中出现。
在大型多节点企业服务器上运行 SQL Server 2016 SP1 Analysis Services 时,性能和可伸缩性测试显示查询吞吐量显著提高。
虽然此版本中的大多数增强功能都特定于表格模型,但对多维模型进行了多项增强,包括针对如 DB2 和 Oracle 等数据源的唯一计数 ROLAP 优化、支持 Excel 2016 的钻取多选功能以及 Excel 查询优化。
SQL Server 2016 分析服务正式发布
建 模
改进了表格 1200 模型的建模性能
对于表格 1200 模型,SSDT 中的元数据作比表格 1100 或 1103 模型快得多。 相比之下,在同一硬件上,在设置为 SQL Server 2014 兼容级别(1103)和 23 个表的模型上创建关系需要 3 秒,而创建为兼容级别 1200 的模型上的同一关系只需不到一秒。
在 SSDT 中添加了用于表格 1200 模型的项目模板
在此版本中,不再需要两个版本的 SSDT 来生成关系项目和 BI 项目。 适用于 Visual Studio 2015 的 SQL Server Data Tools 为 Analysis Services 解决方案添加项目模板,包括用于在 1200 兼容级别生成模型的 Analysis Services 表格项目 。 此外,还包括用于多维和数据挖掘解决方案的其他 Analysis Services 项目模板,但与以前版本中的功能级别(1100 或 1103)相同。
显示文件夹
现在,显示文件夹适用于表格 1200 模型。 在 SQL Server Data Tools 中定义并在 Excel 或 Power BI Desktop 等客户端应用程序中呈现,显示文件夹可帮助你将大量度量值组织到单个文件夹中,并添加视觉层次结构,以便更轻松地在字段列表中导航。
双向交叉筛选
此版本中的新增功能是一种内置方案,可在表格模型中启用双向交叉筛选器,不再需要手动编写 DAX 解决方法以跨表关系传播筛选器上下文。 仅当可以确定方向时,才会自动生成筛选器。 如果跨表关系的多个查询路径的形式存在歧义,则不会自动创建筛选器。 有关详细信息,请参阅 SQL Server 2016 Analysis Services 中表格模型的双向交叉筛选器 。
翻译
现在可以将翻译后的元数据存储在表格 1200 模型中。 模型中的元数据包括 文化、翻译标题和翻译说明的字段。 若要添加翻译,请使用 SQL Server Data Tools 中的 “模型>翻译 ”命令。 有关详细信息,请参阅 表格模型中的翻译(Analysis Services )。
粘贴的表格
现在,当模型包含粘贴的表时,可以将 1100 或 1103 表格模型升级到 1200。 建议使用 SQL Server Data Tools。 在 SSDT 中,将 CompatibilityLevel 设置为 1200,然后部署到 SQL Server Analysis Services 的 SQL Server 2017 实例。 有关详细信息,请参阅 Analysis Services 中表格模型的兼容性级别 。
SSDT 中的计算表
计算表是一种在 SSDT 中基于 DAX 表达式或查询的仅限模型的构造。 在数据库中部署时,计算表与常规表不可区分。
计算表有多种用途,包括创建新表以在特定角色中公开现有表。 经典示例是在多个上下文(订单日期、发货日期等)中运行的 Date 表。 通过为给定角色创建计算表,现在可以激活表关系,以便使用计算表进行查询或数据交互。 计算表的另一个用途是将现有表的某些部分合并到仅存在于模型中的全新表中。 请参阅 “创建计算表 ”了解详细信息。
公式修正
通过在 1200 表格模型上进行公式修正,SSDT 将自动更新任何引用已重命名列或表的度量值。
对 Visual Studio 配置管理器的支持
为了支持多个环境(如测试和预生产环境),Visual Studio 允许开发人员使用配置管理器创建多个项目配置。 多维模型已经利用了这一点,但表格模型没有。 在此版本中,现在可以使用配置管理器部署到不同的服务器。
实例管理
在 SSMS 中管理 1200 级表格模型
在此版本中,表格服务器模式下的 Analysis Services 实例可以在任何兼容级别(1100、1103、1200)运行表格模型。 最新的 SQL Server Management Studio 更新为显示属性,并为 1200 兼容级别的表格模型提供数据库模型管理。
表格模型中多个表分区的并行处理
