使用 Azure) 生成 Real-World 云应用的暂时性故障处理 (
使用 Azure 构建真实世界云应用 电子书基于 Scott Guthrie 开发的演示文稿。 其中介绍了 13 种模式和做法,可帮助你成功开发适用于云的 Web 应用。 有关电子书的信息,请参阅 第一章。
设计真实的云应用时,需要考虑的一件事就是如何处理临时服务中断。 此问题在云应用中非常重要,因为你非常依赖网络连接和外部服务。 你经常会遇到一些通常自我修复的小故障,如果你不准备智能地处理它们,它们将给你的客户带来糟糕的体验。
暂时性故障的原因
在云环境中,你会发现失败和删除数据库连接定期发生。 部分原因在于,与 Web 服务器和数据库服务器具有直接物理连接的本地环境相比,要经历更多的负载均衡器。 此外,有时当你依赖于多租户服务时,你会看到对服务的调用变慢或超时,因为使用该服务的其他人严重打击了该服务。 在其他情况下,你可能是过于频繁地访问服务的用户,并且服务故意限制你(拒绝连接),以防止你对服务的其他租户产生不利影响。
使用智能重试/回退逻辑来缓解暂时性故障的影响
可以识别通常是暂时性的错误,并自动重试导致错误的操作,而不是引发异常并向客户显示不可用或错误页面,希望不久之后你就能成功。 大多数情况下,操作会在第二次尝试中成功,你将从错误中恢复,而客户从未意识到存在问题。
可通过多种方式实现智能重试逻辑。
Microsoft Patterns & Practices 组有一个暂时性故障处理应用程序块,如果使用 ADO.NET 进行SQL 数据库访问, (不通过 Entity Framework) 执行一切操作。 只需设置重试策略(重试查询或命令的次数以及两次尝试之间的等待时间)并将 SQL 代码包装在 using 块中。
public void HandleTransients() { var connStr = "some database"; var _policy = RetryPolicy.Create < SqlAzureTransientErrorDetectionStrategy( retryCount: 3, retryInterval: TimeSpan.FromSeconds(5)); using (var conn = new ReliableSqlConnection(connStr, _policy)) { // Do SQL stuff here. } }TFH 还支持 Azure In-Role 缓存和服务总线。
使用实体框架时,通常不会直接使用 SQL 连接,因此不能使用此模式和做法包,但 Entity Framework 6 会直接在框架中生成这种重试逻辑。 以类似的方式指定重试策略,然后 EF 在访问数据库时使用该策略。
若要在 Fix It 应用中使用此功能,只需添加派生自 DbConfiguration 的类并打开重试逻辑。
// EF follows a Code based Configuration model and will look for a class that // derives from DbConfiguration for executing any Connection Resiliency strategies public class EFConfiguration : DbConfiguration { public EFConfiguration() { AddExecutionStrategy(() => new SqlAzureExecutionStrategy()); } }对于框架识别为通常暂时性错误的SQL 数据库异常,所示代码指示 EF 重试操作最多 3 次,重试之间的退避延迟呈指数级,最大延迟为 5 秒。 指数退避意味着每次重试失败后,它会等待较长时间,然后重试。 如果一行中的三次尝试失败,则会引发异常。 以下有关断路器的部分解释了为何需要指数退避和有限次数的重试。
使用 Azure 存储服务时,可能会遇到类似的问题,就像修复它应用对 Blob 执行的操作一样,而 .NET 存储客户端 API 已经实现了同一类型的逻辑。 只需指定重试策略,如果对默认设置感到满意,甚至无需执行此操作。
