Windows With C++
Exploring High-Performance Algorithms
Kenny Kerr
In the concurrency space, issues such as coordination, asynchronous behavior, responsiveness, and scalability get the lion's share of the attention. These are the high-level topics that developers think about when designing applications. But, perhaps due to inexperience or the lack of good performance tools, some equally important topics are often overlooked. A case in point is high-performance algorithms.
At the enterprise level, developers dwell on issues such as distributed file systems and caches, clusters, message queues, and databases. But what good are all those things if, at the core, you have inefficient algorithms and data structures?
Algorithm efficiency is not as straightforward as you might think. A well-designed algorithm on a single processor can often outperform an inefficient implementation on multiple processors. But a well-designed algorithm today also needs to show measurable scalability and efficiency when multiple processors are available. To complicate matters further, algorithms optimized for a single processor are often difficult to parallelize, whereas slightly less-efficient algorithms can often provide better performance on multiple processors.
As an example, I'm going to use Visual C++ and walk through the development of a fairly simple algorithm, but it's not entirely trivial even if it may seem that way at first glance. Here's what we need to implement:
void MakeGrayscale(BYTE* bitmap,
const int width,
const int height,
const int stride);
The bitmap parameter points to an image consisting of 32 bits per pixel. Again, this is to keep this article focused. The absolute value of the stride indicates the number of bytes from one row of pixels in memory to the next. Padding may exist at the end of each row. The stride's sign indicates whether these rows are top-down with a positive stride or bottom-up with a negative stride in memory.
Let's get the basics out of the way first. We can use the following structure to represent a pixel in memory:
typedef unsigned char BYTE; // from windef.h
struct Pixel
{
BYTE Blue;
BYTE Green;
BYTE Red;
BYTE Alpha;
};
A quick Web search reveals that a reasonable gray scale value can be obtained by blending 30% red, 59% green, and 11% blue for a given color pixel. Here's a simple function to convert just one pixel to gray scale:
void MakeGrayscale(Pixel& pixel)
{
const BYTE scale = static_cast<BYTE>(0.30 * pixel.Red +
0.59 * pixel.Green +
0.11 * pixel.Blue);
pixel.Red = scale;
pixel.Green = scale;
pixel.Blue = scale;
}
The byte offset of a particular pixel within the bitmap can be obtained by calculating the product of its horizontal position and the size of a pixel, along with the product of its vertical position and the stride, and then adding these values together:
offset = x * sizeof(Pixel) + y * stride
How then might you implement the MakeGrayscale function? If you jumped right in without further consideration you might write something along the lines of the algorithm in Figure 1 . At first glance this might look reasonable and, if passed, a small bitmap might even appear to work quite well. But what about larger bitmaps? What about a 20,000 pixel by 20,000 pixel bitmap?
Figure 1 Inefficient Single-Threaded Algorithm
void MakeGrayscale(BYTE* bitmap,
const int width,
const int height,
const int stride)
{
for (int x = 0; x < width; ++x)
for (int y = 0; y < height; ++y)
{
const int offset = x * sizeof(Pixel) + y * stride;
Pixel& pixel = *reinterpret_cast<Pixel*>(bitmap + offset);
MakeGrayscale(pixel);
}
}
I happen to have a Dell PowerEdge with a Quad-Core Intel Xeon X3210 processor. This machine has a clock speed of 2.13GHz, a 1066MHz front-side bus, 8MB of L2 cache, as well as a variety of other cool features. Admittedly it's not the very latest Intel Xeon processor, but it is certainly nothing to scoff at. It's being driven by the 64-bit version of Windows Server 2008 and will do nicely for performance testing.
With all that power I ran the algorithm from Figure 1 on a bitmap 20,000 pixels in width and 20,000 pixels in height. On average it took about 46 seconds over 10 iterations. Admittedly that bitmap is rather large, weighing in at around 1.5GB. But should that matter? My server has 4GB of RAM, so it isn't paging to disk. But Figure 2 reveals the all too familiar view of processor usage.
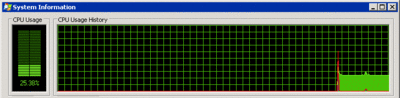
Figure 2 Processor Usage of an Inefficient Single-Threaded Algorithm
The algorithm is furiously working away but only using a quarter of the computer's processing power. The solution is clear—or is it? The most common reaction is to throw more threads at the problem. This is a reasonable position to take. After all, the algorithm as it stands only uses one thread, so only one of the four cores on the test system is being used. The code in Figure 3 adds threads.
Figure 3 Inefficient Multithreaded Algorithm
void MakeGrayscale(BYTE* bitmap,
const int width,
const int height,
const int stride) {
#pragma omp parallel for
for (int x = 0; x < width; ++x)
for (int y = 0; y < height; ++y) {
const int offset = x * sizeof(Pixel) + y * stride;
Pixel& pixel = *reinterpret_cast<Pixel*>(bitmap + offset);
MakeGrayscale(pixel);
}
}
The only difference is the addition of the OpenMP pragma. The outer for loop will now be divided among threads so they can run in parallel and convert different parts of the bitmap. OpenMP creates one thread per processor by default. (Don't get too hung up on the use of OpenMP. It just happens to be a very concise way of partitioning a for loop across threads. There are a variety of other techniques for achieving the same thing depending on your compiler and run time.) This small change makes a big difference, as you can see in Figure 4 .
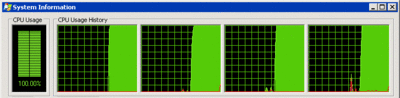
Figure 4 Processor Usage of Inefficient Multithreaded Algorithm
Performance-Improvement Resources
For more information on the topics covered here, see the following resources:
- Maximize Locality, Minimize Contention
- CPU Cache
- OpenMP and C++: Reap the Benefits of Multithreading without All the Work
- Quad-Core Intel Xeon X3210
- Converting Color to Grayscale
But the results are less than ideal. The multithreaded algorithm takes about 30 seconds compared to 46 seconds for the single-threaded version. The 34% increase in performance hardly seems worth the 300% increase in processing cost. What if I told you that an efficient implementation can complete in about 2 seconds using only a single thread, and with the help of multiple threads it can do it in about 0.5 seconds (on the same test system)? That's quite a lot faster than 30 seconds.
It's easier than you think. It just takes some thought about the physical hardware on which your algorithm is running and how data is organized in memory. All too often developers are lulled into a state of indifference toward the hardware that ultimately runs their code. I'm going to reveal an efficient algorithm and then discuss why it is so much better.
Take a look at Figure 5 . It might surprise you that the only difference here is in the order of the for loops. That is, I changed the algorithm from Figure 3 such that the outer loop iterates over the Y axis and the inner loop iterates over the X axis. Now, why would such a seemingly innocuous change cut the time down from 30 seconds to less than 1 second? The answer lies in appreciating the fact that an algorithm tends to be severely impacted by the shape and locality of the data on which it operates as well as the characteristics of the hardware.
Figure 5 Efficient Algorithm
void MakeGrayscale(BYTE* bitmap,
const int width,
const int height,
const int stride) {
#pragma omp parallel for
for (int y = 0; y < height; ++y)
for (int x = 0; x < width; ++x) {
const int offset = x * sizeof(Pixel) + y * stride;
Pixel& pixel = *reinterpret_cast<Pixel*>(bitmap + offset);
MakeGrayscale(pixel);
}
}
To understand this we must reexamine the data structure on which the algorithm operates. The bitmap's memory buffer logically contains rows of pixels. Obviously memory is not tabular, but there needs to be a way to easily and efficiently address any pixel given its coordinates; thinking in terms of rows helps to conceptualize this. This abstraction does, however, reveal its physical implementation when you consider that these rows may contain padding, which is necessary to properly align the beginning of each row, particularly when using bitmaps with indexed color tables (see Figure 6 ).
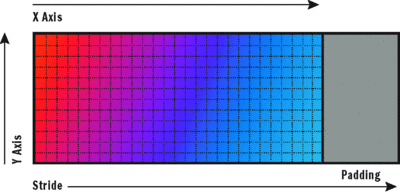
Figure 6 Rows and Padding (Bottom-up)
The direction of the Y axis illustrates a bottom-up layout indicated by a negative stride. It is theoretically possible that this direction could also impact performance, but that would be hard to measure without very good tooling support.
A good concurrency rule of thumb is that memory that is farther apart should not be used together by a single processor, while memory that is close together should not be used by different processors. In other words, keep the data that is used together close together and the data that is used separately far enough apart. In this way, a hardware cache manager can cache data that will be used by different processors without introducing any contention.
To appreciate how the memory layout affects performance, you need to remember that memory is continuous, not tabular. The virtual address space is flat. Figure 7 illustrates how the bitmap is partitioned using the inefficient algorithm in Figure 3 .
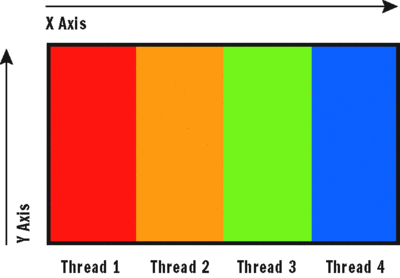
Figure 7 Inefficient Data Partitioning
It should now be obvious why this algorithm performs so poorly. Although there are no loop-carried dependencies, the algorithm is parallelized in such a way as to almost guarantee contention at the hardware cache level. Larger bitmaps may reduce contention, but the repeated cache misses will force the cache manager to constantly reload cache lines, thus affecting performance. Even on a single processor it will perform very poorly as it has to replace the data in its cache lines constantly. Figure 8 provides a clearer indication that locality is at fault. The pattern will repeat for as many rows as there are in the bitmap.