此版本包括具有两个或多个分区的表的新并行处理功能,从而提高处理性能。 此功能没有配置设置。 有关配置分区和处理表的详细信息,请参阅 表格模型分区。
在 SSMS 中将计算机账户添加为管理员
SQL Server Analysis Services 管理员现在可以使用 SQL Server Management Studio 将计算机帐户配置为 SQL Server Analysis Services 管理员组的成员。 在 “选择用户或组 ”对话框中,设置计算机域 的位置 ,然后添加 计算机 对象类型。 有关详细信息,请参阅授予对 Analysis Services 实例的服务器管理员权限。
用于 Analysis Services 的 DBCC
数据库一致性检查器(DBCC)在内部运行,以检测数据库负载上的潜在数据损坏问题,但如果怀疑数据或模型中存在问题,也可以按需运行。 DBCC 根据模型是表格还是多维,运行不同的检查。 有关详细信息 ,请参阅 Analysis Services 表格数据库和多维数据库的数据库一致性检查器(DBCC )。
扩展事件更新
此版本向 SQL Server Management Studio 添加图形用户界面,以配置和管理 SQL Server Analysis Services 扩展事件。 可以设置实时数据流以实时监视服务器活动、将会话数据加载到内存中以加快分析速度,或将数据流保存到文件中以供脱机分析。 有关详细信息,请参阅 使用 SQL Server 扩展事件监视 Analysis Services。
脚本编写
适用于表格模型的 PowerShell
此版本包括兼容级别为 1200 的表格模型的 PowerShell 增强功能。 可以使用所有适用的 cmdlet 以及特定于表格模式的 cmdlet:Invoke-ProcessASDatabase 和 Invoke-ProcessTable cmdlet。
SSMS 脚本数据库操作
在 最新的 SQL Server Management Studio (SSMS)中,现已为数据库命令启用脚本,包括创建、更改、删除、备份、还原、附加、分离。 输出是 JSON 格式的表格模型脚本语言(TMSL)。 有关详细信息 ,请参阅表格模型脚本语言(TMSL)参考 。
Analysis Services 执行 DDL 任务
Analysis Services 执行 DDL 任务现在还接受表格模型脚本语言 (TMSL) 命令。
SSAS PowerShell 命令行小程序
SSAS PowerShell cmdlet Invoke-ASCmd 现在接受表格模型脚本语言(TMSL)命令。 将来的版本中可能会更新其他 SSAS PowerShell 命令以使用新的表格式元数据(发行说明中将标注异常)。 有关详细信息,请参阅 Analysis Services PowerShell 参考指南。
SSMS 中支持的表格模型脚本语言 (TMSL)
使用 最新版本的 SSMS,现在可以创建脚本来自动执行表格 1200 模型的大多数管理任务。 目前,以下任务可以编写脚本:在任何级别进行处理,以及在数据库级别执行 CREATE、ALTER、DELETE 操作。
在功能上,TMSL 等效于提供多维对象定义的 XMLA ASSL 扩展,但 TMSL 使用本机描述符(如 模型、 表和 关系 )来描述表格元数据。 有关架构的详细信息 ,请参阅表格模型脚本语言(TMSL)参考 。
为表格模型生成的基于 JSON 的脚本可能如下所示:
{
"create": {
"database": {
"name": "AdventureWorksTabular1200",
"id": "AdventureWorksTabular1200",
"compatibilityLevel": 1200,
"readWriteMode": "readWrite",
"model": {}
}
}
}
该 JSON 文档的负载可以如上例所示那样简单,也可以通过完整的对象定义集进行丰富。 表格模型脚本语言 (TMSL) 参考 介绍了语法。
在数据库级别,CREATE、ALTER 和 DELETE 命令将在熟悉的 XMLA 窗口中输出 TMSL 脚本。 其他命令(如 Process)也可以在此版本中编写脚本。 将来的版本中可能会添加对许多其他操作的脚本支持。
| 可编写脚本命令 | 说明 |
|---|---|
| 创建 | 添加数据库、连接或分区。 ASSL 等效项为 CREATE。 |