断路 器
不想在一段时间内重试太多次的原因有多种:
- 过多用户持续重试失败的请求可能会降低其他用户的体验。 如果数百万人都发出重复重试请求,你可能会将 IIS 调度队列绑起来,并阻止应用为它可能成功处理的请求提供服务。
- 如果每个人都因服务故障而重试,则可能会有太多请求排队,导致服务在开始恢复时被淹没。
- 如果错误是由于限制造成的,并且存在服务用于限制的时间窗口,则继续重试可能会使该窗口移出并导致限制继续。
- 你可能有一个用户正在等待网页呈现。 让人们等待太久可能更烦人, 相对较快地建议他们稍后再试。
指数退避通过限制服务可从应用程序获取的重试频率来解决其中的某些问题。 但你还需要具有 断路器:这意味着,在特定的重试阈值下,应用将停止重试并采取其他一些操作,例如以下操作之一:
- 自定义回退。 如果你不能从路透社得到股票价格, 也许你可以从彭博社得到它:或者,如果无法从数据库获取数据,则可以从缓存中获取数据。
- 失败无提示。 如果从服务中需要的内容不是应用的全有或全无,请在无法获取数据时返回 null。 如果显示“修复它”任务,但 Blob 服务未响应,则可以显示任务详细信息,而不显示图像。
- 快速失败。 使用户出错,以避免重试请求充斥服务,这可能会导致其他用户的服务中断或延长限制窗口。 可以显示友好的“稍后重试”消息。
没有一刀切的重试策略。 与在用户等待响应的同步 Web 应用中相比,在异步后台工作进程中重试次数和等待时间更长。 对于关系数据库服务,两次重试之间的等待时间比缓存服务要长。 下面是一些建议的重试策略示例,可让你了解数字可能如何变化。 (“Fast First”表示在第一次重试之前没有延迟。
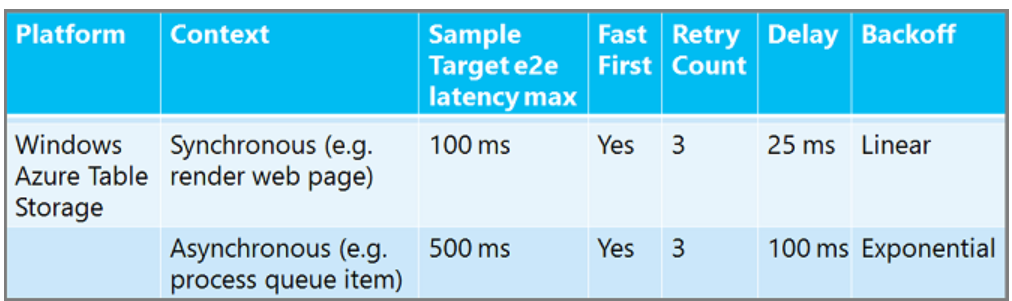
有关SQL 数据库重试策略指南,请参阅排查暂时性故障和SQL 数据库连接错误。
总结
重试/回退策略有助于使临时错误在大多数时间对客户不可见,Microsoft 提供了框架,无论你使用的是 ADO.NET、实体框架还是 Azure 存储服务,你都可以使用这些框架来最大程度地减少实施策略的工作。
下一章将介绍如何使用分布式缓存提高性能和可靠性。
资源
有关详细信息,请参阅以下资源:
文档
- Azure 云服务 上 Large-Scale 服务的设计的最佳做法。 马克·西姆斯和迈克尔·托马斯西的白皮书。 类似于故障安全系列,但会介绍更多操作方法详细信息。 请参阅遥测和诊断部分。
- 故障安全:弹性云体系结构指南。 马克·莫塞里、乌尔里希·霍曼和安德鲁·汤希尔的白皮书。 FailSafe 视频系列的网页版本。
- Microsoft 模式和做法 - Azure 指南。 请参阅重试模式、计划程序代理监督程序模式。
- 实体框架 - 连接复原/重试逻辑。 如何使用和自定义 Entity Framework 6 的暂时性故障处理功能。
- 在 ASP.NET MVC 应用程序中使用实体框架进行连接复原和命令拦截。 第四个教程系列由九部分组成,演示如何为SQL 数据库设置 EF 6 连接复原功能。
视频
- FailSafe:生成可缩放、可复原云服务。 由乌尔里希·霍曼、马克·莫库里和马克·西姆斯组成的九部分系列。 以一种易于访问且有趣的方式呈现高级概念和体系结构原则,其中从 Microsoft 客户咨询团队 (CAT) 实际客户的体验中提取的故事。 请参阅从 40:55 开始的第 3 集关于断路器的讨论。
- 构建大型:从 Azure 客户那里吸取的教训 - 第 II 部分。 Mark Simms 讨论如何设计故障、暂时性故障处理和检测所有内容。
代码示例
- Azure 中的云服务基础知识。 Microsoft Azure 客户顾问团队创建的示例应用程序,演示如何使用 企业库暂时性故障处理块 (TFH) 。 有关详细信息,请参阅云服务基础数据访问层 - 临时故障处理。 建议使用 TFH 直接 (使用 ADO.NET 访问数据库,而无需使用 Entity Framework) 。
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