Figure 8 Inefficient Data Partitioning (Repeating)
As a contrast, the efficient algorithm in Figure 5 partitions the bitmap along the Y axis so that each processor will be able to process a stream of pixels that are close together but far apart from pixels processed by other processors, thus making it possible for the cache manager to share the bitmap across processors without contention (see Figures 9 and 10 ). In particular, Figure 10 shows that each process has a single continuous block of memory to process, improving locating and caching performance immensely.

Figure 9 Efficient Data Partitioning

Figure 10 Efficient Data Partitioning (Non-Repeating)
Reaching the 0.5-second target cited above would be tough given the static scheduling used by OpenMP by default. OpenMP also provides dynamic and guided scheduling that can be used to squeeze those last few milliseconds out of the algorithm. The fundamental problem is that dividing the work perfectly among the available processors isn't likely to provide the best results since the computer might be doing some minor tasks in the background. This could result in some of the threads completing before the others and then sitting idly while waiting for the stragglers to complete.
On the other hand, you may be able to make it even faster, possibly using a different algorithm or data structure. You could load bitmap partitions into the physical memory of individual nodes in a Non-uniform Memory Access (NUMA) system. You could even send them off to different nodes on a Windows Server High-Performance Computing (HPC) grid. None of this would be possible with the inefficient algorithm. The point is that you can dramatically improve the performance of your code by giving a little thought to your data structures and algorithms and how performance may be affected by the hardware on which you're running.
Send your questions and comments to mmwincpp@microsoft.com .
Kenny Kerr is a software craftsman specializing in software development for Windows. He has a passion for writing and teaching developers about programming and software design. Reach Kenny at weblogs.asp.net/kennykerr .