| createOrReplace(创建或替换) | 通过覆盖以前的版本来更新现有对象定义(数据库、连接或分区)。 ASSL 等效项是 ALTER,AllowOverwrite 设置为 true,ObjectDefinition 设置为 ExpandFull。 |
| 删除 | 删除对象定义。 ASSL 等效项为 DELETE。 |
| 刷新 | 处理对象。 ASSL 等效项是 PROCESS。 |
DAX
DAX 公式编辑功能得到改进
公式编辑栏的更新可帮助你更轻松地编写公式,方法是使用语法着色来区分函数、字段和度量值,同时提供智能的函数和字段建议,并通过错误波浪线标记告诉你 DAX 表达式的某些部分是否错误。 它还允许使用多行(Alt + Enter)和缩进(Tab)。 现在,编辑栏还允许您将注释作为度量值的一部分进行编写,只需键入“//”,同一行上的这些字符后的所有内容都将被视为注释。
DAX 变量
此版本现在包括对 DAX 中的变量的支持。 变量现在可以将表达式的结果存储为命名变量,然后将其作为参数传递给其他度量值表达式。 为变量表达式计算结果值后,即使变量在另一个表达式中引用,这些值也不会更改。 有关详细信息,请参阅 VAR 函数。
新的 DAX 函数
在此版本中,DAX 引入了五十多个新函数,以支持 Power BI 中更快的计算和增强的可视化效果。 若要了解详细信息,请参阅 新的 DAX 函数。
保存不完整度量值
现在,您可以直接在表格 1200 模型项目中存储不完整的 DAX 度量值,然后在准备好继续时再次继续处理它。
其他 DAX 增强功能
- 非空值计算 - 减少进行非空值计算所需的扫描次数。
- 度量值融合 - 同一表中的多个度量值将合并为单个存储引擎 - 查询。
- 分组集 - 当查询要求采用多个粒度(Total/Year/Month)度量值时,在最低级别发送单个查询,其余粒度派生自最低级别。
- 冗余联接消除 - 存储引擎的单个查询返回维度列和度量值。
- 严格评估 IF/SWITCH - 条件为 false 的分支将不再会导致存储引擎查询。 之前,对分支进行了积极评估,但其结果后来被丢弃。
开发人员
AMO 中用于表格 1200 可编程性的 Microsoft.AnalysisServices.Tabular 命名空间
Analysis Services 管理对象(AMO)更新为包含用于管理 SQL Server 2016 Analysis Services 表格模式实例的新表格命名空间,并提供用于以编程方式创建或修改表格 1200 模型的数据定义语言。 访问 Microsoft.AnalysisServices.Tabular 了解 API。
Analysis Services 管理对象(AMO)更新
Analysis Services 管理对象(AMO) 已被重构,包含第二个程序集 Microsoft.AnalysisServices.Core.dll。 新程序集分离出在 Analysis Services 中具有广泛应用程序的常见类,如服务器、数据库和角色,而不考虑服务器模式。 以前,这些类是原始 Microsoft.AnalysisServices 程序集的一部分。 将它们移动到新的程序集为将来的 AMO 扩展铺平了道路,在泛型 API 和特定于上下文的 API 之间明确划分。 现有应用程序不受新程序集影响。 但是,如果出于任何原因选择使用新的 AMO 程序集重新生成应用程序,请务必添加对 Microsoft.AnalysisServices.Core 的引用。 同样,加载和调用 AMO 的 PowerShell 脚本现在必须加载 Microsoft.AnalysisServices.Core.dll。 请务必更新任何脚本。
BIM 文件的 JSON 编辑器
Visual Studio 2015 中的代码视图现在以 JSON 格式呈现表格 1200 模型的 BIM 文件。 Visual Studio 的版本确定 BIM 文件是通过内置 JSON 编辑器还是简单文本以 JSON 形式呈现。
若要使用 JSON 编辑器,并能够展开和折叠模型的各个部分,您需要最新版本的 SQL Server Data Tools 以及 Visual Studio 2015(任何版本,包括免费社区版)。 对于 SSDT 或 Visual Studio 的所有其他版本,BIM 文件以 JSON 形式呈现为简单文本。 空模型至少将包括以下 JSON:
{
"name": "SemanticModel",
"id": "SemanticModel",
"compatibilityLevel": 1200,
"readWriteMode": "readWrite",
"model": {}
}
警告
避免直接编辑 JSON。 这样做可能会损坏模型。
MS-CSDLBI 2.0 架构中的新元素
以下元素已添加到 [MS-CSDLBI] 2.0 架构中定义的 TProperty 复杂类型:
| 元素 | 定义 |
|---|---|
| 默认值 | 一个属性,指定在计算查询时使用的值。 DefaultValue 属性是可选的,但如果无法聚合成员中的值,则会自动选择此属性。 |
| 统计信息 | 与列关联的基础数据中的一组统计信息。 这些统计信息由 TPropertyStatistics 复杂类型定义,仅在生成计算成本不高时才提供,如概念架构定义文件格式与商业智能注释文档的 2.1.13.5 节中所述。 |
DirectQuery
新的 DirectQuery 实现
此版本在表格 1200 模型的 DirectQuery 中具有显著增强功能。 摘要如下:
- DirectQuery 现在会生成更简单的查询,从而提供更好的性能。
- 对定义用于模型设计和测试的示例数据集进行额外控制。
- DirectQuery 模式下的表格 1200 模型现在支持行级别安全性(RLS)。 以前,RLS 的存在阻止在 DirectQuery 模式下部署表格模型。
- 在 DirectQuery 模式中,现已支持表格 1200 模型的计算列。 以前,计算列的存在曾阻碍在 DirectQuery 模式下表格式模型的部署。
- 性能优化包括 VertiPaq 和 DirectQuery 的冗余联接消除。
DirectQuery 模式的新数据源
DirectQuery 模式下的表格 1200 模型支持的数据源现在包括 Oracle、Teradata 和 Microsoft Analytics Platform(以前称为并行数据仓库)。 若要了解详细信息,请参阅 DirectQuery 模式。
SSAS 2016 中弃用的功能
此版本中 弃用 了以下功能:
| 模式/类别 | 功能 / 特点 |
|---|---|
| 多维 | 远程分区 |
| 多维 | 远程链接度量值组 |
| 多维 | 维度写回 |
| 多维 | 链接维度 |
| 多维 | 用于主动缓存的 SQL Server 表通知。 替换项是使用轮询进行主动缓存。 请参阅主动缓存(维度)和主动缓存(分区)。 |
| 多维 | 会话多维数据集。 没有替代项。 |
| 多维 | 本地多维数据集。 没有替代项。 |
| 表格 | 将来的版本不支持表格模型 1100 和 1103 兼容级别。 将模型的兼容级别设置为 1200 或更高版本,然后将模型定义转换为表格元数据。 请参阅 Analysis Services 中表格模型的兼容性级别。 |
| 工具 | 用于跟踪捕获的 SQL Server Profiler 替换项是使用 SQL Server Management Studio 中嵌入的扩展事件探查器。 请参阅 使用 SQL Server 扩展事件监视 Analysis Services。 |
| 工具 | 用于追踪重播的服务器分析器 更换。 没有替代项。 |
| 跟踪管理对象和跟踪 API | Microsoft.AnalysisServices.Trace 对象(包含 Analysis Services 跟踪和重播对象的 API)。 替换过程包括多个部分: - 跟踪配置:Microsoft.SqlServer.Management.XEvent - 跟踪读取:Microsoft.SqlServer.XEvent.Linq - 跟踪回放:无 |
SSAS 2016 中已停用的功能
此版本中 已停用 以下功能:
| 功能 / 特点 | 替代方案或变通方法 |
|---|---|
| CalculationPassValue (MDX) | 没有。 SQL Server 2005 中已弃用此功能。 |
| CalculationCurrentPass (MDX) | 没有。 SQL Server 2005 中已弃用此功能。 |
| NON_EMPTY_BEHAVIOR 查询优化器提示 | 没有。 此功能在 SQL Server 2008 中已弃用。 |
| COM 程序集 | 没有。 此功能在 SQL Server 2008 中已弃用。 |
| CELL_EVALUATION_LIST内部单元属性 | 没有。 SQL Server 2005 中已弃用此功能。 |
SSAS 2016 中的重大更改
.NET 4.0 版本升级
Analysis Services 管理对象(AMO)、ADOMD.NET 和表格对象模型(TOM)客户端库现在针对 .NET 4.0 运行时。 对于面向 .NET 3.5 的应用程序,这可能是一个破坏性变更。 使用这些程序集的较新版本的应用程序现在必须面向 .NET 4.0 或更高版本。
AMO 版本升级
此版本是 Analysis Services 管理对象(AMO) 的版本升级,在某些情况下是一项重大更改。 从以前的版本升级时,调用 AMO 的现有代码和脚本将继续像以前一样运行。 但是,如果需要 重新编译 应用程序并面向 SQL Server 2016 Analysis Services 实例,则必须添加以下命名空间以使代码或脚本正常运行:
using Microsoft.AnalysisServices;
using Microsoft.AnalysisServices.Core;
每当在代码中引用 Microsoft.AnalysisServices 程序集时,现在都需要 Microsoft.AnalysisServices.Core 命名空间。 以前仅位于 Microsoft.AnalysisServices 命名空间中的对象,如果在表格和多维场景中使用方式相同,则在本版本中已被移至核心命名空间。 例如,与服务器相关的 API 将重新定位到 Core 命名空间。
虽然现在有多个命名空间,但两者都存在于同一程序集中(Microsoft.AnalysisServices.dll)。
XEvent DISCOVER 更改
为了更好地支持 SSMS for SQL Server 2016 Analysis Services 中的 XEvent DISCOVER 流式处理,将 DISCOVER_XEVENT_TRACE_DEFINITION 替换为以下 XEvent 跟踪:
DISCOVER_XEVENT_PACKAGES
DISCOVER_XEVENT_OBJECT
DISCOVER_XEVENT_OBJECT_COLUMNS
DISCOVER_XEVENT_SESSION_TARGETS
SSAS 2016 中的行为更改
SharePoint 模式下的分析服务
作为安装后任务,不再需要运行 Power Pivot 配置向导。 对于从当前 SQL Server 2016 Analysis Services 加载模型的所有受支持的 SharePoint 版本都是如此。
表格模型的 DirectQuery 模式
DirectQuery 是表格模型的数据访问模式,可在其中对后端关系数据库执行查询,实时检索结果集。 它通常用于非常大型的数据集,这些数据集不能容纳在内存中或数据不稳定时,并且您希望在针对表格模型的查询中返回的最新数据。
DirectQuery 作为最近几个版本的数据访问模式存在。 在 SQL Server 2016 Analysis Services 中,假设表格模型处于兼容级别 1200 或更高版本,则实现已略有修改。 DirectQuery 的限制比以前少。 它还具有不同的数据库属性。
如果在现有表格模型中使用 DirectQuery,则可以使模型保持其当前兼容级别为 1100 或 1103,并继续使用 DirectQuery 作为针对这些级别的实现。 或者,可以升级到 1200 或更高版本,以便受益于 DirectQuery 的增强功能。
DirectQuery 模型无法直接升级,因为较旧兼容级别的设置在较新的 1200 和更高兼容级别中没有精确对应。 如果有在 DirectQuery 模式下运行的现有表格模型,则应在 SQL Server Data Tools 中打开该模型,关闭 DirectQuery,将 兼容性级别 属性设置为 1200 或更高版本,然后重新配置 DirectQuery 属性。 有关详细信息,请参阅 DirectQuery 模式 。
定义
在将来的版本中,弃 用的功能 将从产品中停止使用,但仍受支持并包含在当前版本中,以保持向后兼容性。 建议停止在新的和现有项目中使用已弃用的功能,以保持与将来版本的兼容性。 文档未针对已弃用的功能进行更新。
早期版本中已弃用 已停用的功能 。 它可能继续包含在当前版本中,但不再受支持。 在上述或将来的版本中,可能会完全删除已停用的功能。
中断性变更会导致升级到当前版本后功能、数据模型、应用程序代码或脚本不再正常运行。
行为更改会影响与上一版本相比,当前版本中相同的功能的工作方式。 仅描述重大行为更改。 不包括用户界面中的更改。 对默认值的更改、完成升级或还原功能所需的手动配置,或现有功能的新实现都是行为更改的示例。